 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaogang Wang
ZoomNAS: Searching for Whole-body Human Pose Estimation in the Wild
Aug 23, 2022
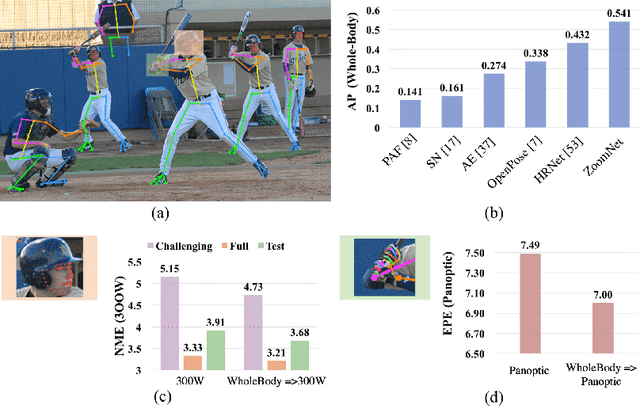
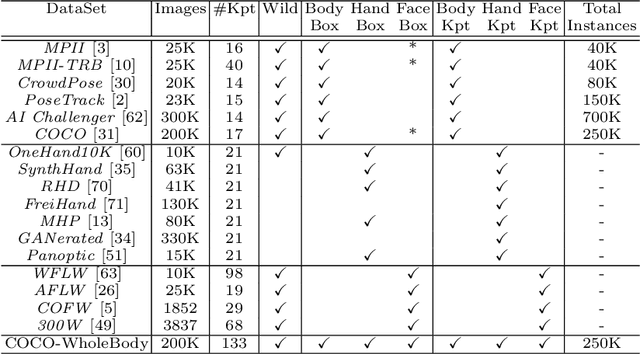

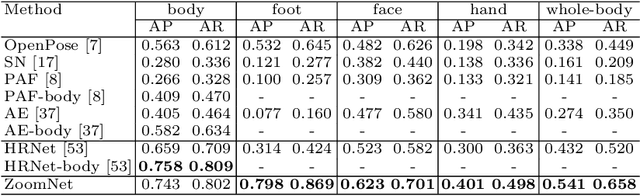
This paper investigates the task of 2D whole-body human pose estimation, which aims to localize dense landmarks on the entire human body including body, feet, face, and hands. We propose a single-network approach, termed ZoomNet, to take into account the hierarchical structure of the full human body and solve the scale variation of different body parts. We further propose a neural architecture search framework, termed ZoomNAS, to promote both the accuracy and efficiency of whole-body pose estimation. ZoomNAS jointly searches the model architecture and the connections between different sub-modules, and automatically allocates computational complexity for searched sub-modules. To train and evaluate ZoomNAS, we introduce the first large-scale 2D human whole-body dataset, namely COCO-WholeBody V1.0, which annotates 133 keypoints for in-the-wild images. Extensive experiments demonstrate the effectiveness of ZoomNAS and the significance of COCO-WholeBody V1.0.
