 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenwu Zhu
Automated Machine Learning on Graphs: A Survey
Mar 01, 2021
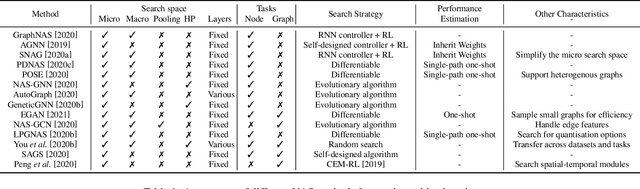
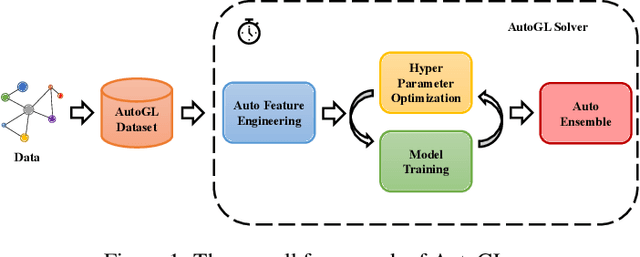

Machine learning on graphs has been extensively studied in both academic and industry. However, as the literature on graph learning booms with a vast number of emerging methods and techniques, it becomes increasingly difficult to manually design the optimal machine learning algorithm for different graph-related tasks. To solve this critical challenge, automated machine learning (AutoML) on graphs which combines the strength of graph machine learning and AutoML together, is gaining attentions from the research community. Therefore, we comprehensively survey AutoML on graphs in this paper, primarily focusing on hyper-parameter optimization (HPO) and neural architecture search (NAS) for graph machine learning. We further overview libraries related to automated graph machine learning and in depth discuss AutoGL, the first dedicated open-source library for AutoML on graphs. In the end, we share our insights on future research directions for automated graph machine learning. To the best of our knowledge, this paper is the first systematic and comprehensive review of automated machine learning on graphs.
MetaDelta: A Meta-Learning System for Few-shot Image Classification
Feb 22, 2021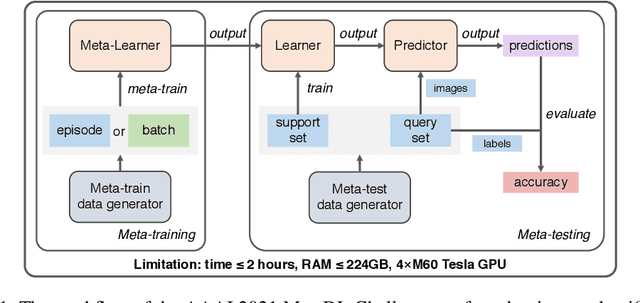

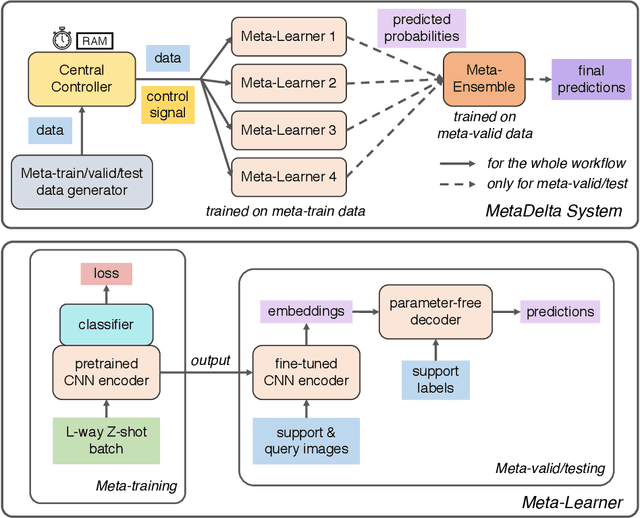
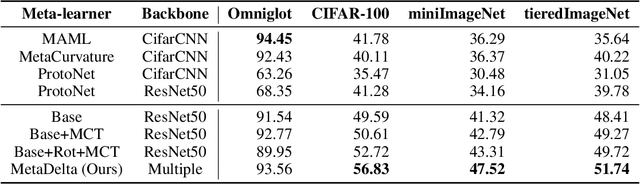
Meta-learning aims at learning quickly on novel tasks with limited data by transferring generic experience learned from previous tasks. Naturally, few-shot learning has been one of the most popular applications for meta-learning. However, existing meta-learning algorithms rarely consider the time and resource efficiency or the generalization capacity for unknown datasets, which limits their applicability in real-world scenarios. In this paper, we propose MetaDelta, a novel practical meta-learning system for the few-shot image classification. MetaDelta consists of two core components: i) multiple meta-learners supervised by a central controller to ensure efficiency, and ii) a meta-ensemble module in charge of integrated inference and better generalization. In particular, each meta-learner in MetaDelta is composed of a unique pretrained encoder fine-tuned by batch training and parameter-free decoder used for prediction. MetaDelta ranks first in the final phase in the AAAI 2021 MetaDL Challenge\footnote{https://competitions.codalab.org/competitions/26638}, demonstrating the advantages of our proposed system. The codes are publicly available at https://github.com/Frozenmad/MetaDelta.
