 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Emma Zhang
Conversational Question Answering: A Survey
Jun 03, 2021
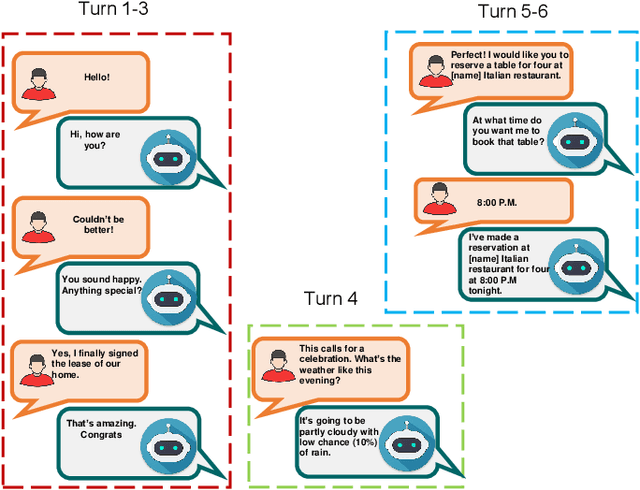

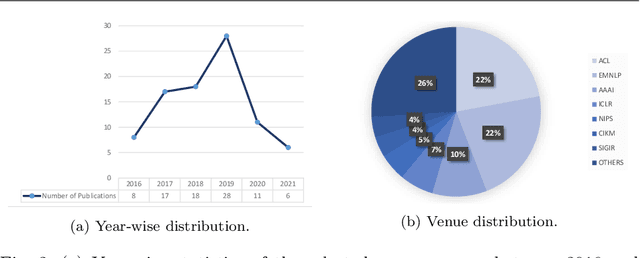
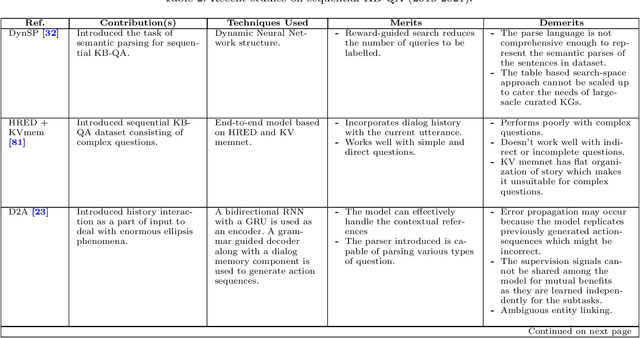
Question answering (QA) systems provide a way of querying the information available in various formats including, but not limited to, unstructured and structured data in natural languages. It constitutes a considerable part of conversational artificial intelligence (AI) which has led to the introduction of a special research topic on Conversational Question Answering (CQA), wherein a system is required to understand the given context and then engages in multi-turn QA to satisfy the user's information needs. Whilst the focus of most of the existing research work is subjected to single-turn QA, the field of multi-turn QA has recently grasped attention and prominence owing to the availability of large-scale, multi-turn QA datasets and the development of pre-trained language models. With a good amount of models and research papers adding to the literature every year recently, there is a dire need of arranging and presenting the related work in a unified manner to streamline future research. This survey, therefore, is an effort to present a comprehensive review of the state-of-the-art research trends of CQA primarily based on reviewed papers from 2016-2021. Our findings show that there has been a trend shift from single-turn to multi-turn QA which empowers the field of Conversational AI from different perspectives. This survey is intended to provide an epitome for the research community with the hope of laying a strong foundation for the field of CQA.
