 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyu Li
A Benchmark of Video-Based Clothes-Changing Person Re-Identification
Nov 21, 2022

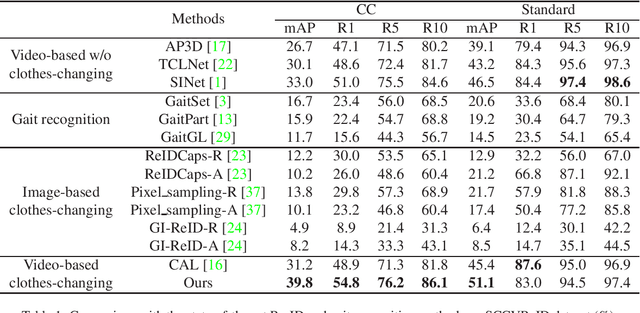
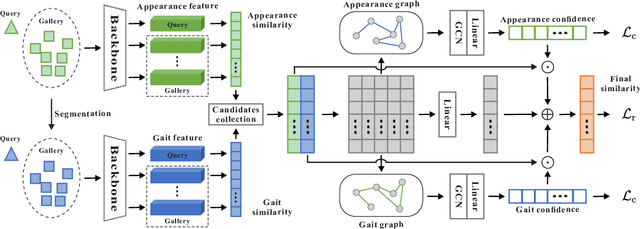
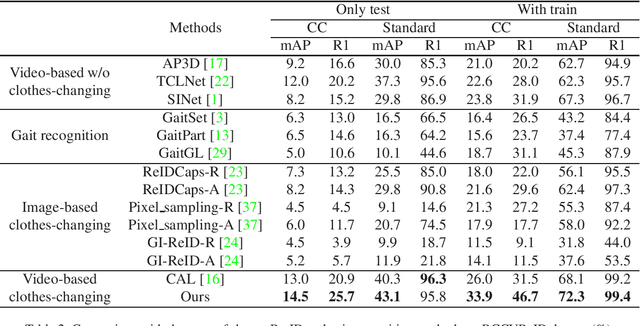
Person re-identification (Re-ID) is a classical computer vision task and has achieved great progress so far. Recently, long-term Re-ID with clothes-changing has attracted increasing attention. However, existing methods mainly focus on image-based setting, where richer temporal information is overlooked. In this paper, we focus on the relatively new yet practical problem of clothes-changing video-based person re-identification (CCVReID), which is less studied. We systematically study this problem by simultaneously considering the challenge of the clothes inconsistency issue and the temporal information contained in the video sequence for the person Re-ID problem. Based on this, we develop a two-branch confidence-aware re-ranking framework for handling the CCVReID problem. The proposed framework integrates two branches that consider both the classical appearance features and cloth-free gait features through a confidence-guided re-ranking strategy. This method provides the baseline method for further studies. Also, we build two new benchmark datasets for CCVReID problem, including a large-scale synthetic video dataset and a real-world one, both containing human sequences with various clothing changes. We will release the benchmark and code in this work to the public.