A Closer Look at Temporal Sentence Grounding in Videos: Datasets and Metrics
Jan 27, 2021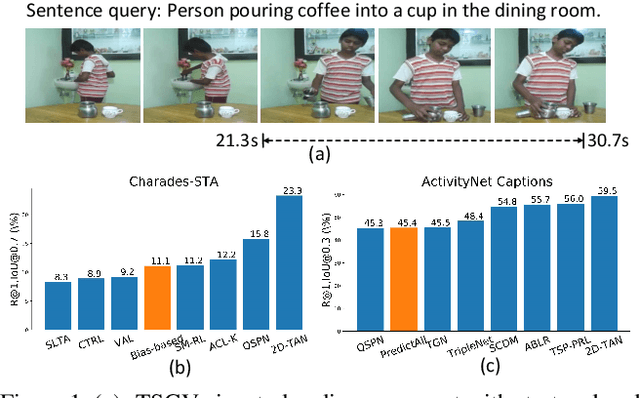
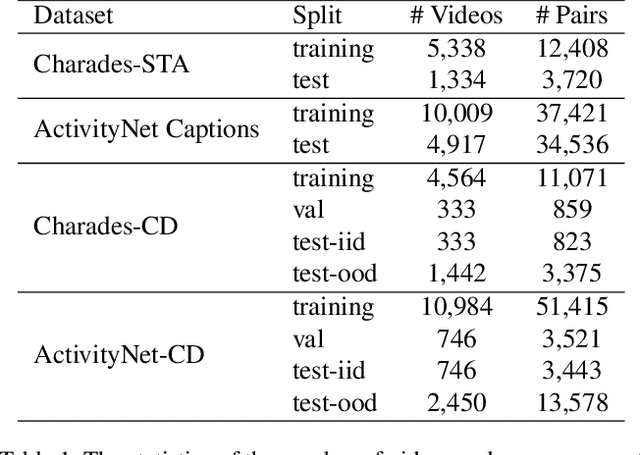
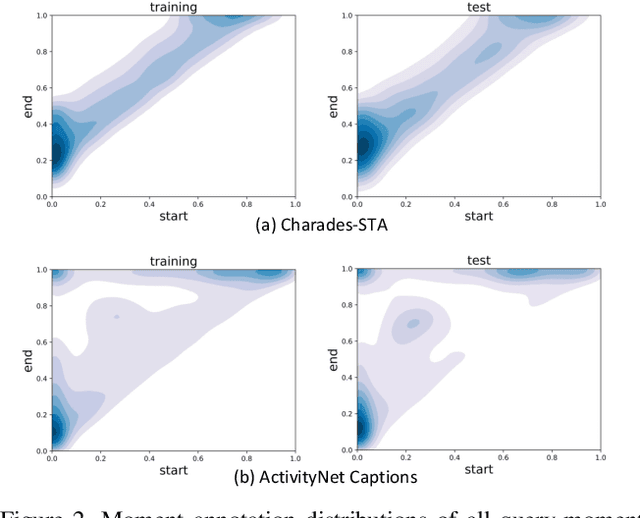
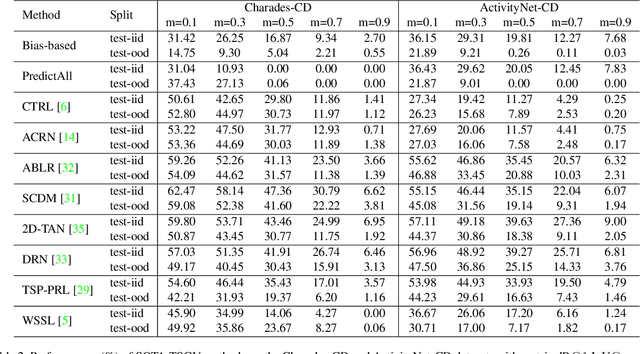
Despite Temporal Sentence Grounding in Videos (TSGV) has realized impressive progress over the last few years, current TSGV models tend to capture the moment annotation biases and fail to take full advantage of multi-modal inputs. Miraculously, some extremely simple TSGV baselines even without training can also achieve state-of-the-art performance. In this paper, we first take a closer look at the existing evaluation protocol, and argue that both the prevailing datasets and metrics are the devils to cause the unreliable benchmarking. To this end, we propose to re-organize two widely-used TSGV datasets (Charades-STA and ActivityNet Captions), and deliberately \textbf{C}hange the moment annotation \textbf{D}istribution of the test split to make it different from the training split, dubbed as Charades-CD and ActivityNet-CD, respectively. Meanwhile, we further introduce a new evaluation metric "dR@$n$,IoU@$m$" to calibrate the basic IoU scores by penalizing more on the over-long moment predictions and reduce the inflating performance caused by the moment annotation biases. Under this new evaluation protocol, we conduct extensive experiments and ablation studies on eight state-of-the-art TSGV models. All the results demonstrate that the re-organized datasets and new metric can better monitor the progress in TSGV, which is still far from satisfactory. The repository of this work is at \url{https://github.com/yytzsy/grounding_changing_distribution}.
