 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyang Wang
SFC: Shared Feature Calibration in Weakly Supervised Semantic Segmentation
Jan 22, 2024
Image-level weakly supervised semantic segmentation has received increasing attention due to its low annotation cost. Existing methods mainly rely on Class Activation Mapping (CAM) to obtain pseudo-labels for training semantic segmentation models. In this work, we are the first to demonstrate that long-tailed distribution in training data can cause the CAM calculated through classifier weights over-activated for head classes and under-activated for tail classes due to the shared features among head- and tail- classes. This degrades pseudo-label quality and further influences final semantic segmentation performance. To address this issue, we propose a Shared Feature Calibration (SFC) method for CAM generation. Specifically, we leverage the class prototypes that carry positive shared features and propose a Multi-Scaled Distribution-Weighted (MSDW) consistency loss for narrowing the gap between the CAMs generated through classifier weights and class prototypes during training. The MSDW loss counterbalances over-activation and under-activation by calibrating the shared features in head-/tail-class classifier weights. Experimental results show that our SFC significantly improves CAM boundaries and achieves new state-of-the-art performances. The project is available at https://github.com/Barrett-python/SFC.
InFoBench: Evaluating Instruction Following Ability in Large Language Models
Jan 07, 2024This paper introduces the Decomposed Requirements Following Ratio (DRFR), a new metric for evaluating Large Language Models' (LLMs) ability to follow instructions. Addressing a gap in current methodologies, DRFR breaks down complex instructions into simpler criteria, facilitating a detailed analysis of LLMs' compliance with various aspects of tasks. Alongside this metric, we present InFoBench, a benchmark comprising 500 diverse instructions and 2,250 decomposed questions across multiple constraint categories. Our experiments compare DRFR with traditional scoring methods and explore annotation sources, including human experts, crowd-sourced workers, and GPT-4. The findings demonstrate DRFR's higher reliability and the effectiveness of using GPT-4 as a cost-efficient annotator. The evaluation of several advanced LLMs using this framework reveals their strengths and areas needing improvement, particularly in complex instruction-following. This study contributes a novel metric and benchmark, offering insights for future LLM development and evaluation.
Zebra: Extending Context Window with Layerwise Grouped Local-Global Attention
Dec 14, 2023This paper introduces a novel approach to enhance the capabilities of Large Language Models (LLMs) in processing and understanding extensive text sequences, a critical aspect in applications requiring deep comprehension and synthesis of large volumes of information. Recognizing the inherent challenges in extending the context window for LLMs, primarily built on Transformer architecture, we propose a new model architecture, referred to as Zebra. This architecture efficiently manages the quadratic time and memory complexity issues associated with full attention in the Transformer by employing grouped local-global attention layers. Our model, akin to a zebra's alternating stripes, balances local and global attention layers, significantly reducing computational requirements and memory consumption. Comprehensive experiments, including pretraining from scratch, continuation of long context adaptation training, and long instruction tuning, are conducted to evaluate the Zebra's performance. The results show that Zebra achieves comparable or superior performance on both short and long sequence benchmarks, while also enhancing training and inference efficiency.
MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning
Nov 15, 2023With the rapid development of large language models (LLMs) and their integration into large multimodal models (LMMs), there has been impressive progress in zero-shot completion of user-oriented vision-language tasks. However, a gap remains in the domain of chart image understanding due to the distinct abstract components in charts. To address this, we introduce a large-scale MultiModal Chart Instruction (MMC-Instruction) dataset comprising 600k instances supporting diverse tasks and chart types. Leveraging this data, we develop MultiModal Chart Assistant (MMCA), an LMM that achieves state-of-the-art performance on existing chart QA benchmarks. Recognizing the need for a comprehensive evaluation of LMM chart understanding, we also propose a MultiModal Chart Benchmark (MMC-Benchmark), a comprehensive human-annotated benchmark with 9 distinct tasks evaluating reasoning capabilities over charts. Extensive experiments on MMC-Benchmark reveal the limitations of existing LMMs on correctly interpreting charts, even for the most recent GPT-4V model. Our work provides an instruction-tuning methodology and benchmark to advance multimodal understanding of charts.
