 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Sequence Training of Recurrent Neural Networks with Connectionist Temporal Classification
Feb 02, 2017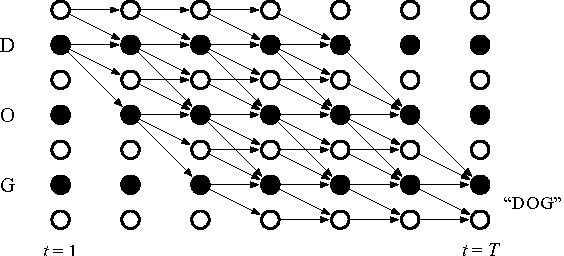
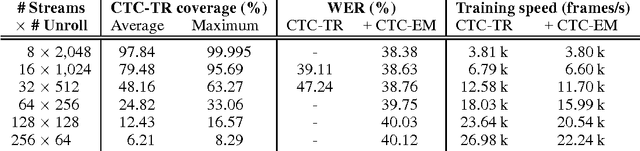
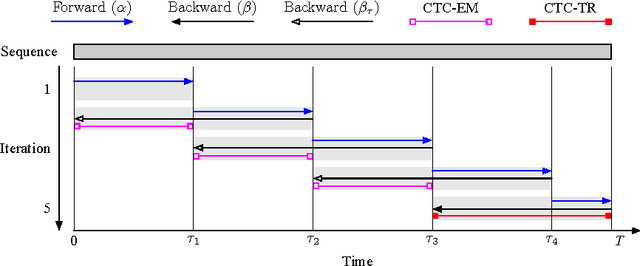
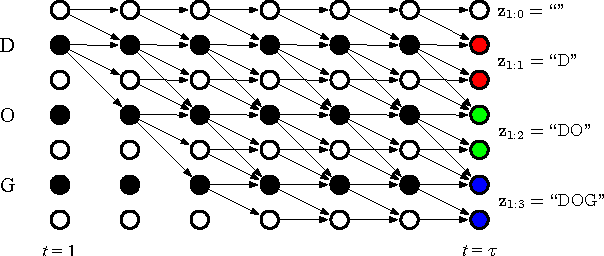
Connectionist temporal classification (CTC) based supervised sequence training of recurrent neural networks (RNNs) has shown great success in many machine learning areas including end-to-end speech and handwritten character recognition. For the CTC training, however, it is required to unroll (or unfold) the RNN by the length of an input sequence. This unrolling requires a lot of memory and hinders a small footprint implementation of online learning or adaptation. Furthermore, the length of training sequences is usually not uniform, which makes parallel training with multiple sequences inefficient on shared memory models such as graphics processing units (GPUs). In this work, we introduce an expectation-maximization (EM) based online CTC algorithm that enables unidirectional RNNs to learn sequences that are longer than the amount of unrolling. The RNNs can also be trained to process an infinitely long input sequence without pre-segmentation or external reset. Moreover, the proposed approach allows efficient parallel training on GPUs. For evaluation, phoneme recognition and end-to-end speech recognition examples are presented on the TIMIT and Wall Street Journal (WSJ) corpora, respectively. Our online model achieves 20.7% phoneme error rate (PER) on the very long input sequence that is generated by concatenating all 192 utterances in the TIMIT core test set. On WSJ, a network can be trained with only 64 times of unrolling while sacrificing 4.5% relative word error rate (WER).
