 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Zhang
A Deep Learning Method for Real-time Bias Correction of Wind Field Forecasts in the Western North Pacific
Dec 29, 2022

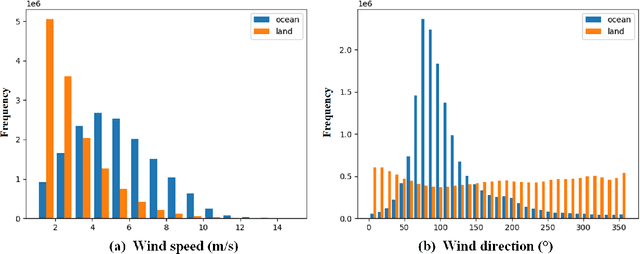

Forecasts by the European Centre for Medium-Range Weather Forecasts (ECMWF; EC for short) can provide a basis for the establishment of maritime-disaster warning systems, but they contain some systematic biases.The fifth-generation EC atmospheric reanalysis (ERA5) data have high accuracy, but are delayed by about 5 days. To overcome this issue, a spatiotemporal deep-learning method could be used for nonlinear mapping between EC and ERA5 data, which would improve the quality of EC wind forecast data in real time. In this study, we developed the Multi-Task-Double Encoder Trajectory Gated Recurrent Unit (MT-DETrajGRU) model, which uses an improved double-encoder forecaster architecture to model the spatiotemporal sequence of the U and V components of the wind field; we designed a multi-task learning loss function to correct wind speed and wind direction simultaneously using only one model. The study area was the western North Pacific (WNP), and real-time rolling bias corrections were made for 10-day wind-field forecasts released by the EC between December 2020 and November 2021, divided into four seasons. Compared with the original EC forecasts, after correction using the MT-DETrajGRU model the wind speed and wind direction biases in the four seasons were reduced by 8-11% and 9-14%, respectively. In addition, the proposed method modelled the data uniformly under different weather conditions. The correction performance under normal and typhoon conditions was comparable, indicating that the data-driven mode constructed here is robust and generalizable.
* 18 pages
Circular Accessible Depth: A Robust Traversability Representation for UGV Navigation
Dec 28, 2022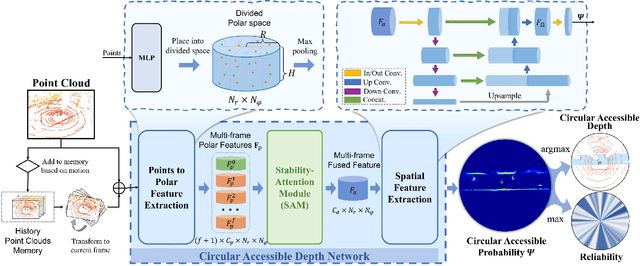
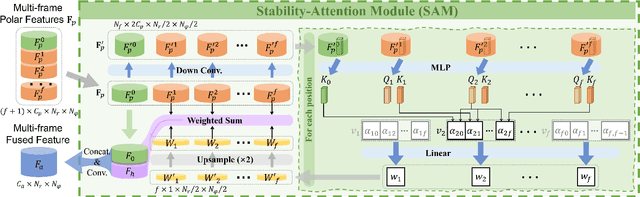

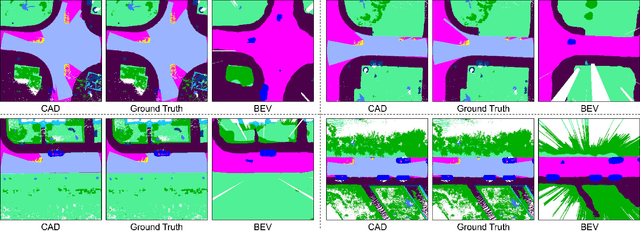
In this paper, we present the Circular Accessible Depth (CAD), a robust traversability representation for an unmanned ground vehicle (UGV) to learn traversability in various scenarios containing irregular obstacles. To predict CAD, we propose a neural network, namely CADNet, with an attention-based multi-frame point cloud fusion module, Stability-Attention Module (SAM), to encode the spatial features from point clouds captured by LiDAR. CAD is designed based on the polar coordinate system and focuses on predicting the border of traversable area. Since it encodes the spatial information of the surrounding environment, which enables a semi-supervised learning for the CADNet, and thus desirably avoids annotating a large amount of data. Extensive experiments demonstrate that CAD outperforms baselines in terms of robustness and precision. We also implement our method on a real UGV and show that it performs well in real-world scenarios.
