 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Xia
On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation
Apr 23, 2022
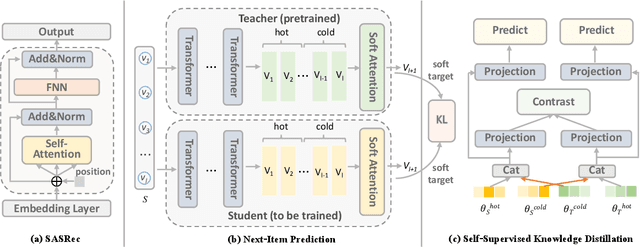
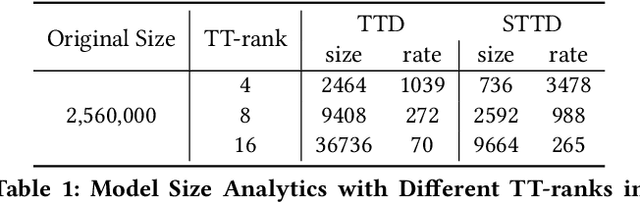
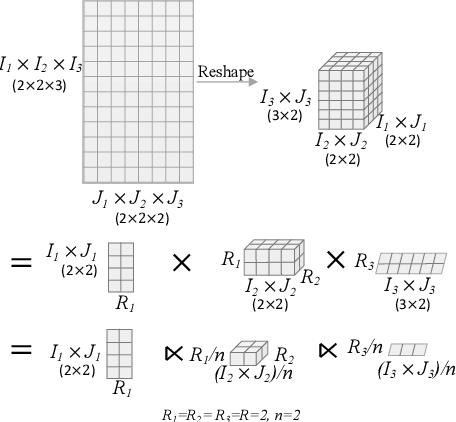

Modern recommender systems operate in a fully server-based fashion. To cater to millions of users, the frequent model maintaining and the high-speed processing for concurrent user requests are required, which comes at the cost of a huge carbon footprint. Meanwhile, users need to upload their behavior data even including the immediate environmental context to the server, raising the public concern about privacy. On-device recommender systems circumvent these two issues with cost-conscious settings and local inference. However, due to the limited memory and computing resources, on-device recommender systems are confronted with two fundamental challenges: (1) how to reduce the size of regular models to fit edge devices? (2) how to retain the original capacity? Previous research mostly adopts tensor decomposition techniques to compress the regular recommendation model with limited compression ratio so as to avoid drastic performance degradation. In this paper, we explore ultra-compact models for next-item recommendation, by loosing the constraint of dimensionality consistency in tensor decomposition. Meanwhile, to compensate for the capacity loss caused by compression, we develop a self-supervised knowledge distillation framework which enables the compressed model (student) to distill the essential information lying in the raw data, and improves the long-tail item recommendation through an embedding-recombination strategy with the original model (teacher). The extensive experiments on two benchmarks demonstrate that, with 30x model size reduction, the compressed model almost comes with no accuracy loss, and even outperforms its uncompressed counterpart in most cases.
SepViT: Separable Vision Transformer
Apr 03, 2022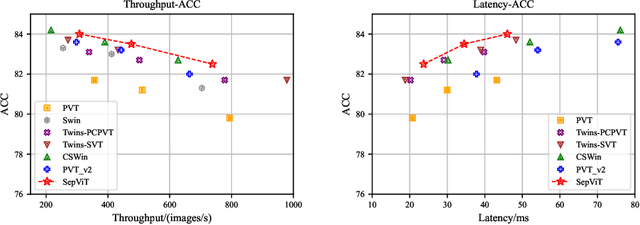

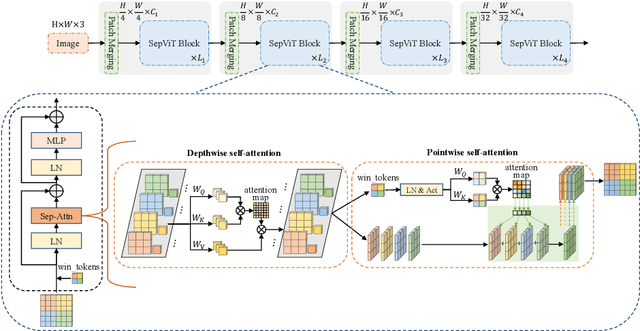
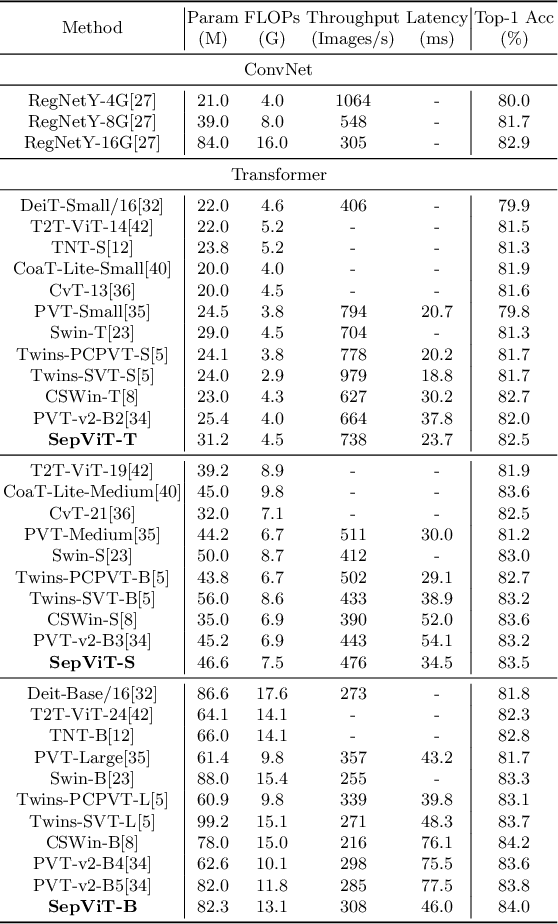