A Review of the Non-Invasive Techniques for Monitoring Different Aspects of Sleep
Apr 27, 2021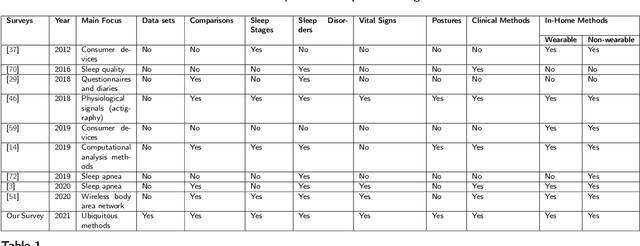
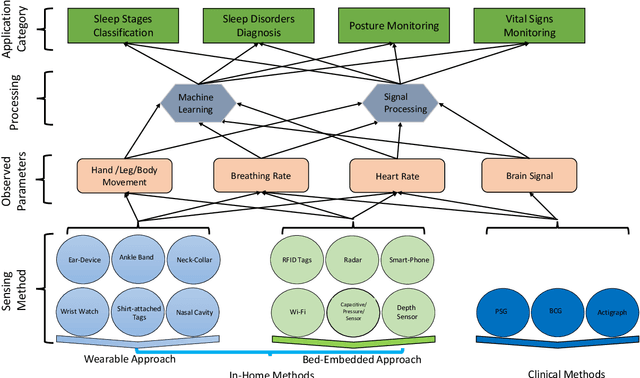
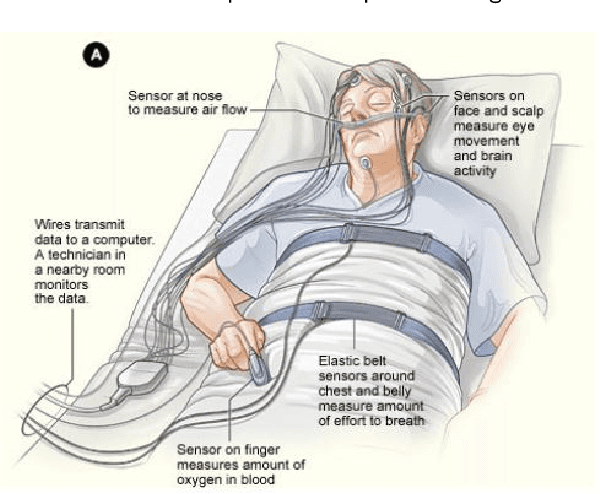
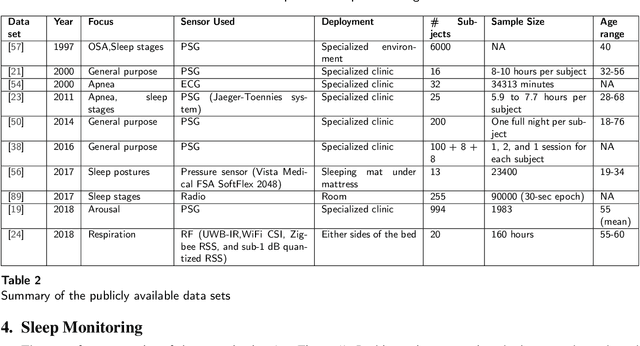
Quality sleep is very important for a healthy life. Nowadays, many people around the world are not getting enough sleep which is having negative impacts on their lifestyles. Studies are being conducted for sleep monitoring and have now become an important tool for understanding sleep behavior. The gold standard method for sleep analysis is polysomnography (PSG) conducted in a clinical environment but this method is both expensive and complex for long-term use. With the advancements in the field of sensors and the introduction of off-the-shelf technologies, unobtrusive solutions are becoming common as alternatives for in-home sleep monitoring. Various solutions have been proposed using both wearable and non-wearable methods which are cheap and easy to use for in-home sleep monitoring. In this paper, we present a comprehensive survey of the latest research works (2015 and after) conducted in various categories of sleep monitoring including sleep stage classification, sleep posture recognition, sleep disorders detection, and vital signs monitoring. We review the latest works done using the non-invasive approach and cover both wearable and non-wearable methods. We discuss the design approaches and key attributes of the work presented and provide an extensive analysis based on 10 key factors, to give a comprehensive overview of the recent developments and trends in all four categories of sleep monitoring. We also present some publicly available datasets for different categories of sleep monitoring. In the end, we discuss several open issues and provide future research directions in the area of sleep monitoring.
