 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXavier Giro-i-Nieto
Hate Speech in Pixels: Detection of Offensive Memes towards Automatic Moderation
Oct 05, 2019
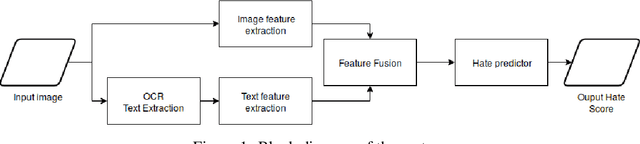
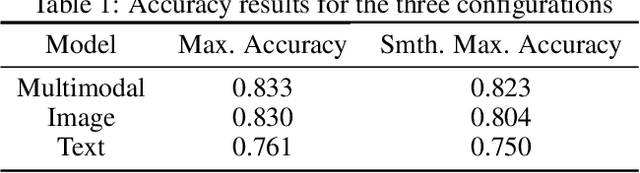
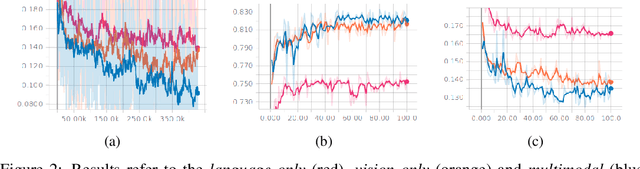

This work addresses the challenge of hate speech detection in Internet memes, and attempts using visual information to automatically detect hate speech, unlike any previous work of our knowledge. Memes are pixel-based multimedia documents that contain photos or illustrations together with phrases which, when combined, usually adopt a funny meaning. However, hate memes are also used to spread hate through social networks, so their automatic detection would help reduce their harmful societal impact. Our results indicate that the model can learn to detect some of the memes, but that the task is far from being solved with this simple architecture. While previous work focuses on linguistic hate speech, our experiments indicate how the visual modality can be much more informative for hate speech detection than the linguistic one in memes. In our experiments, we built a dataset of 5,020 memes to train and evaluate a multi-layer perceptron over the visual and language representations, whether independently or fused. The source code and mode and models are available https://github.com/imatge-upc/hate-speech-detection .
Simple vs complex temporal recurrences for video saliency prediction
Jul 16, 2019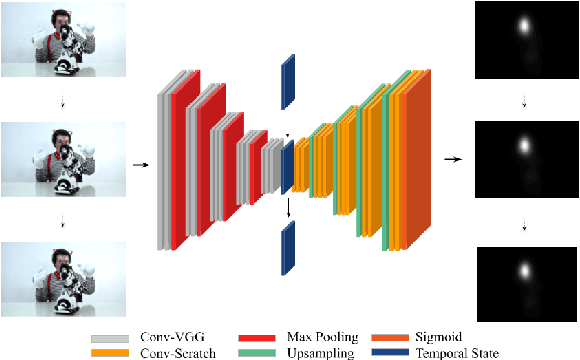
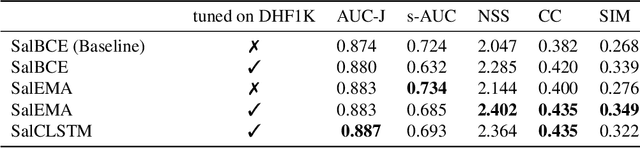
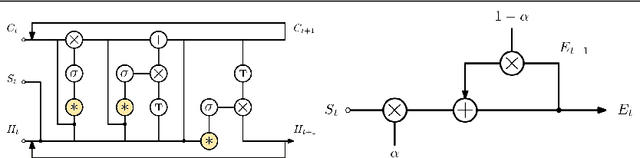
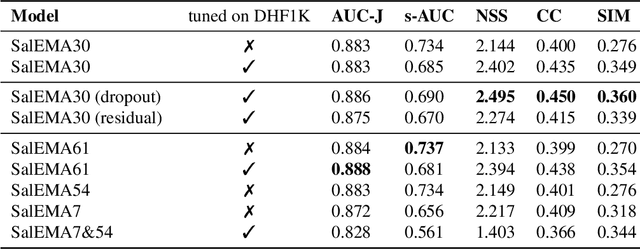
This paper investigates modifying an existing neural network architecture for static saliency prediction using two types of recurrences that integrate information from the temporal domain. The first modification is the addition of a ConvLSTM within the architecture, while the second is a conceptually simple exponential moving average of an internal convolutional state. We use weights pre-trained on the SALICON dataset and fine-tune our model on DHF1K. Our results show that both modifications achieve state-of-the-art results and produce similar saliency maps. Source code is available at https://git.io/fjPiB.