A Policy-based Approach to the SpecAugment Method for Low Resource E2E ASR
Oct 16, 2022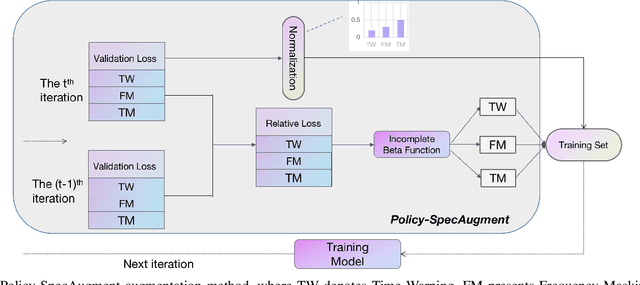
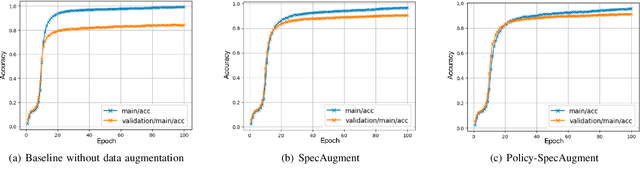
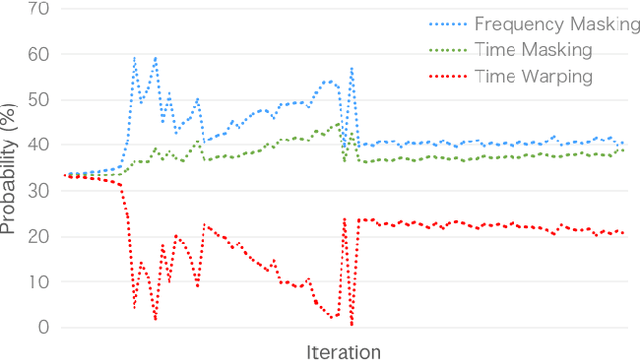
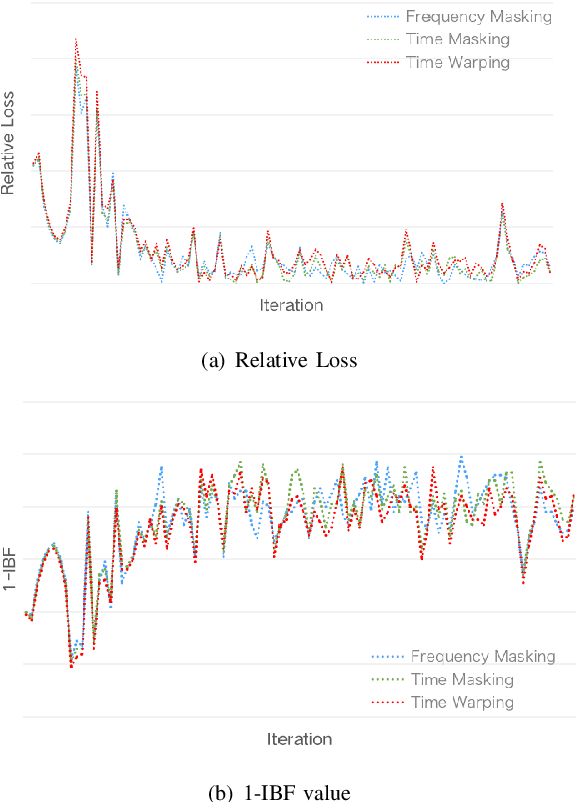
SpecAugment is a very effective data augmentation method for both HMM and E2E-based automatic speech recognition (ASR) systems. Especially, it also works in low-resource scenarios. However, SpecAugment masks the spectrum of time or the frequency domain in a fixed augmentation policy, which may bring relatively less data diversity to the low-resource ASR. In this paper, we propose a policy-based SpecAugment (Policy-SpecAugment) method to alleviate the above problem. The idea is to use the augmentation-select policy and the augmentation-parameter changing policy to solve the fixed way. These policies are learned based on the loss of validation set, which is applied to the corresponding augmentation policies. It aims to encourage the model to learn more diverse data, which the model relatively requires. In experiments, we evaluate the effectiveness of our approach in low-resource scenarios, i.e., the 100 hours librispeech task. According to the results and analysis, we can see that the above issue can be obviously alleviated using our proposal. In addition, the experimental results show that, compared with the state-of-the-art SpecAugment, the proposed Policy-SpecAugment has a relative WER reduction of more than 10% on the Test/Dev-clean set, more than 5% on the Test/Dev-other set, and an absolute WER reduction of more than 1% on all test sets.