Quantized neural network design under weight capacity constraint
Nov 19, 2016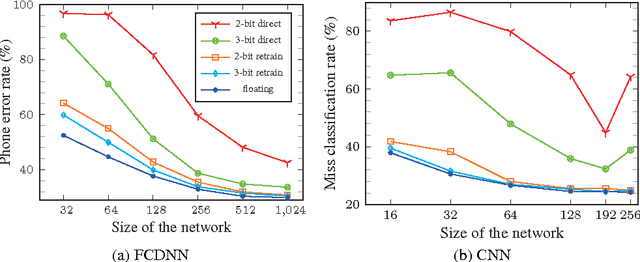
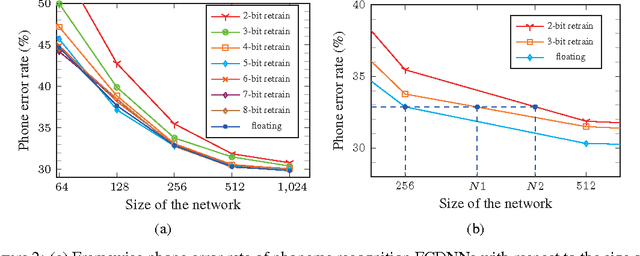
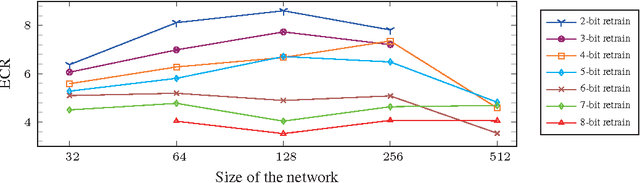
The complexity of deep neural network algorithms for hardware implementation can be lowered either by scaling the number of units or reducing the word-length of weights. Both approaches, however, can accompany the performance degradation although many types of research are conducted to relieve this problem. Thus, it is an important question which one, between the network size scaling and the weight quantization, is more effective for hardware optimization. For this study, the performances of fully-connected deep neural networks (FCDNNs) and convolutional neural networks (CNNs) are evaluated while changing the network complexity and the word-length of weights. Based on these experiments, we present the effective compression ratio (ECR) to guide the trade-off between the network size and the precision of weights when the hardware resource is limited.
Compact Deep Convolutional Neural Networks With Coarse Pruning
Oct 30, 2016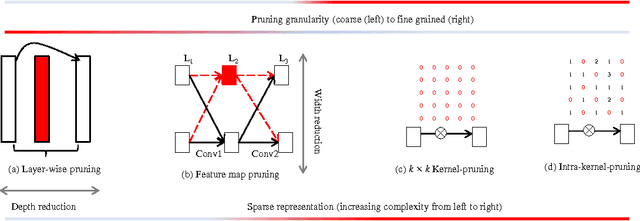

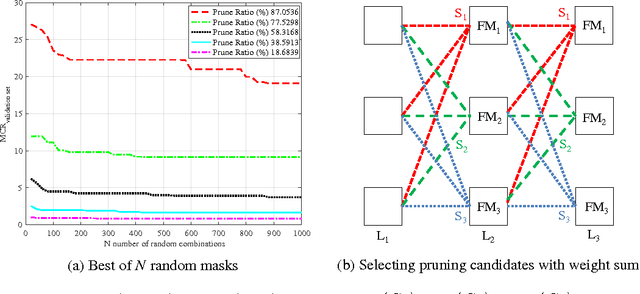
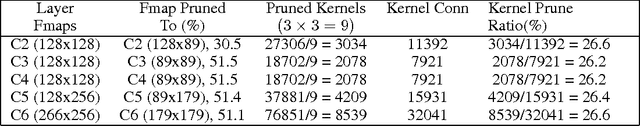
The learning capability of a neural network improves with increasing depth at higher computational costs. Wider layers with dense kernel connectivity patterns furhter increase this cost and may hinder real-time inference. We propose feature map and kernel level pruning for reducing the computational complexity of a deep convolutional neural network. Pruning feature maps reduces the width of a layer and hence does not need any sparse representation. Further, kernel pruning converts the dense connectivity pattern into a sparse one. Due to coarse nature, these pruning granularities can be exploited by GPUs and VLSI based implementations. We propose a simple and generic strategy to choose the least adversarial pruning masks for both granularities. The pruned networks are retrained which compensates the loss in accuracy. We obtain the best pruning ratios when we prune a network with both granularities. Experiments with the CIFAR-10 dataset show that more than 85% sparsity can be induced in the convolution layers with less than 1% increase in the missclassification rate of the baseline network.