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Sep 30, 2023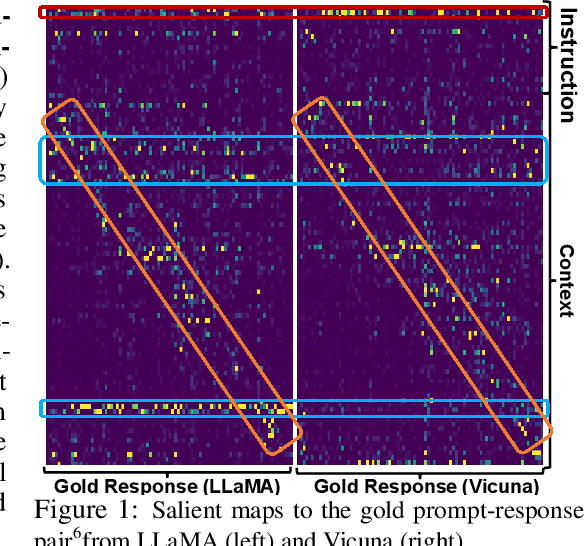
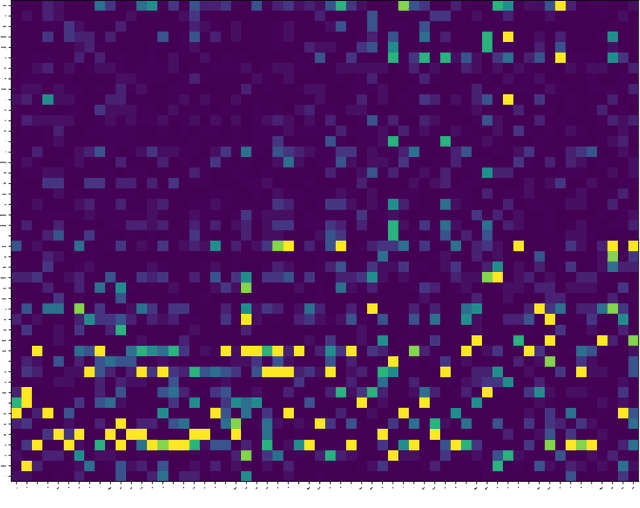
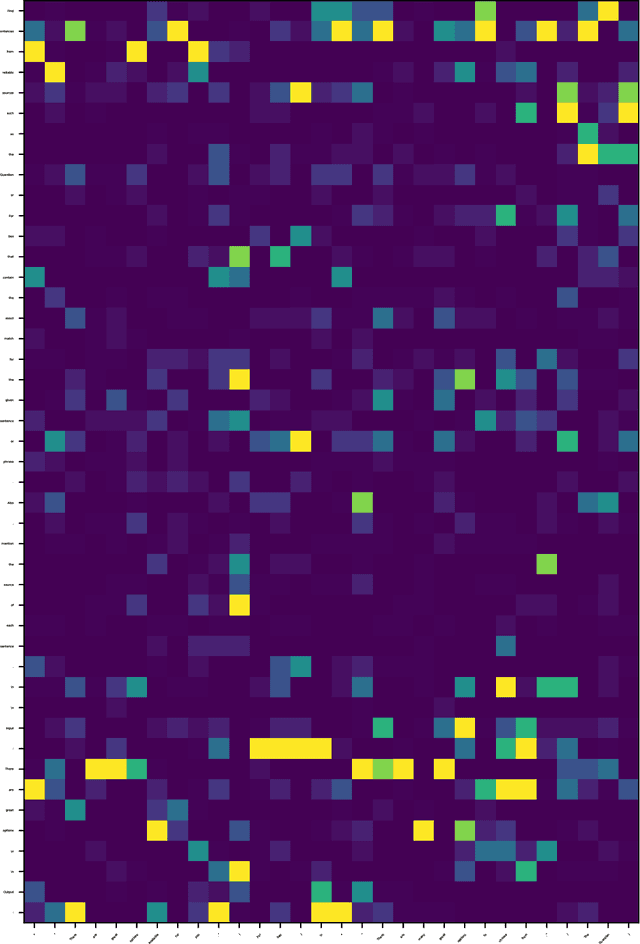

Large Language Models (LLMs) have achieved remarkable success, demonstrating powerful instruction-following capabilities across diverse tasks. Instruction fine-tuning is critical in enabling LLMs to align with user intentions and effectively follow instructions. In this work, we investigate how instruction fine-tuning modifies pre-trained models, focusing on two perspectives: instruction recognition and knowledge evolution. To study the behavior shift of LLMs, we employ a suite of local and global explanation methods, including a gradient-based approach for input-output attribution and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. Our findings reveal three significant impacts of instruction fine-tuning: 1) It empowers LLMs to better recognize the instruction parts from user prompts, thereby facilitating high-quality response generation and addressing the ``lost-in-the-middle'' issue observed in pre-trained models; 2) It aligns the knowledge stored in feed-forward layers with user-oriented tasks, exhibiting minimal shifts across linguistic levels. 