CAMO-MOT: Combined Appearance-Motion Optimization for 3D Multi-Object Tracking with Camera-LiDAR Fusion
Sep 12, 2022
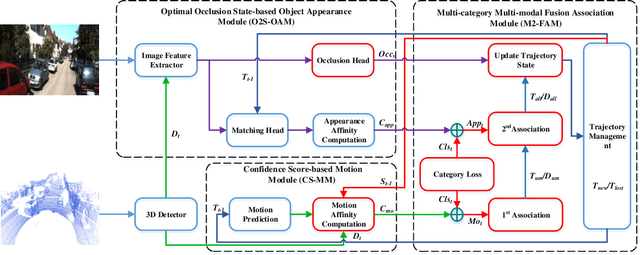
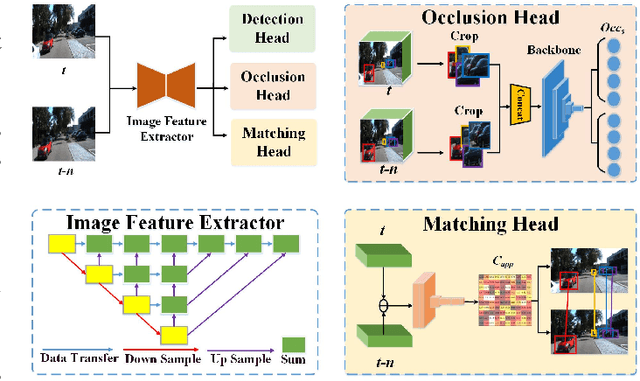
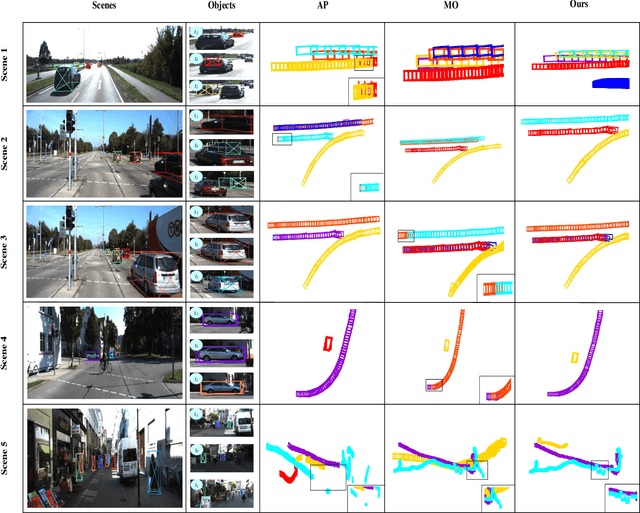
3D Multi-object tracking (MOT) ensures consistency during continuous dynamic detection, conducive to subsequent motion planning and navigation tasks in autonomous driving. However, camera-based methods suffer in the case of occlusions and it can be challenging to accurately track the irregular motion of objects for LiDAR-based methods. Some fusion methods work well but do not consider the untrustworthy issue of appearance features under occlusion. At the same time, the false detection problem also significantly affects tracking. As such, we propose a novel camera-LiDAR fusion 3D MOT framework based on the Combined Appearance-Motion Optimization (CAMO-MOT), which uses both camera and LiDAR data and significantly reduces tracking failures caused by occlusion and false detection. For occlusion problems, we are the first to propose an occlusion head to select the best object appearance features multiple times effectively, reducing the influence of occlusions. To decrease the impact of false detection in tracking, we design a motion cost matrix based on confidence scores which improve the positioning and object prediction accuracy in 3D space. As existing multi-object tracking methods only consider a single category, we also propose to build a multi-category loss to implement multi-object tracking in multi-category scenes. A series of validation experiments are conducted on the KITTI and nuScenes tracking benchmarks. Our proposed method achieves state-of-the-art performance and the lowest identity switches (IDS) value (23 for Car and 137 for Pedestrian) among all multi-modal MOT methods on the KITTI test dataset. And our proposed method achieves state-of-the-art performance among all algorithms on the nuScenes test dataset with 75.3% AMOTA.