A Short Survey of Pre-trained Language Models for Conversational AI-A NewAge in NLP
Apr 22, 2021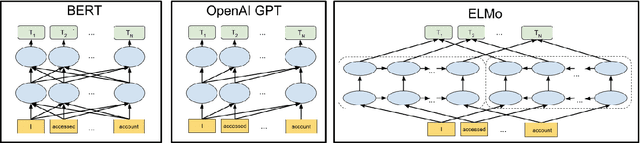
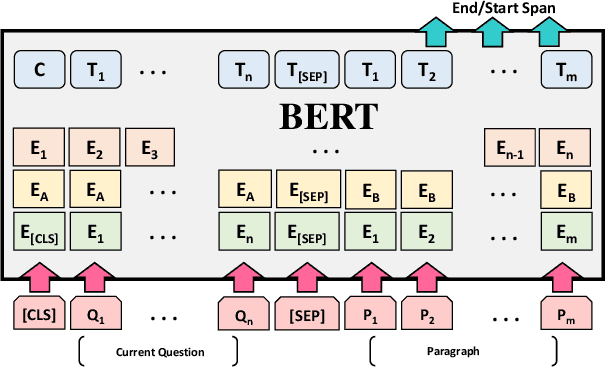
Building a dialogue system that can communicate naturally with humans is a challenging yet interesting problem of agent-based computing. The rapid growth in this area is usually hindered by the long-standing problem of data scarcity as these systems are expected to learn syntax, grammar, decision making, and reasoning from insufficient amounts of task-specific dataset. The recently introduced pre-trained language models have the potential to address the issue of data scarcity and bring considerable advantages by generating contextualized word embeddings. These models are considered counterpart of ImageNet in NLP and have demonstrated to capture different facets of language such as hierarchical relations, long-term dependency, and sentiment. In this short survey paper, we discuss the recent progress made in the field of pre-trained language models. We also deliberate that how the strengths of these language models can be leveraged in designing more engaging and more eloquent conversational agents. This paper, therefore, intends to establish whether these pre-trained models can overcome the challenges pertinent to dialogue systems, and how their architecture could be exploited in order to overcome these challenges. Open challenges in the field of dialogue systems have also been deliberated.
Multi-document Summarization via Deep Learning Techniques: A Survey
Nov 10, 2020
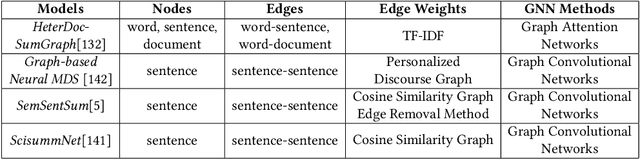
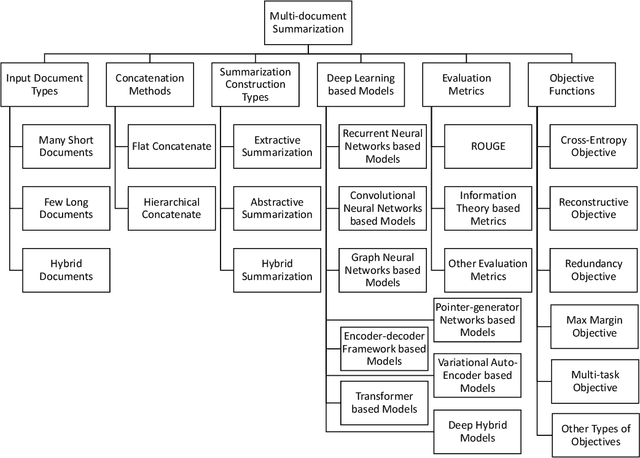
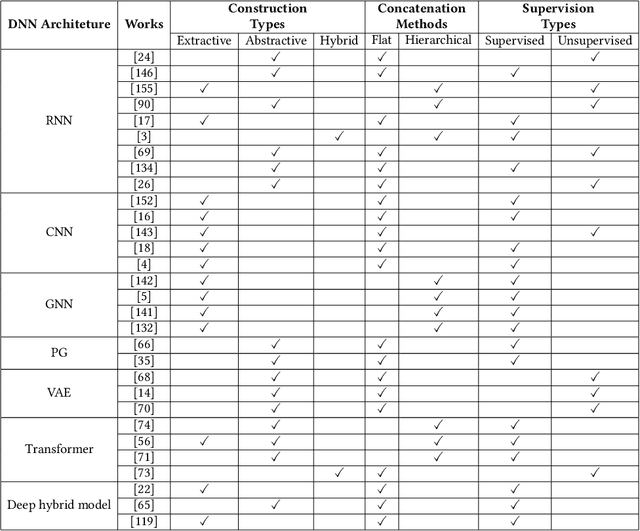
Multi-document summarization (MDS) is an effective tool for information aggregation which generates an informative and concise summary from a cluster of topic-related documents. Our survey structurally overviews the recent deep learning based multi-document summarization models via a proposed taxonomy