Temporal recurrences for video saliency prediction
Jul 11, 2019This paper investigates modifying an existing neural network architecture for static saliency prediction using two types of recurrences that integrate information from the temporal domain. The first modification is the addition of a ConvLSTM within the architecture, while the second is a conceptually simple exponential moving average of an internal convolutional state. We use weights pre-trained on the SALICON dataset and fine-tune our model on DHF1K. Our results show that both modifications achieve state-of-the-art results and produce similar saliency maps. Source code is available at https://git.io/fjPiB.
Budget-aware Semi-Supervised Semantic and Instance Segmentation
May 23, 2019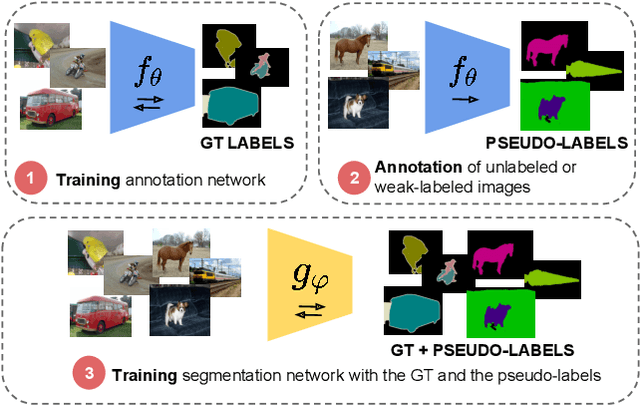


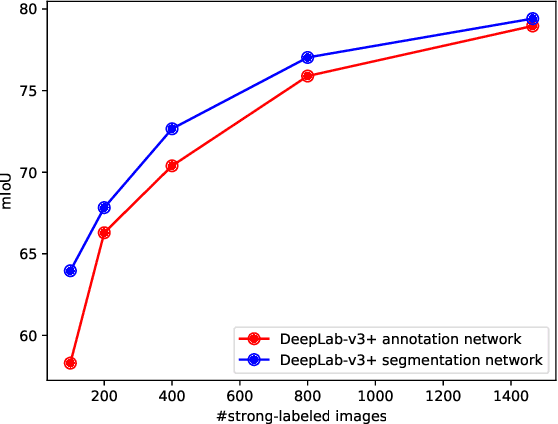
Methods that move towards less supervised scenarios are key for image segmentation, as dense labels demand significant human intervention. Generally, the annotation burden is mitigated by labeling datasets with weaker forms of supervision, e.g. image-level labels or bounding boxes. Another option are semi-supervised settings, that commonly leverage a few strong annotations and a huge number of unlabeled/weakly-labeled data. In this paper, we revisit semi-supervised segmentation schemes and narrow down significantly the annotation budget (in terms of total labeling time of the training set) compared to previous approaches. With a very simple pipeline, we demonstrate that at low annotation budgets, semi-supervised methods outperform by a wide margin weakly-supervised ones for both semantic and instance segmentation. Our approach also outperforms previous semi-supervised works at a much reduced labeling cost. We present results for the Pascal VOC benchmark and unify weakly and semi-supervised approaches by considering the total annotation budget, thus allowing a fairer comparison between methods.
Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks
Mar 25, 2019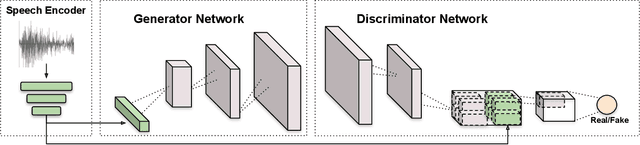
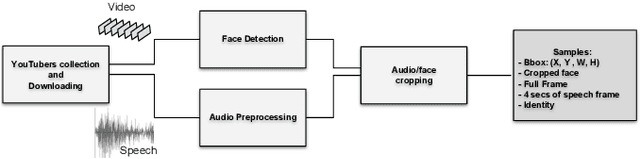


Speech is a rich biometric signal that contains information about the identity, gender and emotional state of the speaker. In this work, we explore its potential to generate face images of a speaker by conditioning a Generative Adversarial Network (GAN) with raw speech input. We propose a deep neural network that is trained from scratch in an end-to-end fashion, generating a face directly from the raw speech waveform without any additional identity information (e.g reference image or one-hot encoding). Our model is trained in a self-supervised approach by exploiting the audio and visual signals naturally aligned in videos. With the purpose of training from video data, we present a novel dataset collected for this work, with high-quality videos of youtubers with notable expressiveness in both the speech and visual signals.
RVOS: End-to-End Recurrent Network for Video Object Segmentation
Mar 13, 2019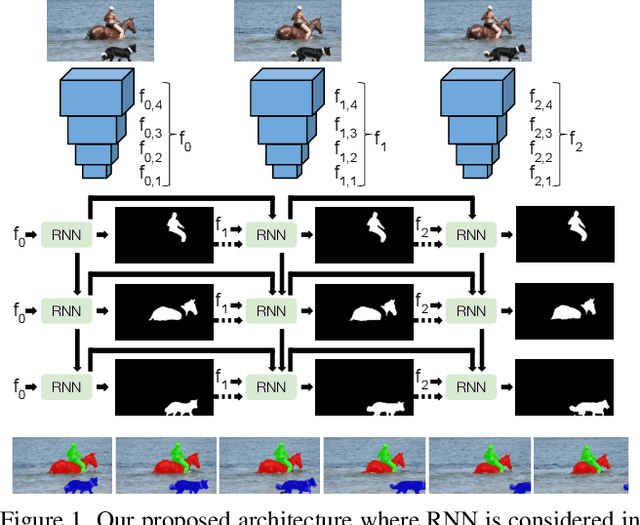
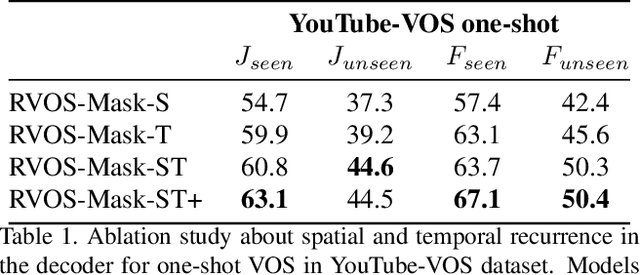
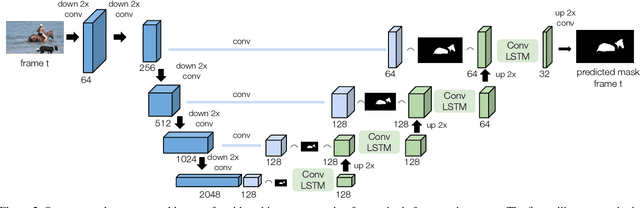
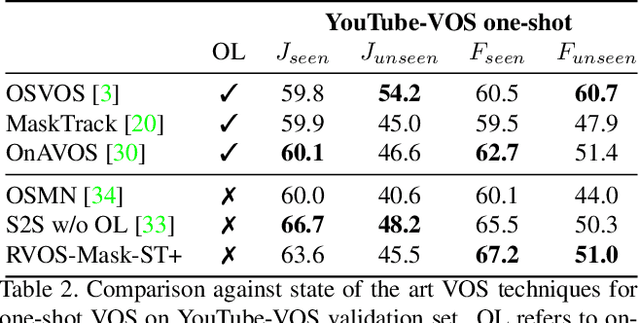
Multiple object video object segmentation is a challenging task, specially for the zero-shot case, when no object mask is given at the initial frame and the model has to find the objects to be segmented along the sequence. In our work, we propose a Recurrent network for multiple object Video Object Segmentation (RVOS) that is fully end-to-end trainable. Our model incorporates recurrence on two different domains: (i) the spatial, which allows to discover the different object instances within a frame, and (ii) the temporal, which allows to keep the coherence of the segmented objects along time. We train RVOS for zero-shot video object segmentation