FDNeRF: Few-shot Dynamic Neural Radiance Fields for Face Reconstruction and Expression Editing
Aug 11, 2022
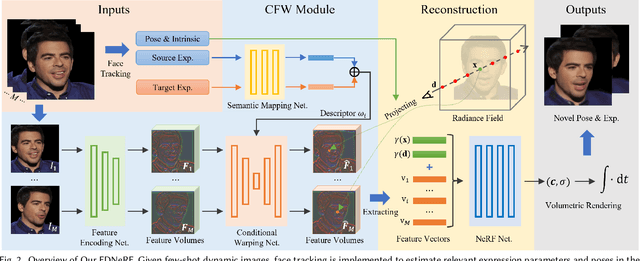

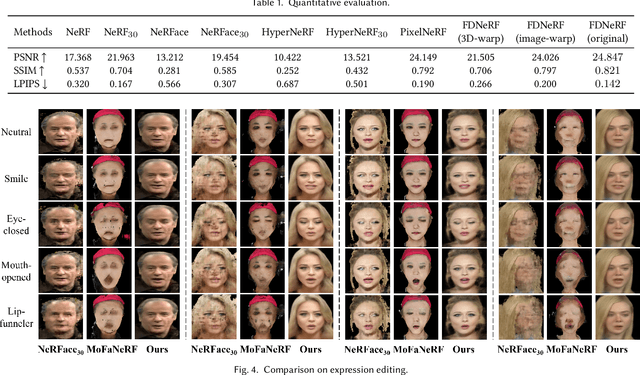
We propose a Few-shot Dynamic Neural Radiance Field (FDNeRF), the first NeRF-based method capable of reconstruction and expression editing of 3D faces based on a small number of dynamic images. Unlike existing dynamic NeRFs that require dense images as input and can only be modeled for a single identity, our method enables face reconstruction across different persons with few-shot inputs. Compared to state-of-the-art few-shot NeRFs designed for modeling static scenes, the proposed FDNeRF accepts view-inconsistent dynamic inputs and supports arbitrary facial expression editing, i.e., producing faces with novel expressions beyond the input ones. To handle the inconsistencies between dynamic inputs, we introduce a well-designed conditional feature warping (CFW) module to perform expression conditioned warping in 2D feature space, which is also identity adaptive and 3D constrained. As a result, features of different expressions are transformed into the target ones. We then construct a radiance field based on these view-consistent features and use volumetric rendering to synthesize novel views of the modeled faces. Extensive experiments with quantitative and qualitative evaluation demonstrate that our method outperforms existing dynamic and few-shot NeRFs on both 3D face reconstruction and expression editing tasks. Our code and model will be available upon acceptance.
Formal guarantees for heuristic optimization algorithms used in machine learning
Jul 31, 2022
Recently, Stochastic Gradient Descent (SGD) and its variants have become the dominant methods in the large-scale optimization of machine learning (ML) problems. A variety of strategies have been proposed for tuning the step sizes, ranging from adaptive step sizes to heuristic methods to change the step size in each iteration. Also, momentum has been widely employed in ML tasks to accelerate the training process. Yet, there is a gap in our theoretical understanding of them. In this work, we start to close this gap by providing formal guarantees to a few heuristic optimization methods and proposing improved algorithms. First, we analyze a generalized version of the AdaGrad (Delayed AdaGrad) step sizes in both convex and non-convex settings, showing that these step sizes allow the algorithms to automatically adapt to the level of noise of the stochastic gradients. We show for the first time sufficient conditions for Delayed AdaGrad to achieve almost sure convergence of the gradients to zero. Moreover, we present a high probability analysis for Delayed AdaGrad and its momentum variant in the non-convex setting. Second, we analyze SGD with exponential and cosine step sizes, which are empirically successful but lack theoretical support. We provide the very first convergence guarantees for them in the smooth and non-convex setting, with and without the Polyak-{\L}ojasiewicz (PL) condition. We also show their good property of adaptivity to noise under the PL condition. Third, we study the last iterate of momentum methods. We prove the first lower bound in the convex setting for the last iterate of SGD with constant momentum. Moreover, we investigate a class of Follow-The-Regularized-Leader-based momentum algorithms with increasing momentum and shrinking updates. We show that their last iterate has optimal convergence for unconstrained convex stochastic optimization problems.
