 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoxiao Li
FL-NTK: A Neural Tangent Kernel-based Framework for Federated Learning Convergence Analysis
May 11, 2021
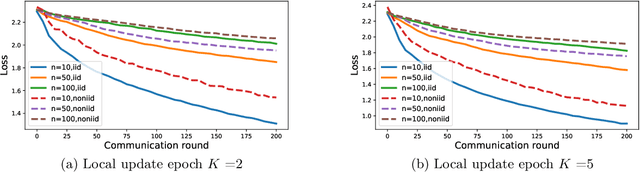
Federated Learning (FL) is an emerging learning scheme that allows different distributed clients to train deep neural networks together without data sharing. Neural networks have become popular due to their unprecedented success. To the best of our knowledge, the theoretical guarantees of FL concerning neural networks with explicit forms and multi-step updates are unexplored. Nevertheless, training analysis of neural networks in FL is non-trivial for two reasons: first, the objective loss function we are optimizing is non-smooth and non-convex, and second, we are even not updating in the gradient direction. Existing convergence results for gradient descent-based methods heavily rely on the fact that the gradient direction is used for updating. This paper presents a new class of convergence analysis for FL, Federated Learning Neural Tangent Kernel (FL-NTK), which corresponds to overparamterized ReLU neural networks trained by gradient descent in FL and is inspired by the analysis in Neural Tangent Kernel (NTK). Theoretically, FL-NTK converges to a global-optimal solution at a linear rate with properly tuned learning parameters. Furthermore, with proper distributional assumptions, FL-NTK can also achieve good generalization.
Demographic-Guided Attention in Recurrent Neural Networks for Modeling Neuropathophysiological Heterogeneity
Apr 15, 2021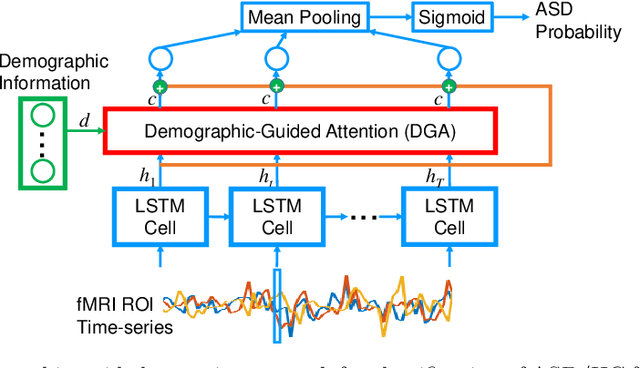
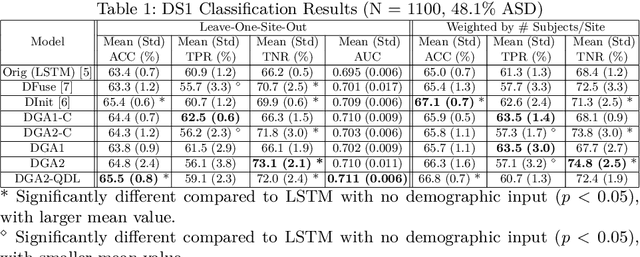
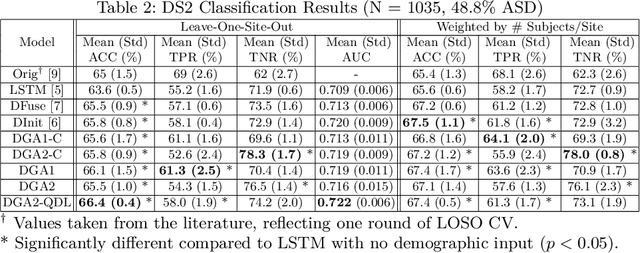
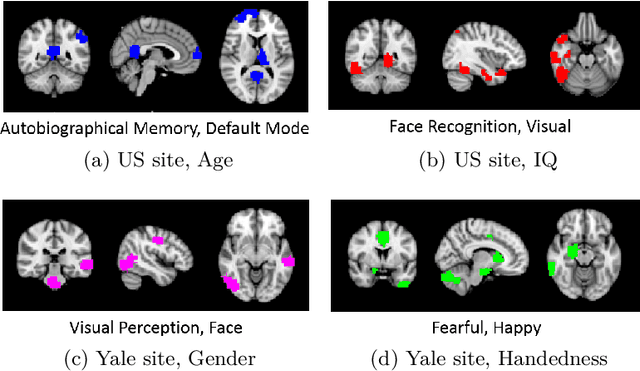
Heterogeneous presentation of a neurological disorder suggests potential differences in the underlying pathophysiological changes that occur in the brain. We propose to model heterogeneous patterns of functional network differences using a demographic-guided attention (DGA) mechanism for recurrent neural network models for prediction from functional magnetic resonance imaging (fMRI) time-series data. The context computed from the DGA head is used to help focus on the appropriate functional networks based on individual demographic information. We demonstrate improved classification on 3 subsets of the ABIDE I dataset used in published studies that have previously produced state-of-the-art results, evaluating performance under a leave-one-site-out cross-validation framework for better generalizeability to new data. Finally, we provide examples of interpreting functional network differences based on individual demographic variables.