FPGA-Based Low-Power Speech Recognition with Recurrent Neural Networks
Sep 30, 2016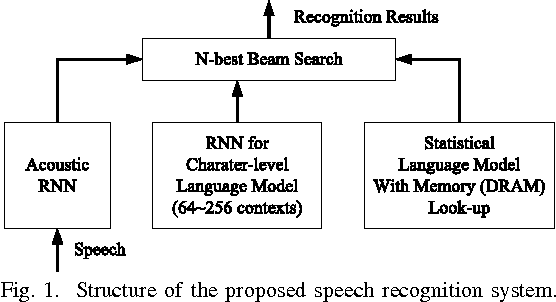
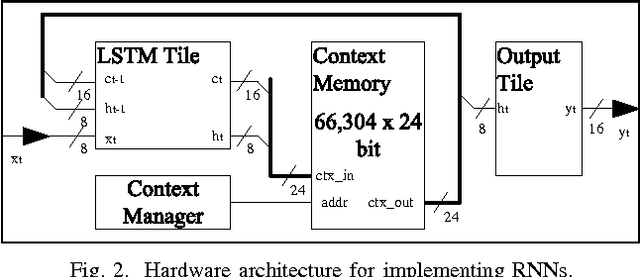
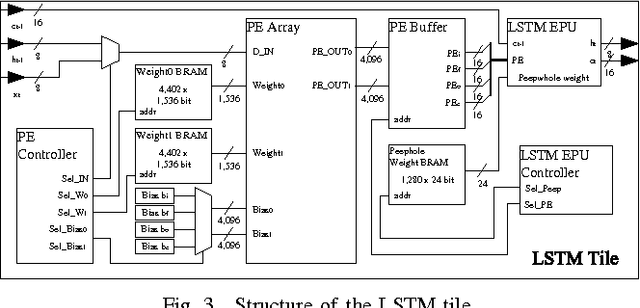
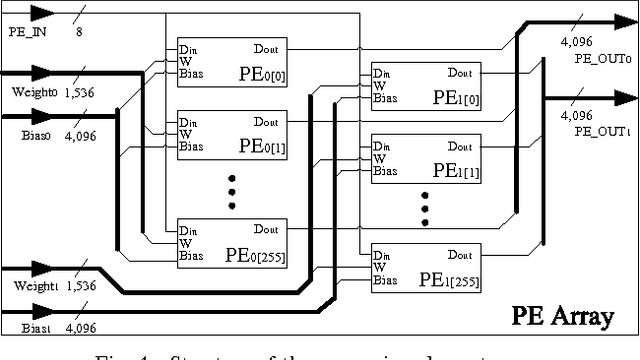
In this paper, a neural network based real-time speech recognition (SR) system is developed using an FPGA for very low-power operation. The implemented system employs two recurrent neural networks (RNNs); one is a speech-to-character RNN for acoustic modeling (AM) and the other is for character-level language modeling (LM). The system also employs a statistical word-level LM to improve the recognition accuracy. The results of the AM, the character-level LM, and the word-level LM are combined using a fairly simple N-best search algorithm instead of the hidden Markov model (HMM) based network. The RNNs are implemented using massively parallel processing elements (PEs) for low latency and high throughput. The weights are quantized to 6 bits to store all of them in the on-chip memory of an FPGA. The proposed algorithm is implemented on a Xilinx XC7Z045, and the system can operate much faster than real-time.
Fixed-Point Performance Analysis of Recurrent Neural Networks
Sep 27, 2016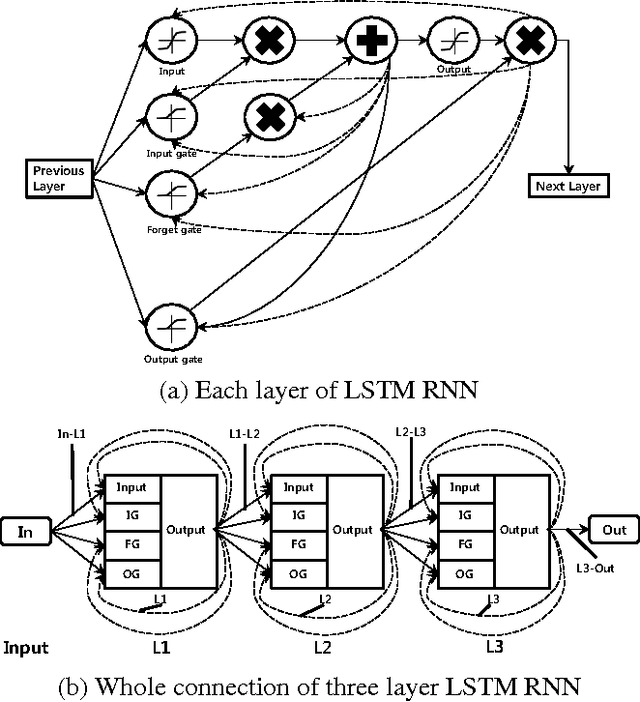
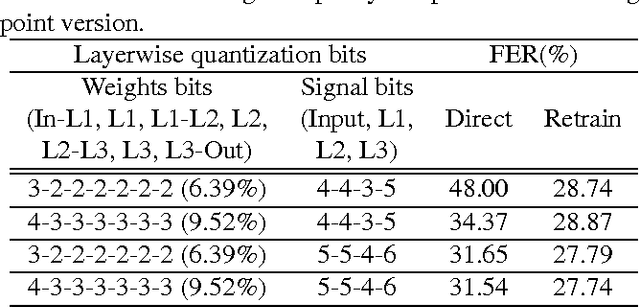
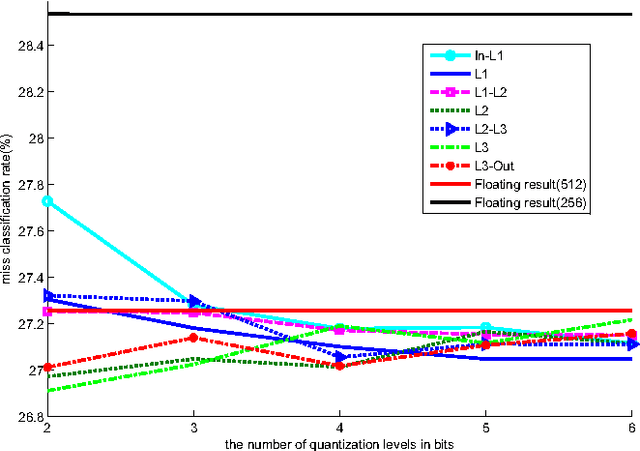
