 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaolin Zheng
Federated Unlearning via Active Forgetting
Jul 07, 2023
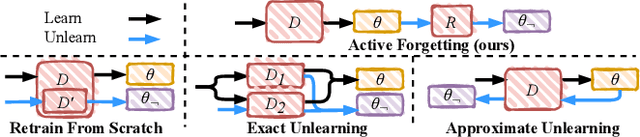

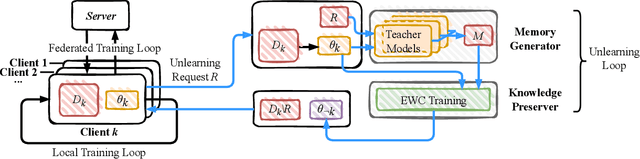
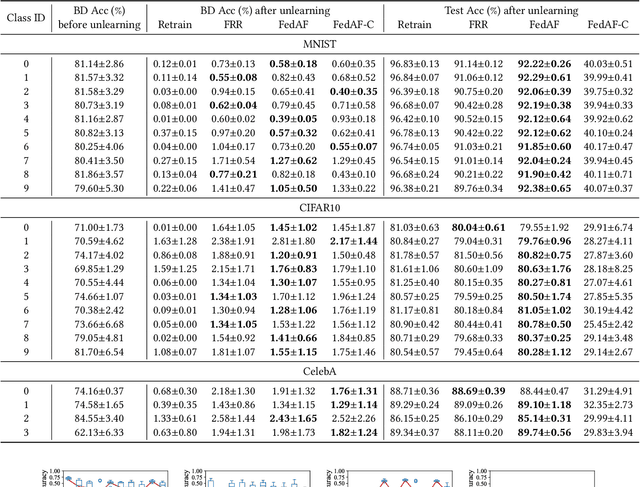
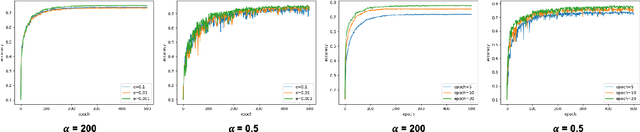
The increasing concerns regarding the privacy of machine learning models have catalyzed the exploration of machine unlearning, i.e., a process that removes the influence of training data on machine learning models. This concern also arises in the realm of federated learning, prompting researchers to address the federated unlearning problem. However, federated unlearning remains challenging. Existing unlearning methods can be broadly categorized into two approaches, i.e., exact unlearning and approximate unlearning. Firstly, implementing exact unlearning, which typically relies on the partition-aggregation framework, in a distributed manner does not improve time efficiency theoretically. Secondly, existing federated (approximate) unlearning methods suffer from imprecise data influence estimation, significant computational burden, or both. To this end, we propose a novel federated unlearning framework based on incremental learning, which is independent of specific models and federated settings. Our framework differs from existing federated unlearning methods that rely on approximate retraining or data influence estimation. Instead, we leverage new memories to overwrite old ones, imitating the process of \textit{active forgetting} in neurology. Specifically, the model, intended to unlearn, serves as a student model that continuously learns from randomly initiated teacher models. To preserve catastrophic forgetting of non-target data, we utilize elastic weight consolidation to elastically constrain weight change. Extensive experiments on three benchmark datasets demonstrate the efficiency and effectiveness of our proposed method. The result of backdoor attacks demonstrates that our proposed method achieves satisfying completeness.
