 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Sentiment: Fine-tuning CNNs for Visual Sentiment Prediction
Jan 27, 2017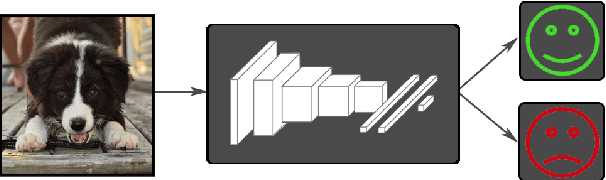


Visual multimedia have become an inseparable part of our digital social lives, and they often capture moments tied with deep affections. Automated visual sentiment analysis tools can provide a means of extracting the rich feelings and latent dispositions embedded in these media. In this work, we explore how Convolutional Neural Networks (CNNs), a now de facto computational machine learning tool particularly in the area of Computer Vision, can be specifically applied to the task of visual sentiment prediction. We accomplish this through fine-tuning experiments using a state-of-the-art CNN and via rigorous architecture analysis, we present several modifications that lead to accuracy improvements over prior art on a dataset of images from a popular social media platform. We additionally present visualizations of local patterns that the network learned to associate with image sentiment for insight into how visual positivity (or negativity) is perceived by the model.
Hierarchical Object Detection with Deep Reinforcement Learning
Nov 25, 2016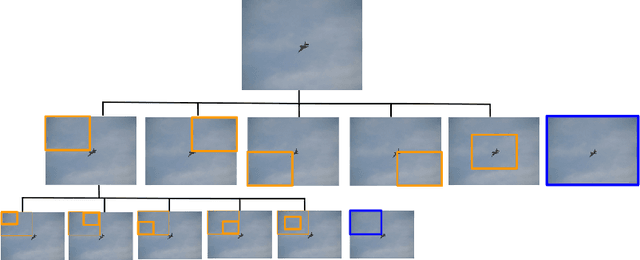
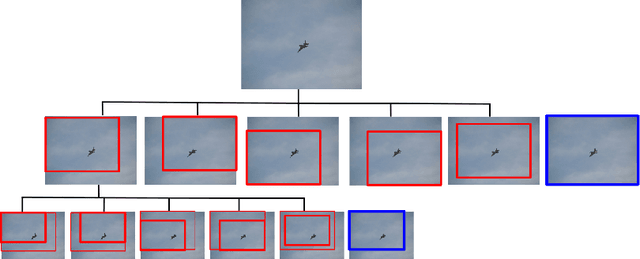
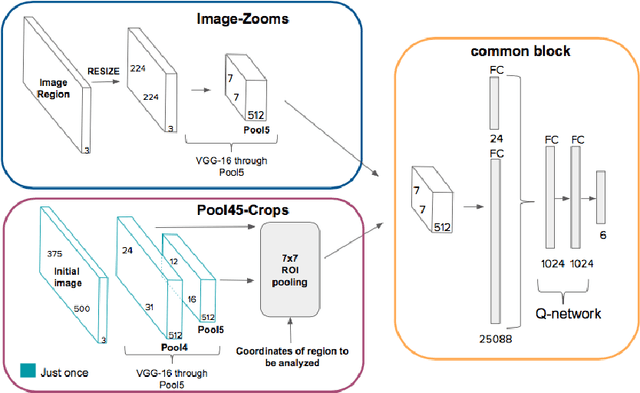