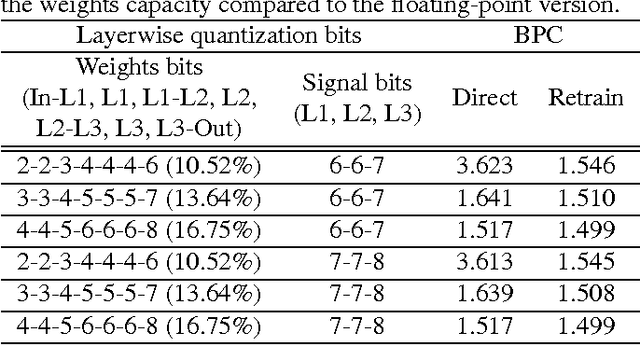
Recurrent neural networks have shown excellent performance in many applications, however they require increased complexity in hardware or software based implementations. The hardware complexity can be much lowered by minimizing the word-length of weights and signals. This work analyzes the fixed-point performance of recurrent neural networks using a retrain based quantization method. The quantization sensitivity of each layer in RNNs is studied, and the overall fixed-point optimization results minimizing the capacity of weights while not sacrificing the performance are presented. A language model and a phoneme recognition examples are used.
FPGA Based Implementation of Deep Neural Networks Using On-chip Memory Only
Aug 29, 2016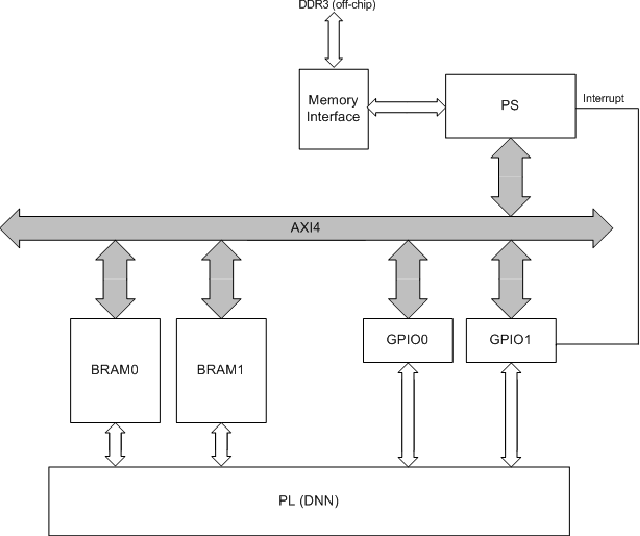
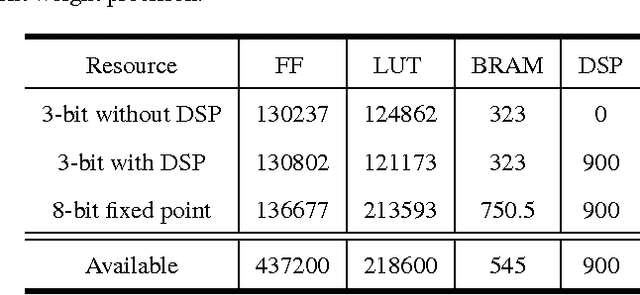
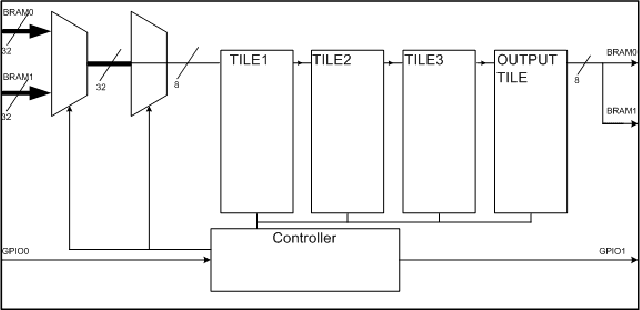
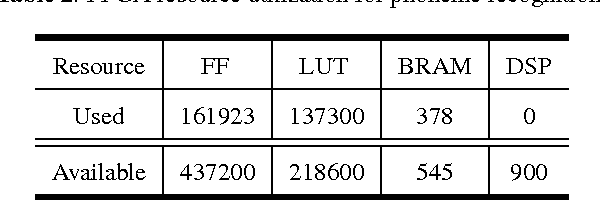
Deep neural networks (DNNs) demand a very large amount of computation and weight storage, and thus efficient implementation using special purpose hardware is highly desired. In this work, we have developed an FPGA based fixed-point DNN system using only on-chip memory not to access external DRAM. The execution time and energy consumption of the developed system is compared with a GPU based implementation. Since the capacity of memory in FPGA is