Neural Parameterization for Dynamic Human Head Editing
Jul 01, 2022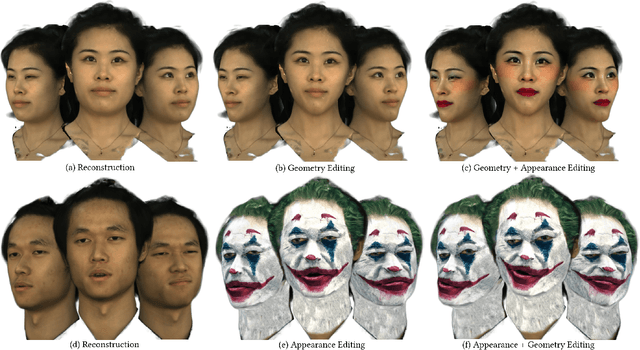

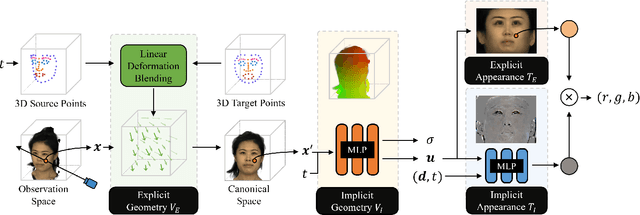

Implicit radiance functions emerged as a powerful scene representation for reconstructing and rendering photo-realistic views of a 3D scene. These representations, however, suffer from poor editability. On the other hand, explicit representations such as polygonal meshes allow easy editing but are not as suitable for reconstructing accurate details in dynamic human heads, such as fine facial features, hair, teeth, and eyes. In this work, we present Neural Parameterization (NeP), a hybrid representation that provides the advantages of both implicit and explicit methods. NeP is capable of photo-realistic rendering while allowing fine-grained editing of the scene geometry and appearance. We first disentangle the geometry and appearance by parameterizing the 3D geometry into 2D texture space. We enable geometric editability by introducing an explicit linear deformation blending layer. The deformation is controlled by a set of sparse key points, which can be explicitly and intuitively displaced to edit the geometry. For appearance, we develop a hybrid 2D texture consisting of an explicit texture map for easy editing and implicit view and time-dependent residuals to model temporal and view variations. We compare our method to several reconstruction and editing baselines. The results show that the NeP achieves almost the same level of rendering accuracy while maintaining high editability.
UV Volumes for Real-time Rendering of Editable Free-view Human Performance
Mar 27, 2022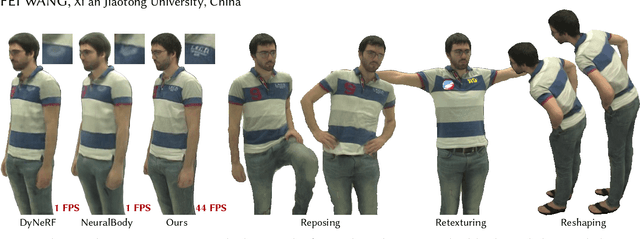
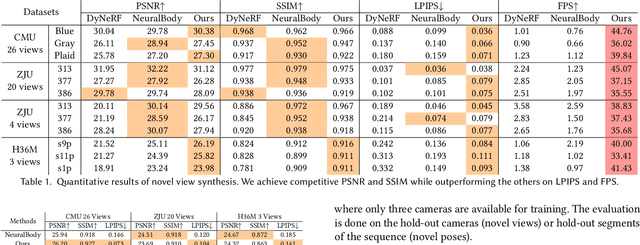
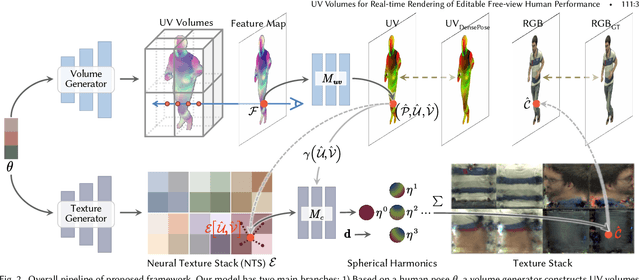

Neural volume rendering has been proven to be a promising method for efficient and photo-realistic rendering of a human performer in free-view, a critical task in many immersive VR/AR applications. However, existing approaches are severely limited by their high computational cost in the rendering process. To solve this problem, we propose the UV Volumes, an approach that can render an editable free-view video of a human performer in real-time. It is achieved by removing the high-frequency (i.e., non-smooth) human textures from the 3D volume and encoding them into a 2D neural texture stack (NTS). The smooth UV volume allows us to employ a much smaller and shallower structure for 3D CNN and MLP, to obtain the density and texture coordinates without losing image details. Meanwhile, the NTS only needs to be queried once for each pixel in the UV image to retrieve its RGB value. For editability, the 3D CNN and MLP decoder can easily fit the function that maps the input structured-and-posed latent codes to the relatively smooth densities and texture coordinates. It gives our model a better generalization ability to handle novel poses and shapes. Furthermore, the use of NST enables new applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 900 * 500 images in 40 fps on average with comparable photorealism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes.