Learning Degradation Representations for Image Deblurring
Aug 10, 2022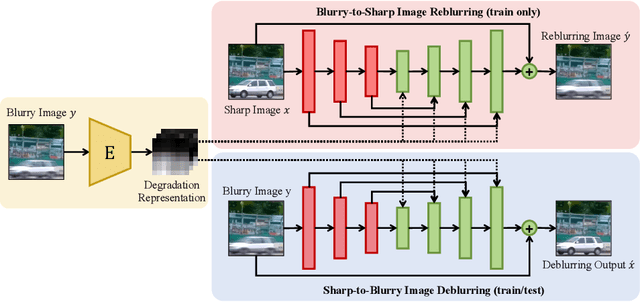
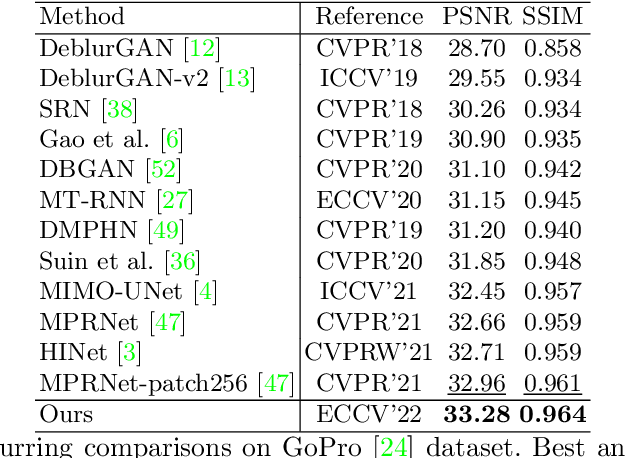
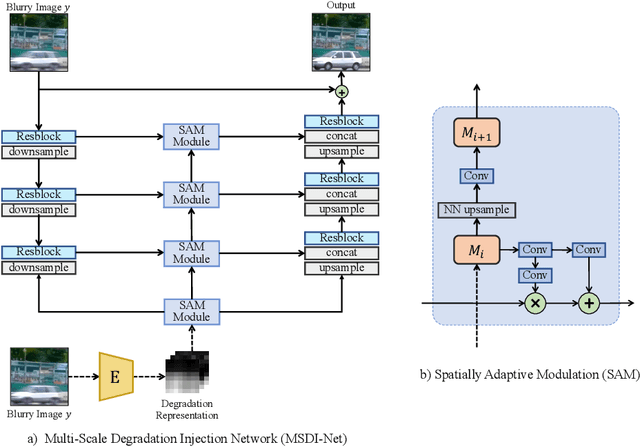

In various learning-based image restoration tasks, such as image denoising and image super-resolution, the degradation representations were widely used to model the degradation process and handle complicated degradation patterns. However, they are less explored in learning-based image deblurring as blur kernel estimation cannot perform well in real-world challenging cases. We argue that it is particularly necessary for image deblurring to model degradation representations since blurry patterns typically show much larger variations than noisy patterns or high-frequency textures.In this paper, we propose a framework to learn spatially adaptive degradation representations of blurry images. A novel joint image reblurring and deblurring learning process is presented to improve the expressiveness of degradation representations. To make learned degradation representations effective in reblurring and deblurring, we propose a Multi-Scale Degradation Injection Network (MSDI-Net) to integrate them into the neural networks. With the integration, MSDI-Net can handle various and complicated blurry patterns adaptively. Experiments on the GoPro and RealBlur datasets demonstrate that our proposed deblurring framework with the learned degradation representations outperforms state-of-the-art methods with appealing improvements. The code is released at https://github.com/dasongli1/Learning_degradation.
* Accepted to ECCV 2022
Frozen CLIP Models are Efficient Video Learners
Aug 06, 2022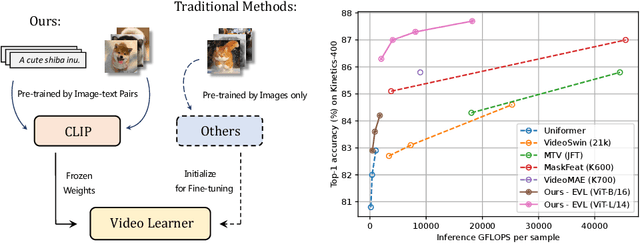
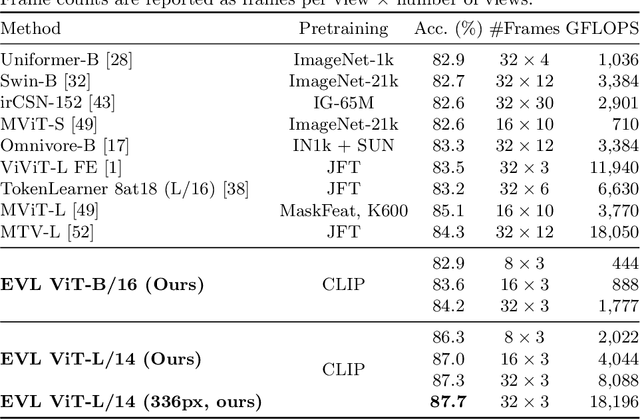
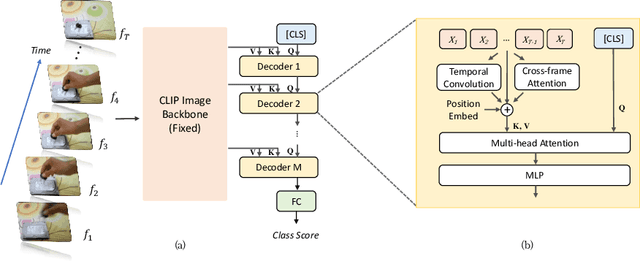
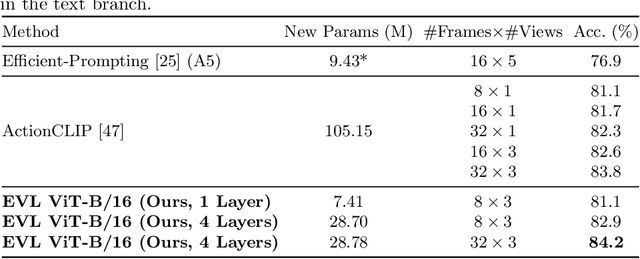