limited, only 3-bit weights are used for this implementation, and training based fixed-point weight optimization is employed. The implementation using Xilinx XC7Z045 is tested for the MNIST handwritten digit recognition benchmark and a phoneme recognition task on TIMIT corpus. The obtained speed is about one quarter of a GPU based implementation and much better than that of a PC based one. The power consumption is less than 5 Watt at the full speed operation resulting in much higher efficiency compared to GPU based systems.
Dynamic Hand Gesture Recognition for Wearable Devices with Low Complexity Recurrent Neural Networks
Aug 14, 2016
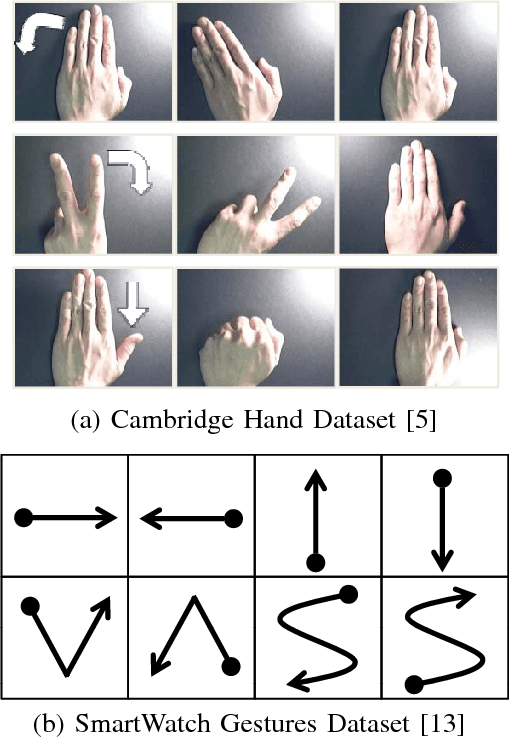

Gesture recognition is a very essential technology for many wearable devices. While previous algorithms are mostly based on statistical methods including the hidden Markov model, we develop two dynamic hand gesture recognition techniques using low complexity recurrent neural network (RNN) algorithms. One is based on video signal and employs a combined structure of a convolutional neural network (CNN) and an RNN. The other uses accelerometer data and only requires an RNN. Fixed-point optimization that quantizes most of the weights into two bits is conducted to optimize the amount of memory size for weight storage and reduce the power consumption in hardware and software based implementations.