We present a method for performing hierarchical object detection in images guided by a deep reinforcement learning agent. The key idea is to focus on those parts of the image that contain richer information and zoom on them. We train an intelligent agent that, given an image window, is capable of deciding where to focus the attention among five different predefined region candidates (smaller windows). This procedure is iterated providing a hierarchical image analysis.We compare two different candidate proposal strategies to guide the object search: with and without overlap. Moreover, our work compares two different strategies to extract features from a convolutional neural network for each region proposal: a first one that computes new feature maps for each region proposal, and a second one that computes the feature maps for the whole image to later generate crops for each region proposal. Experiments indicate better results for the overlapping candidate proposal strategy and a loss of performance for the cropped image features due to the loss of spatial resolution. We argue that, while this loss seems unavoidable when working with large amounts of object candidates, the much more reduced amount of region proposals generated by our reinforcement learning agent allows considering to extract features for each location without sharing convolutional computation among regions.
Open-Ended Visual Question-Answering
Oct 09, 2016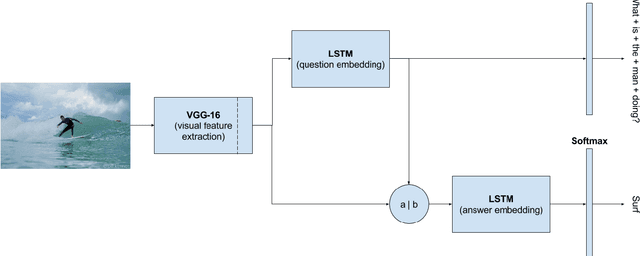
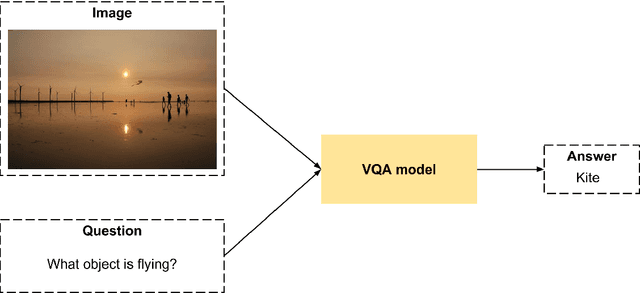
This thesis report studies methods to solve Visual Question-Answering (VQA) tasks with a Deep Learning framework. As a preliminary step, we explore Long Short-Term Memory (LSTM) networks used in Natural Language Processing (NLP) to tackle Question-Answering (text based). We then modify the previous model to accept an image as an input in addition to the question. For this purpose, we explore the VGG-16 and K-CNN convolutional neural networks to extract visual features from the image. These are merged with the word embedding or with a sentence embedding of the question to predict the answer. This work was successfully submitted to the Visual Question Answering Challenge 2016, where it achieved a 53,62% of accuracy in the test dataset. The developed software has followed the best programming practices and Python code style, providing a consistent baseline in Keras for different configurations.
Faster R-CNN Features for Instance Search
Apr 29, 2016
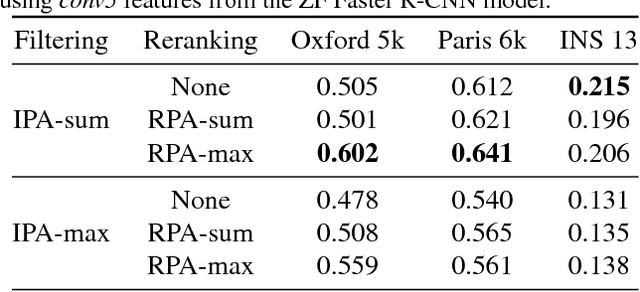
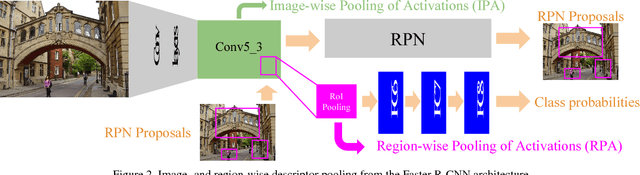
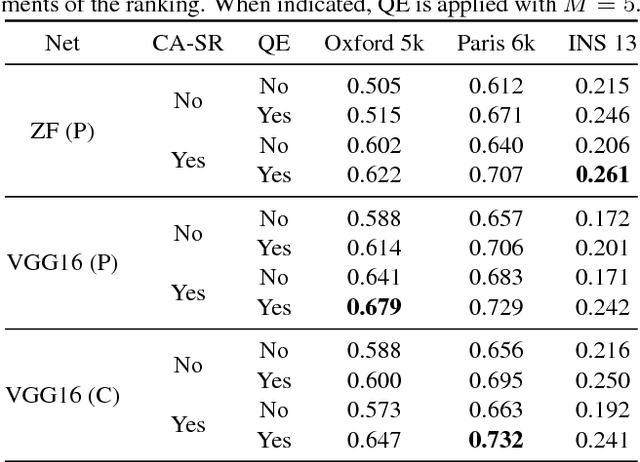
Image representations derived from pre-trained Convolutional Neural Networks (CNNs) have become the new state of the art in computer vision tasks such as instance retrieval. This work explores the suitability for instance retrieval of image- and region-wise representations pooled from an object detection CNN such as Faster R-CNN. We take advantage of the object proposals learned by a Region Proposal Network (RPN) and their associated CNN features to build an instance search pipeline composed of a first filtering stage followed by a spatial reranking. We further investigate the suitability of Faster R-CNN features when the network is fine-tuned for the same objects one wants to retrieve. We assess the performance of our proposed system with the Oxford Buildings 5k, Paris Buildings 6k and a subset of TRECVid Instance Search 2013, achieving competitive results.
Bags of Local Convolutional Features for Scalable Instance Search
Apr 15, 2016
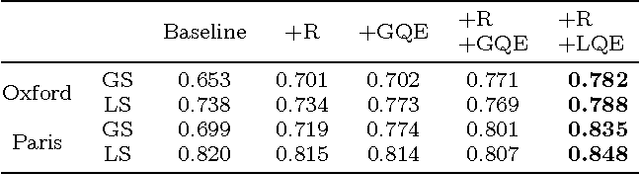