Semantic optical fiber communication system
Dec 27, 2022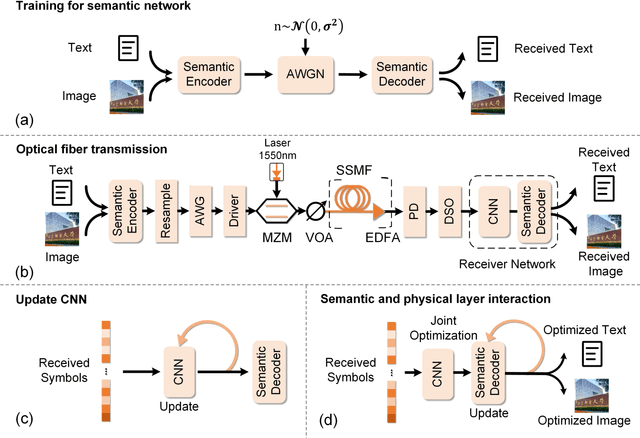
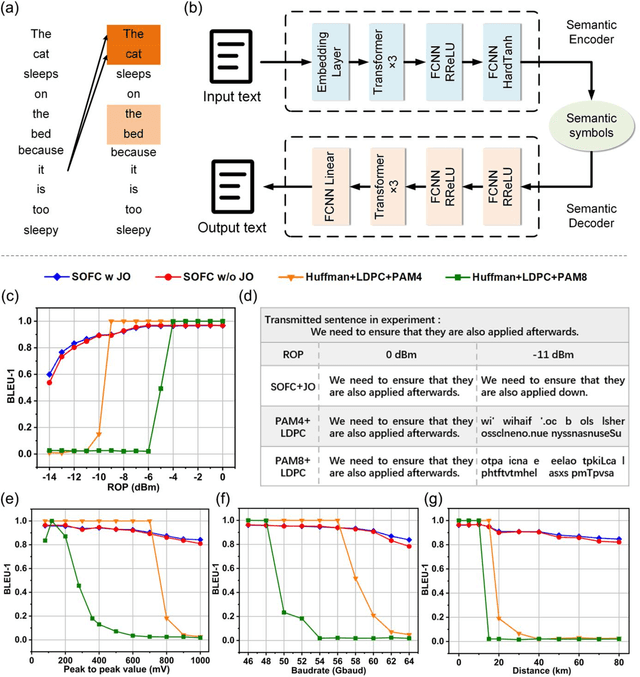
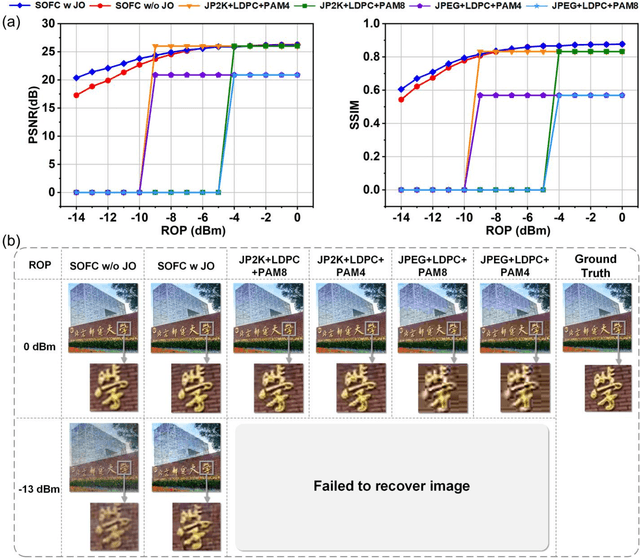
The current optical communication systems minimize bit or symbol errors without considering the semantic meaning behind digital bits, thus transmitting a lot of unnecessary information. We propose and experimentally demonstrate a semantic optical fiber communication (SOFC) system. Instead of encoding information into bits for transmission, semantic information is extracted from the source using deep learning. The generated semantic symbols are then directly transmitted through an optical fiber. Compared with the bit-based structure, the SOFC system achieved higher information compression and a more stable performance, especially in the low received optical power regime, and enhanced the robustness against optical link impairments. This work introduces an intelligent optical communication system at the human analytical thinking level, which is a significant step toward a breakthrough in the current optical communication architecture.