Character-Level Incremental Speech Recognition with Recurrent Neural Networks
Jan 28, 2016
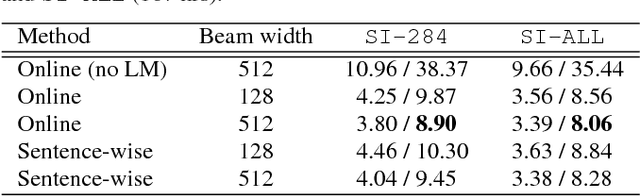
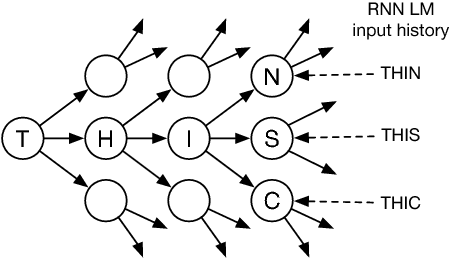

In real-time speech recognition applications, the latency is an important issue. We have developed a character-level incremental speech recognition (ISR) system that responds quickly even during the speech, where the hypotheses are gradually improved while the speaking proceeds. The algorithm employs a speech-to-character unidirectional recurrent neural network (RNN), which is end-to-end trained with connectionist temporal classification (CTC), and an RNN-based character-level language model (LM). The output values of the CTC-trained RNN are character-level probabilities, which are processed by beam search decoding. The RNN LM augments the decoding by providing long-term dependency information. We propose tree-based online beam search with additional depth-pruning, which enables the system to process infinitely long input speech with low latency. This system not only responds quickly on speech but also can dictate out-of-vocabulary (OOV) words according to pronunciation. The proposed model achieves the word error rate (WER) of 8.90% on the Wall Street Journal (WSJ) Nov'92 20K evaluation set when trained on the WSJ SI-284 training set.
Resiliency of Deep Neural Networks under Quantization
Jan 07, 2016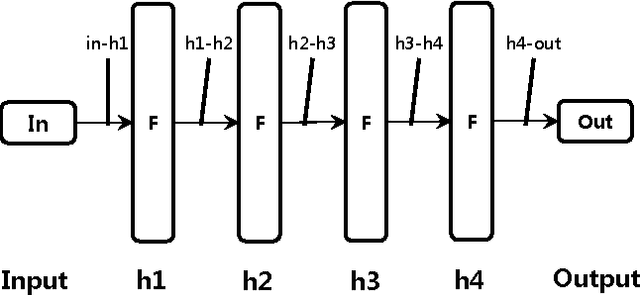
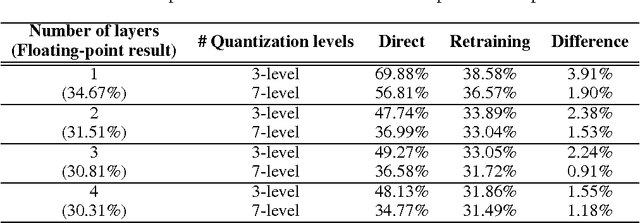
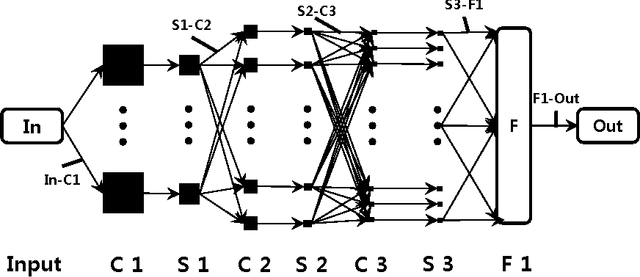
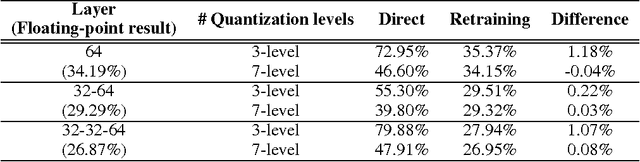
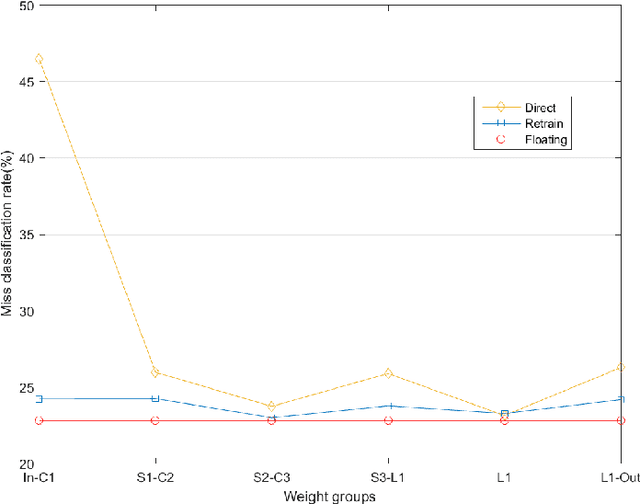
The complexity of deep neural network algorithms for hardware implementation can be much lowered by optimizing the word-length of weights and signals. Direct quantization of floating-point weights, however, does not show good performance when the number of bits assigned is small. Retraining of quantized networks has been developed to relieve this problem. In this work, the effects of retraining are analyzed for a feedforward deep neural network (FFDNN) and a convolutional neural network (CNN). The network complexity