 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Apr 15, 2024



Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.
Hierarchical Skip Decoding for Efficient Autoregressive Text Generation
Mar 22, 2024Autoregressive decoding strategy is a commonly used method for text generation tasks with pre-trained language models, while early-exiting is an effective approach to speedup the inference stage. In this work, we propose a novel decoding strategy named Hierarchical Skip Decoding (HSD) for efficient autoregressive text generation. Different from existing methods that require additional trainable components, HSD is a plug-and-play method applicable to autoregressive text generation models, it adaptively skips decoding layers in a hierarchical manner based on the current sequence length, thereby reducing computational workload and allocating computation resources. Comprehensive experiments on five text generation datasets with pre-trained language models demonstrate HSD's advantages in balancing efficiency and text quality. With almost half of the layers skipped, HSD can sustain 90% of the text quality compared to vanilla autoregressive decoding, outperforming the competitive approaches.
Integrating Homomorphic Encryption and Trusted Execution Technology for Autonomous and Confidential Model Refining in Cloud
Aug 02, 2023



With the popularity of cloud computing and machine learning, it has been a trend to outsource machine learning processes (including model training and model-based inference) to cloud. By the outsourcing, other than utilizing the extensive and scalable resource offered by the cloud service provider, it will also be attractive to users if the cloud servers can manage the machine learning processes autonomously on behalf of the users. Such a feature will be especially salient when the machine learning is expected to be a long-term continuous process and the users are not always available to participate. Due to security and privacy concerns, it is also desired that the autonomous learning preserves the confidentiality of users' data and models involved. Hence, in this paper, we aim to design a scheme that enables autonomous and confidential model refining in cloud. Homomorphic encryption and trusted execution environment technology can protect confidentiality for autonomous computation, but each of them has their limitations respectively and they are complementary to each other. Therefore, we further propose to integrate these two techniques in the design of the model refining scheme. Through implementation and experiments, we evaluate the feasibility of our proposed scheme. The results indicate that, with our proposed scheme the cloud server can autonomously refine an encrypted model with newly provided encrypted training data to continuously improve its accuracy. Though the efficiency is still significantly lower than the baseline scheme that refines plaintext-model with plaintext-data, we expect that it can be improved by fully utilizing the higher level of parallelism and the computational power of GPU at the cloud server.
Parameter-Efficient Fine-Tuning with Layer Pruning on Free-Text Sequence-to-Sequence Modeling
May 19, 2023The increasing size of language models raises great research interests in parameter-efficient fine-tuning such as LoRA that freezes the pre-trained model, and injects small-scale trainable parameters for multiple downstream tasks (e.g., summarization, question answering and translation). To further enhance the efficiency of fine-tuning, we propose a framework that integrates LoRA and structured layer pruning. The integrated framework is validated on two created deidentified medical report summarization datasets based on MIMIC-IV-Note and two public medical dialogue datasets. By tuning 0.6% parameters of the original model and pruning over 30% Transformer-layers, our framework can reduce 50% of GPU memory usage and speed up 100% of the training phase, while preserving over 92% generation qualities on free-text sequence-to-sequence tasks.
Cross-Stream Contrastive Learning for Self-Supervised Skeleton-Based Action Recognition
May 03, 2023



Self-supervised skeleton-based action recognition enjoys a rapid growth along with the development of contrastive learning. The existing methods rely on imposing invariance to augmentations of 3D skeleton within a single data stream, which merely leverages the easy positive pairs and limits the ability to explore the complicated movement patterns. In this paper, we advocate that the defect of single-stream contrast and the lack of necessary feature transformation are responsible for easy positives, and therefore propose a Cross-Stream Contrastive Learning framework for skeleton-based action Representation learning (CSCLR). Specifically, the proposed CSCLR not only utilizes intra-stream contrast pairs, but introduces inter-stream contrast pairs as hard samples to formulate a better representation learning. Besides, to further exploit the potential of positive pairs and increase the robustness of self-supervised representation learning, we propose a Positive Feature Transformation (PFT) strategy which adopts feature-level manipulation to increase the variance of positive pairs. To validate the effectiveness of our method, we conduct extensive experiments on three benchmark datasets NTU-RGB+D 60, NTU-RGB+D 120 and PKU-MMD. Experimental results show that our proposed CSCLR exceeds the state-of-the-art methods on a diverse range of evaluation protocols.