Differentiating Student Feedbacks for Knowledge Tracing
Dec 16, 2022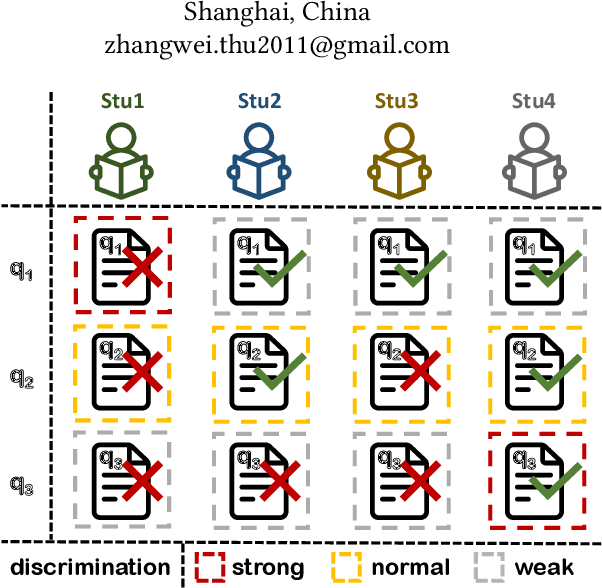

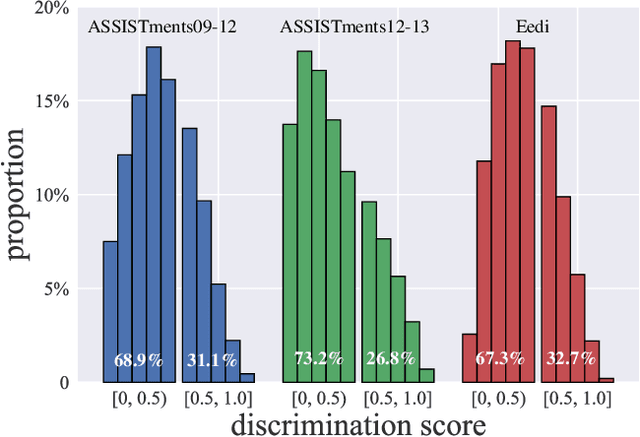

In computer-aided education and intelligent tutoring systems, knowledge tracing (KT) raises attention due to the development of data-driven learning methods, which aims to predict students' future performance given their past question response sequences to trace their knowledge states. However, current deep learning approaches only focus on enhancing prediction accuracy, but neglecting the discrimination imbalance of responses. That is, a considerable proportion of question responses are weak to discriminate students' knowledge states, but equally considered compared to other discriminative responses, thus hurting the ability of tracing students' personalized knowledge states. To tackle this issue, we propose DR4KT for Knowledge Tracing, which reweights the contribution of different responses according to their discrimination in training. For retaining high prediction accuracy on low discriminative responses after reweighting, DR4KT also introduces a discrimination-aware score fusion technique to make a proper combination between student knowledge mastery and the questions themselves. Comprehensive experimental results show that our DR4KT applied on four mainstream KT methods significantly improves their performance on three widely-used datasets.
