 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXi Yang
A Low-Overhead Incorporation-Extrapolation based Few-Shot CSI Feedback Framework for Massive MIMO Systems
Dec 07, 2023
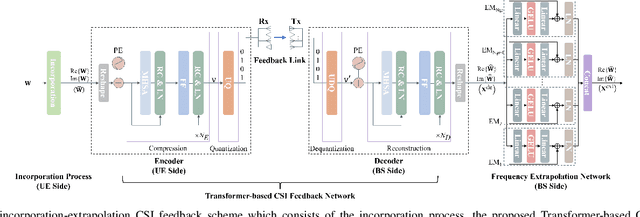
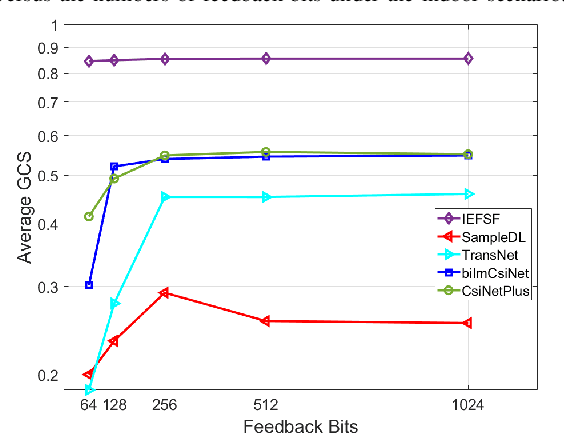
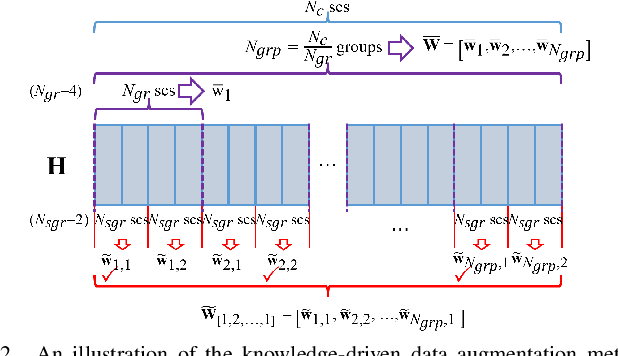
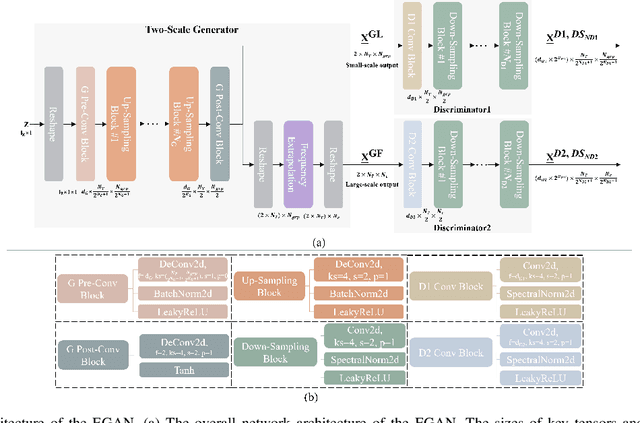
Accurate channel state information (CSI) is essential for downlink precoding at the base station (BS), especially for frequency FDD wideband massive MIMO systems with OFDM. In FDD systems, CSI is attained through CSI feedback from the user equipment (UE). However, large-scale antennas and large number of subcarriers significantly increase CSI feedback overhead. Deep learning-based CSI feedback methods have received tremendous attention in recent years due to their great capability of compressing CSI. Nonetheless, large amounts of collected samples are required to train deep learning models, which is severely challenging in practice. Besides, with the rapidly increasing number of antennas and subcarriers, most of these deep learning methods' CSI feedback overhead also grow dramatically, owing to their focus on full-dimensional CSI feedback. To address this issue, in this paper, we propose a low-overhead Incorporation-Extrapolation based Few-Shot CSI feedback Framework (IEFSF) for massive MIMO systems. To further reduce the feedback overhead, a low-dimensional eigenvector-based CSI matrix is first formed with the incorporation process at the UE, and then recovered to the full-dimensional eigenvector-based CSI matrix at the BS via the extrapolation process. After that, to alleviate the necessity of the extensive collected samples and enable few-shot CSI feedback, we further propose a knowledge-driven data augmentation method and an artificial intelligence-generated content (AIGC) -based data augmentation method by exploiting the domain knowledge of wireless channels and by exploiting a novel generative model, respectively. Numerical results demonstrate that the proposed IEFSF can significantly reduce CSI feedback overhead by 16 times compared with existing CSI feedback methods while maintaining higher feedback accuracy using only several hundreds of collected samples.
