 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaokui Xiao
MGNNI: Multiscale Graph Neural Networks with Implicit Layers
Oct 15, 2022
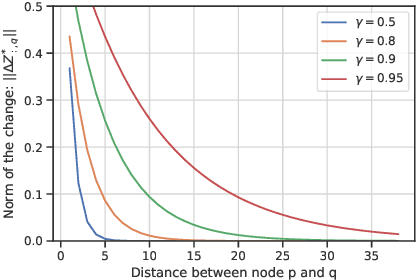
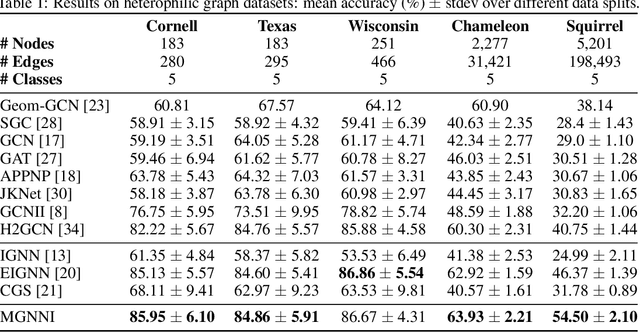
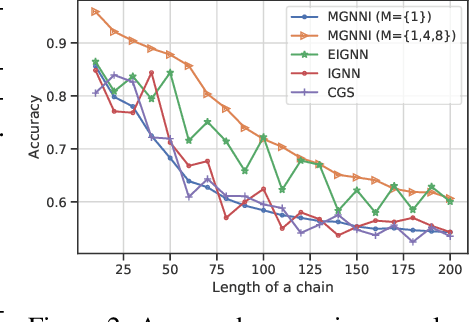
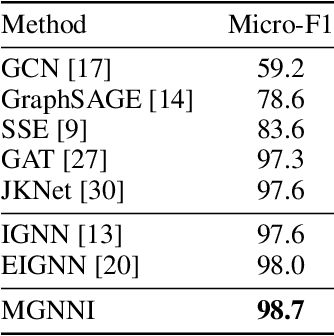
Recently, implicit graph neural networks (GNNs) have been proposed to capture long-range dependencies in underlying graphs. In this paper, we introduce and justify two weaknesses of implicit GNNs: the constrained expressiveness due to their limited effective range for capturing long-range dependencies, and their lack of ability to capture multiscale information on graphs at multiple resolutions. To show the limited effective range of previous implicit GNNs, We first provide a theoretical analysis and point out the intrinsic relationship between the effective range and the convergence of iterative equations used in these models. To mitigate the mentioned weaknesses, we propose a multiscale graph neural network with implicit layers (MGNNI) which is able to model multiscale structures on graphs and has an expanded effective range for capturing long-range dependencies. We conduct comprehensive experiments for both node classification and graph classification to show that MGNNI outperforms representative baselines and has a better ability for multiscale modeling and capturing of long-range dependencies.
Sense The Physical, Walkthrough The Virtual, Manage The Metaverse: A Data-centric Perspective
Jun 14, 2022
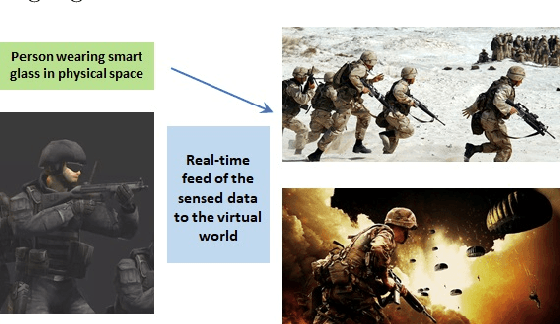
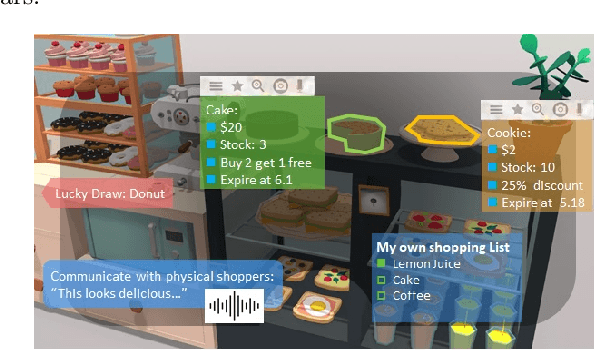

In the Metaverse, the physical space and the virtual space co-exist, and interact simultaneously. While the physical space is virtually enhanced with information, the virtual space is continuously refreshed with real-time, real-world information. To allow users to process and manipulate information seamlessly between the real and digital spaces, novel technologies must be developed. These include smart interfaces, new augmented realities, efficient storage and data management and dissemination techniques. In this paper, we first discuss some promising co-space applications. These applications offer experiences and opportunities that neither of the spaces can realize on its own. We then argue that the database community has much to offer to this field. Finally, we present several challenges that we, as a community, can contribute towards managing the Metaverse.