and it is the first of its kind. Particularly, we propose a novel mechanism to summarize the design strategies of neural networks and conduct a comprehensive summary of the state-of-the-art. We highlight the differences among various objective functions which are rarely discussed in the existing literature. Finally, we propose several future directions pertaining to this new and exciting development of the field.
Semantic Equivalent Adversarial Data Augmentation for Visual Question Answering
Jul 19, 2020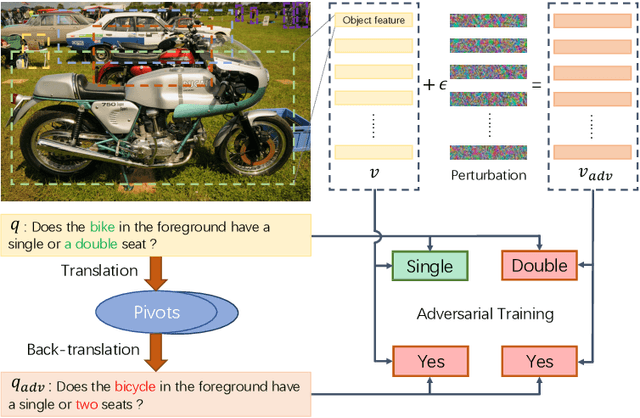
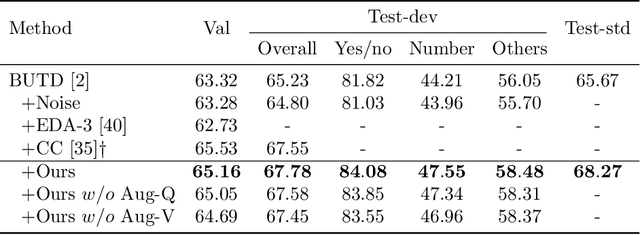


Visual Question Answering (VQA) has achieved great success thanks to the fast development of deep neural networks (DNN). On the other hand, the data augmentation, as one of the major tricks for DNN, has been widely used in many computer vision tasks. However, there are few works studying the data augmentation problem for VQA and none of the existing image based augmentation schemes (such as rotation and flipping) can be directly applied to VQA due to its semantic structure -- an $\langle image, question, answer\rangle$ triplet needs to be maintained correctly. For example, a direction related Question-Answer (QA) pair may not be true if the associated image is rotated or flipped. In this paper, instead of directly manipulating images and questions, we use generated adversarial examples for both images and questions as the augmented data. The augmented examples do not change the visual properties presented in the image as well as the \textbf{semantic} meaning of the question, the correctness of the $\langle image, question, answer\rangle$ is thus still maintained. We then use adversarial learning to train a classic VQA model (BUTD) with our augmented data. We find that we not only improve the overall performance on VQAv2, but also can withstand adversarial attack effectively, compared to the baseline model. The source code is available at https://github.com/zaynmi/seada-vqa.