A Comprehensive Survey on Curriculum Learning
Oct 25, 2020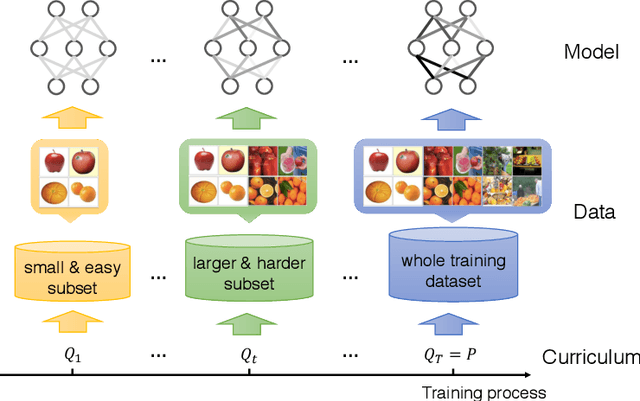
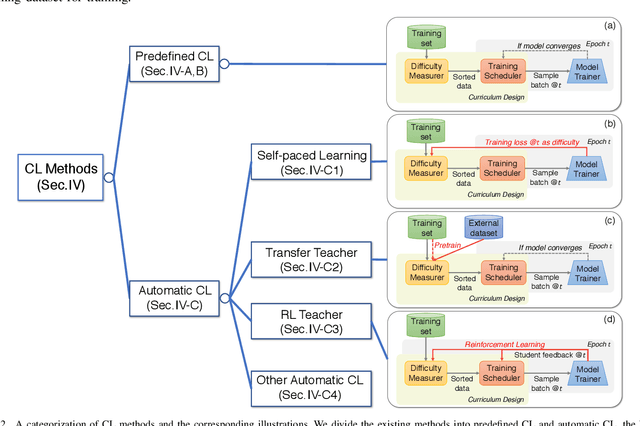
Curriculum learning (CL) is a training strategy that trains a machine learning model from easier data to harder data, which imitates the meaningful learning order in human curricula. As an easy-to-use plug-in tool, the CL strategy has demonstrated its power in improving the generalization capacity and convergence rate of various models in a wide range of scenarios such as computer vision and natural language processing, etc. In this survey article, we comprehensively review CL from various aspects including motivations, definitions, theories, and applications. We discuss works on curriculum learning within a general CL framework, elaborating on how to design a manually predefined curriculum or an automatic curriculum. In particular, we summarize existing CL designs based on the general framework of Difficulty Measurer + Training Scheduler and further categorize the methodologies for automatic CL into four groups, i.e., Self-paced Learning, Transfer Teacher, RL Teacher, and Other Automatic CL. Finally, we present brief discussions on the relationships between CL and other methods, and point out potential future research directions deserving further investigations.