Federated Learning on Non-iid Data via Local and Global Distillation
Jun 26, 2023
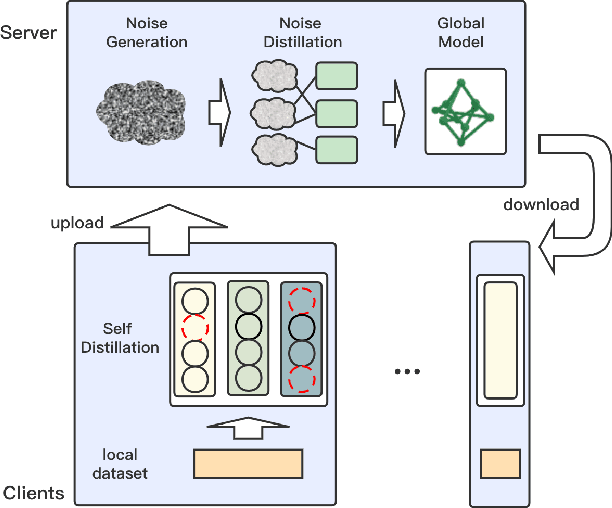
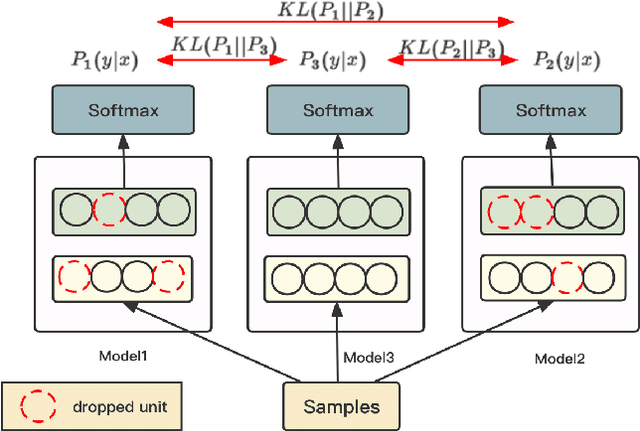
Most existing federated learning algorithms are based on the vanilla FedAvg scheme. However, with the increase of data complexity and the number of model parameters, the amount of communication traffic and the number of iteration rounds for training such algorithms increases significantly, especially in non-independently and homogeneously distributed scenarios, where they do not achieve satisfactory performance. In this work, we propose FedND: federated learning with noise distillation. The main idea is to use knowledge distillation to optimize the model training process. In the client, we propose a self-distillation method to train the local model. In the server, we generate noisy samples for each client and use them to distill other clients. Finally, the global model is obtained by the aggregation of local models. Experimental results show that the algorithm achieves the best performance and is more communication-efficient than state-of-the-art methods.
Robust Representation Learning with Reliable Pseudo-labels Generation via Self-Adaptive Optimal Transport for Short Text Clustering
May 23, 2023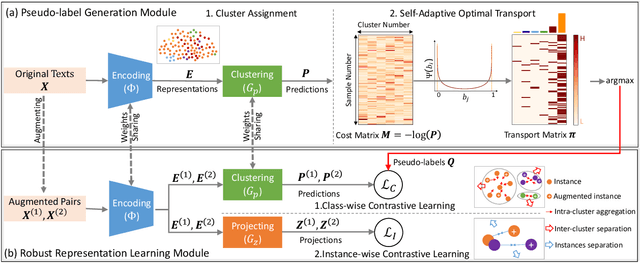
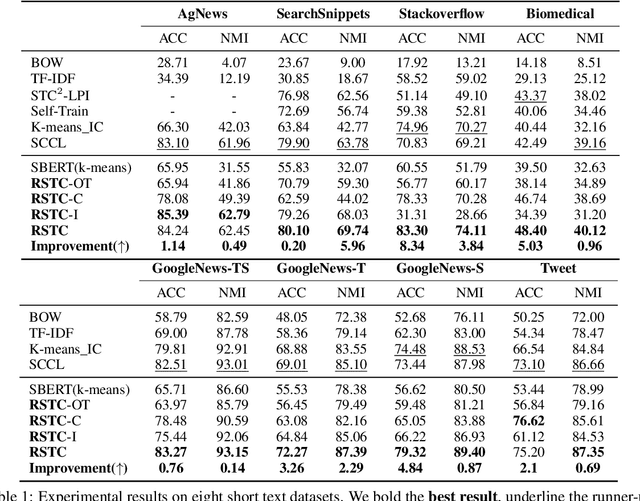
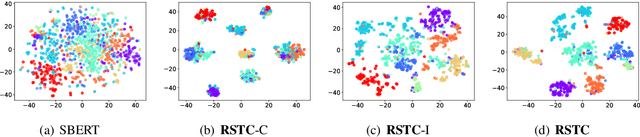
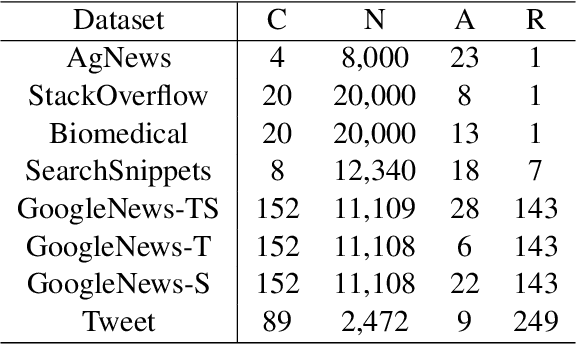
Short text clustering is challenging since it takes imbalanced and noisy data as inputs. Existing approaches cannot solve this problem well, since (1) they are prone to obtain degenerate solutions especially on heavy imbalanced datasets, and (2) they are vulnerable to noises. To tackle the above issues, we propose a Robust Short Text Clustering (RSTC) model to improve robustness against imbalanced and noisy data. RSTC includes two modules, i.e., pseudo-label generation module and robust representation learning module. The former generates pseudo-labels to provide supervision for the later, which contributes to more robust representations and correctly separated clusters. To provide robustness against the imbalance in data, we propose self-adaptive