Vision Transformers have witnessed prevailing success in a series of vision tasks. However, they often require enormous amount of computations to achieve high performance, which is burdensome to deploy on resource-constrained devices. To address these issues, we draw lessons from depthwise separable convolution and imitate its ideology to design the Separable Vision Transformer, abbreviated as SepViT. SepViT helps to carry out the information interaction within and among the windows via a depthwise separable self-attention. The novel window token embedding and grouped self-attention are employed to model the attention relationship among windows with negligible computational cost and capture a long-range visual dependencies of multiple windows, respectively. Extensive experiments on various benchmark tasks demonstrate SepViT can achieve state-of-the-art results in terms of trade-off between accuracy and latency. Among them, SepViT achieves 84.0% top-1 accuracy on ImageNet-1K classification while decreasing the latency by 40%, compared to the ones with similar accuracy (e.g., CSWin, PVTV2). As for the downstream vision tasks, SepViT with fewer FLOPs can achieve 50.4% mIoU on ADE20K semantic segmentation task, 47.5 AP on the RetinaNet-based COCO detection task, 48.7 box AP and 43.9 mask AP on Mask R-CNN-based COCO detection and segmentation tasks.
Self-Supervised Learning for Recommender Systems: A Survey
Mar 29, 2022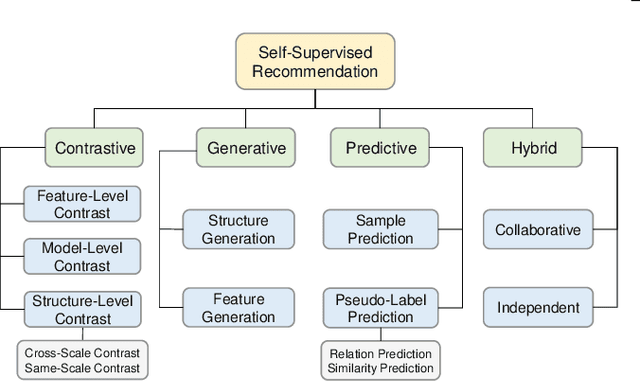
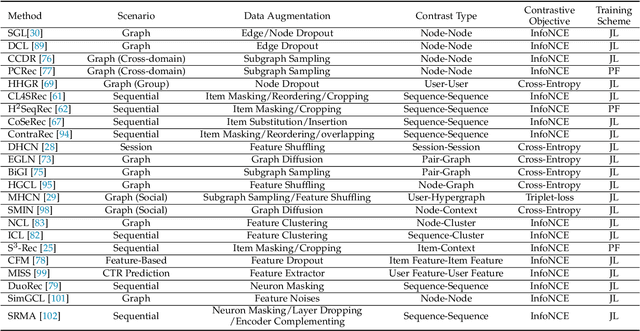
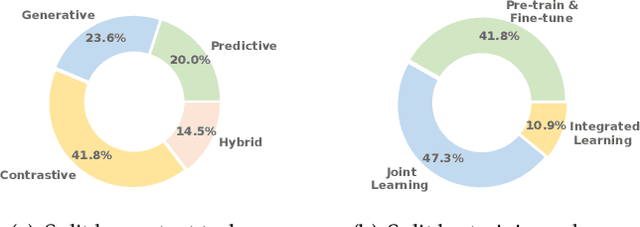
Neural architecture-based recommender systems have achieved tremendous success in recent years. However, when dealing with highly sparse data, they still fall short of expectation. Self-supervised learning (SSL), as an emerging technique to learn with unlabeled data, recently has drawn considerable attention in many fields. There is also a growing body of research proceeding towards applying SSL to recommendation for mitigating the data sparsity issue. In this survey, a timely and systematical review of the research efforts on self-supervised recommendation (SSR) is