Implicit Graph Neural Networks
Sep 14, 2020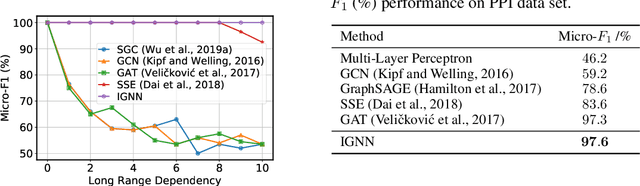
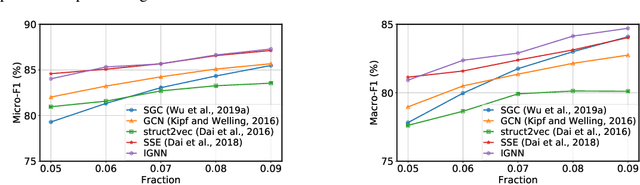
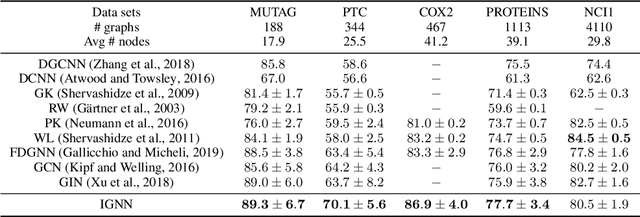
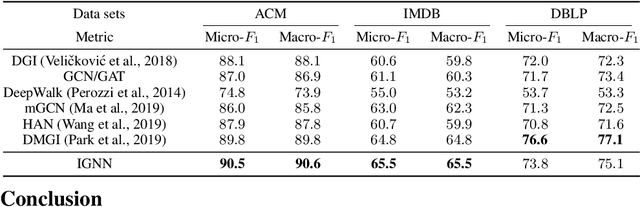
Graph Neural Networks (GNNs) are widely used deep learning models that learn meaningful representations from graph-structured data. Due to the finite nature of the underlying recurrent structure, current GNN methods may struggle to capture long-range dependencies in underlying graphs. To overcome this difficulty, we propose a graph learning framework, called Implicit Graph Neural Networks (IGNN), where predictions are based on the solution of a fixed-point equilibrium equation involving implicitly defined "state" vectors. We use the Perron-Frobenius theory to derive sufficient conditions that ensure well-posedness of the framework. Leveraging implicit differentiation, we derive a tractable projected gradient descent method to train the framework. Experiments on a comprehensive range of tasks show that IGNNs consistently capture long-range dependencies and outperform the state-of-the-art GNN models.
A Simple and General Graph Neural Network with Stochastic Message Passing
Sep 05, 2020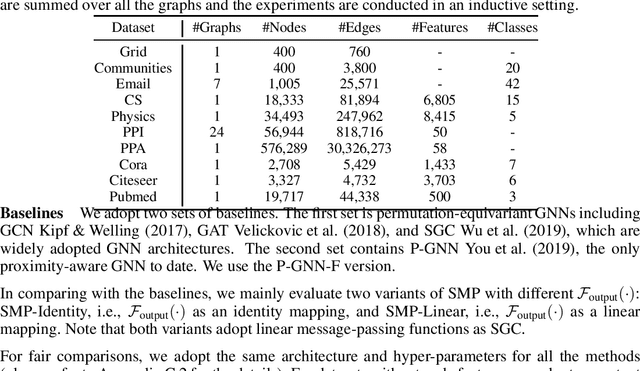
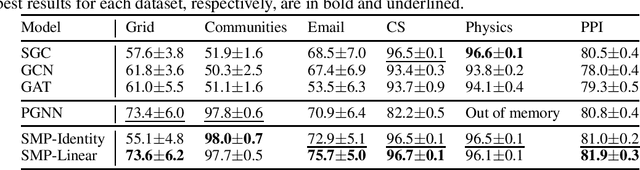
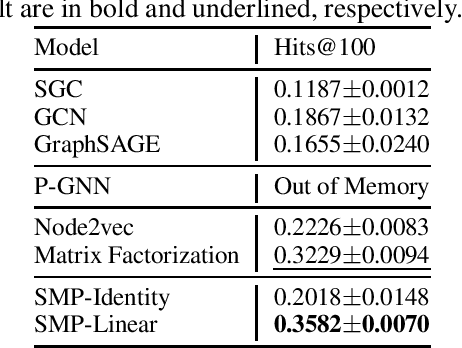
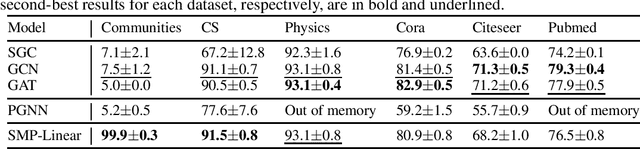
Graph neural networks (GNNs) are emerging machine learning models on graphs. One key property behind the expressiveness of existing GNNs is that the learned node representations are permutation-equivariant. Though being a desirable property for certain tasks, however, permutation-equivariance prevents GNNs from being proximity-aware, i.e., preserving the walk-based proximities between pairs of nodes, which is another critical property for graph analytical tasks. On the other hand, some variants of GNNs are proposed to preserve node proximities, but they fail to maintain permutation-equivariance. How to empower GNNs to be proximity-aware while maintaining permutation-equivariance remains an open problem. In this paper, we propose Stochastic Message Passing (SMP), a general and simple GNN to maintain both proximity-awareness and permutation-equivariance properties. Specifically, we augment the existing GNNs with stochastic node representations learned to preserve node proximities. Though seemingly simple, we prove that such a mechanism can enable GNNs to preserve node proximities in theory while maintaining permutation-equivariance with certain parametrization. Extensive experimental results demonstrate the effectiveness and efficiency of SMP for tasks including node classification and link prediction.