Finite-Time Regret of Thompson Sampling Algorithms for Exponential Family Multi-Armed Bandits
Jun 07, 2022
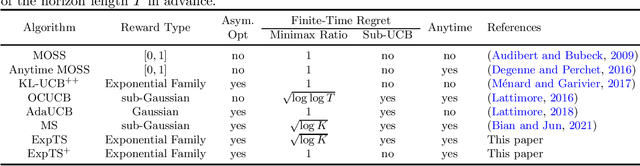
We study the regret of Thompson sampling (TS) algorithms for exponential family bandits, where the reward distribution is from a one-dimensional exponential family, which covers many common reward distributions including Bernoulli, Gaussian, Gamma, Exponential, etc. We propose a Thompson sampling algorithm, termed ExpTS, which uses a novel sampling distribution to avoid the under-estimation of the optimal arm. We provide a tight regret analysis for ExpTS, which simultaneously yields both the finite-time regret bound as well as the asymptotic regret bound. In particular, for a $K$-armed bandit with exponential family rewards, ExpTS over a horizon $T$ is sub-UCB (a strong criterion for the finite-time regret that is problem-dependent), minimax optimal up to a factor $\sqrt{\log K}$, and asymptotically optimal, for exponential family rewards. Moreover, we propose ExpTS$^+$, by adding a greedy exploitation step in addition to the sampling distribution used in ExpTS, to avoid the over-estimation of sub-optimal arms. ExpTS$^+$ is an anytime bandit algorithm and achieves the minimax optimality and asymptotic optimality simultaneously for exponential family reward distributions. Our proof techniques are general and conceptually simple and can be easily applied to analyze standard Thompson sampling with specific reward distributions.
Dangling-Aware Entity Alignment with Mixed High-Order Proximities
May 05, 2022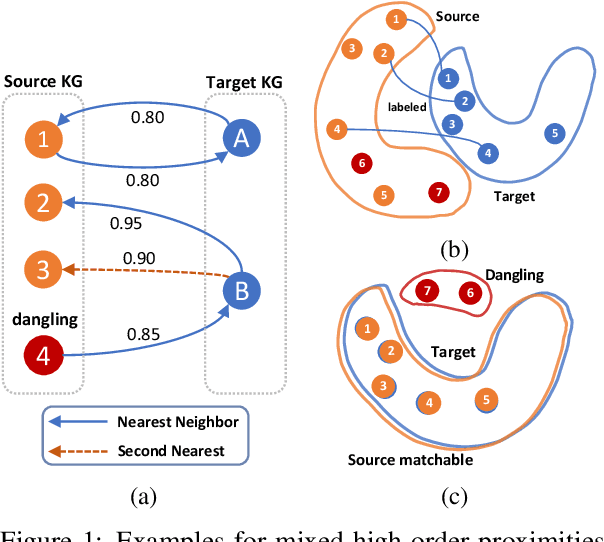

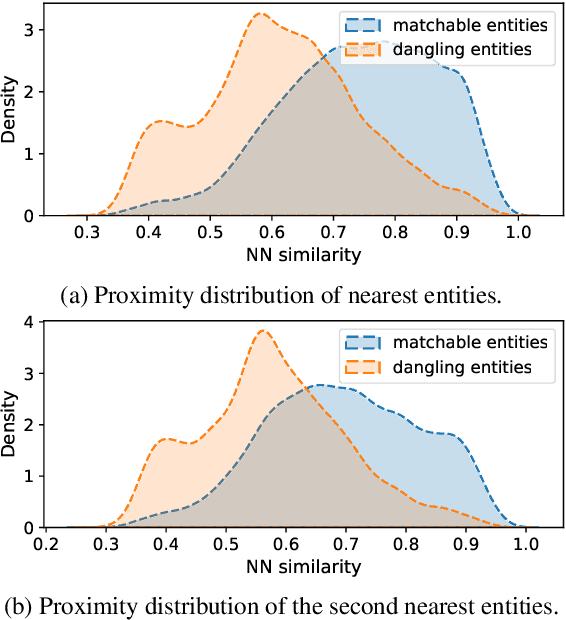

We study dangling-aware entity alignment in knowledge graphs (KGs), which is an underexplored but important problem. As different KGs are naturally constructed by different sets of entities, a KG commonly contains some dangling entities that cannot find counterparts in other KGs. Therefore, dangling-aware entity alignment is more realistic than the conventional entity alignment where prior studies simply ignore dangling entities. We propose a framework using mixed high-order proximities on dangling-aware entity alignment. Our framework