Adversarial Attacks and Detection on Reinforcement Learning-Based Interactive Recommender Systems
Jun 14, 2020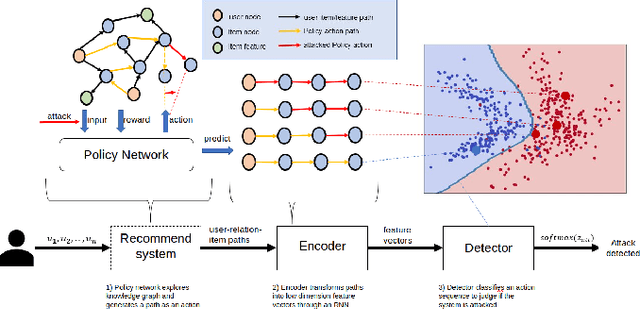
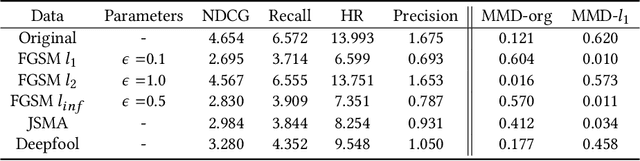
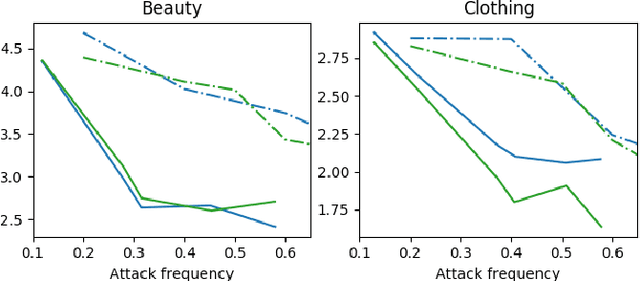
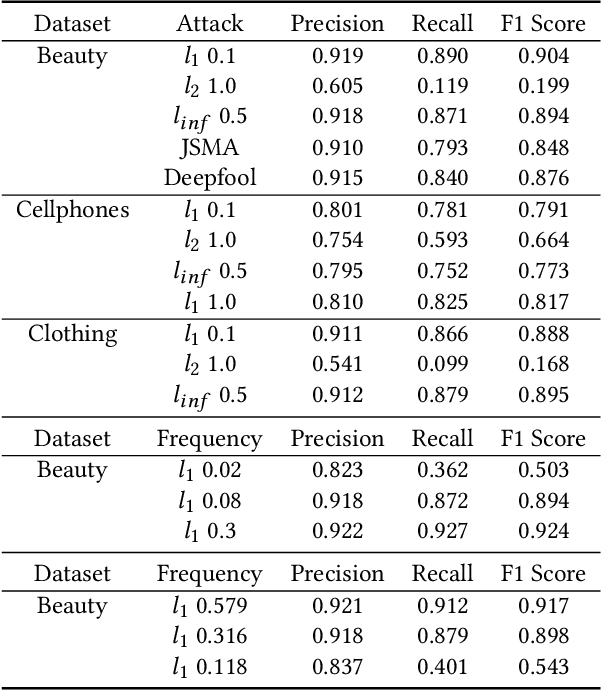
Adversarial attacks pose significant challenges for detecting adversarial attacks at an early stage. We propose attack-agnostic detection on reinforcement learning-based interactive recommendation systems. We first craft adversarial examples to show their diverse distributions and then augment recommendation systems by detecting potential attacks with a deep learning-based classifier based on the crafted data. Finally, we study the attack strength and frequency of adversarial examples and evaluate our model on standard datasets with multiple crafting methods. Our extensive experiments show that most adversarial attacks are effective, and both attack strength and attack frequency impact the attack performance. The strategically-timed attack achieves comparative attack performance with only 1/3 to 1/2 attack frequency. Besides, our black-box detector trained with one crafting method has the generalization ability over several crafting methods.