Video recognition has been dominated by the end-to-end learning paradigm -- first initializing a video recognition model with weights of a pretrained image model and then conducting end-to-end training on videos. This enables the video network to benefit from the pretrained image model. However, this requires substantial computation and memory resources for finetuning on videos and the alternative of directly using pretrained image features without finetuning the image backbone leads to subpar results. Fortunately, recent advances in Contrastive Vision-Language Pre-training (CLIP) pave the way for a new route for visual recognition tasks. Pretrained on large open-vocabulary image-text pair data, these models learn powerful visual representations with rich semantics. In this paper, we present Efficient Video Learning (EVL) -- an efficient framework for directly training high-quality video recognition models with frozen CLIP features. Specifically, we employ a lightweight Transformer decoder and learn a query token to dynamically collect frame-level spatial features from the CLIP image encoder. Furthermore, we adopt a local temporal module in each decoder layer to discover temporal clues from adjacent frames and their attention maps. We show that despite being efficient to train with a frozen backbone, our models learn high quality video representations on a variety of video recognition datasets. Code is available at https://github.com/OpenGVLab/efficient-video-recognition.
A Hybrid Complex-valued Neural Network Framework with Applications to Electroencephalogram (EEG)
Jul 28, 2022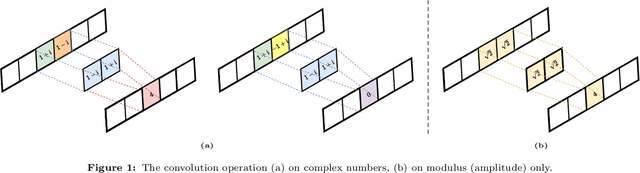
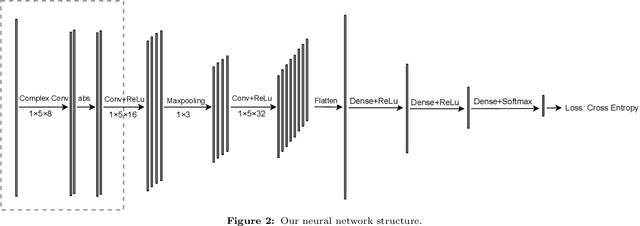
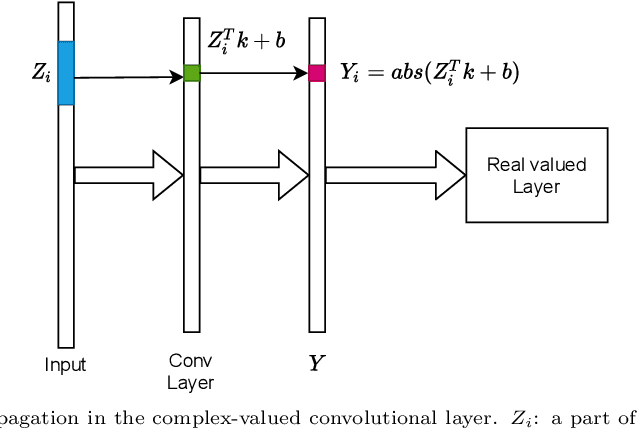
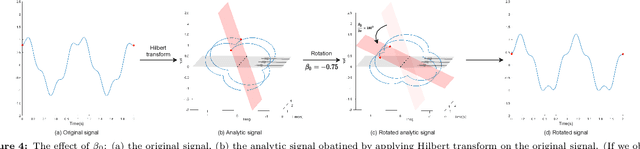