utilizes both the local high-order proximity in a nearest neighbor subgraph and the global high-order proximity in an embedding space for both dangling detection and entity alignment. Extensive experiments with two evaluation settings shows that our framework more precisely detects dangling entities, and better aligns matchable entities. Further investigations demonstrate that our framework can mitigate the hubness problem on dangling-aware entity alignment.
Differentially Private Multivariate Time Series Forecasting of Aggregated Human Mobility With Deep Learning: Input or Gradient Perturbation?
May 01, 2022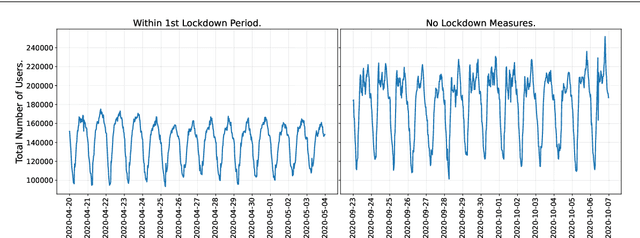
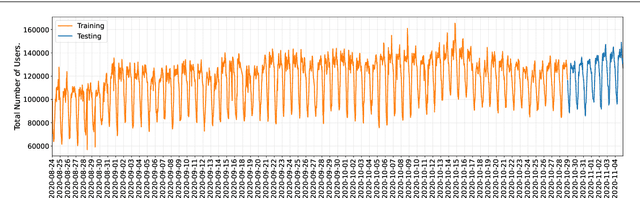

This paper investigates the problem of forecasting multivariate aggregated human mobility while preserving the privacy of the individuals concerned. Differential privacy, a state-of-the-art formal notion, has been used as the privacy guarantee in two different and independent steps when training deep learning models. On one hand, we considered \textit{gradient perturbation}, which uses the differentially private stochastic gradient descent algorithm to guarantee the privacy of each time series sample in the learning stage. On the other hand, we considered \textit{input perturbation}, which adds differential privacy guarantees in each sample of the series before applying any learning. We compared four state-of-the-art recurrent neural networks: Long Short-Term Memory, Gated Recurrent Unit, and their Bidirectional architectures, i.e., Bidirectional-LSTM and Bidirectional-GRU. Extensive experiments were conducted with a real-world multivariate mobility dataset, which we published openly along with this paper. As shown in the results, differentially private deep learning models trained under gradient or input perturbation achieve nearly the same performance as non-private deep learning models, with loss in performance varying between $0.57\%$ to $2.8\%$. The contribution of this paper is significant for those involved in urban planning and decision-making, providing a solution to the human mobility multivariate forecast problem through differentially private deep learning models.