Adaptive Low-Precision Training for Embeddings in Click-Through Rate Prediction
Dec 12, 2022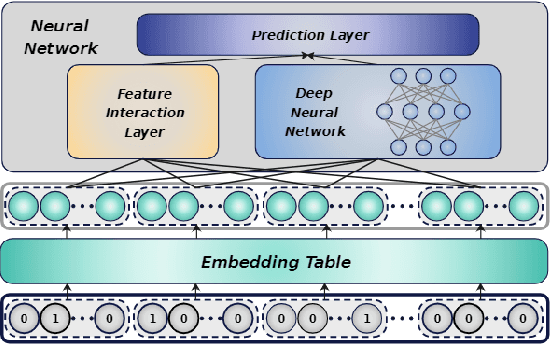
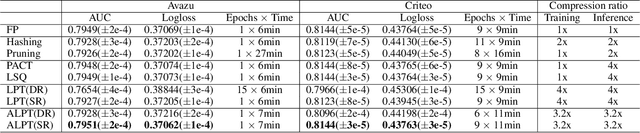
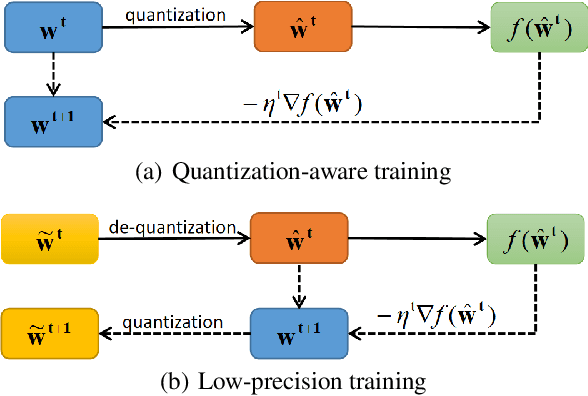
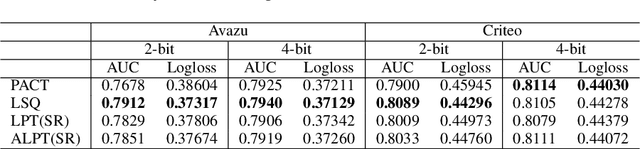
Embedding tables are usually huge in click-through rate (CTR) prediction models. To train and deploy the CTR models efficiently and economically, it is necessary to compress their embedding tables at the training stage. To this end, we formulate a novel quantization training paradigm to compress the embeddings from the training stage, termed low-precision training (LPT). Also, we provide theoretical analysis on its convergence. The results show that stochastic weight quantization has a faster convergence rate and a smaller convergence error than deterministic weight quantization in LPT. Further, to reduce the accuracy degradation, we propose adaptive low-precision training (ALPT) that learns the step size (i.e., the quantization resolution) through gradient descent. Experiments on two real-world datasets confirm our analysis and show that ALPT can significantly improve the prediction accuracy, especially at extremely low bit widths. For the first time in CTR models, we successfully train 8-bit embeddings without sacrificing prediction accuracy. The code of ALPT is publicly available.
Low-rank Tensor Assisted K-space Generative Model for Parallel Imaging Reconstruction
Dec 11, 2022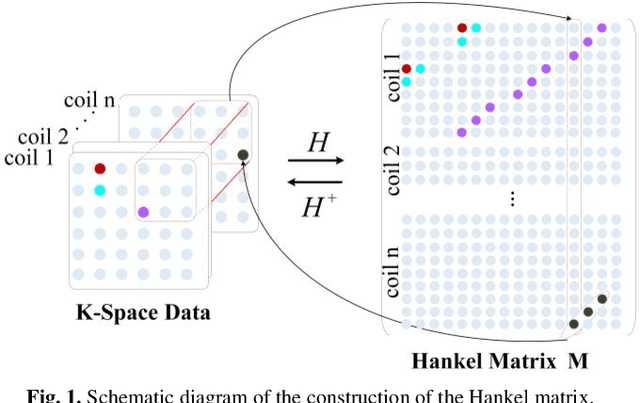
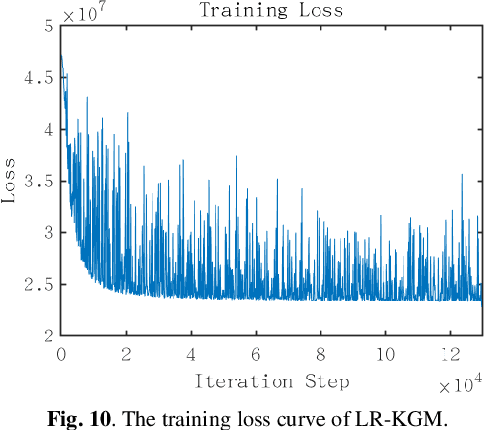
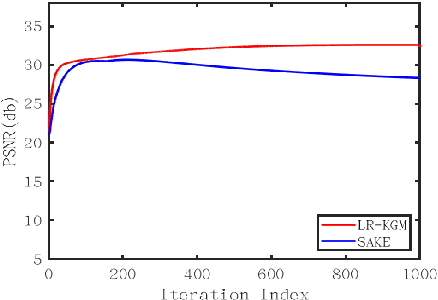
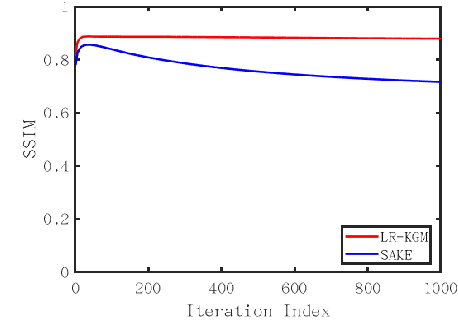
Although recent deep learning methods, especially generative models, have shown good performance in fast magnetic resonance imaging, there is still much room for improvement in high-dimensional generation. Considering that internal dimensions in score-based generative models have a critical impact on estimating the gradient of the data distribution, we present a new idea, low-rank tensor assisted k-space generative model (LR-KGM), for parallel imaging reconstruction. This means that we transform original