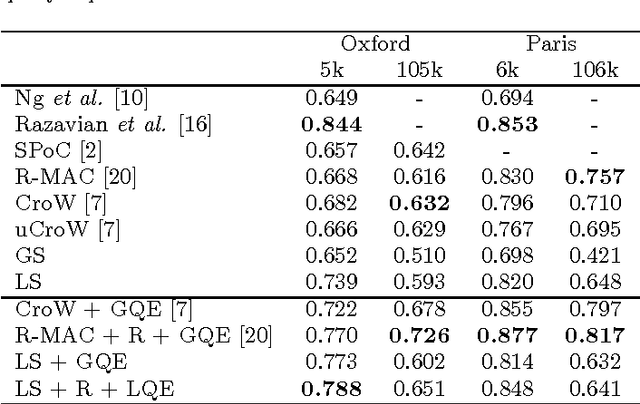
This work proposes a simple instance retrieval pipeline based on encoding the convolutional features of CNN using the bag of words aggregation scheme (BoW). Assigning each local array of activations in a convolutional layer to a visual word produces an \textit{assignment map}, a compact representation that relates regions of an image with a visual word. We use the assignment map for fast spatial reranking, obtaining object localizations that are used for query expansion. We demonstrate the suitability of the BoW representation based on local CNN features for instance retrieval, achieving competitive performance on the Oxford and Paris buildings benchmarks. We show that our proposed system for CNN feature aggregation with BoW outperforms state-of-the-art techniques using sum pooling at a subset of the challenging TRECVid INS benchmark.
Shallow and Deep Convolutional Networks for Saliency Prediction
Mar 02, 2016
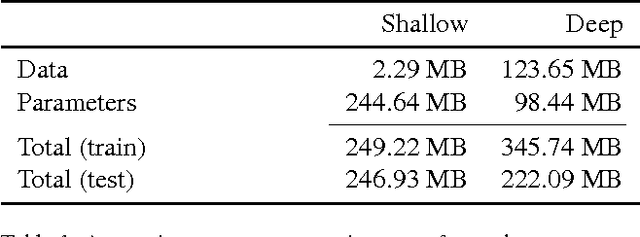
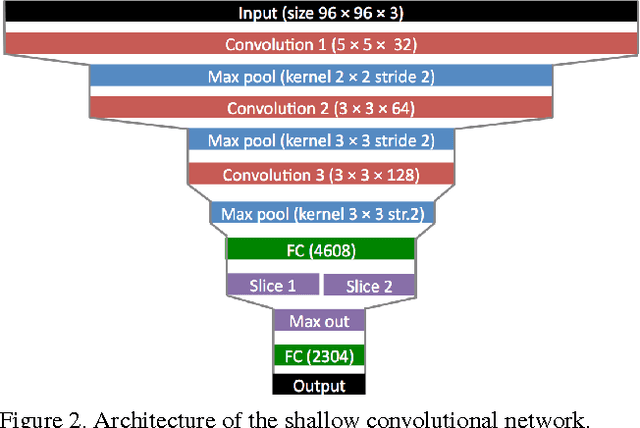