EIGNN: Efficient Infinite-Depth Graph Neural Networks
Feb 22, 2022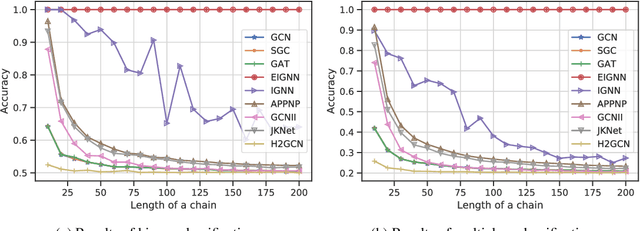
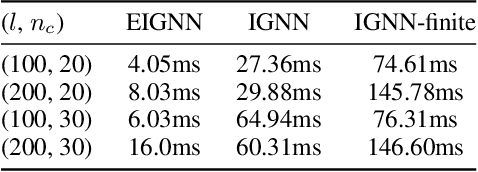
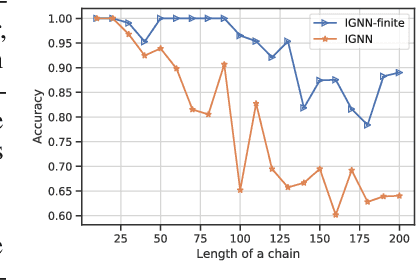
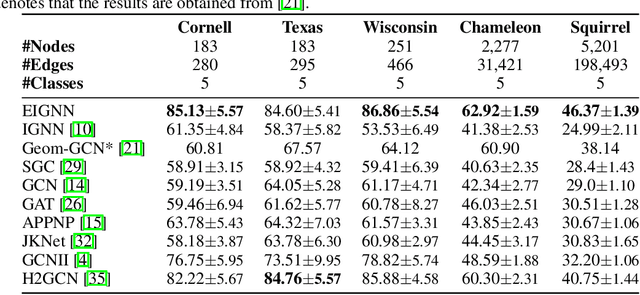
Graph neural networks (GNNs) are widely used for modelling graph-structured data in numerous applications. However, with their inherently finite aggregation layers, existing GNN models may not be able to effectively capture long-range dependencies in the underlying graphs. Motivated by this limitation, we propose a GNN model with infinite depth, which we call Efficient Infinite-Depth Graph Neural Networks (EIGNN), to efficiently capture very long-range dependencies. We theoretically derive a closed-form solution of EIGNN which makes training an infinite-depth GNN model tractable. We then further show that we can achieve more efficient computation for training EIGNN by using eigendecomposition. The empirical results of comprehensive experiments on synthetic and real-world datasets show that EIGNN has a better ability to capture long-range dependencies than recent baselines, and consistently achieves state-of-the-art performance. Furthermore, we show that our model is also more robust against both noise and adversarial perturbations on node features.
A Fusion-Denoising Attack on InstaHide with Data Augmentation
May 17, 2021


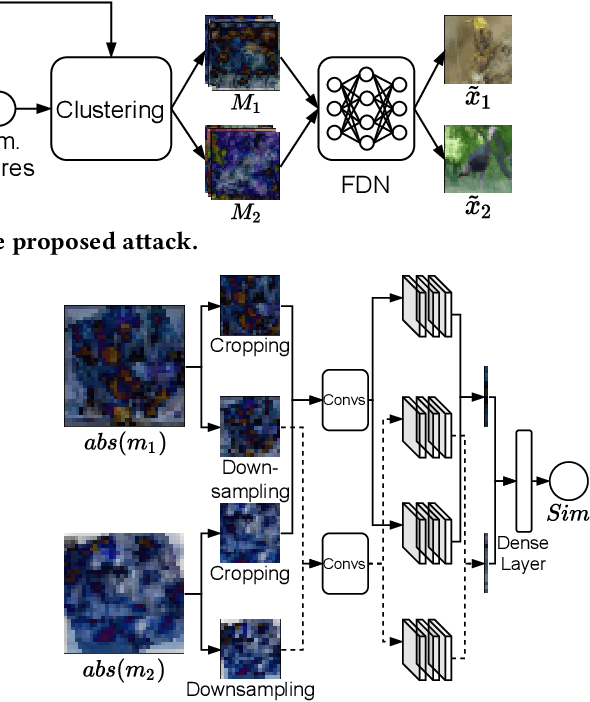
InstaHide is a state-of-the-art mechanism for protecting private training images in collaborative learning. It works by mixing multiple private images and modifying them in such a way that their visual features are no longer distinguishable to the naked eye, without significantly degrading the accuracy of training. In recent work, however, Carlini et al. show that it is possible to reconstruct private images from the encrypted dataset generated by InstaHide, by exploiting the correlations among the encrypted images. Nevertheless, Carlini et al.'s attack relies on the assumption that each private image is used without modification when mixing up with other private images. As a consequence, it could be easily defeated by incorporating data augmentation into InstaHide. This leads to a natural question: is InstaHide with data augmentation secure? This paper provides a negative answer to the above question, by present an attack for recovering private images from the outputs of InstaHide even when data augmentation is present. The basic idea of our attack is to use a comparative network to identify encrypted images that are likely to correspond to the same private image, and then employ a fusion-denoising network for restoring the private image from the encrypted ones, taking into account the effects of data augmentation. Extensive experiments demonstrate the effectiveness of the proposed attack in comparison to Carlini et al.'s attack.