prior information into high-dimensional prior information for learning. More specifically, the multi-channel data is constructed into a large Hankel matrix and the matrix is subsequently folded into tensor for prior learning. In the testing phase, the low-rank rotation strategy is utilized to impose low-rank constraints on tensor output of the generative network. Furthermore, we alternately use traditional generative iterations and low-rank high-dimensional tensor iterations for reconstruction. Experimental comparisons with the state-of-the-arts demonstrated that the proposed LR-KGM method achieved better performance.
Matrix Profile XXVII: A Novel Distance Measure for Comparing Long Time Series
Dec 09, 2022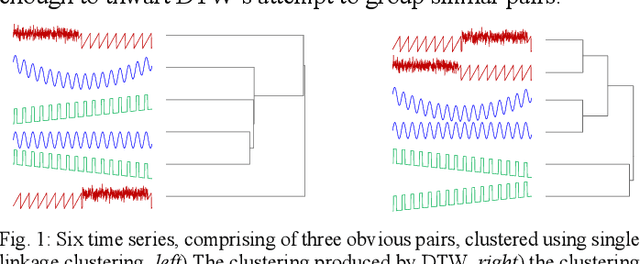
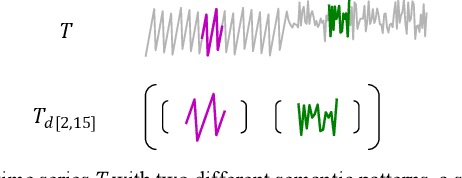
The most useful data mining primitives are distance measures. With an effective distance measure, it is possible to perform classification, clustering, anomaly detection, segmentation, etc. For single-event time series Euclidean Distance and Dynamic Time Warping distance are known to be extremely effective. However, for time series containing cyclical behaviors, the semantic meaningfulness of such comparisons is less clear. For example, on two separate days the telemetry from an athlete workout routine might be very similar. The second day may change the order in of performing push-ups and squats, adding repetitions of pull-ups, or completely omitting dumbbell curls. Any of these minor changes would defeat existing time series distance measures. Some bag-of-features methods have been proposed to address this problem, but we argue that in many cases, similarity is intimately tied to the shapes of subsequences within these longer time series. In such cases, summative features will lack discrimination ability. In this work we introduce PRCIS, which stands for Pattern Representation Comparison in Series. PRCIS is a distance measure for long time series, which exploits recent progress in our ability to summarize time series with dictionaries. We will demonstrate the utility of our ideas on diverse tasks and datasets.