The prediction of salient areas in images has been traditionally addressed with hand-crafted features based on neuroscience principles. This paper, however, addresses the problem with a completely data-driven approach by training a convolutional neural network (convnet). The learning process is formulated as a minimization of a loss function that measures the Euclidean distance of the predicted saliency map with the provided ground truth. The recent publication of large datasets of saliency prediction has provided enough data to train end-to-end architectures that are both fast and accurate. Two designs are proposed: a shallow convnet trained from scratch, and a another deeper solution whose first three layers are adapted from another network trained for classification. To the authors knowledge, these are the first end-to-end CNNs trained and tested for the purpose of saliency prediction.
Cultural Event Recognition with Visual ConvNets and Temporal Models
Apr 24, 2015

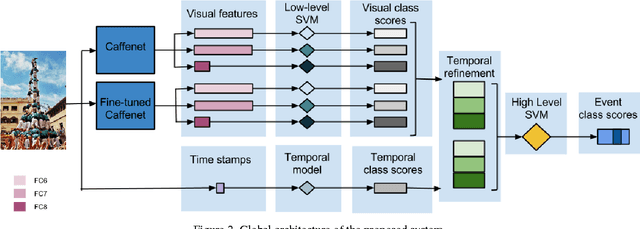

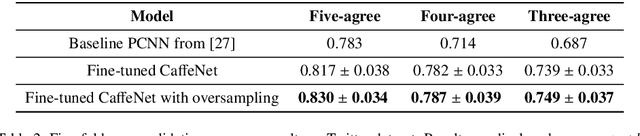
This paper presents our contribution to the ChaLearn Challenge 2015 on Cultural Event Classification. The challenge in this task is to automatically classify images from 50 different cultural events. Our solution is based on the combination of visual features extracted from convolutional neural networks with temporal information using a hierarchical classifier scheme. We extract visual features from the last three fully connected layers of both CaffeNet (pretrained with ImageNet) and our fine tuned version for the ChaLearn challenge. We propose a late fusion strategy that trains a separate low-level SVM on each of the extracted neural codes. The class predictions of the low-level SVMs form the input to a higher level SVM, which gives the final event scores. We achieve our best result by adding a temporal refinement step into our classification scheme, which is applied directly to the output of each low-level SVM. Our approach penalizes high classification scores based on visual features when their time stamp does not match well an event-specific temporal distribution learned from the training and validation data. Our system achieved the second best result in the ChaLearn Challenge 2015 on Cultural Event Classification with a mean average precision of 0.767 on the test set.
Object Segmentation in Images using EEG Signals
Aug 19, 2014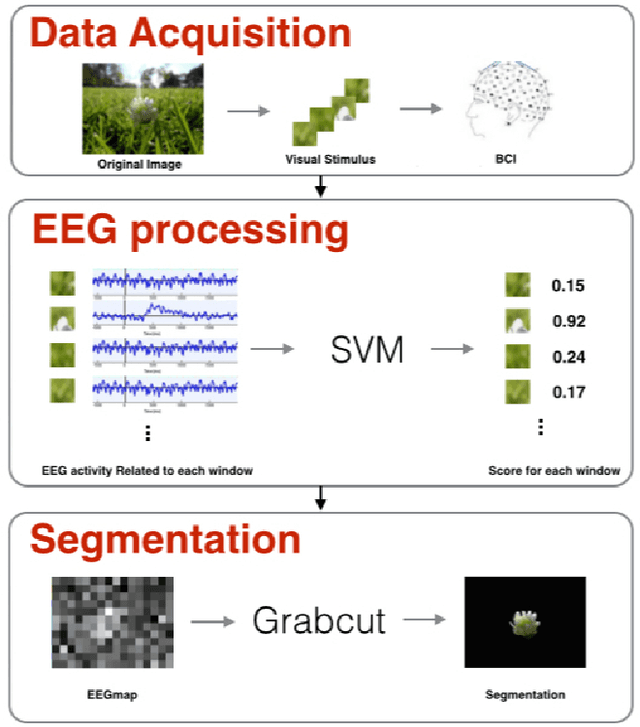



This paper explores the potential of brain-computer interfaces in segmenting objects from images. Our approach is centered around designing an effective method for displaying the image parts to the users such that they generate measurable brain reactions. When an image region, specifically a block of pixels, is displayed we estimate the probability of the block containing the object of interest using a score based on EEG activity. After several such blocks are displayed, the resulting probability map is binarized and combined with the GrabCut algorithm to segment the image into object and background regions. This study shows that BCI and simple EEG analysis are useful in locating object boundaries in images.