Exploiting Explanations for Model Inversion Attacks
Apr 26, 2021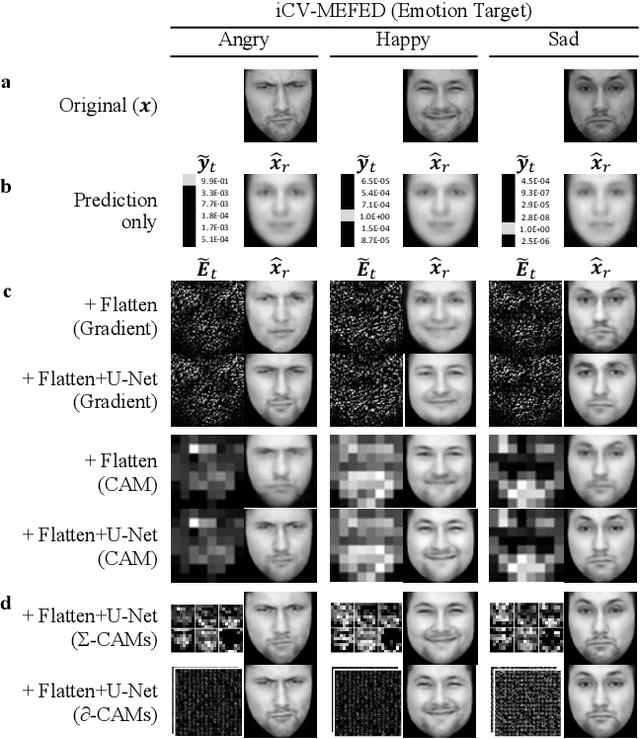
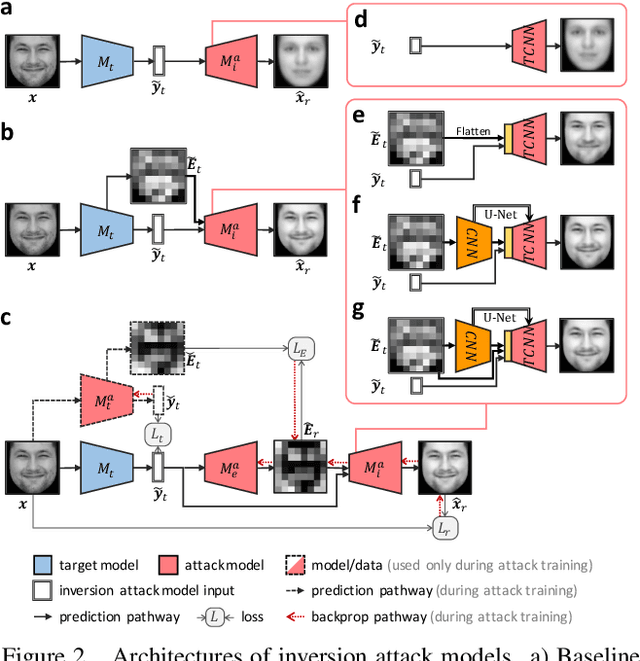

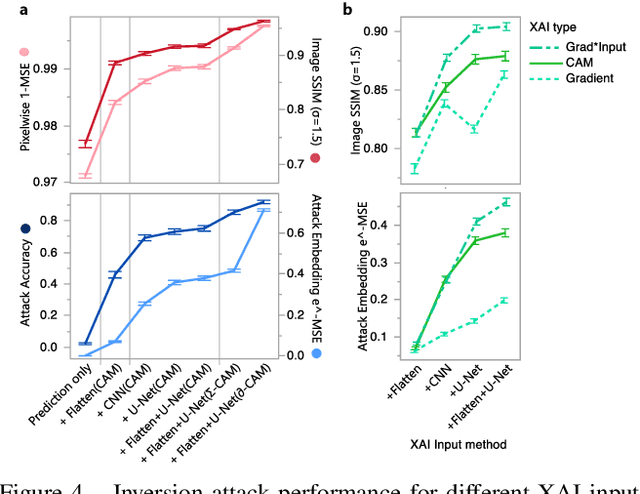
The successful deployment of artificial intelligence (AI) in many domains from healthcare to hiring requires their responsible use, particularly in model explanations and privacy. Explainable artificial intelligence (XAI) provides more information to help users to understand model decisions, yet this additional knowledge exposes additional risks for privacy attacks. Hence, providing explanation harms privacy. We study this risk for image-based model inversion attacks and identified several attack architectures with increasing performance to reconstruct private image data from model explanations. We have developed several multi-modal transposed CNN architectures that achieve significantly higher inversion performance than using the target model prediction only. These XAI-aware inversion models were designed to exploit the spatial knowledge in image explanations. To understand which explanations have higher privacy risk, we analyzed how various explanation types and factors influence inversion performance. In spite of some models not providing explanations, we further demonstrate increased inversion performance even for non-explainable target models by exploiting explanations of surrogate models through attention transfer. This method first inverts an explanation from the target prediction, then reconstructs the target image. These threats highlight the urgent and significant privacy risks of explanations and calls attention for new privacy preservation techniques that balance the dual-requirement for AI explainability and privacy.
Effective and Scalable Clustering on Massive Attributed Graphs
Feb 07, 2021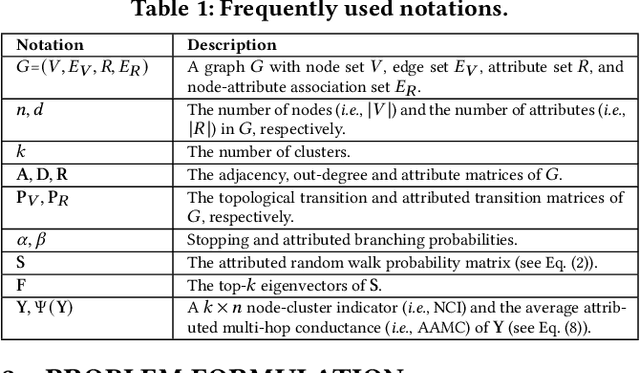
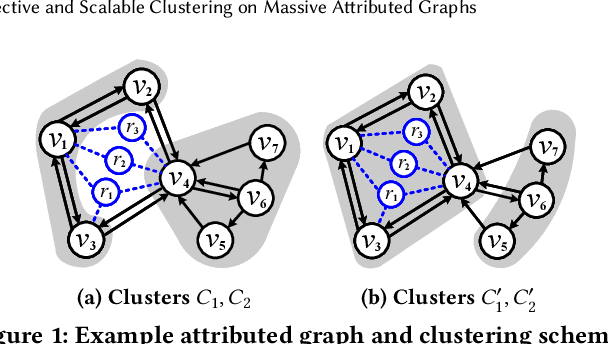