Hallucinated Neural Radiance Fields in the Wild
Dec 01, 2021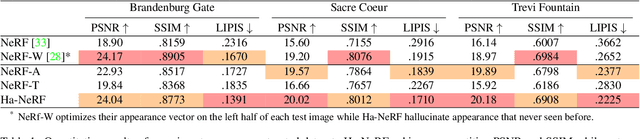
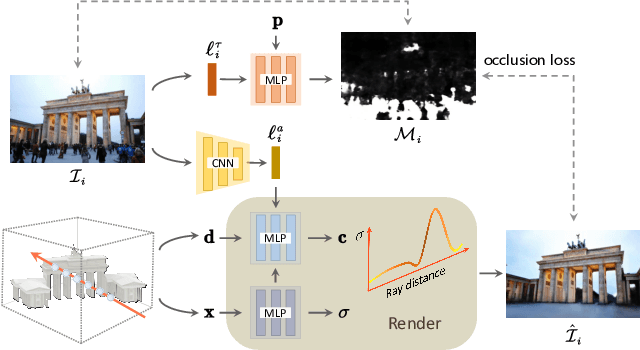
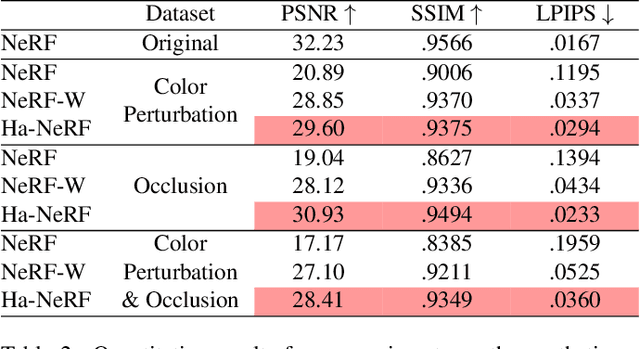
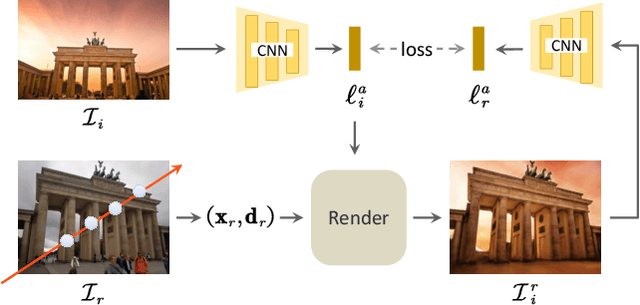
Neural Radiance Fields (NeRF) has recently gained popularity for its impressive novel view synthesis ability. This paper studies the problem of hallucinated NeRF: i.e. recovering a realistic NeRF at a different time of day from a group of tourism images. Existing solutions adopt NeRF with a controllable appearance embedding to render novel views under various conditions, but cannot render view-consistent images with an unseen appearance. To solve this problem, we present an end-to-end framework for constructing a hallucinated NeRF, dubbed as Ha-NeRF. Specifically, we propose an appearance hallucination module to handle time-varying appearances and transfer them to novel views. Considering the complex occlusions of tourism images, an anti-occlusion module is introduced to decompose the static subjects for visibility accurately. Experimental results on synthetic data and real tourism photo collections demonstrate that our method can not only hallucinate the desired appearances, but also render occlusion-free images from different views. The project and supplementary materials are available at https://rover-xingyu.github.io/Ha-NeRF/.