Deep Conversational Recommender Systems: A New Frontier for Goal-Oriented Dialogue Systems
Apr 28, 2020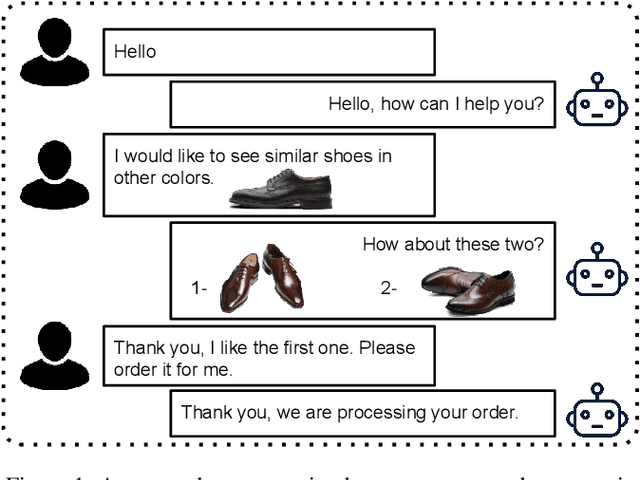
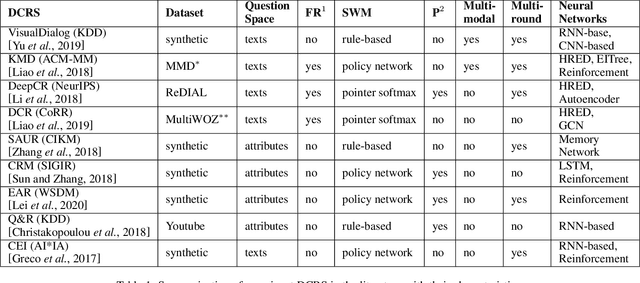
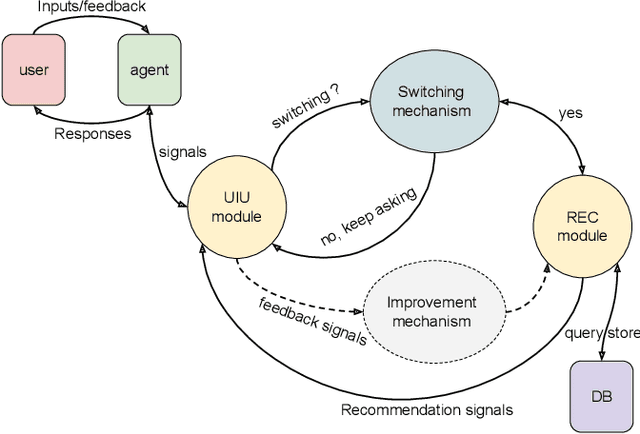
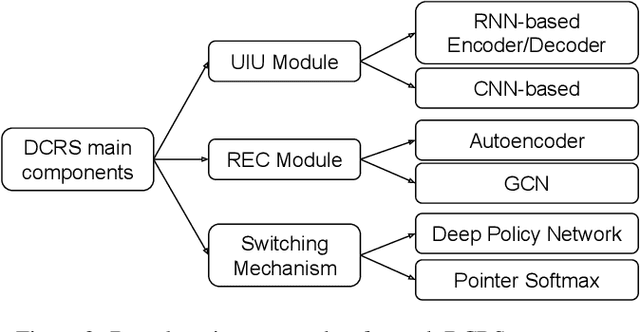
In recent years, the emerging topics of recommender systems that take advantage of natural language processing techniques have attracted much attention, and one of their applications is the Conversational Recommender System (CRS). Unlike traditional recommender systems with content-based and collaborative filtering approaches, CRS learns and models user's preferences through interactive dialogue conversations. In this work, we provide a summarization of the recent evolution of CRS, where deep learning approaches are applied to CRS and have produced fruitful results. We first analyze the research problems and present key challenges in the development of Deep Conversational Recommender Systems (DCRS), then present the current state of the field taken from the most recent researches, including the most common deep learning models that benefit DCRS. Finally, we discuss future directions for this vibrant area.