Estimating and Improving Fairness with Adversarial Learning
Mar 07, 2021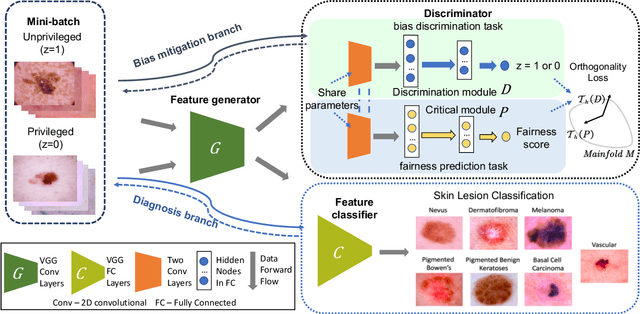
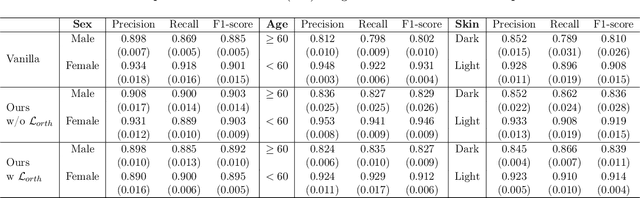
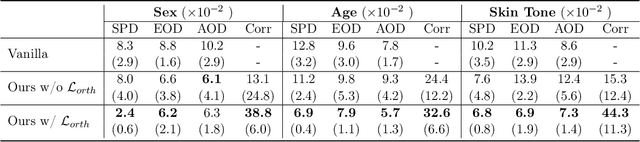
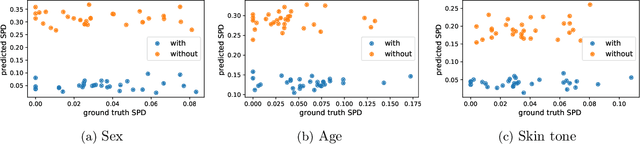
Fairness and accountability are two essential pillars for trustworthy Artificial Intelligence (AI) in healthcare. However, the existing AI model may be biased in its decision marking. To tackle this issue, we propose an adversarial multi-task training strategy to simultaneously mitigate and detect bias in the deep learning-based medical image analysis system. Specifically, we propose to add a discrimination module against bias and a critical module that predicts unfairness within the base classification model. We further impose an orthogonality regularization to force the two modules to be independent during training. Hence, we can keep these deep learning tasks distinct from one another, and avoid collapsing them into a singular point on the manifold. Through this adversarial training method, the data from the underprivileged group, which is vulnerable to bias because of attributes such as sex and skin tone, are transferred into a domain that is neutral relative to these attributes. Furthermore, the critical module can predict fairness scores for the data with unknown sensitive attributes. We evaluate our framework on a large-scale public-available skin lesion dataset under various fairness evaluation metrics. The experiments demonstrate the effectiveness of our proposed method for estimating and improving fairness in the deep learning-based medical image analysis system.
FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
Feb 15, 2021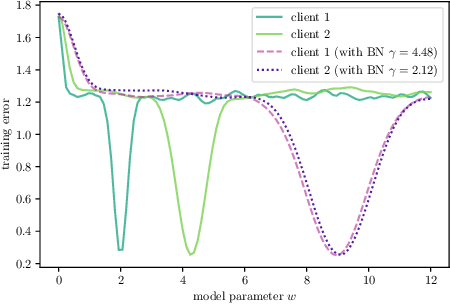
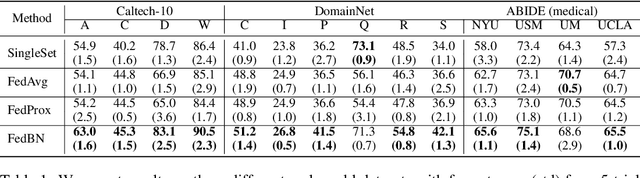
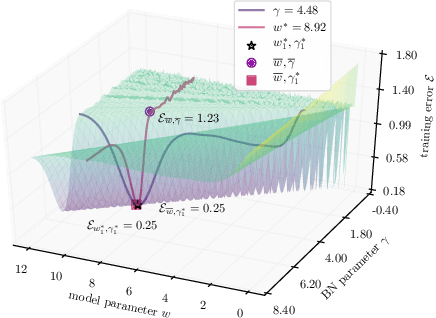

The emerging paradigm of federated learning (FL) strives to enable collaborative training of deep models on the network edge without centrally aggregating raw data and hence improving data privacy. In most cases, the assumption of independent and identically distributed samples across local clients does not hold for federated learning setups. Under this setting, neural network training performance may vary significantly according to the data distribution and even hurt training convergence. Most of the previous work has focused on a difference in the distribution of labels or client shifts. Unlike those settings, we address an important problem of FL, e.g., different scanners/sensors in medical imaging, different scenery distribution in autonomous driving (highway vs. city), where local clients store examples with different distributions compared to other clients, which we denote as feature shift non-iid. In this work, we propose an effective method that uses local batch normalization to alleviate the feature shift before averaging models. The resulting scheme, called FedBN, outperforms both classical FedAvg, as well as the state-of-the-art for non-iid data (FedProx) on our extensive experiments. These empirical results are supported by a convergence analysis that shows in a simplified setting that FedBN has a faster convergence rate than FedAvg. Code is available at https://github.com/med-air/FedBN.
Automating Document Classification with Distant Supervision to Increase the Efficiency of Systematic Reviews
Dec 09, 2020
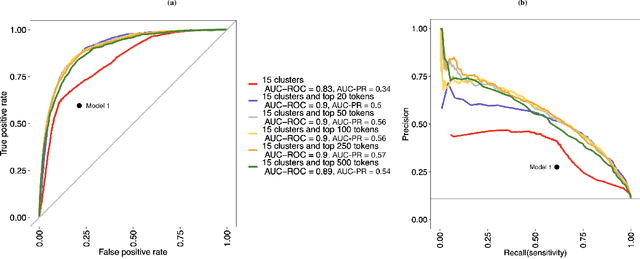
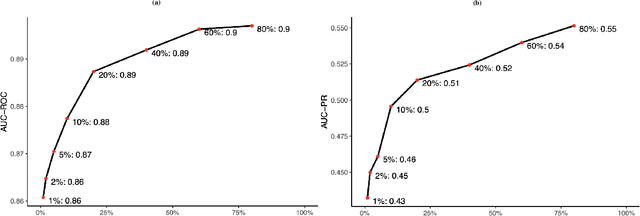
Objective: Systematic reviews of scholarly documents often provide complete and exhaustive summaries of literature relevant to a research question. However, well-done systematic reviews are expensive, time-demanding, and labor-intensive. Here, we propose an automatic document classification approach to significantly reduce the effort in reviewing documents. Methods: We first describe a manual document classification procedure that is used to curate a pertinent training dataset and then propose three classifiers: a keyword-guided method, a cluster analysis-based refined method, and a random forest approach that utilizes a large set of feature tokens. As an example, this approach is used to identify documents studying female sex workers that are assumed to contain content relevant to either HIV or violence. We compare the performance of the three classifiers by cross-validation and conduct a sensitivity analysis on the portion of data utilized in training the model. Results: The random forest approach provides the highest area under the curve (AUC) for both receiver operating characteristic (ROC) and precision/recall (PR). Analyses of precision and recall suggest that random forest could facilitate manually reviewing 20\% of the articles while containing 80\% of the relevant cases. Finally, we found a good classifier could be obtained by using a relatively small training sample size. Conclusions: In sum, the automated procedure of document classification presented here could improve both the precision and efficiency of systematic reviews, as well as facilitating live reviews, where reviews are updated regularly.