FENeRF: Face Editing in Neural Radiance Fields
Nov 30, 2021
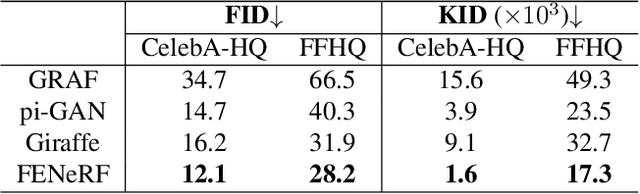
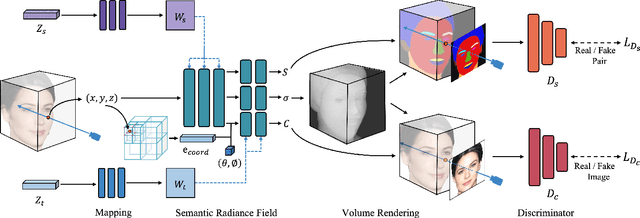

Previous portrait image generation methods roughly fall into two categories: 2D GANs and 3D-aware GANs. 2D GANs can generate high fidelity portraits but with low view consistency. 3D-aware GAN methods can maintain view consistency but their generated images are not locally editable. To overcome these limitations, we propose FENeRF, a 3D-aware generator that can produce view-consistent and locally-editable portrait images. Our method uses two decoupled latent codes to generate corresponding facial semantics and texture in a spatial aligned 3D volume with shared geometry. Benefiting from such underlying 3D representation, FENeRF can jointly render the boundary-aligned image and semantic mask and use the semantic mask to edit the 3D volume via GAN inversion. We further show such 3D representation can be learned from widely available monocular image and semantic mask pairs. Moreover, we reveal that joint learning semantics and texture helps to generate finer geometry. Our experiments demonstrate that FENeRF outperforms state-of-the-art methods in various face editing tasks.
Deblur-NeRF: Neural Radiance Fields from Blurry Images
Nov 29, 2021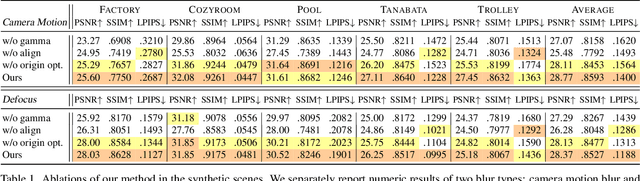
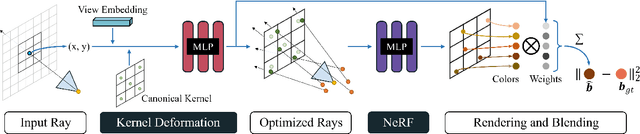
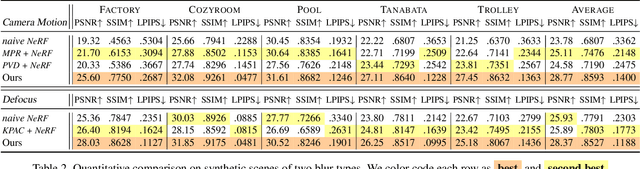
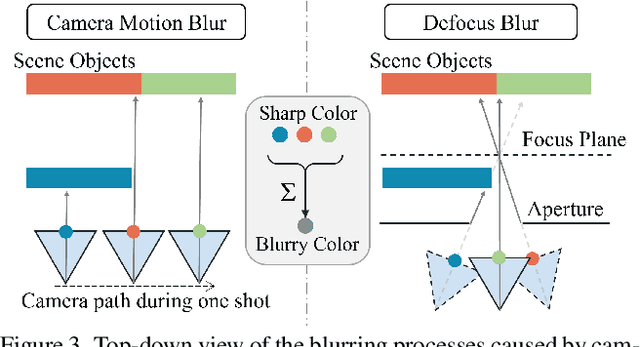
Neural Radiance Field (NeRF) has gained considerable attention recently for 3D scene reconstruction and novel view synthesis due to its remarkable synthesis quality. However, image blurriness caused by defocus or motion, which often occurs when capturing scenes in the wild, significantly degrades its reconstruction quality. To address this problem, We propose Deblur-NeRF, the first method that can recover a sharp NeRF from blurry input. We adopt an analysis-by-synthesis approach that reconstructs blurry views by simulating the blurring process, thus making NeRF robust to blurry inputs. The core of this simulation is a novel Deformable Sparse Kernel (DSK) module that models spatially-varying blur kernels by deforming a canonical sparse kernel at each spatial location. The ray origin of each kernel point is jointly optimized, inspired by the physical blurring process. This module is parameterized as an MLP that has the ability to be generalized to various blur types. Jointly optimizing the NeRF and the DSK module allows us to restore a sharp NeRF. We demonstrate that our method can be used on both camera motion blur and defocus blur: the two most common types of blur in real scenes. Evaluation results on both synthetic and real-world data show that our method outperforms several baselines. The synthetic and real datasets along with the source code will be made publicly available to facilitate future research.