Detecting Voice Cloning Attacks via Timbre Watermarking
Dec 06, 2023Nowadays, it is common to release audio content to the public. However, with the rise of voice cloning technology, attackers have the potential to easily impersonate a specific person by utilizing his publicly released audio without any permission. Therefore, it becomes significant to detect any potential misuse of the released audio content and protect its timbre from being impersonated. To this end, we introduce a novel concept, "Timbre Watermarking", which embeds watermark information into the target individual's speech, eventually defeating the voice cloning attacks. To ensure the watermark is robust to the voice cloning model's learning process, we design an end-to-end voice cloning-resistant detection framework. The core idea of our solution is to embed and extract the watermark in the frequency domain in a temporally invariant manner. To acquire generalization across different voice cloning attacks, we modulate their shared process and integrate it into our framework as a distortion layer. Experiments demonstrate that the proposed timbre watermarking can defend against different voice cloning attacks, exhibit strong resistance against various adaptive attacks (e.g., reconstruction-based removal attacks, watermark overwriting attacks), and achieve practicality in real-world services such as PaddleSpeech, Voice-Cloning-App, and so-vits-svc. In addition, ablation studies are also conducted to verify the effectiveness of our design. Some audio samples are available at https://timbrewatermarking.github.io/samples.
A Dynamic Network for Efficient Point Cloud Registration
Dec 05, 2023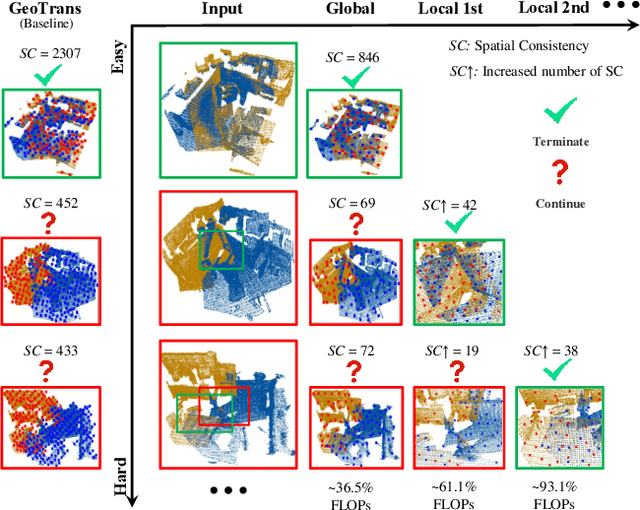
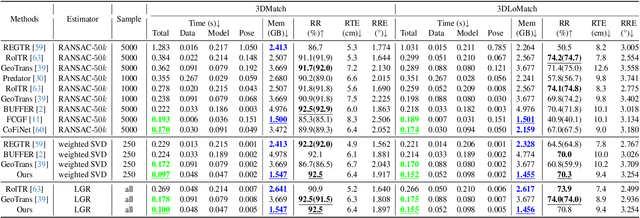
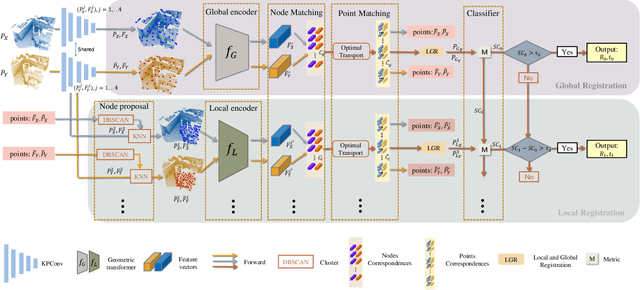
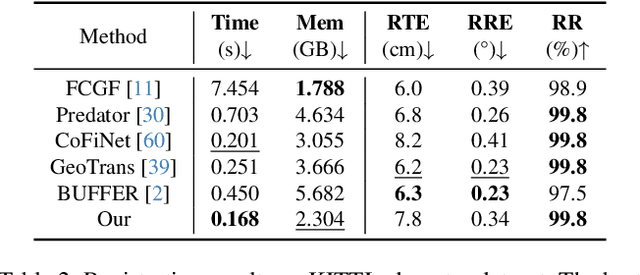
For the point cloud registration task, a significant challenge arises from non-overlapping points that consume extensive computational resources while negatively affecting registration accuracy. In this paper, we introduce a dynamic approach, widely utilized to improve network efficiency in computer vision tasks, to the point cloud registration task. We employ an iterative registration process on point cloud data multiple times to identify regions where matching points