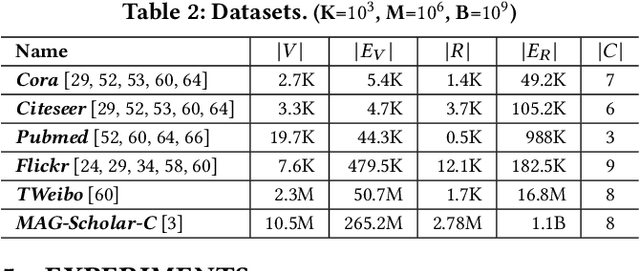
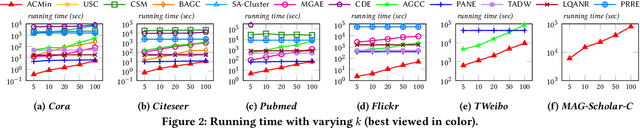
Given a graph G where each node is associated with a set of attributes, and a parameter k specifying the number of output clusters, k-attributed graph clustering (k-AGC) groups nodes in G into k disjoint clusters, such that nodes within the same cluster share similar topological and attribute characteristics, while those in different clusters are dissimilar. This problem is challenging on massive graphs, e.g., with millions of nodes and billions of edges. For such graphs, existing solutions either incur prohibitively high costs, or produce clustering results with compromised quality. In this paper, we propose ACMin, an effective approach to k-AGC that yields high-quality clusters with cost linear to the size of the input graph G. The main contributions of ACMin are twofold: (i) a novel formulation of the k-AGC problem based on an attributed multi-hop conductance quality measure custom-made for this problem setting, which effectively captures cluster coherence in terms of both topological proximities and attribute similarities, and (ii) a linear-time optimization solver that obtains high-quality clusters iteratively, based on efficient matrix operations such as orthogonal iterations, an alternative optimization approach, as well as an initialization technique that significantly speeds up the convergence of ACMin in practice. Extensive experiments, comparing 11 competitors on 6 real datasets, demonstrate that ACMin consistently outperforms all competitors in terms of result quality measured against ground-truth labels, while being up to orders of magnitude faster. In particular, on the Microsoft Academic Knowledge Graph dataset with 265.2 million edges and 1.1 billion attribute values, ACMin outputs high-quality results for 5-AGC within 1.68 hours using a single CPU core, while none of the 11 competitors finish within 3 days.