presented. Specifically, we propose an exclusive definition of SSR, on top of which we build a comprehensive taxonomy to divide existing SSR methods into four categories: contrastive, generative, predictive, and hybrid. For each category, the narrative unfolds along its concept and formulation, the involved methods, and its pros and cons. Meanwhile, to facilitate the development and evaluation of SSR models, we release an open-source library SELFRec, which incorporates multiple benchmark datasets and evaluation metrics, and has implemented a number of state-of-the-art SSR models for empirical comparison. Finally, we shed light on the limitations in the current research and outline the future research directions.
V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer
Mar 20, 2022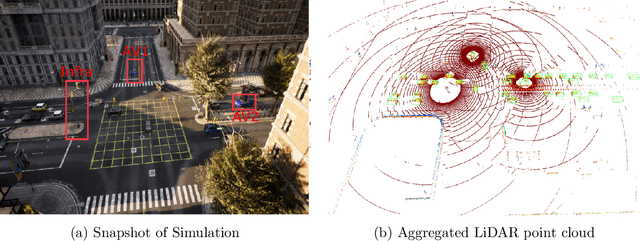
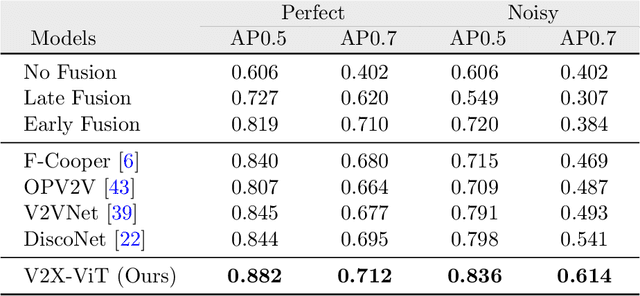
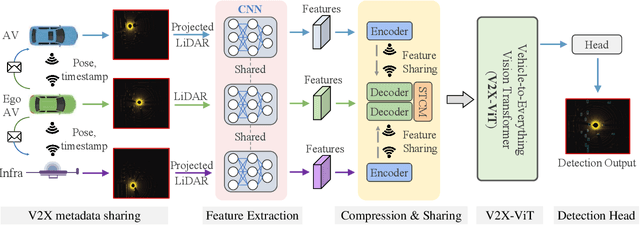
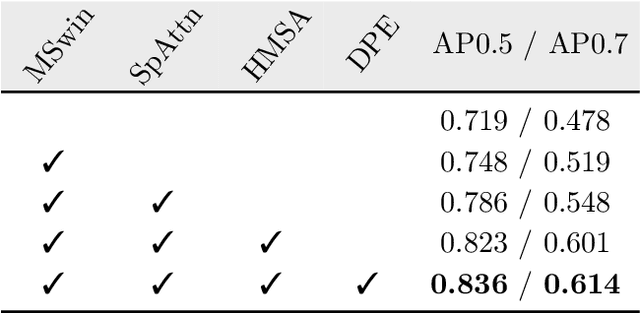
In this paper, we investigate the application of Vehicle-to-Everything (V2X) communication to improve the perception performance of autonomous vehicles. We present a robust cooperative perception framework with V2X communication using a novel vision Transformer. Specifically, we build a holistic attention model, namely V2X-ViT, to effectively fuse information across on-road agents (i.e., vehicles and infrastructure). V2X-ViT consists of alternating layers of heterogeneous multi-agent self-attention and multi-scale window self-attention, which captures inter-agent interaction and per-agent spatial relationships. These key modules are designed in a unified Transformer architecture to handle common V2X challenges, including asynchronous information sharing, pose errors, and heterogeneity of V2X components. To validate our approach, we create a large-scale V2X perception dataset using CARLA and OpenCDA. Extensive experimental results demonstrate that V2X-ViT sets new state-of-the-art performance for 3D object detection and achieves robust performance even under harsh, noisy environments. The dataset, source code, and trained models will be open-sourced.