cluster, ultimately enabling us to remove noisy points. Specifically, we begin with deep global sampling to perform coarse global registration. Subsequently, we employ the proposed refined node proposal module to further narrow down the registration region and perform local registration. Furthermore, we utilize a spatial consistency-based classifier to evaluate the results of each registration stage. The model terminates once it reaches sufficient confidence, avoiding unnecessary computations. Extended experiments demonstrate that our model significantly reduces time consumption compared to other methods with similar results, achieving a speed improvement of over 41% on indoor dataset (3DMatch) and 33% on outdoor datasets (KITTI) while maintaining competitive registration recall requirements.
Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
Dec 01, 2023Real-world low-resolution (LR) videos have diverse and complex degradations, imposing great challenges on video super-resolution (VSR) algorithms to reproduce their high-resolution (HR) counterparts with high quality. Recently, the diffusion models have shown compelling performance in generating realistic details for image restoration tasks. However, the diffusion process has randomness, making it hard to control the contents of restored images. This issue becomes more serious when applying diffusion models to VSR tasks because temporal consistency is crucial to the perceptual quality of videos. In this paper, we propose an effective real-world VSR algorithm by leveraging the strength of pre-trained latent diffusion models. To ensure the content consistency among adjacent frames, we exploit the temporal dynamics in LR videos to guide the diffusion process by optimizing the latent sampling path with a motion-guided loss, ensuring that the generated HR video maintains a coherent and continuous visual flow. To further mitigate the discontinuity of generated details, we insert temporal module to the decoder and fine-tune it with an innovative sequence-oriented loss. The proposed motion-guided latent diffusion (MGLD) based VSR algorithm achieves significantly better perceptual quality than state-of-the-arts on real-world VSR benchmark datasets, validating the effectiveness of the proposed model design and training strategies.