MixCon: Adjusting the Separability of Data Representations for Harder Data Recovery
Oct 22, 2020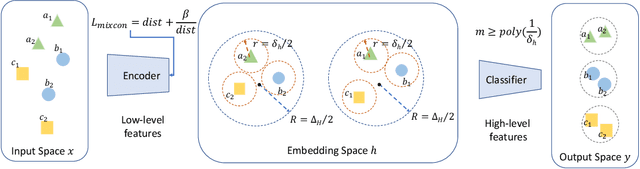

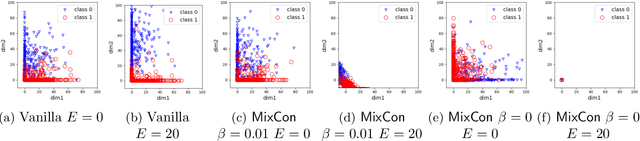

To address the issue that deep neural networks (DNNs) are vulnerable to model inversion attacks, we design an objective function, which adjusts the separability of the hidden data representations, as a way to control the trade-off between data utility and vulnerability to inversion attacks. Our method is motivated by the theoretical insights of data separability in neural networking training and results on the hardness of model inversion. Empirically, by adjusting the separability of data representation, we show that there exist sweet-spots for data separability such that it is difficult to recover data during inference while maintaining data utility.
Texture Memory-Augmented Deep Patch-Based Image Inpainting
Sep 28, 2020



Patch-based methods and deep networks have been employed to tackle image inpainting problem, with their own strengths and weaknesses. Patch-based methods are capable of restoring a missing region with high-quality texture through searching nearest neighbor patches from the unmasked regions. However, these methods bring problematic contents when recovering large missing regions. Deep networks, on the other hand, show promising results in completing large regions. Nonetheless, the results often lack faithful and sharp details that resemble the surrounding area. By bringing together the best of both paradigms, we propose a new deep inpainting framework where texture generation is guided by a texture memory of patch samples extracted from unmasked regions. The framework has a novel design that allows texture memory retrieval to be trained end-to-end with the deep inpainting network. In addition, we introduce a patch distribution loss to encourage high-quality patch synthesis. The proposed method shows superior performance both qualitatively and quantitatively on three challenging image benchmarks, i.e., Places, CelebA-HQ, and Paris Street-View datasets.