Cross-Domain Label Propagation for Domain Adaptation with Discriminative Graph Self-Learning
Feb 17, 2023



Domain adaptation manages to transfer the knowledge of well-labeled source data to unlabeled target data. Many recent efforts focus on improving the prediction accuracy of target pseudo-labels to reduce conditional distribution shift. In this paper, we propose a novel domain adaptation method, which infers target pseudo-labels through cross-domain label propagation, such that the underlying manifold structure of two domain data can be explored. Unlike existing cross-domain label propagation methods that separate domain-invariant feature learning, affinity matrix constructing and target labels inferring into three independent stages, we propose to integrate them into a unified optimization framework. In such way, these three parts can boost each other from an iterative optimization perspective and thus more effective knowledge transfer can be achieved. Furthermore, to construct a high-quality affinity matrix, we propose a discriminative graph self-learning strategy, which can not only adaptively capture the inherent similarity of the data from two domains but also effectively exploit the discriminative information contained in well-labeled source data and pseudo-labeled target data. An efficient iterative optimization algorithm is designed to solve the objective function of our proposal. Notably, the proposed method can be extended to semi-supervised domain adaptation in a simple but effective way and the corresponding optimization problem can be solved with the identical algorithm. Extensive experiments on six standard datasets verify the significant superiority of our proposal in both unsupervised and semi-supervised domain adaptation settings.
Leveraging Summary Guidance on Medical Report Summarization
Feb 08, 2023This study presents three deidentified large medical text datasets, named DISCHARGE, ECHO and RADIOLOGY, which contain 50K, 16K and 378K pairs of report and summary that are derived from MIMIC-III, respectively. We implement convincing baselines of automated abstractive summarization on the proposed datasets with pre-trained encoder-decoder language models, including BERT2BERT, T5-large and BART. Further, based on the BART model, we leverage the sampled summaries from the train set as prior knowledge guidance, for encoding additional contextual representations of the guidance with the encoder and enhancing the decoding representations in the decoder. The experimental results confirm the improvement of ROUGE scores and BERTScore made by the proposed method, outperforming the larger model T5-large.
Constrained Maximum Cross-Domain Likelihood for Domain Generalization
Oct 09, 2022
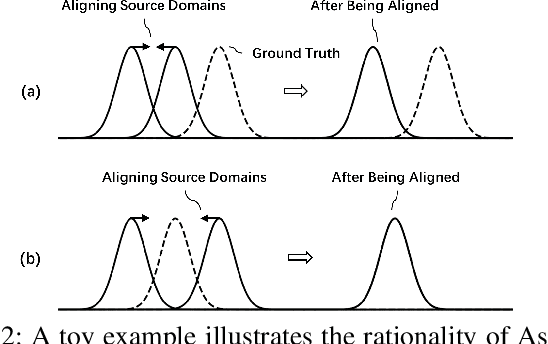
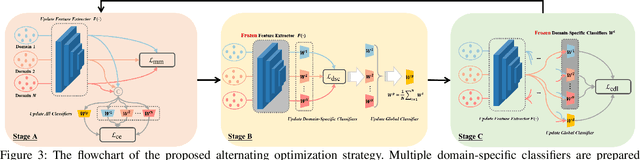
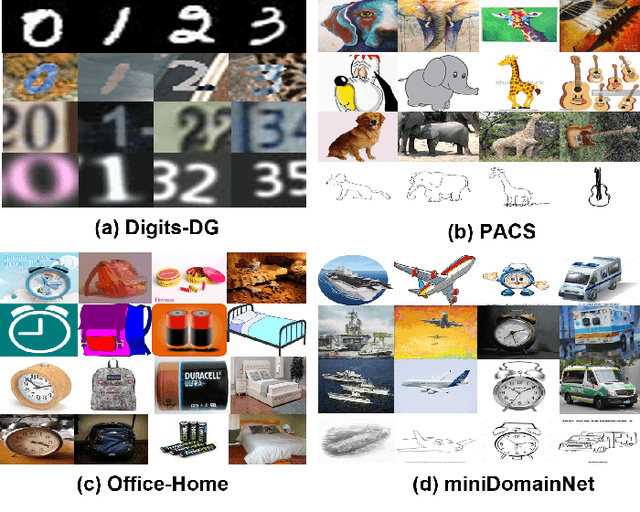
As a recent noticeable topic, domain generalization aims to learn a generalizable model on multiple source domains, which is expected to perform well on unseen test domains. Great efforts have been made to learn domain-invariant features by aligning distributions across domains. However, existing works are often designed based on some relaxed conditions which are generally hard to satisfy and fail to realize the desired joint distribution alignment. In this paper, we propose a novel domain generalization method, which originates from an intuitive idea that a domain-invariant classifier can be learned by minimizing the KL-divergence between posterior distributions from different domains. To enhance the generalizability of the learned classifier, we formalize the optimization objective as an expectation computed on the ground-truth marginal distribution. Nevertheless, it also presents two obvious deficiencies, one of which is the side-effect of entropy increase in KL-divergence and the other is the unavailability of ground-truth marginal distributions. For the former, we introduce a term named maximum in-domain likelihood to maintain the discrimination of the learned domain-invariant representation space. For the latter, we approximate the ground-truth marginal distribution with source domains under a reasonable convex hull assumption. Finally, a Constrained Maximum Cross-domain Likelihood (CMCL) optimization problem is deduced, by solving which the joint distributions are naturally aligned. An alternating optimization strategy is carefully designed to approximately solve this optimization problem. Extensive experiments on four standard benchmark datasets, i.e., Digits-DG, PACS, Office-Home and miniDomainNet, highlight the superior performance of our method.