IPMix: Label-Preserving Data Augmentation Method for Training Robust Classifiers
Oct 17, 2023
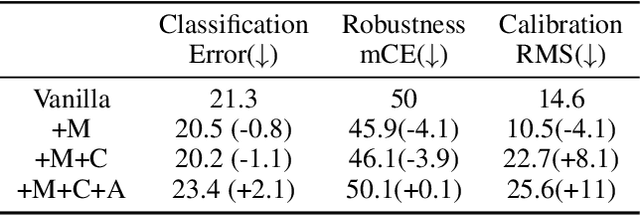
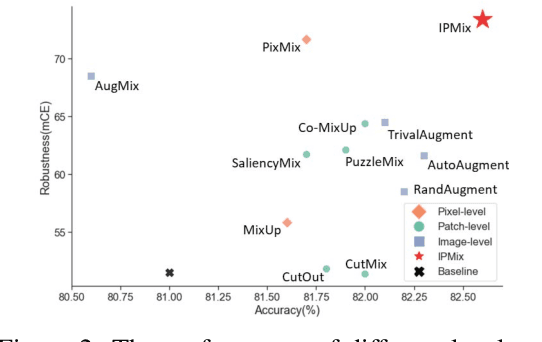
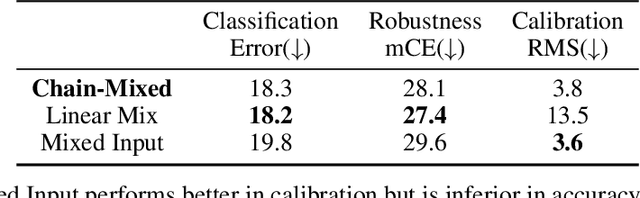
Data augmentation has been proven effective for training high-accuracy convolutional neural network classifiers by preventing overfitting. However, building deep neural networks in real-world scenarios requires not only high accuracy on clean data but also robustness when data distributions shift. While prior methods have proposed that there is a trade-off between accuracy and robustness, we propose IPMix, a simple data augmentation approach to improve robustness without hurting clean accuracy. IPMix integrates three levels of data augmentation (image-level, patch-level, and pixel-level) into a coherent and label-preserving technique to increase the diversity of training data with limited computational overhead. To further improve the robustness, IPMix introduces structural complexity at different levels to generate more diverse images and adopts the random mixing method for multi-scale information fusion. Experiments demonstrate that IPMix outperforms state-of-the-art corruption robustness on CIFAR-C and ImageNet-C. In addition, we show that IPMix also significantly improves the other safety measures, including robustness to adversarial perturbations, calibration, prediction consistency, and anomaly detection, achieving state-of-the-art or comparable results on several benchmarks, including ImageNet-R, ImageNet-A, and ImageNet-O.
On the Impact of Cross-Domain Data on German Language Models
Oct 13, 2023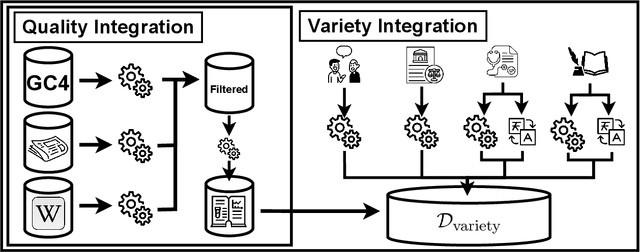
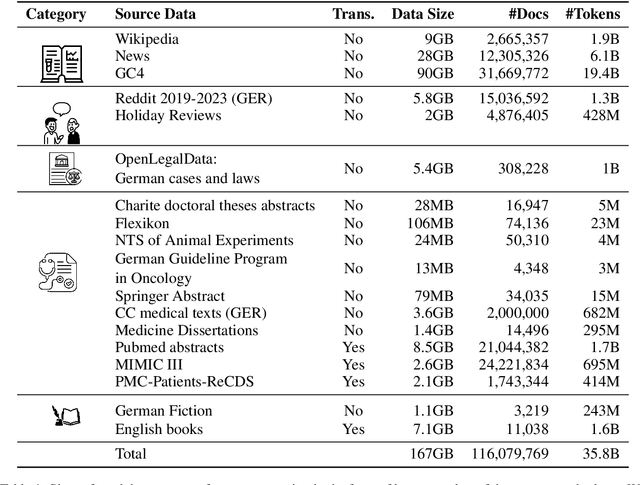
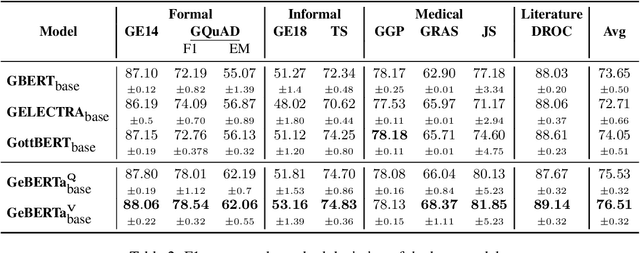
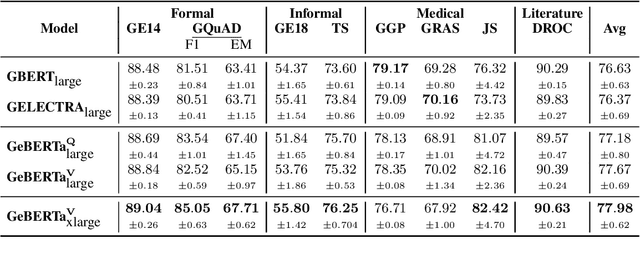
Traditionally, large language models have been either trained on general web crawls or domain-specific data. However, recent successes of generative large language models, have shed light on the benefits of cross-domain datasets. To examine the significance of prioritizing data diversity over quality, we present a German dataset comprising texts from five domains, along with another dataset