In this article, we present a new EEG signal classification framework by integrating the complex-valued and real-valued Convolutional Neural Network(CNN) with discrete Fourier transform (DFT). The proposed neural network architecture consists of one complex-valued convolutional layer, two real-valued convolutional layers, and three fully connected layers. Our method can efficiently utilize the phase information contained in the DFT. We validate our approach using two simulated EEG signals and a benchmark data set and compare it with two widely used frameworks. Our method drastically reduces the number of parameters used and improves accuracy when compared with the existing methods in classifying benchmark data sets, and significantly improves performance in classifying simulated EEG signals.
Pose for Everything: Towards Category-Agnostic Pose Estimation
Jul 21, 2022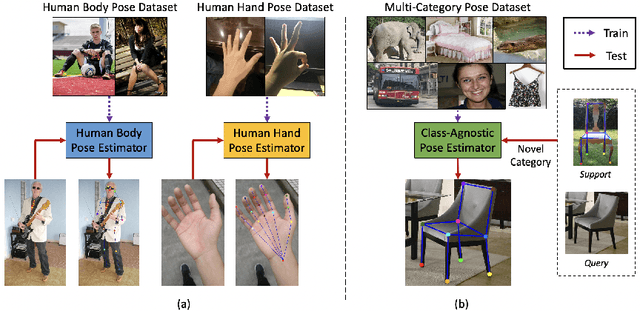
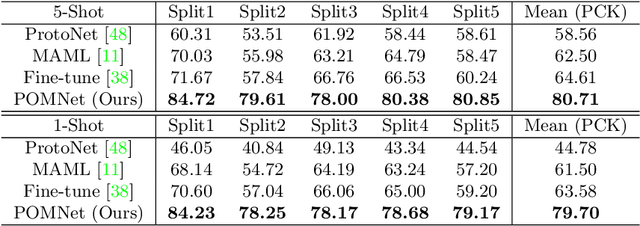
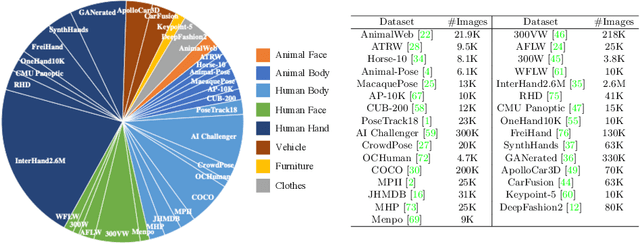

Existing works on 2D pose estimation mainly focus on a certain category, e.g. human, animal, and vehicle. However, there are lots of application scenarios that require detecting the poses/keypoints of the unseen class of objects. In this paper, we introduce the task of Category-Agnostic Pose Estimation (CAPE), which aims to create a pose estimation model capable of detecting the pose of any class of object given only a few samples with keypoint definition. To achieve this goal, we formulate the pose estimation problem as a keypoint matching problem and design a novel CAPE framework, termed POse Matching Network (POMNet). A transformer-based Keypoint Interaction Module (KIM) is proposed to capture both the interactions among different keypoints and the relationship between the support and query images. We also introduce Multi-category Pose (MP-100) dataset, which is a 2D pose dataset of 100 object categories containing over 20K instances and is well-designed for developing CAPE algorithms. Experiments show that our method outperforms other baseline approaches by a large margin. Codes and data are available at https://github.com/luminxu/Pose-for-Everything.