Mitigating Both Covariate and Conditional Shift for Domain Generalization
Sep 17, 2022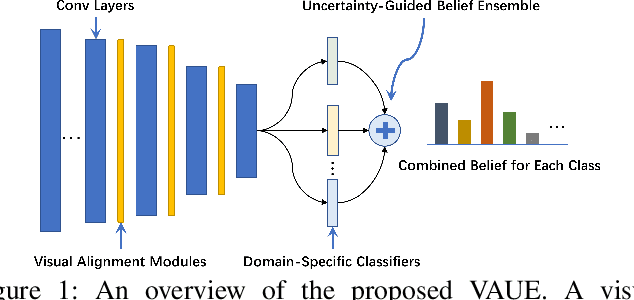
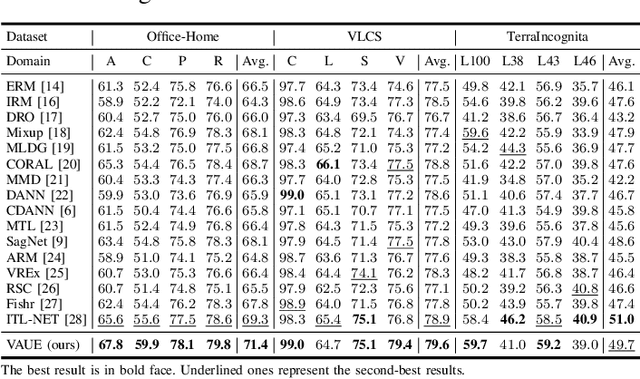
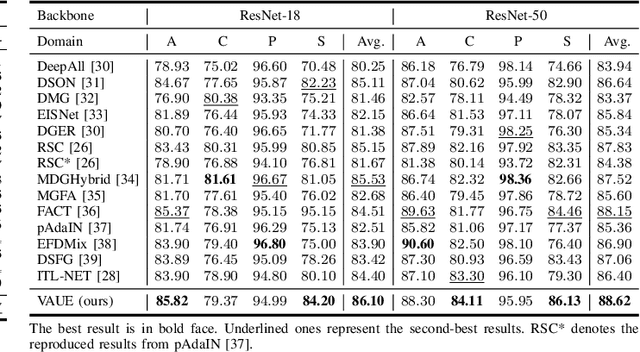
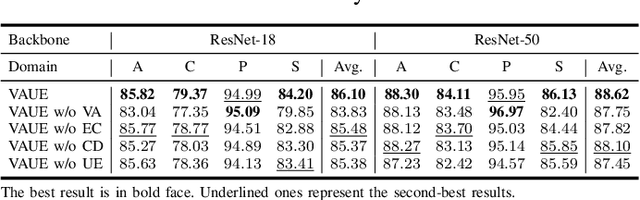
Domain generalization (DG) aims to learn a model on several source domains, hoping that the model can generalize well to unseen target domains. The distribution shift between domains contains the covariate shift and conditional shift, both of which the model must be able to handle for better generalizability. In this paper, a novel DG method is proposed to deal with the distribution shift via Visual Alignment and Uncertainty-guided belief Ensemble (VAUE). Specifically, for the covariate shift, a visual alignment module is designed to align the distribution of image style to a common empirical Gaussian distribution so that the covariate shift can be eliminated in the visual space. For the conditional shift, we adopt an uncertainty-guided belief ensemble strategy based on the subjective logic and Dempster-Shafer theory. The conditional distribution given a test sample is estimated by the dynamic combination of that of source domains. Comprehensive experiments are conducted to demonstrate the superior performance of the proposed method on four widely used datasets, i.e., Office-Home, VLCS, TerraIncognita, and PACS.