aimed at containing high-quality data. Through training a series of models ranging between 122M and 750M parameters on both datasets, we conduct a comprehensive benchmark on multiple downstream tasks. Our findings demonstrate that the models trained on the cross-domain dataset outperform those trained on quality data alone, leading to improvements up to $4.45\%$ over the previous state-of-the-art. The models are available at https://huggingface.co/ikim-uk-essen
Model Tuning or Prompt Tuning? A Study of Large Language Models for Clinical Concept and Relation Extraction
Oct 10, 2023
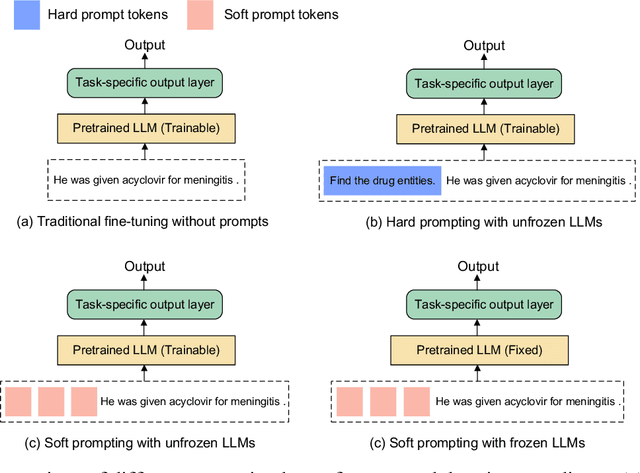
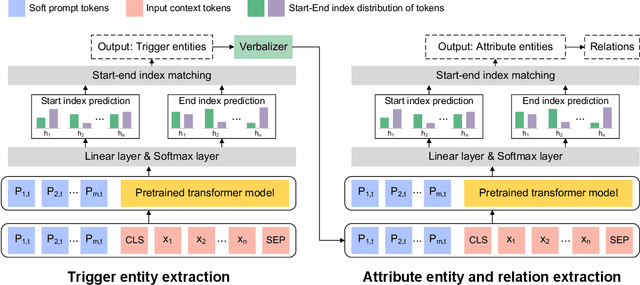
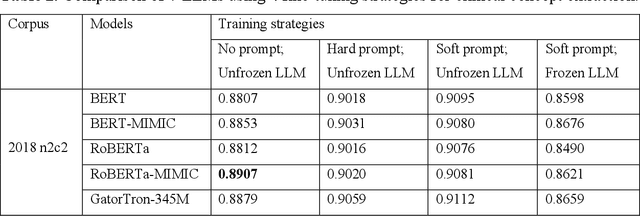
Objective To develop soft prompt-based learning algorithms for large language models (LLMs), examine the shape of prompts, prompt-tuning using frozen/unfrozen LLMs, transfer learning, and few-shot learning abilities. Methods We developed a soft prompt-based LLM model and compared 4 training strategies including (1) fine-tuning without prompts; (2) hard-prompt with unfrozen LLMs; (3) soft-prompt with unfrozen LLMs; and (4) soft-prompt with frozen LLMs. We evaluated 7 pretrained LLMs using the 4 training strategies for clinical concept and relation extraction on two benchmark datasets. We evaluated the transfer learning ability of the prompt-based learning algorithms in a cross-institution setting. We also assessed the few-shot learning ability. Results and Conclusion When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6~3.1% and 1.2~2.9%, respectively; GatorTron-345M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming the other two models by 0.2~2% and 0.6~11.7%, respectively. When LLMs are frozen, small (i.e., 345 million parameters) LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen LLMs. For cross-institute evaluation, soft prompting with a frozen GatorTron-8.9B model achieved the best performance. This study demonstrates that (1) machines can learn soft prompts better than humans, (2) frozen LLMs have better few-shot learning ability and transfer learning ability to facilitate muti-institution applications, and (3) frozen LLMs require large models.