optimal transport in the pseudo-label generation module. To improve robustness against the noise in data, we further introduce both class-wise and instance-wise contrastive learning in the robust representation learning module. Our empirical studies on eight short text clustering datasets demonstrate that RSTC significantly outperforms the state-of-the-art models. The code is available at: https://github.com/hmllmh/RSTC.
PPGenCDR: A Stable and Robust Framework for Privacy-Preserving Cross-Domain Recommendation
May 11, 2023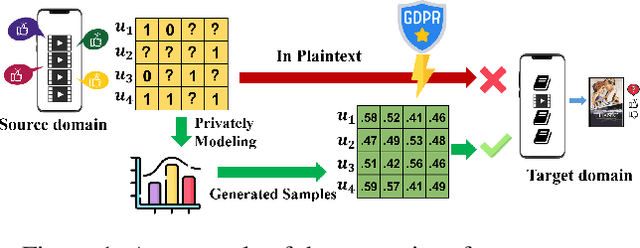
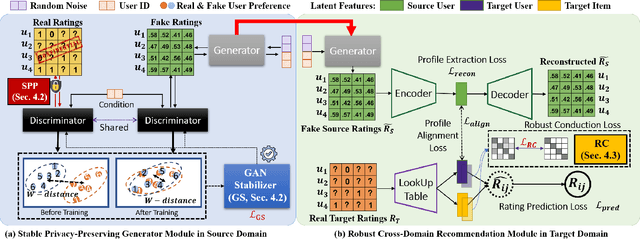
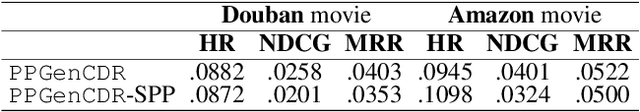
Privacy-preserving cross-domain recommendation (PPCDR) refers to preserving the privacy of users when transferring the knowledge from source domain to target domain for better performance, which is vital for the long-term development of recommender systems. Existing work on cross-domain recommendation (CDR) reaches advanced and satisfying recommendation performance, but mostly neglects preserving privacy. To fill this gap, we propose a privacy-preserving generative cross-domain recommendation (PPGenCDR) framework for PPCDR. PPGenCDR includes two main modules, i.e., stable privacy-preserving generator module, and robust cross-domain recommendation module. Specifically, the former isolates data from different domains with a generative adversarial network (GAN) based model, which stably estimates the distribution of private data in the source domain with Renyi differential privacy (RDP) technique. Then the latter aims to robustly leverage the perturbed but effective knowledge from the source domain with the raw data in target domain to improve recommendation performance. Three key modules, i.e., (1) selective privacy preserver, (2) GAN stabilizer, and (3) robustness conductor, guarantee the cost-effective trade-off between utility and privacy, the stability of GAN when using RDP, and the robustness of leveraging transferable knowledge accordingly. The extensive empirical studies on Douban and Amazon datasets demonstrate that PPGenCDR significantly outperforms the state-of-the-art recommendation models while preserving privacy.