Not All Models Are Equal: Predicting Model Transferability in a Self-challenging Fisher Space
Jul 19, 2022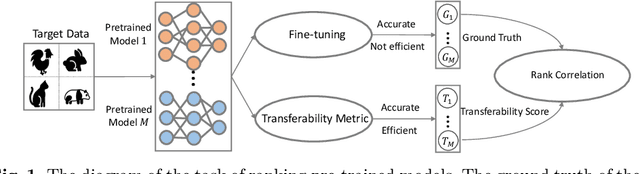
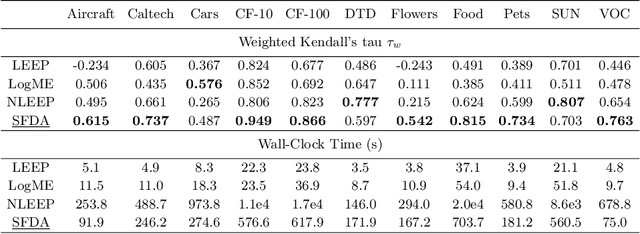
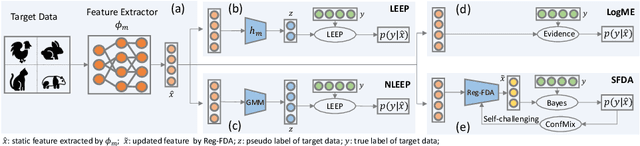
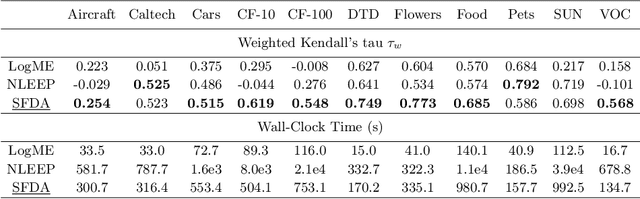
This paper addresses an important problem of ranking the pre-trained deep neural networks and screening the most transferable ones for downstream tasks. It is challenging because the ground-truth model ranking for each task can only be generated by fine-tuning the pre-trained models on the target dataset, which is brute-force and computationally expensive. Recent advanced methods proposed several lightweight transferability metrics to predict the fine-tuning results. However, these approaches only capture static representations but neglect the fine-tuning dynamics. To this end, this paper proposes a new transferability metric, called \textbf{S}elf-challenging \textbf{F}isher \textbf{D}iscriminant \textbf{A}nalysis (\textbf{SFDA}), which has many appealing benefits that existing works do not have. First, SFDA can embed the static features into a Fisher space and refine them for better separability between classes. Second, SFDA uses a self-challenging mechanism to encourage different pre-trained models to differentiate on hard examples. Third, SFDA can easily select multiple pre-trained models for the model ensemble. Extensive experiments on $33$ pre-trained models of $11$ downstream tasks show that SFDA is efficient, effective, and robust when measuring the transferability of pre-trained models. For instance, compared with the state-of-the-art method NLEEP, SFDA demonstrates an average of $59.1$\% gain while bringing $22.5$x speedup in wall-clock time. The code will be available at \url{https://github.com/TencentARC/SFDA}.