3) It facilitates the learning of word-word relations with instruction verbs through the self-attention mechanism, particularly in the lower and middle layers, indicating enhanced recognition of instruction words. These insights contribute to a deeper understanding of the behavior shifts in LLMs after instruction fine-tuning and lay the groundwork for future research aimed at interpreting and optimizing LLMs for various applications. We will release our code and data soon.
Unsupervised Multi-document Summarization with Holistic Inference
Sep 08, 2023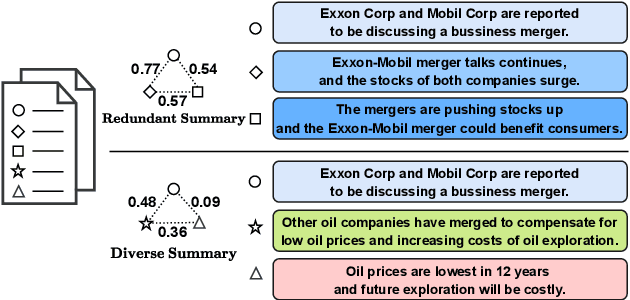

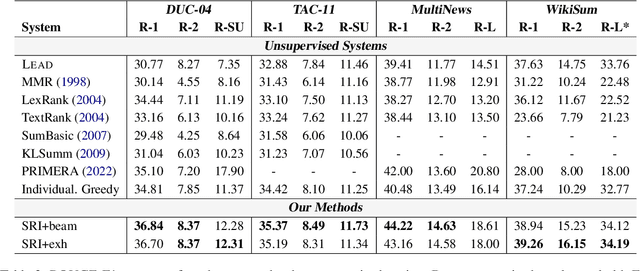
Multi-document summarization aims to obtain core information from a collection of documents written on the same topic. This paper proposes a new holistic framework for unsupervised multi-document extractive summarization. Our method incorporates the holistic beam search inference method associated with the holistic measurements, named Subset Representative Index (SRI). SRI balances the importance and diversity of a subset of sentences from the source documents and can be calculated in unsupervised and adaptive manners. To demonstrate the effectiveness of our method, we conduct extensive experiments on both small and large-scale multi-document summarization datasets under both unsupervised and adaptive settings. The proposed method outperforms strong baselines by a significant margin, as indicated by the resulting ROUGE scores and diversity measures. Our findings also suggest that diversity is essential for improving multi-document summary performance.