Selective and Collaborative Influence Function for Efficient Recommendation Unlearning
Apr 20, 2023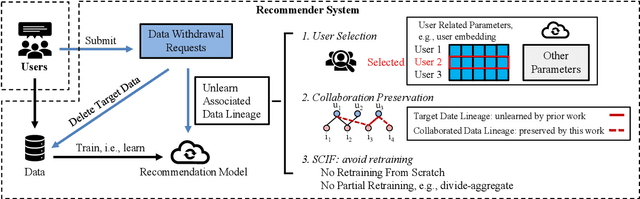
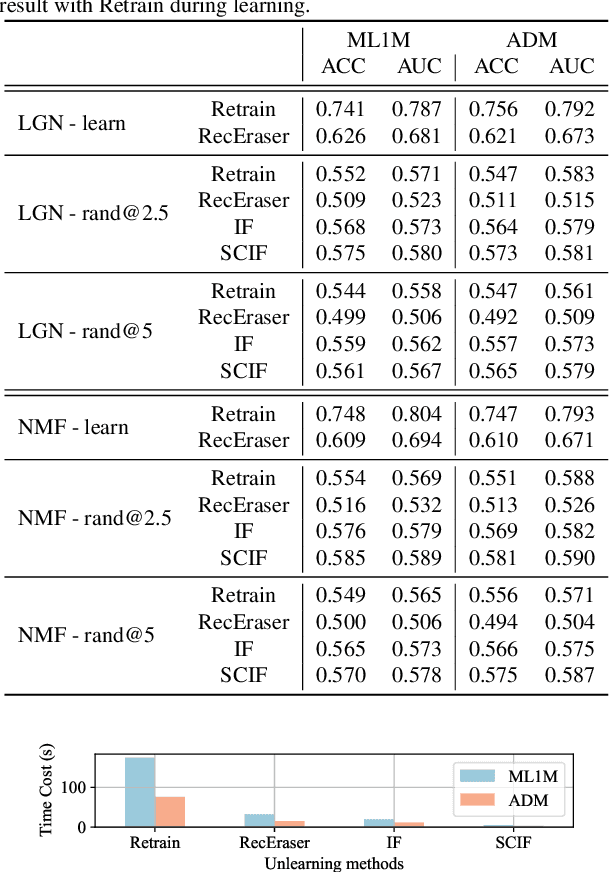
Recent regulations on the Right to be Forgotten have greatly influenced the way of running a recommender system, because users now have the right to withdraw their private data. Besides simply deleting the target data in the database, unlearning the associated data lineage e.g., the learned personal features and preferences in the model, is also necessary for data withdrawal. Existing unlearning methods are mainly devised for generalized machine learning models in classification tasks. In this paper, we first identify two main disadvantages of directly applying existing unlearning methods in the context of recommendation, i.e., (i) unsatisfactory efficiency for large-scale recommendation models and (ii) destruction of collaboration across users and items. To tackle the above issues, we propose an extra-efficient recommendation unlearning method based on Selective and Collaborative Influence Function (SCIF). Our proposed method can (i) avoid any kind of retraining which is computationally prohibitive for large-scale systems, (ii) further enhance efficiency by selectively updating user embedding and (iii) preserve the collaboration across the remaining users and items. Furthermore, in order to evaluate the unlearning completeness, we define a Membership Inference Oracle (MIO), which can justify whether the unlearned data points were in the training set of the model, i.e., whether a data point was completely unlearned. Extensive experiments on two benchmark datasets demonstrate that our proposed method can not only greatly enhance unlearning efficiency, but also achieve adequate unlearning completeness. More importantly, our proposed method outperforms the state-of-the-art unlearning method regarding comprehensive recommendation metrics.