G-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks
Dec 08, 2022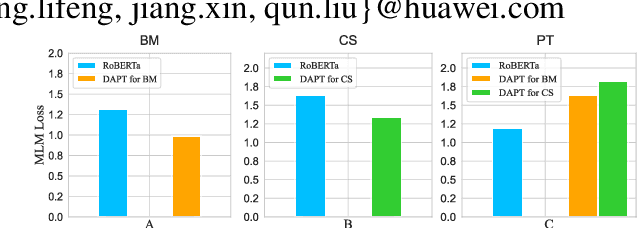
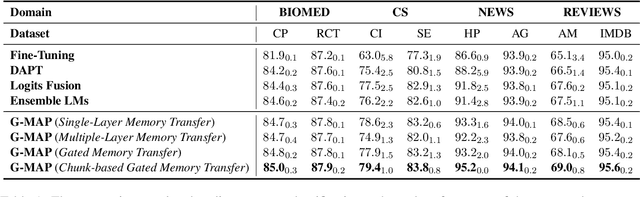
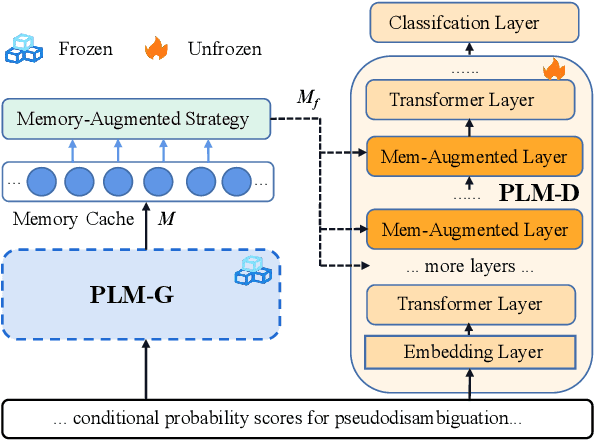
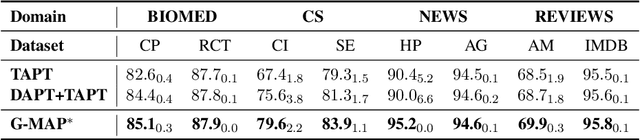
Recently, domain-specific PLMs have been proposed to boost the task performance of specific domains (e.g., biomedical and computer science) by continuing to pre-train general PLMs with domain-specific corpora. However, this Domain-Adaptive Pre-Training (DAPT; Gururangan et al. (2020)) tends to forget the previous general knowledge acquired by general PLMs, which leads to a catastrophic forgetting phenomenon and sub-optimal performance. To alleviate this problem, we propose a new framework of General Memory Augmented Pre-trained Language Model (G-MAP), which augments the domain-specific PLM by a memory representation built from the frozen general PLM without losing any general knowledge. Specifically, we propose a new memory-augmented layer, and based on it, different augmented strategies are explored to build the memory representation and then adaptively fuse it into the domain-specific PLM. We demonstrate the effectiveness of G-MAP on various domains (biomedical and computer science publications, news, and reviews) and different kinds (text classification, QA, NER) of tasks, and the extensive results show that the proposed G-MAP can achieve SOTA results on all tasks.