Graph Augmentation-Free Contrastive Learning for Recommendation
Dec 16, 2021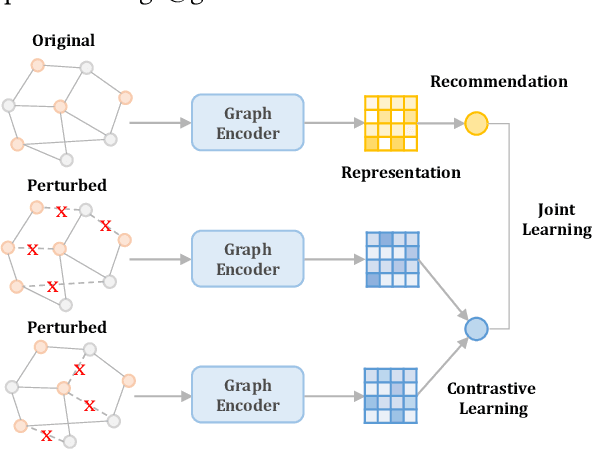
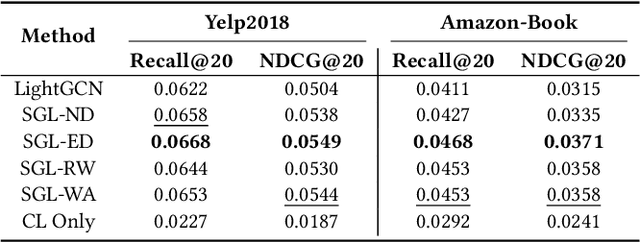
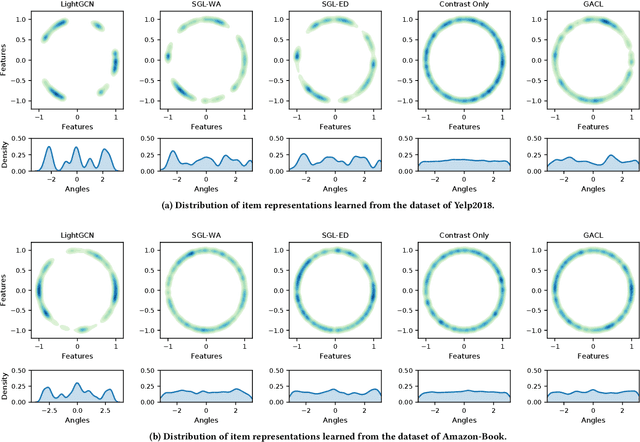
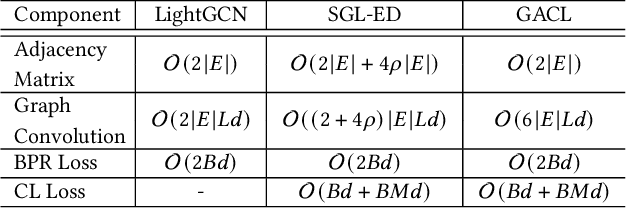
Contrastive learning (CL) recently has received considerable attention in the field of recommendation, since it can greatly alleviate the data sparsity issue and improve recommendation performance in a self-supervised manner. A typical way to apply CL to recommendation is conducting edge/node dropout on the user-item bipartite graph to augment the graph data and then maximizing the correspondence between representations of the same user/item augmentations under a joint optimization setting. Despite the encouraging results brought by CL, however, what underlies the performance gains still remains unclear. In this paper, we first experimentally demystify that the uniformity of the learned user/item representation distributions on the unit hypersphere is closely related to the recommendation performance. Based on the experimental findings, we propose a graph augmentation-free CL method to simply adjust the uniformity by adding uniform noises to the original representations for data augmentations, and enhance recommendation from a geometric view. Specifically, the constant graph perturbation during training is not required in our method and hence the positive and negative samples for CL can be generated on-the-fly. The experimental results on three benchmark datasets demonstrate that the proposed method has distinct advantages over its graph augmentation-based counterparts in terms of both the ability to improve recommendation performance and the running/convergence speed. The code is released at https://github.com/Coder-Yu/QRec.
OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication
Sep 17, 2021

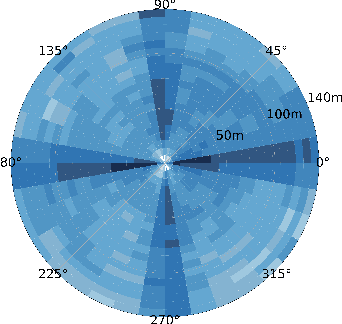
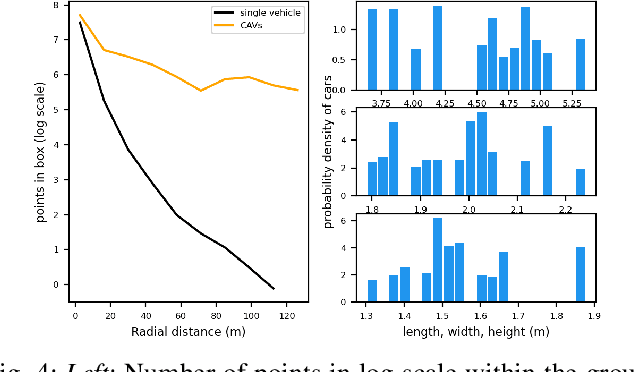
Employing Vehicle-to-Vehicle communication to enhance perception performance in self-driving technology has attracted considerable attention recently; however, the absence of a suitable open dataset for benchmarking algorithms has made it difficult to develop and assess cooperative perception technologies. To this end, we present the first large-scale open simulated dataset for Vehicle-to-Vehicle perception. It contains over 70 interesting scenes, 11,464 frames, and 232,913 annotated 3D vehicle bounding boxes, collected from 8 towns in CARLA and a digital town of Culver City, Los Angeles. We then construct a comprehensive benchmark with a total of 16 implemented models to evaluate several information fusion strategies~(i.e. early, late, and intermediate fusion) with state-of-the-art LiDAR detection algorithms. Moreover, we propose a new Attentive Intermediate Fusion pipeline to aggregate information from multiple connected vehicles. Our experiments show that the proposed pipeline can be easily integrated with existing 3D LiDAR detectors and achieve outstanding performance even with large compression rates. To encourage more researchers to investigate Vehicle-to-Vehicle perception, we will release the dataset, benchmark methods, and all related codes in https://mobility-lab.seas.ucla.edu/opv2v/.
Self-Supervised Graph Co-Training for Session-based Recommendation
Aug 24, 2021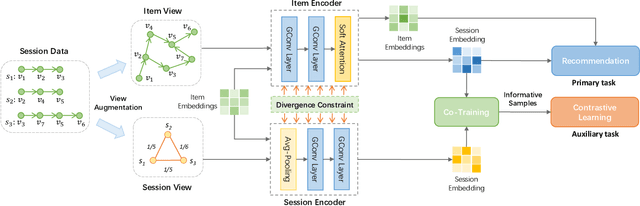
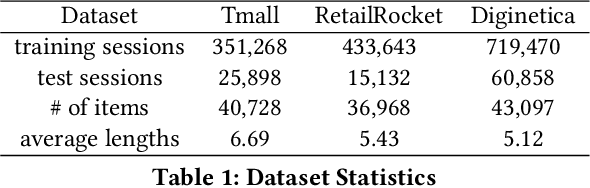
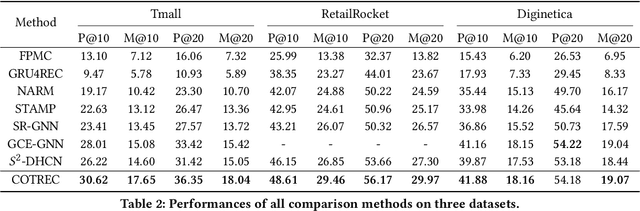
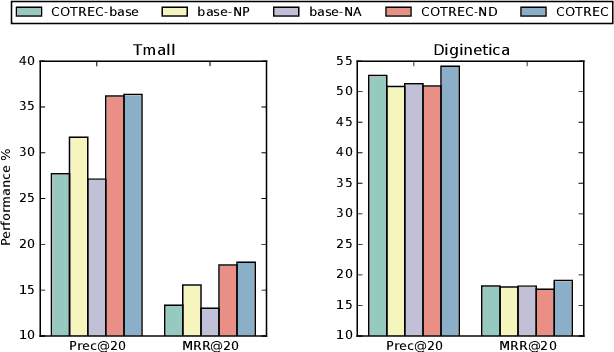
Session-based recommendation targets next-item prediction by exploiting user behaviors within a short time period. Compared with other recommendation paradigms, session-based recommendation suffers more from the problem of data sparsity due to the very limited short-term interactions. Self-supervised learning, which can discover ground-truth samples from the raw data, holds vast potentials to tackle this problem. However, existing self-supervised recommendation models mainly rely