Active Learning for Node Classification: The Additional Learning Ability from Unlabelled Nodes
Dec 13, 2020
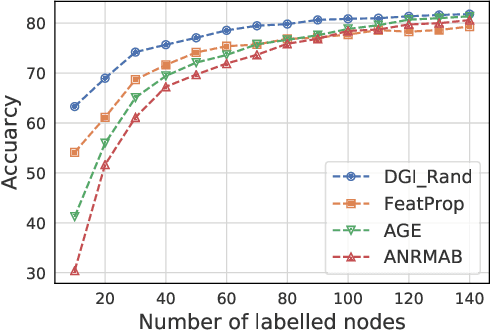
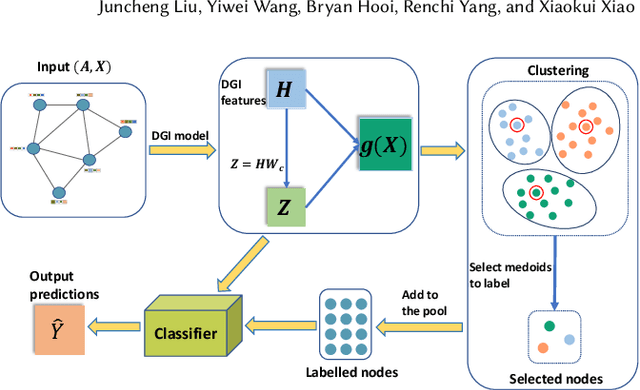
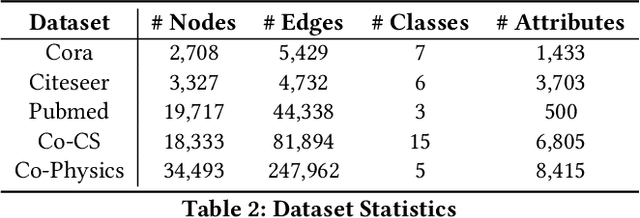
Node classification on graph data is an important task on many practical domains. However, it requires labels for training, which can be difficult or expensive to obtain in practice. Given a limited labelling budget, active learning aims to improve performance by carefully choosing which nodes to label. Our empirical study shows that existing active learning methods for node classification are considerably outperformed by a simple method which randomly selects nodes to label and trains a linear classifier with labelled nodes and unsupervised learning features. This indicates that existing methods do not fully utilize the information present in unlabelled nodes as they only use unlabelled nodes for label acquisition. In this paper, we utilize the information in unlabelled nodes by using unsupervised learning features. We propose a novel latent space clustering-based active learning method for node classification (LSCALE). Specifically, to select nodes for labelling, our method uses the K-Medoids clustering algorithm on a feature space based on the dynamic combination of both unsupervised features and supervised features. In addition, we design an incremental clustering module to avoid redundancy between nodes selected at different steps. We conduct extensive experiments on three public citation datasets and two co-authorship datasets, where our proposed method LSCALE consistently and significantly outperforms the state-of-the-art approaches by a large margin.