Active Learning with Effective Scoring Functions for Semi-Supervised Temporal Action Localization
Aug 31, 2022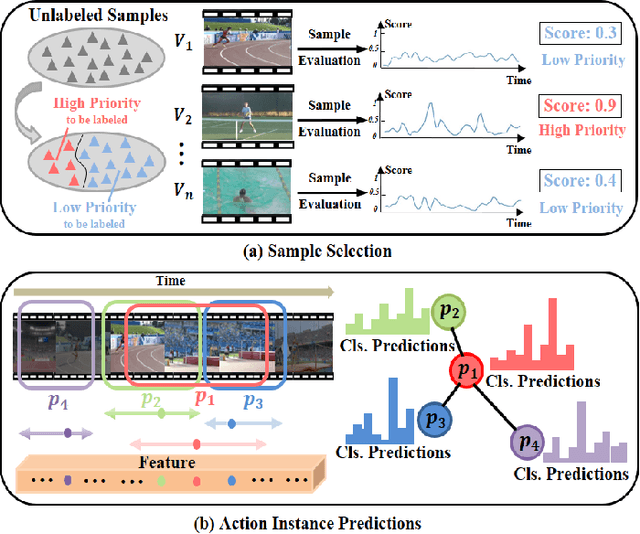
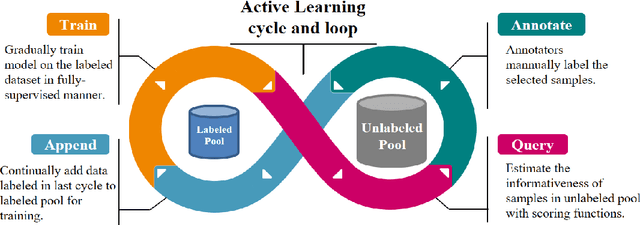
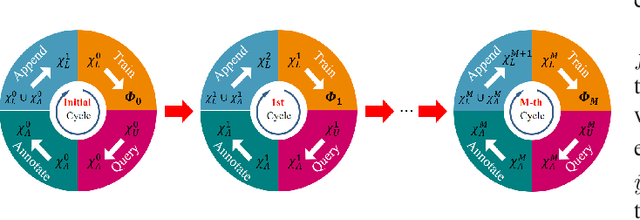
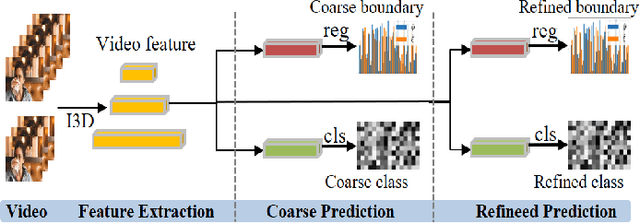
Temporal Action Localization (TAL) aims to predict both action category and temporal boundary of action instances in untrimmed videos, i.e., start and end time. Fully-supervised solutions are usually adopted in most existing works, and proven to be effective. One of the practical bottlenecks in these solutions is the large amount of labeled training data required. To reduce expensive human label cost, this paper focuses on a rarely investigated yet practical task named semi-supervised TAL and proposes an effective active learning method, named AL-STAL. We leverage four steps for actively selecting video samples with high informativeness and training the localization model, named \emph{Train, Query, Annotate, Append}. Two scoring functions that consider the uncertainty of localization model are equipped in AL-STAL, thus facilitating the video sample rank and selection. One takes entropy of predicted label distribution as measure of uncertainty, named Temporal Proposal Entropy (TPE). And the other introduces a new metric based on mutual information between adjacent action proposals and evaluates the informativeness of video samples, named Temporal Context Inconsistency (TCI). To validate the effectiveness of proposed method, we conduct extensive experiments on two benchmark datasets THUMOS'14 and ActivityNet 1.3. Experiment results show that AL-STAL outperforms the existing competitors and achieves satisfying performance compared with fully-supervised learning.