Heterogeneous Information Crossing on Graphs for Session-based Recommender Systems
Oct 24, 2022

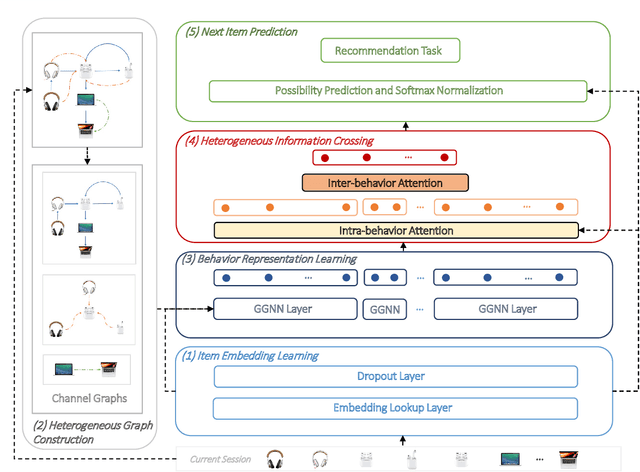
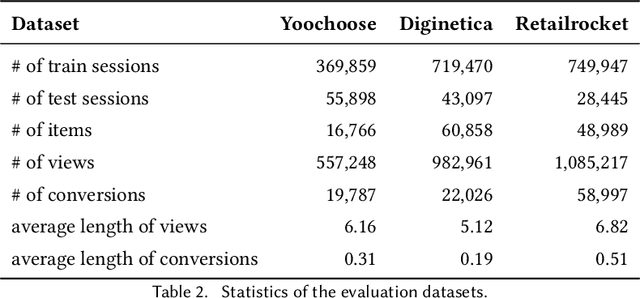
Recommender systems are fundamental information filtering techniques to recommend content or items that meet users' personalities and potential needs. As a crucial solution to address the difficulty of user identification and unavailability of historical information, session-based recommender systems provide recommendation services that only rely on users' behaviors in the current session. However, most existing studies are not well-designed for modeling heterogeneous user behaviors and capturing the relationships between them in practical scenarios. To fill this gap, in this paper, we propose a novel graph-based method, namely Heterogeneous Information Crossing on Graphs (HICG). HICG utilizes multiple types of user behaviors in the sessions to construct heterogeneous graphs, and captures users' current interests with their long-term preferences by effectively crossing the heterogeneous information on the graphs. In addition, we also propose an enhanced version, named HICG-CL, which incorporates contrastive learning (CL) technique to enhance item representation ability. By utilizing the item co-occurrence relationships across different sessions, HICG-CL improves the recommendation performance of HICG. We conduct extensive experiments on three real-world recommendation datasets, and the results verify that (i) HICG achieves the state-of-the-art performance by utilizing multiple types of behaviors on the heterogeneous graph. (ii) HICG-CL further significantly improves the recommendation performance of HICG by the proposed contrastive learning module.
Making Split Learning Resilient to Label Leakage by Potential Energy Loss
Oct 18, 2022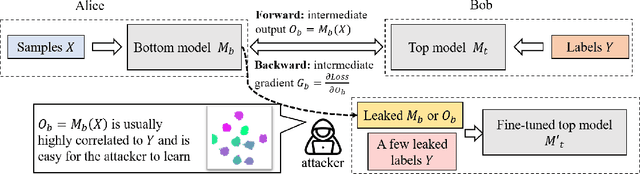
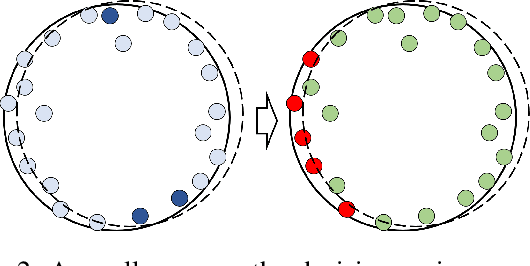
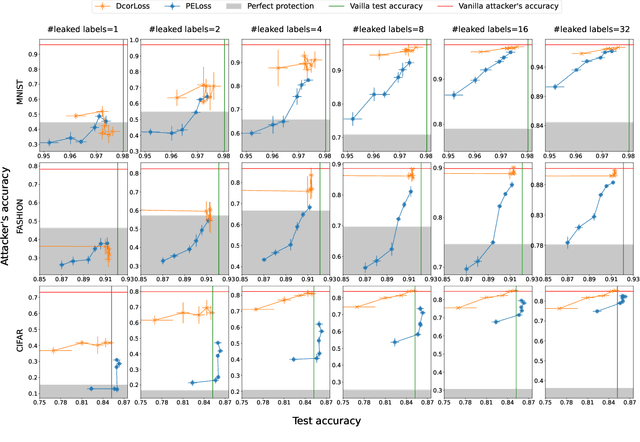
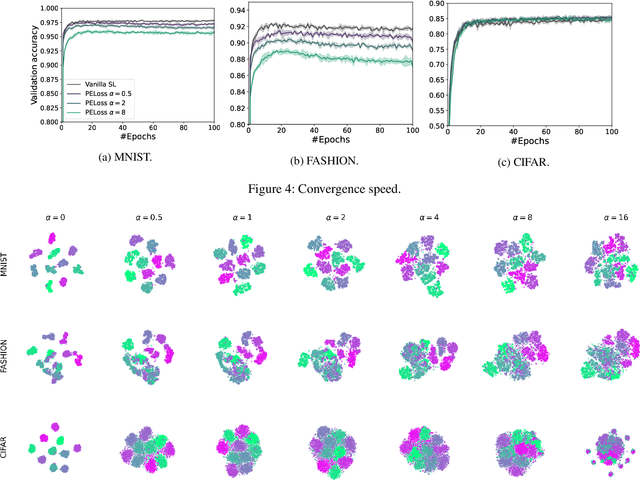
As a practical privacy-preserving learning method, split learning has drawn much attention in academia and industry. However, its security is constantly being questioned since the intermediate results are shared during training and inference. In this paper, we focus on the privacy leakage problem caused by the trained split model, i.e., the attacker can use a few