Eigen-GNN: A Graph Structure Preserving Plug-in for GNNs
Jun 08, 2020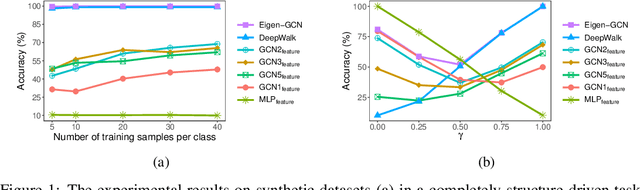
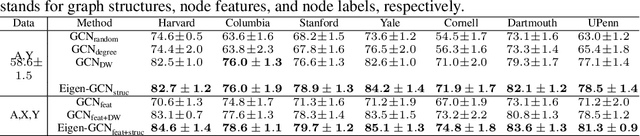
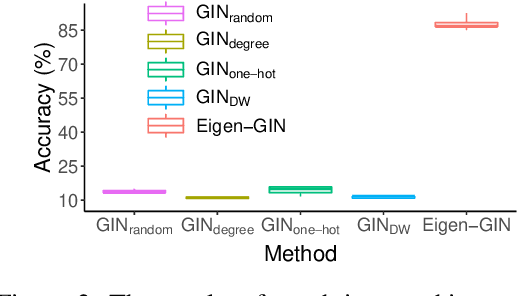

Graph Neural Networks (GNNs) are emerging machine learning models on graphs. Although sufficiently deep GNNs are shown theoretically capable of fully preserving graph structures, most existing GNN models in practice are shallow and essentially feature-centric. We show empirically and analytically that the existing shallow GNNs cannot preserve graph structures well. To overcome this fundamental challenge, we propose Eigen-GNN, a simple yet effective and general plug-in module to boost GNNs ability in preserving graph structures. Specifically, we integrate the eigenspace of graph structures with GNNs by treating GNNs as a type of dimensionality reduction and expanding the initial dimensionality reduction bases. Without needing to increase depths, Eigen-GNN possesses more flexibilities in handling both feature-driven and structure-driven tasks since the initial bases contain both node features and graph structures. We present extensive experimental results to demonstrate the effectiveness of Eigen-GNN for tasks including node classification, link prediction, and graph isomorphism tests.
Spectral Graph Attention Network
Mar 16, 2020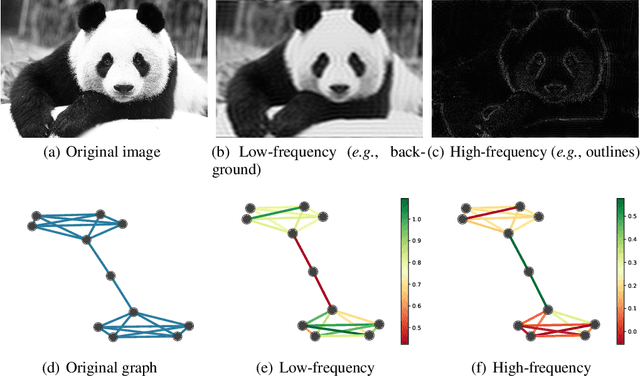
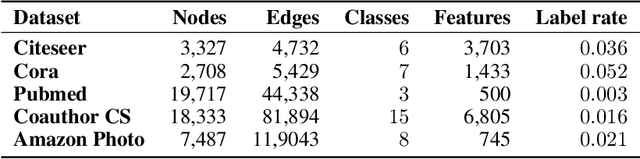
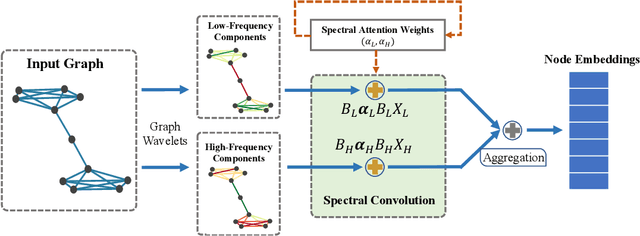
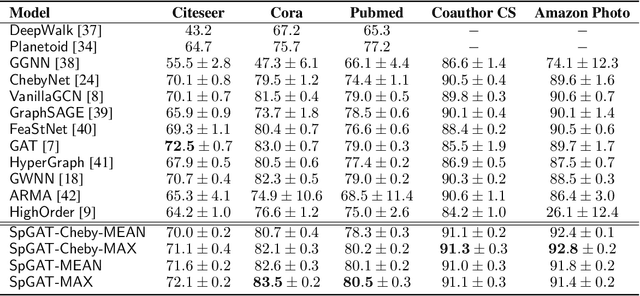