Different Approaches for Human Activity Recognition: A Survey
Jun 11, 2019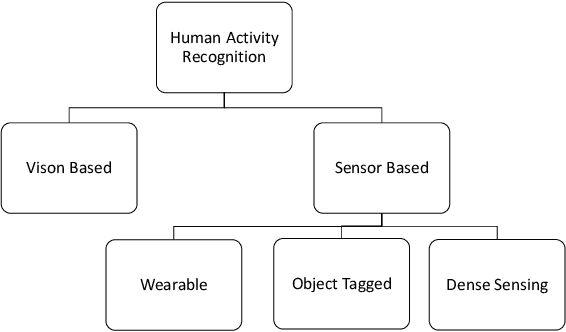
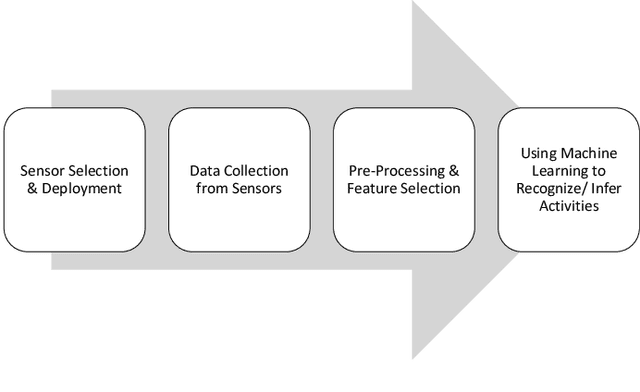
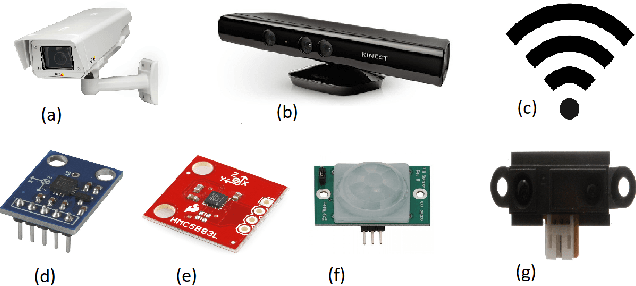
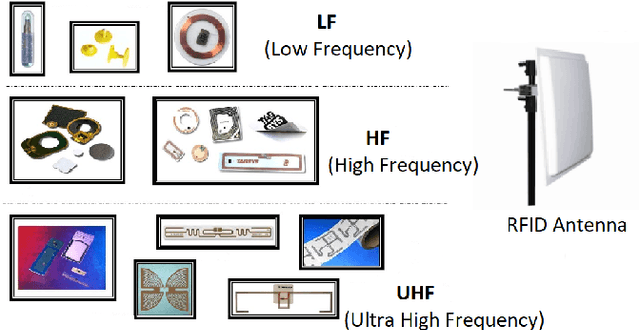
Human activity recognition has gained importance in recent years due to its applications in various fields such as health, security and surveillance, entertainment, and intelligent environments. A significant amount of work has been done on human activity recognition and researchers have leveraged different approaches, such as wearable, object-tagged, and device-free, to recognize human activities. In this article, we present a comprehensive survey of the work conducted over the period 2010-2018 in various areas of human activity recognition with main focus on device-free solutions. The device-free approach is becoming very popular due to the fact that the subject is not required to carry anything, instead, the environment is tagged with devices to capture the required information. We propose a new taxonomy for categorizing the research work conducted in the field of activity recognition and divide the existing literature into three sub-areas: action-based, motion-based, and interaction-based. We further divide these areas into ten different sub-topics and present the latest research work in these sub-topics. Unlike previous surveys which focus only on one type of activities, to the best of our knowledge, we cover all the sub-areas in activity recognition and provide a comparison of the latest research work in these sub-areas. Specifically, we discuss the key attributes and design approaches for the work presented. Then we provide extensive analysis based on 10 important metrics, to give the reader, a complete overview of the state-of-the-art techniques and trends in different sub-areas of human activity recognition. In the end, we discuss open research issues and provide future research directions in the field of human activity recognition.