labeled samples to fine-tune the bottom model, and gets quite good performance. To prevent such kind of privacy leakage, we propose the potential energy loss to make the output of the bottom model become a more `complicated' distribution, by pushing outputs of the same class towards the decision boundary. Therefore, the adversary suffers a large generalization error when fine-tuning the bottom model with only a few leaked labeled samples. Experiment results show that our method significantly lowers the attacker's fine-tuning accuracy, making the split model more resilient to label leakage.
DDGHM: Dual Dynamic Graph with Hybrid Metric Training for Cross-Domain Sequential Recommendation
Sep 21, 2022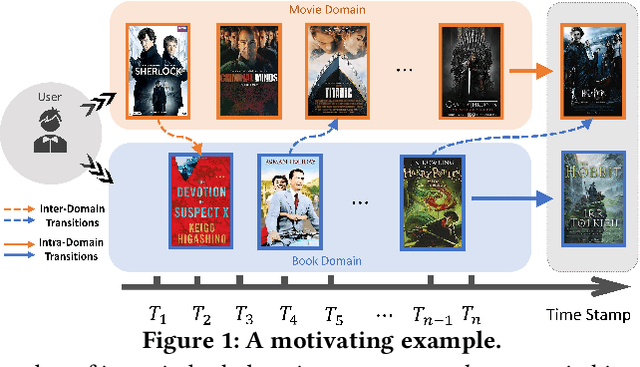
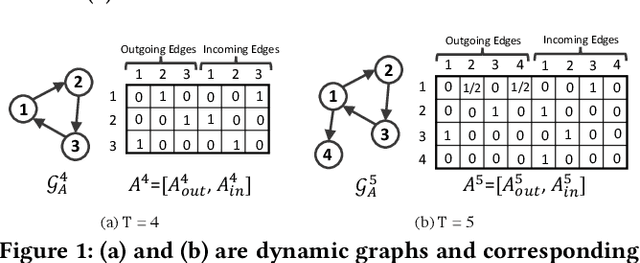
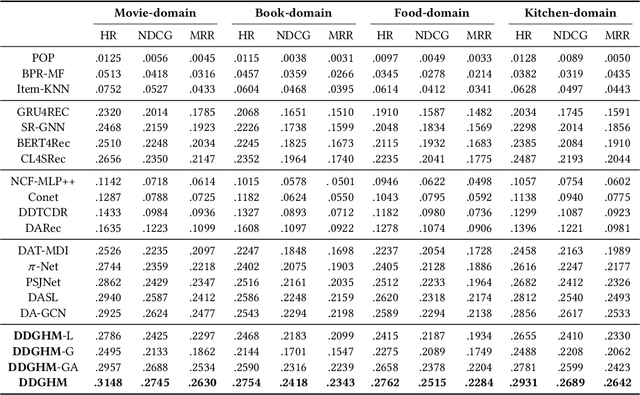
Sequential Recommendation (SR) characterizes evolving patterns of user behaviors by modeling how users transit among items. However, the short interaction sequences limit the performance of existing SR. To solve this problem, we focus on Cross-Domain Sequential Recommendation (CDSR) in this paper, which aims to leverage information from other domains to improve the sequential recommendation performance of a single domain. Solving CDSR is challenging. On the one hand, how to retain single domain preferences as well as integrate cross-domain influence remains an essential problem. On the other hand, the data sparsity problem cannot be totally solved by simply utilizing knowledge from other domains, due to the limited length of the merged sequences. To address the challenges, we propose DDGHM, a novel framework for the CDSR problem, which includes two main modules, i.e., dual dynamic graph modeling and hybrid metric training. The former captures intra-domain and inter-domain sequential transitions through dynamically constructing two-level graphs, i.e., the local graphs and the global graph, and incorporating them with a fuse attentive gating mechanism. The latter enhances user and item representations by employing hybrid metric learning, including collaborative metric for achieving alignment and contrastive metric for preserving uniformity, to further alleviate data sparsity issue and improve prediction accuracy. We conduct experiments on two benchmark datasets and the results demonstrate the effectiveness of DDHMG.