Skills-in-Context Prompting: Unlocking Compositionality in Large Language Models
Aug 14, 2023
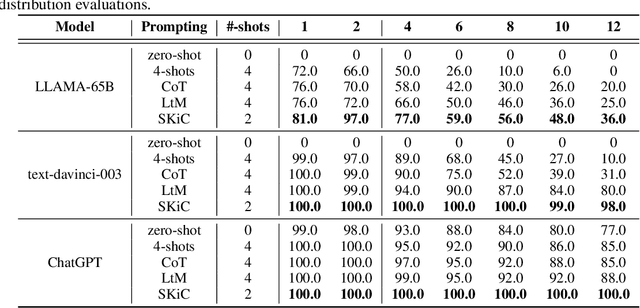
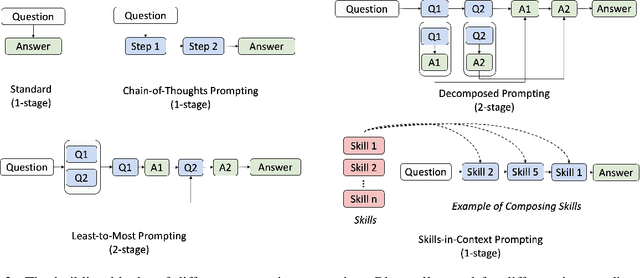
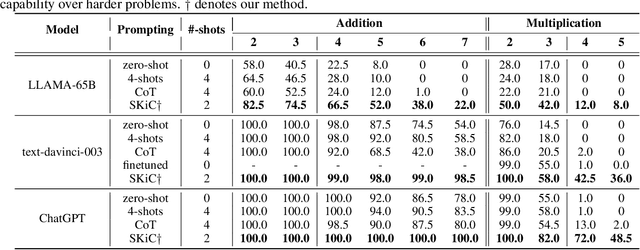
We consider the problem of eliciting compositional generalization capabilities in large language models (LLMs) with a novel type of prompting strategy. Compositional generalization empowers the LLMs to solve problems that are harder than the ones they have seen (i.e., easy-to-hard generalization), which is a critical reasoning capability of human-like intelligence. However, even the current state-of-the-art LLMs still struggle with this form of reasoning. To bridge this gap, we propose skills-in-context (SKiC) prompting, which instructs LLMs how to compose basic skills to resolve more complex problems. We find that it is crucial to demonstrate both the skills and the compositional examples within the same prompting context. With as few as two examplars, our SKiC prompting initiates strong synergies between skills and their composition capabilities. Notably, it empowers LLMs to solve unseen problems that require innovative skill compositions, achieving near-perfect generalization on a broad range of challenging compositionality tasks. Intriguingly, SKiC prompting unlocks the latent potential of LLMs, enabling them to leverage pre-existing internal skills acquired during earlier pre-training stages, even when these skills are not explicitly presented in the prompting context. This results in the capability of LLMs to solve unseen complex problems by activating and composing internal competencies. With such prominent features, SKiC prompting is able to achieve state-of-the-art performance on challenging mathematical reasoning benchmarks (e.g., MATH).
FedMLSecurity: A Benchmark for Attacks and Defenses in Federated Learning and LLMs
Jun 08, 2023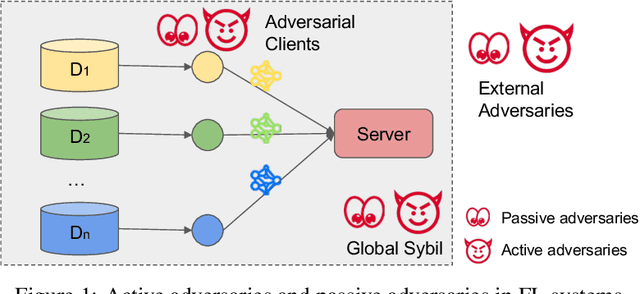

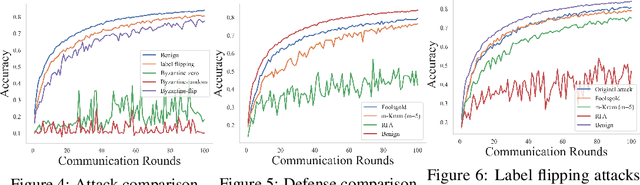
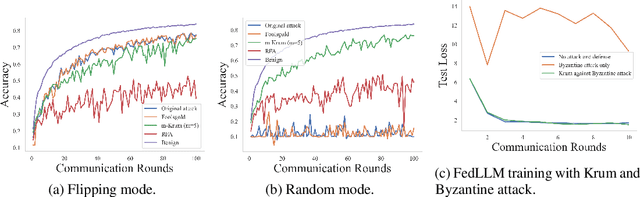
This paper introduces FedMLSecurity, a benchmark that simulates adversarial attacks and corresponding defense mechanisms in Federated Learning (FL). As an integral module of the open-sourced library FedML that facilitates FL algorithm development and performance comparison, FedMLSecurity enhances the security assessment capacity of FedML. FedMLSecurity comprises two principal components: FedMLAttacker, which simulates attacks injected into FL training, and FedMLDefender, which emulates defensive strategies designed to mitigate the impacts of the attacks. FedMLSecurity is open-sourced 1 and is customizable to a wide range of machine learning models (e.g., Logistic Regression, ResNet, GAN, etc.) and federated optimizers (e.g., FedAVG, FedOPT, FedNOVA, etc.). Experimental evaluations in this paper also demonstrate the ease of application of FedMLSecurity to Large Language Models (LLMs), further reinforcing its versatility and practical utility in various scenarios.