Variants of Graph Neural Networks (GNNs) for representation learning have been proposed recently and achieved fruitful results in various fields. Among them, graph attention networks (GATs) first employ a self-attention strategy to learn attention weights for each edge in the spatial domain. However, learning the attentions over edges only pays attention to the local information of graphs and greatly increases the number of parameters. In this paper, we first introduce attentions in the spectral domain of graphs. Accordingly, we present Spectral Graph Attention Network (SpGAT) that learn representations for different frequency components regarding weighted filters and graph wavelets bases. In this way, SpGAT can better capture global patterns of graphs in an efficient manner with much fewer learned parameters than that of GAT. We thoroughly evaluate the performance of SpGAT in the semi-supervised node classification task and verified the effectiveness of the learned attentions in the spectral domain.
Deep Learning for Learning Graph Representations
Jan 02, 2020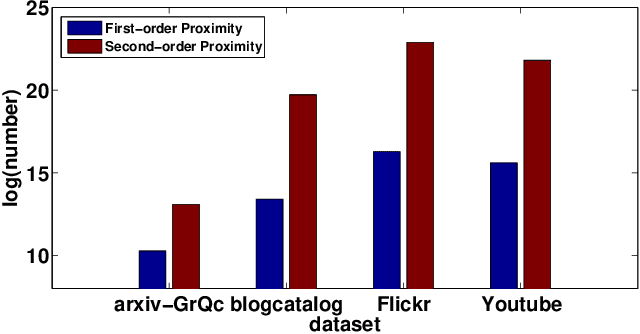
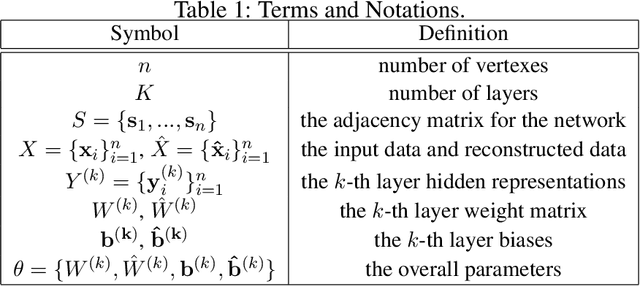
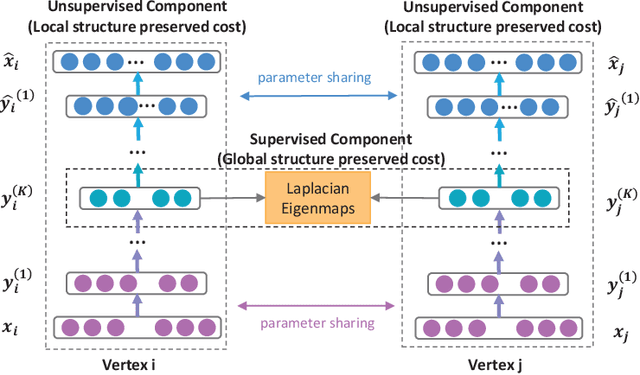

Mining graph data has become a popular research topic in computer science and has been widely studied in both academia and industry given the increasing amount of network data in the recent years. However, the huge amount of network data has posed great challenges for efficient analysis. This motivates the advent of graph representation which maps the graph into a low-dimension vector space, keeping original graph structure and supporting graph inference. The investigation on efficient representation of a graph has profound theoretical significance and important realistic meaning, we therefore introduce some basic ideas in graph representation/network embedding as well as some representative models in this chapter.