BIMS-PU: Bi-Directional and Multi-Scale Point Cloud Upsampling
Jun 25, 2022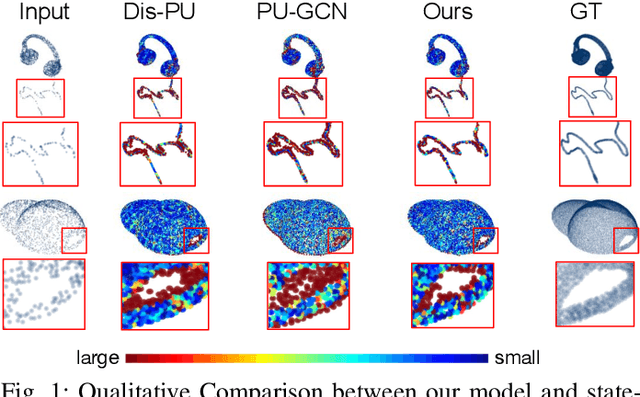
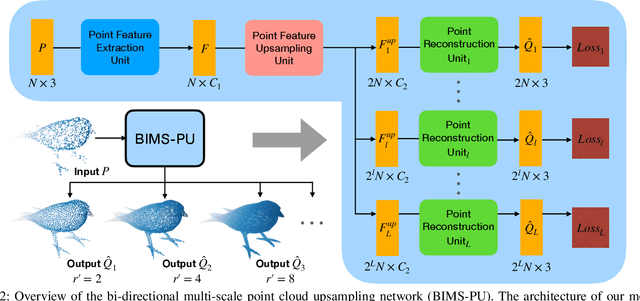
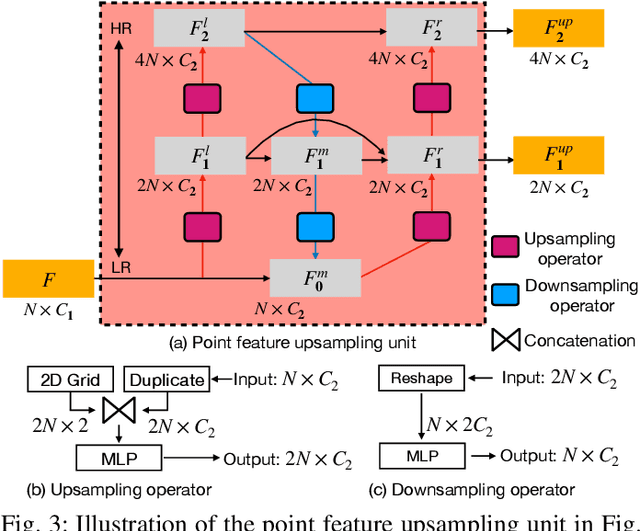
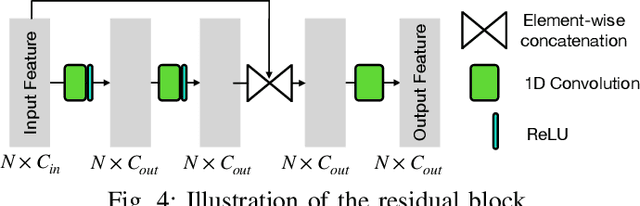
The learning and aggregation of multi-scale features are essential in empowering neural networks to capture the fine-grained geometric details in the point cloud upsampling task. Most existing approaches extract multi-scale features from a point cloud of a fixed resolution, hence obtain only a limited level of details. Though an existing approach aggregates a feature hierarchy of different resolutions from a cascade of upsampling sub-network, the training is complex with expensive computation. To address these issues, we construct a new point cloud upsampling pipeline called BIMS-PU that integrates the feature pyramid architecture with a bi-directional up and downsampling path. Specifically, we decompose the up/downsampling procedure into several up/downsampling sub-steps by breaking the target sampling factor into smaller factors. The multi-scale features are naturally produced in a parallel manner and aggregated using a fast feature fusion method. Supervision signal is simultaneously applied to all upsampled point clouds of different scales. Moreover, we formulate a residual block to ease the training of our model. Extensive quantitative and qualitative experiments on different datasets show that our method achieves superior results to state-of-the-art approaches. Last but not least, we demonstrate that point cloud upsampling can improve robot perception by ameliorating the 3D data quality.