is controlled to know their effects on the resiliency of quantized networks by retraining. The complexity of the FFDNN is controlled by varying the unit size in each hidden layer and the number of layers, while that of the CNN is done by modifying the feature map configuration. We find that the performance gap between the floating-point and the retrain-based ternary (+1, 0, -1) weight neural networks exists with a fair amount in 'complexity limited' networks, but the discrepancy almost vanishes in fully complex networks whose capability is limited by the training data, rather than by the number of connections. This research shows that highly complex DNNs have the capability of absorbing the effects of severe weight quantization through retraining, but connection limited networks are less resilient. This paper also presents the effective compression ratio to guide the trade-off between the network size and the precision when the hardware resource is limited.
Online Keyword Spotting with a Character-Level Recurrent Neural Network
Dec 30, 2015
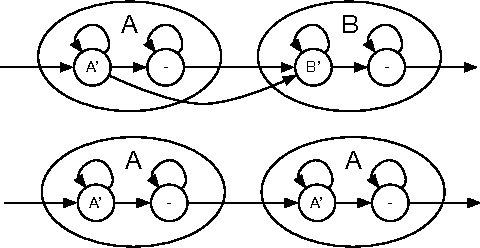
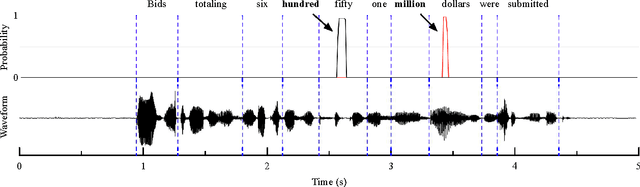
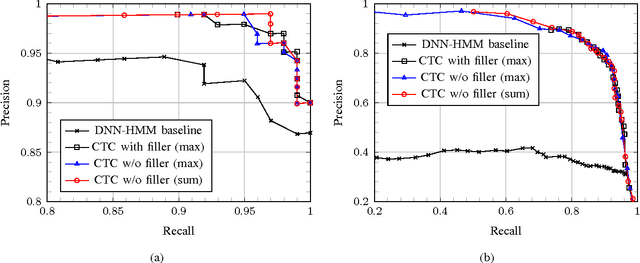
In this paper, we propose a context-aware keyword spotting model employing a character-level recurrent neural network (RNN) for spoken term detection in continuous speech. The RNN is end-to-end trained with connectionist temporal classification (CTC) to generate the probabilities of character and word-boundary labels. There is no need for the phonetic transcription, senone modeling, or system dictionary in training and testing. Also, keywords can easily be added and modified by editing the text based keyword list without retraining the RNN. Moreover, the unidirectional RNN processes an infinitely long input audio streams without pre-segmentation and keywords are detected with low-latency before the utterance is finished. Experimental results show that the proposed keyword spotter significantly outperforms the deep neural network (DNN) and hidden Markov model (HMM) based keyword-filler model even with less computations.