HCFRec: Hash Collaborative Filtering via Normalized Flow with Structural Consensus for Efficient Recommendation
May 24, 2022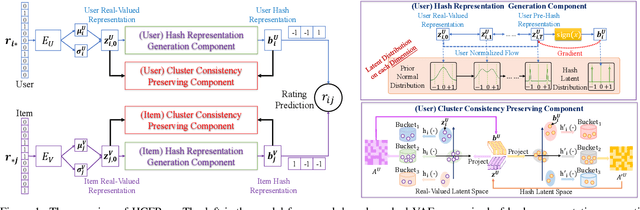
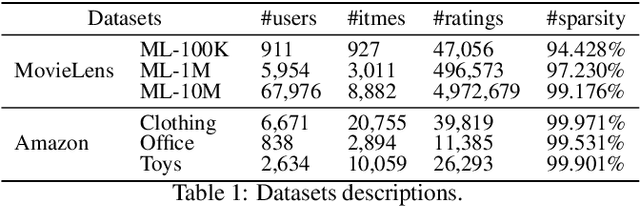
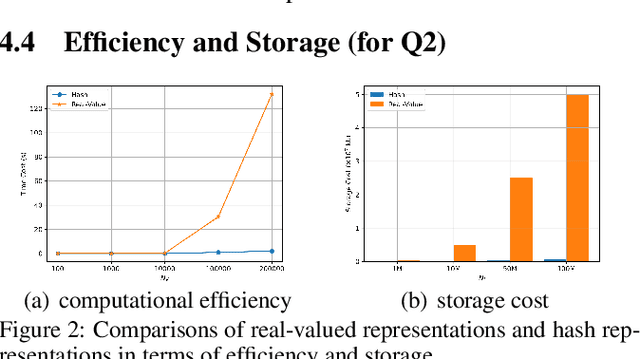
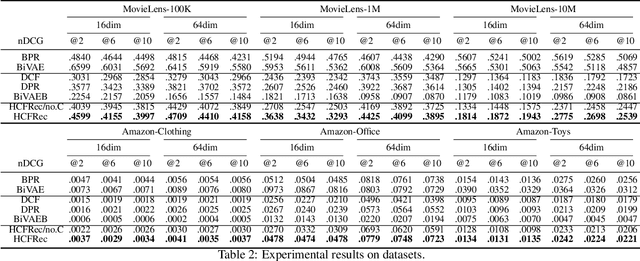
The ever-increasing data scale of user-item interactions makes it challenging for an effective and efficient recommender system. Recently, hash-based collaborative filtering (Hash-CF) approaches employ efficient Hamming distance of learned binary representations of users and items to accelerate recommendations. However, Hash-CF often faces two challenging problems, i.e., optimization on discrete representations and preserving semantic information in learned representations. To address the above two challenges, we propose HCFRec, a novel Hash-CF approach for effective and efficient recommendations. Specifically, HCFRec not only innovatively introduces normalized flow to learn the optimal hash code by efficiently fit a proposed approximate mixture multivariate normal distribution, a continuous but approximately discrete distribution, but also deploys a cluster consistency preserving mechanism to preserve the semantic structure in representations for more accurate recommendations. Extensive experiments conducted on six real-world datasets demonstrate the superiority of our HCFRec compared to the state-of-art methods in terms of effectiveness and efficiency.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022


Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.