* Accepted to RA-L 2022. in IEEE Robotics and Automation Letters
No Attention is Needed: Grouped Spatial-temporal Shift for Simple and Efficient Video Restorers
Jun 22, 2022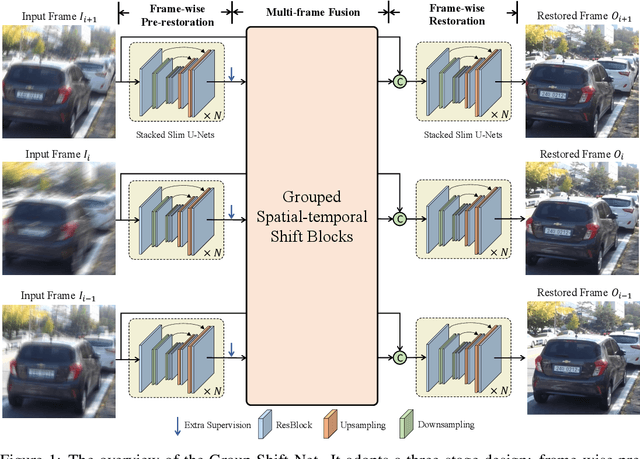
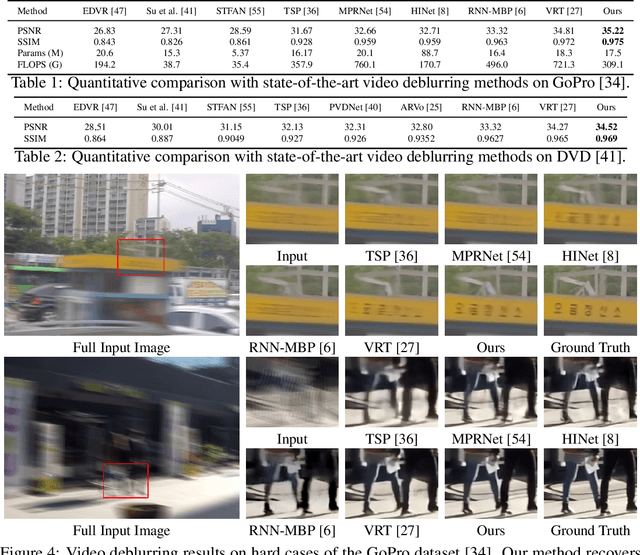
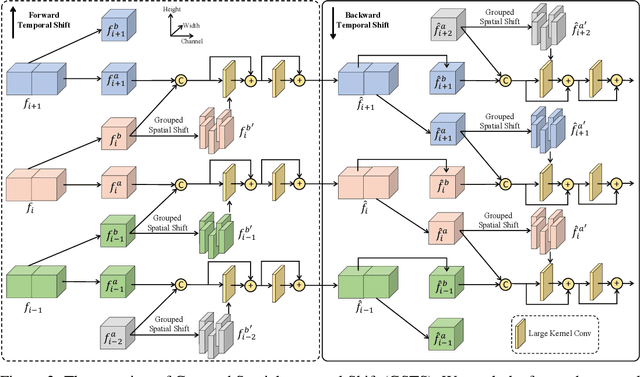
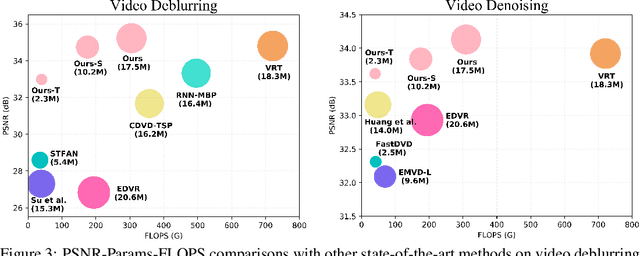
Video restoration, aiming at restoring clear frames from degraded videos, has been attracting increasing attention. Video restoration is required to establish the temporal correspondences from multiple misaligned frames. To achieve that end, existing deep methods generally adopt complicated network architectures, such as integrating optical flow, deformable convolution, cross-frame or cross-pixel self-attention layers, resulting in expensive computational cost. We argue that with proper design, temporal information utilization in video restoration can be much more efficient and effective. In this study, we propose a simple, fast yet effective framework for video restoration. The key of our framework is the grouped spatial-temporal shift, which is simple and lightweight, but can implicitly establish inter-frame correspondences and achieve multi-frame aggregation. Coupled with basic 2D U-Nets for frame-wise encoding and decoding, such an efficient spatial-temporal shift module can effectively tackle the challenges in video restoration. Extensive experiments show that our framework surpasses previous state-of-the-art method with 43% of its computational cost on both video deblurring and video denoising.