on item/segment dropout to augment data, which are not fit for session-based recommendation because the dropout leads to sparser data, creating unserviceable self-supervision signals. In this paper, for informative session-based data augmentation, we combine self-supervised learning with co-training, and then develop a framework to enhance session-based recommendation. Technically, we first exploit the session-based graph to augment two views that exhibit the internal and external connectivities of sessions, and then we build two distinct graph encoders over the two views, which recursively leverage the different connectivity information to generate ground-truth samples to supervise each other by contrastive learning. In contrast to the dropout strategy, the proposed self-supervised graph co-training preserves the complete session information and fulfills genuine data augmentation. Extensive experiments on multiple benchmark datasets show that, session-based recommendation can be remarkably enhanced under the regime of self-supervised graph co-training, achieving the state-of-the-art performance.
OpenCDA:An Open Cooperative Driving Automation Framework Integrated with Co-Simulation
Aug 12, 2021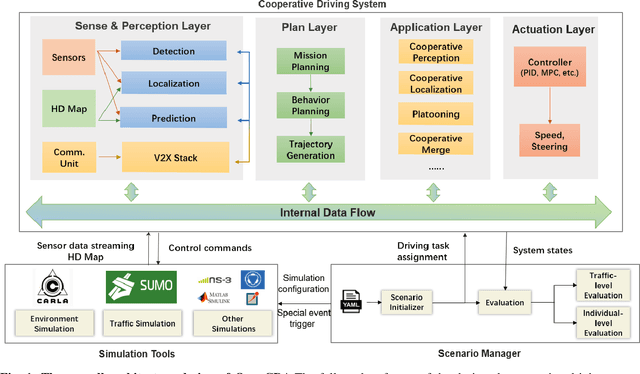
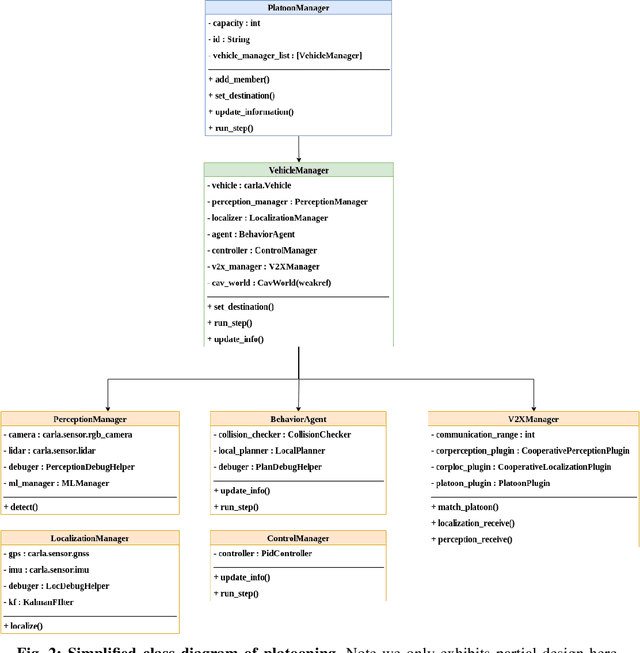
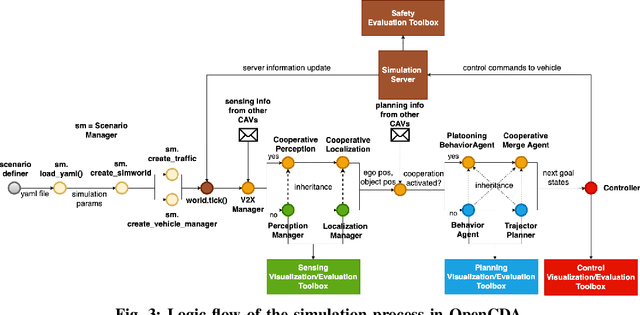
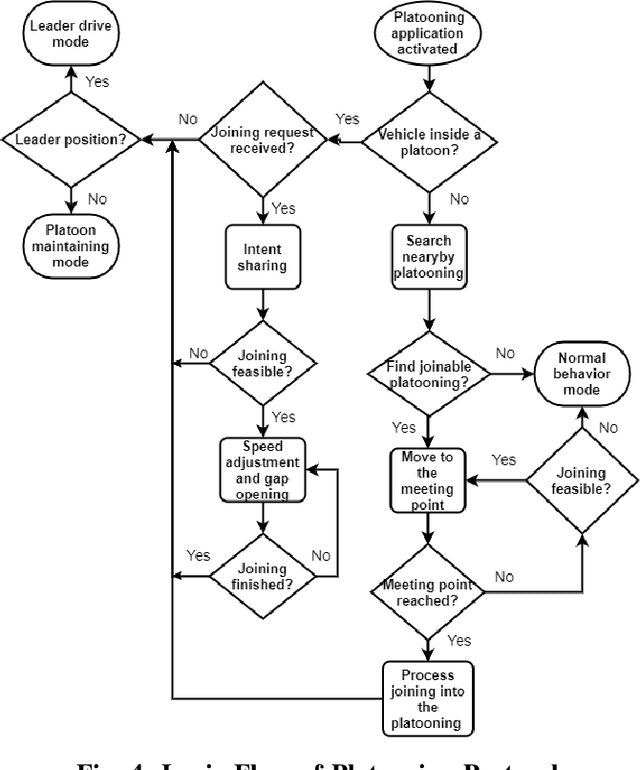
Although Cooperative Driving Automation (CDA) has attracted considerable attention in recent years, there remain numerous open challenges in this field. The gap between existing simulation platforms that mainly concentrate on single-vehicle intelligence and CDA development is one of the critical barriers, as it inhibits researchers from validating and comparing different CDA algorithms conveniently. To this end, we propose OpenCDA, a generalized framework and tool for developing and testing CDA systems. Specifically, OpenCDA is composed of three major components: a co-simulation platform with simulators of different purposes and resolutions, a full-stack cooperative driving system, and a scenario manager. Through the interactions of these three components, our framework offers a straightforward way for researchers