Gradient constrained sharpness-aware prompt learning for vision-language models
Sep 20, 2023
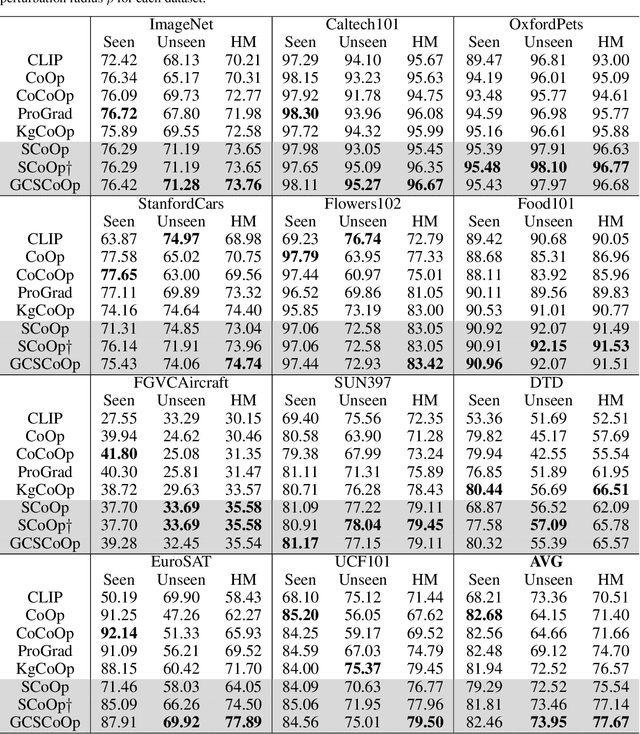
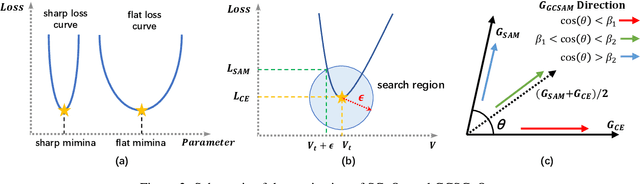
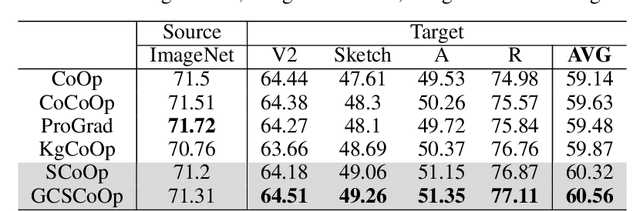
This paper targets a novel trade-off problem in generalizable prompt learning for vision-language models (VLM), i.e., improving the performance on unseen classes while maintaining the performance on seen classes. Comparing with existing generalizable methods that neglect the seen classes degradation, the setting of this problem is more strict and fits more closely with practical applications. To solve this problem, we start from the optimization perspective, and leverage the relationship between loss landscape geometry and model generalization ability. By analyzing the loss landscapes of the state-of-the-art method and vanilla Sharpness-aware Minimization (SAM) based method, we conclude that the trade-off performance correlates to both loss value and loss sharpness, while each of them is indispensable. However, we find the optimizing gradient of existing methods cannot maintain high relevance to both loss value and loss sharpness during optimization, which severely affects their trade-off performance. To this end, we propose a novel SAM-based method for prompt learning, denoted as Gradient Constrained Sharpness-aware Context Optimization (GCSCoOp), to dynamically constrain the optimizing gradient, thus achieving above two-fold optimization objective simultaneously. Extensive experiments verify the effectiveness of GCSCoOp in the trade-off problem.