and are the first ones to report quantitative results for DAVIS-2017 and YouTube-VOS benchmarks. Further, we adapt RVOS for one-shot video object segmentation by using the masks obtained in previous time steps as inputs to be processed by the recurrent module. Our model reaches comparable results to state-of-the-art techniques in YouTube-VOS benchmark and outperforms all previous video object segmentation methods not using online learning in the DAVIS-2017 benchmark. Moreover, our model achieves faster inference runtimes than previous methods, reaching 44ms/frame on a P100 GPU.
Inverse Cooking: Recipe Generation from Food Images
Dec 14, 2018



People enjoy food photography because they appreciate food. Behind each meal there is a story described in a complex recipe and, unfortunately, by simply looking at a food image we do not have access to its preparation process. Therefore, in this paper we introduce an inverse cooking system that recreates cooking recipes given food images. Our system predicts ingredients as sets by means of a novel architecture, modeling their dependencies without imposing any order, and then generates cooking instructions by attending to both image and its inferred ingredients simultaneously. We extensively evaluate the whole system on the large-scale Recipe1M dataset and show that (1) we improve performance w.r.t. previous baselines for ingredient prediction; (2) we are able to obtain high quality recipes by leveraging both image and ingredients; (3) our system is able to produce more compelling recipes than retrieval-based approaches according to human judgment.
Importance Weighted Evolution Strategies
Nov 12, 2018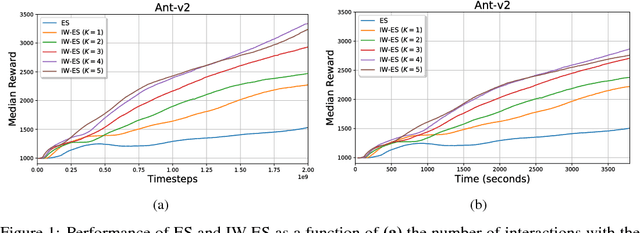
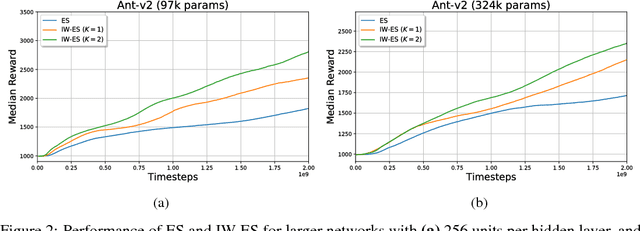
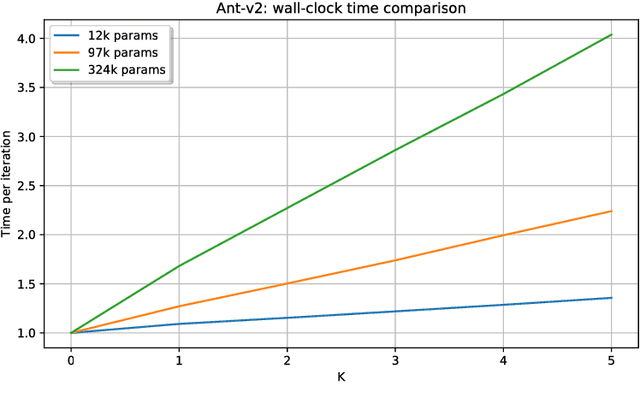
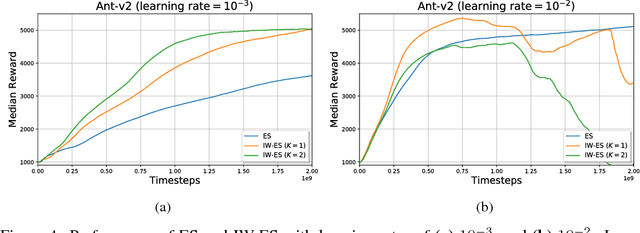