Pretrained Language Model based Web Search Ranking: From Relevance to Satisfaction
Jun 02, 2023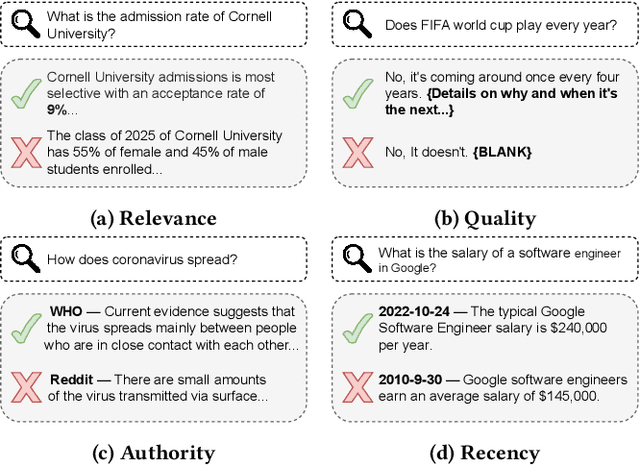

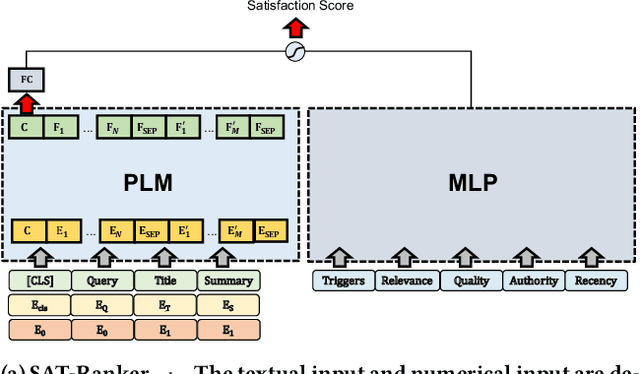
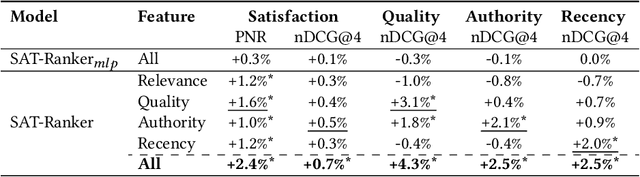
Search engine plays a crucial role in satisfying users' diverse information needs. Recently, Pretrained Language Models (PLMs) based text ranking models have achieved huge success in web search. However, many state-of-the-art text ranking approaches only focus on core relevance while ignoring other dimensions that contribute to user satisfaction, e.g., document quality, recency, authority, etc. In this work, we focus on ranking user satisfaction rather than relevance in web search, and propose a PLM-based framework, namely SAT-Ranker, which comprehensively models different dimensions of user satisfaction in a unified manner. In particular, we leverage the capacities of PLMs on both textual and numerical inputs, and apply a multi-field input that modularizes each dimension of user satisfaction as an input field. Overall, SAT-Ranker is an effective, extensible, and data-centric framework that has huge potential for industrial applications. On rigorous offline and online experiments, SAT-Ranker obtains remarkable gains on various evaluation sets targeting different dimensions of user satisfaction. It is now fully deployed online to improve the usability of our search engine.