3D Object Detection for Autonomous Driving: A Review and New Outlooks
Jun 19, 2022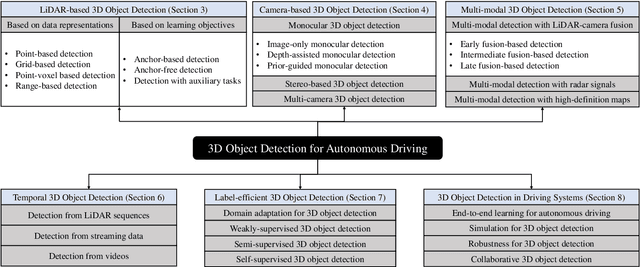
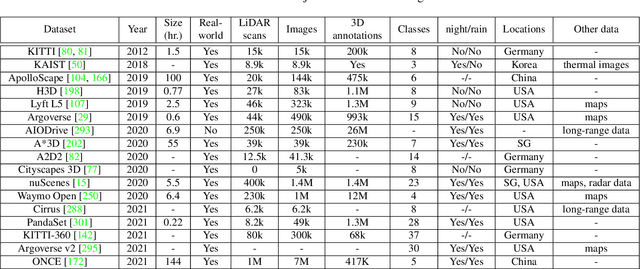
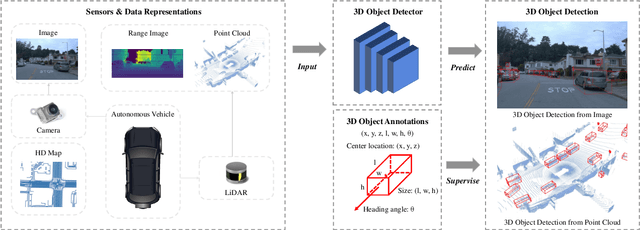
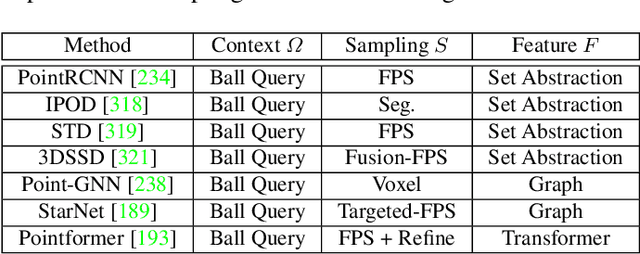
Autonomous driving, in recent years, has been receiving increasing attention for its potential to relieve drivers' burdens and improve the safety of driving. In modern autonomous driving pipelines, the perception system is an indispensable component, aiming to accurately estimate the status of surrounding environments and provide reliable observations for prediction and planning. 3D object detection, which intelligently predicts the locations, sizes, and categories of the critical 3D objects near an autonomous vehicle, is an important part of a perception system. This paper reviews the advances in 3D object detection for autonomous driving. First, we introduce the background of 3D object detection and discuss the challenges in this task. Second, we conduct a comprehensive survey of the progress in 3D object detection from the aspects of models and sensory inputs, including LiDAR-based, camera-based, and multi-modal detection approaches. We also provide an in-depth analysis of the potentials and challenges in each category of methods. Additionally, we systematically investigate the applications of 3D object detection in driving systems. Finally, we conduct a performance analysis of the 3D object detection approaches, and we further summarize the research trends over the years and prospect the future directions of this area.