Generating Textual Adversarial Examples for Deep Learning Models: A Survey
Jan 27, 2019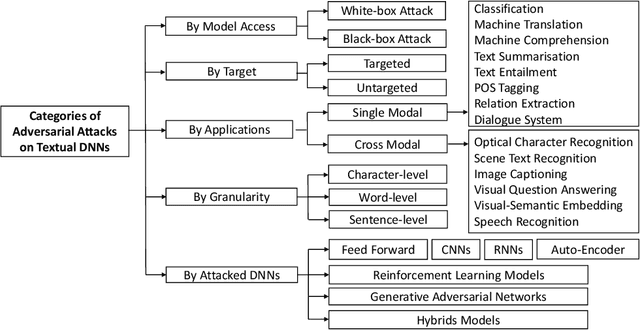
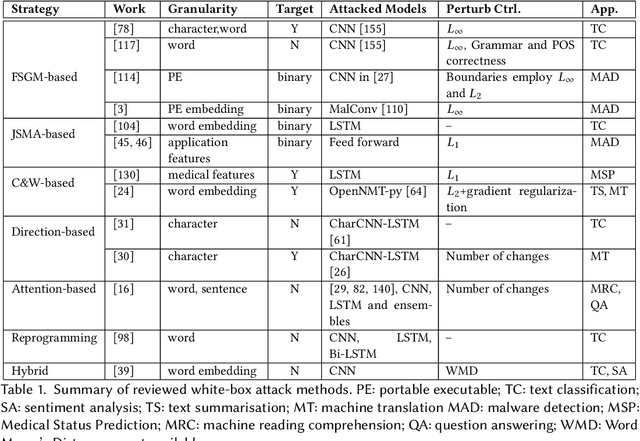
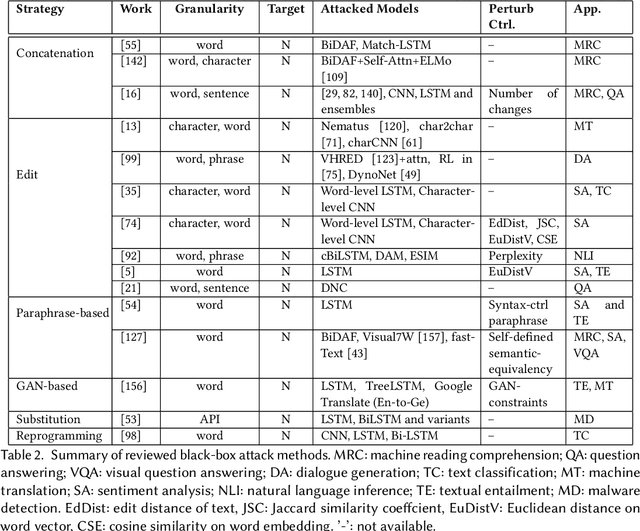
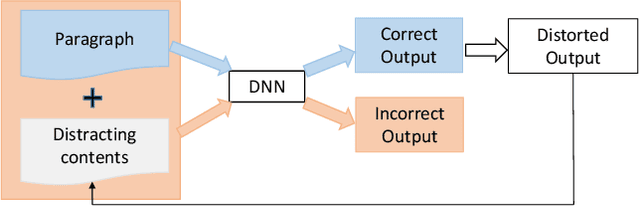
With the development of high computational devices, deep neural networks (DNNs), in recent years, have gained significant popularity in many Artificial Intelligence (AI) applications. However, previous efforts have shown that DNNs were vulnerable to strategically modified samples, named adversarial examples. These samples are generated with some imperceptible perturbations but can fool the DNNs to give false predictions. Inspired by the popularity of generating adversarial examples for image DNNs, research efforts on attacking DNNs for textual applications emerges in recent years. However, existing perturbation methods for images cannotbe directly applied to texts as text data is discrete. In this article, we review research works that address this difference and generatetextual adversarial examples on DNNs. We collect, select, summarize, discuss and analyze these works in a comprehensive way andcover all the related information to make the article self-contained. Finally, drawing on the reviewed literature, we provide further discussions and suggestions on this topic.