Dynamic Graph Node Classification via Time Augmentation
Dec 07, 2022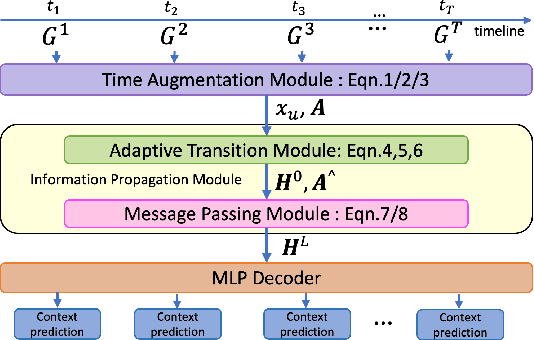
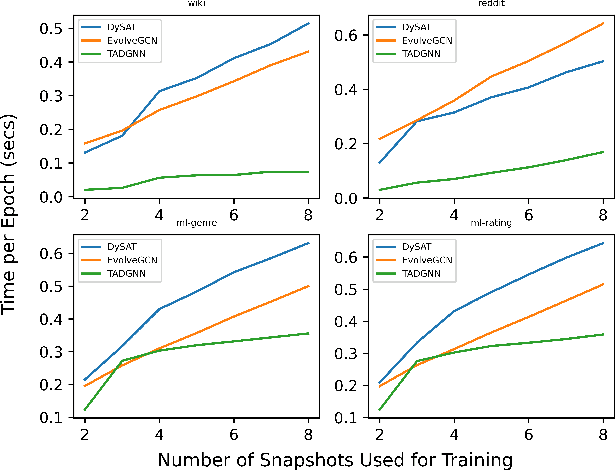

Node classification for graph-structured data aims to classify nodes whose labels are unknown. While studies on static graphs are prevalent, few studies have focused on dynamic graph node classification. Node classification on dynamic graphs is challenging for two reasons. First, the model needs to capture both structural and temporal information, particularly on dynamic graphs with a long history and require large receptive fields. Second, model scalability becomes a significant concern as the size of the dynamic graph increases. To address these problems, we propose the Time Augmented Dynamic Graph Neural Network (TADGNN) framework. TADGNN consists of two modules: 1) a time augmentation module that captures the temporal evolution of nodes across time structurally, creating a time-augmented spatio-temporal graph, and 2) an information propagation module that learns the dynamic representations for each node across time using the constructed time-augmented graph. We perform node classification experiments on four dynamic graph benchmarks. Experimental results demonstrate that TADGNN framework outperforms several static and dynamic state-of-the-art (SOTA) GNN models while demonstrating superior scalability. We also conduct theoretical and empirical analyses to validate the efficiency of the proposed method. Our code is available at https://sites.google.com/view/tadgnn.
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
Dec 06, 2022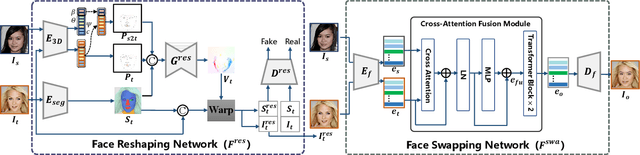
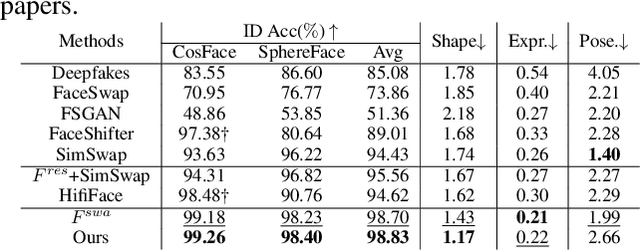


In this work, we propose a semantic flow-guided two-stage framework for shape-aware face swapping, namely FlowFace. Unlike most previous methods that focus on transferring the source inner facial features but neglect facial contours, our FlowFace can transfer both of them to a target face, thus leading to more realistic face swapping. Concretely, our FlowFace consists of a face reshaping network and a face swapping network. The face reshaping network addresses the shape outline differences between the source and target faces. It first estimates a semantic flow (i.e., face shape differences) between the source and the target face, and then explicitly warps the target face shape with the estimated semantic flow. After reshaping, the face swapping network generates inner facial features that exhibit the identity of the source face. We employ a pre-trained face masked autoencoder (MAE) to extract facial features from both the source face and the target face. In contrast to previous methods that use identity embedding to preserve identity information, the features extracted by our encoder can better capture facial appearances and identity information. Then, we develop a cross-attention fusion module to adaptively fuse inner facial features from the source face with the target facial attributes, thus leading to better identity preservation. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace outperforms the state-of-the-art significantly.