Pooling Regularized Graph Neural Network for fMRI Biomarker Analysis
Jul 29, 2020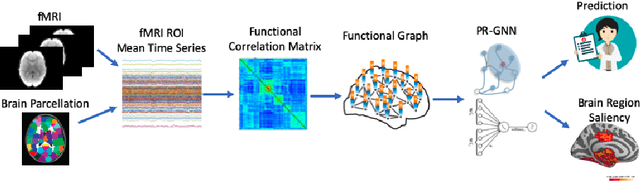

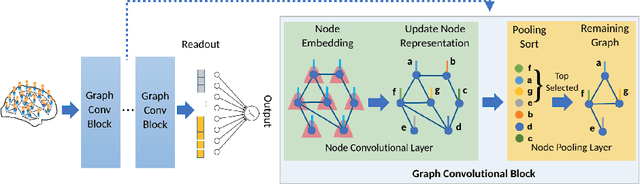

Understanding how certain brain regions relate to a specific neurological disorder has been an important area of neuroimaging research. A promising approach to identify the salient regions is using Graph Neural Networks (GNNs), which can be used to analyze graph structured data, e.g. brain networks constructed by functional magnetic resonance imaging (fMRI). We propose an interpretable GNN framework with a novel salient region selection mechanism to determine neurological brain biomarkers associated with disorders. Specifically, we design novel regularized pooling layers that highlight salient regions of interests (ROIs) so that we can infer which ROIs are important to identify a certain disease based on the node pooling scores calculated by the pooling layers. Our proposed framework, Pooling Regularized-GNN (PR-GNN), encourages reasonable ROI-selection and provides flexibility to preserve either individual- or group-level patterns. We apply the PR-GNN framework on a Biopoint Autism Spectral Disorder (ASD) fMRI dataset. We investigate different choices of the hyperparameters and show that PR-GNN outperforms baseline methods in terms of classification accuracy. The salient ROI detection results show high correspondence with the previous neuroimaging-derived biomarkers for ASD.
* 11 pages, 4 figures
Knowledge Distillation Meets Self-Supervision
Jul 13, 2020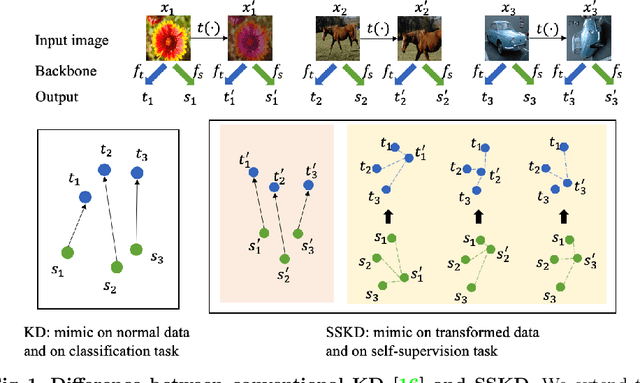

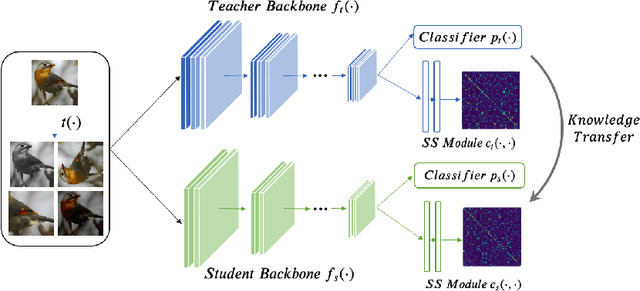

Knowledge distillation, which involves extracting the "dark knowledge" from a teacher network to guide the learning of a student network, has emerged as an important technique for model compression and transfer learning. Unlike previous works that exploit architecture-specific cues such as activation and attention for distillation, here we wish to explore a more general and model-agnostic approach for extracting "richer dark knowledge" from the pre-trained teacher model. We show that the seemingly different self-supervision task can serve as a simple yet powerful solution. For example, when performing contrastive learning between transformed entities, the noisy predictions of the teacher network reflect its intrinsic composition of semantic and pose information. By exploiting the similarity between those self-supervision signals as an auxiliary task, one can effectively transfer the hidden information from the teacher to the student. In this paper, we discuss practical ways to exploit those noisy self-supervision signals with selective transfer for distillation. We further show that self-supervision signals improve conventional distillation with substantial gains under few-shot and noisy-label scenarios. Given the richer knowledge mined from self-supervision, our knowledge distillation approach achieves state-of-the-art performance on standard benchmarks, i.e., CIFAR100 and ImageNet, under both similar-architecture and cross-architecture settings. The advantage is even more pronounced under the cross-architecture setting, where our method outperforms the state of the art CRD by an average of 2.3% in accuracy rate on CIFAR100 across six different teacher-student pairs.