to test different CDA algorithms at both levels of traffic and individual autonomy. More importantly, OpenCDA is highly modularized and installed with benchmark algorithms and test cases. Users can conveniently replace any default module with customized algorithms and use other default modules of the CDA platform to perform evaluations of the effectiveness of new functionalities in enhancing the overall CDA performance. An example of platooning implementation is used to illustrate the framework's capability for CDA research. The codes of OpenCDA are available in the https://github.com/ucla-mobility/OpenCDA.
* Accepted by ITSC2021
OpenCDA:An Open Cooperative Driving Automation FrameworkIntegrated with Co-Simulation
Jul 13, 2021Although Cooperative Driving Automation (CDA) has attracted considerable attention in recent years, there remain numerous open challenges in this field. The gap between existing simulation platforms that mainly concentrate on single-vehicle intelligence and CDA development is one of the critical barriers, as it inhibits researchers from validating and comparing different CDA algorithms conveniently. To this end, we propose OpenCDA, a generalized framework and tool for developing and testing CDA systems. Specifically, OpenCDA is composed of three major components: a co-simulation platform with simulators of different purposes and resolutions, a full-stack cooperative driving system, and a scenario manager. Through the interactions of these three components, our framework offers a straightforward way for researchers to test different CDA algorithms at both levels of traffic and individual autonomy. More importantly, OpenCDA is highly modularized and installed with benchmark algorithms and test cases. Users can conveniently replace any default module with customized algorithms and use other default modules of the CDA platform to perform evaluations of the effectiveness of new functionalities in enhancing the overall CDA performance. An example of platooning implementation is used to illustrate the framework's capability for CDA research. The codes of OpenCDA are available in the https://github.com/ucla-mobility/OpenCDA.
* Accepted by ITSC2021