Evolution Strategies (ES) emerged as a scalable alternative to popular Reinforcement Learning (RL) techniques, providing an almost perfect speedup when distributed across hundreds of CPU cores thanks to a reduced communication overhead. Despite providing large improvements in wall-clock time, ES is data inefficient when compared to competing RL methods. One of the main causes of such inefficiency is the collection of large batches of experience, which are discarded after each policy update. In this work, we study how to perform more than one update per batch of experience by means of Importance Sampling while preserving the scalability of the original method. The proposed method, Importance Weighted Evolution Strategies (IW-ES), shows promising results and is a first step towards designing efficient ES algorithms.
Temporal Saliency Adaptation in Egocentric Videos
Sep 04, 2018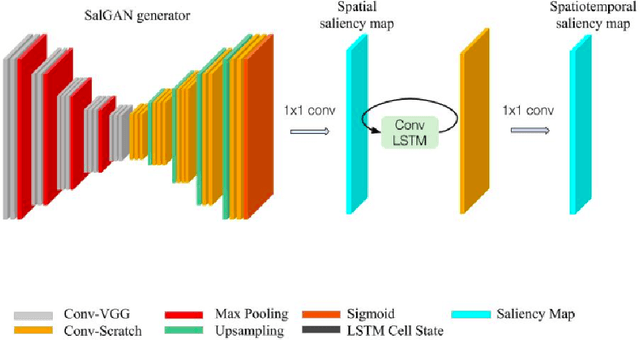
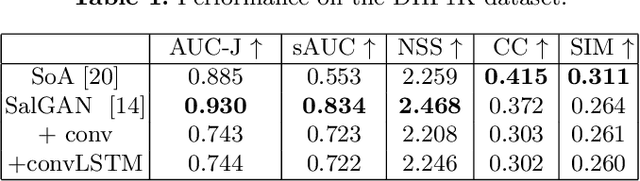
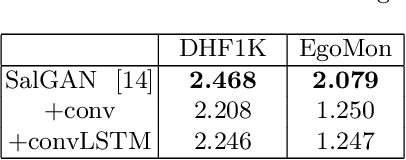
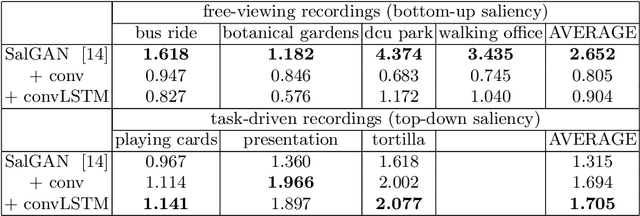
This work adapts a deep neural model for image saliency prediction to the temporal domain of egocentric video. We compute the saliency map for each video frame, firstly with an off-the-shelf model trained from static images, secondly by adding a a convolutional or conv-LSTM layers trained with a dataset for video saliency prediction. We study each configuration on EgoMon, a new dataset made of seven egocentric videos recorded by three subjects in both free-viewing and task-driven set ups. Our results indicate that the temporal adaptation is beneficial when the viewer is not moving and observing the scene from a narrow field of view. Encouraged by this observation, we compute and publish the saliency maps for the EPIC Kitchens dataset, in which viewers are cooking. Source code and models available at https://imatge-upc.github.io/saliency-2018-videosalgan/