 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanli Ouyang
Stimulative Training of Residual Networks: A Social Psychology Perspective of Loafing
Oct 09, 2022
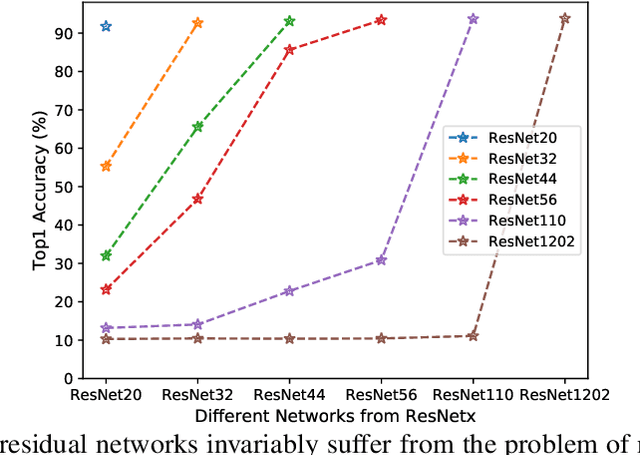
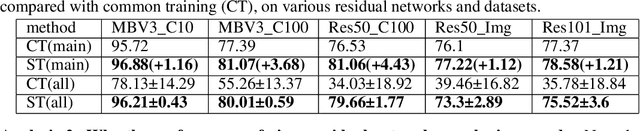
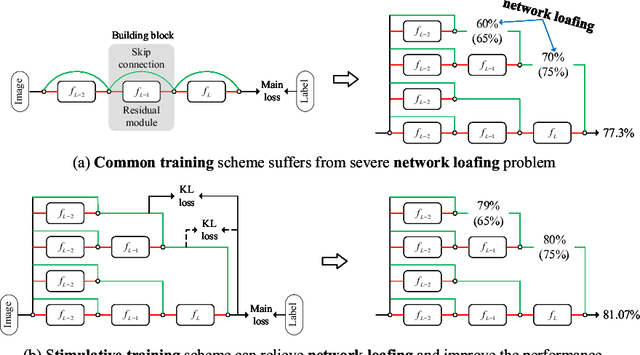
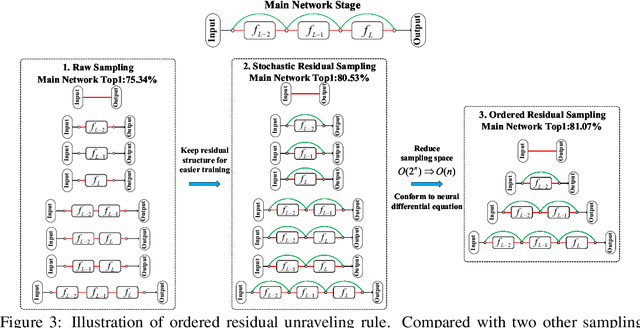
Residual networks have shown great success and become indispensable in today's deep models. In this work, we aim to re-investigate the training process of residual networks from a novel social psychology perspective of loafing, and further propose a new training strategy to strengthen the performance of residual networks. As residual networks can be viewed as ensembles of relatively shallow networks (i.e., \textit{unraveled view}) in prior works, we also start from such view and consider that the final performance of a residual network is co-determined by a group of sub-networks. Inspired by the social loafing problem of social psychology, we find that residual networks invariably suffer from similar problem, where sub-networks in a residual network are prone to exert less effort when working as part of the group compared to working alone. We define this previously overlooked problem as \textit{network loafing}. As social loafing will ultimately cause the low individual productivity and the reduced overall performance, network loafing will also hinder the performance of a given residual network and its sub-networks. Referring to the solutions of social psychology, we propose \textit{stimulative training}, which randomly samples a residual sub-network and calculates the KL-divergence loss between the sampled sub-network and the given residual network, to act as extra supervision for sub-networks and make the overall goal consistent. Comprehensive empirical results and theoretical analyses verify that stimulative training can well handle the loafing problem, and improve the performance of a residual network by improving the performance of its sub-networks. The code is available at https://github.com/Sunshine-Ye/NIPS22-ST .
Towards Frame Rate Agnostic Multi-Object Tracking
Oct 07, 2022

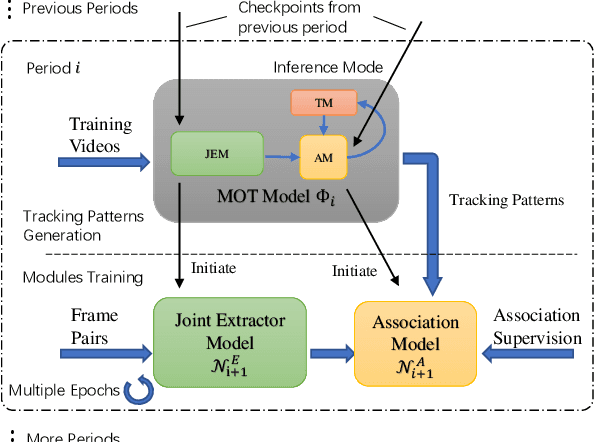
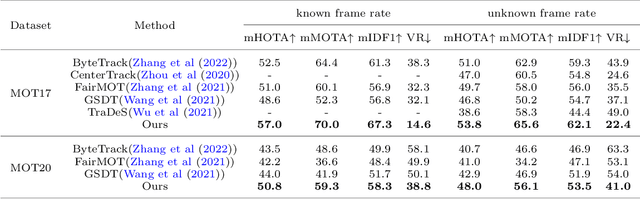
Multi-Object Tracking (MOT) is one of the most fundamental computer vision tasks which contributes to a variety of video analysis applications. Despite the recent promising progress, current MOT research is still limited to a fixed sampling frame rate of the input stream. In fact, we empirically find that the accuracy of all recent state-of-the-art trackers drops dramatically when the input frame rate changes. For a more intelligent tracking solution, we shift the attention of our research work to the problem of Frame Rate Agnostic MOT (FraMOT). In this paper, we propose a Frame Rate Agnostic MOT framework with Periodic training Scheme (FAPS) to tackle the FraMOT problem for the first time. Specifically, we propose a Frame Rate Agnostic Association Module (FAAM) that infers and encodes the frame rate information to aid identity matching across multi-frame-rate inputs, improving the capability of the learned model in handling complex motion-appearance relations in FraMOT. Besides, the association gap between training and inference is enlarged in FraMOT because those post-processing steps not included in training make a larger difference in lower frame rate scenarios. To address it, we propose Periodic Training Scheme (PTS) to reflect all post-processing steps in training via tracking pattern matching and fusion. Along with the proposed approaches, we make the first attempt to establish an evaluation method for this new task of FraMOT in two different modes, i.e., known frame rate and unknown frame rate, aiming to handle a more complex situation. The quantitative experiments on the challenging MOT datasets (FraMOT version) have clearly demonstrated that the proposed approaches can handle different frame rates better and thus improve the robustness against complicated scenarios.
CLIP2Point: Transfer CLIP to Point Cloud Classification with Image-Depth Pre-training
Oct 03, 2022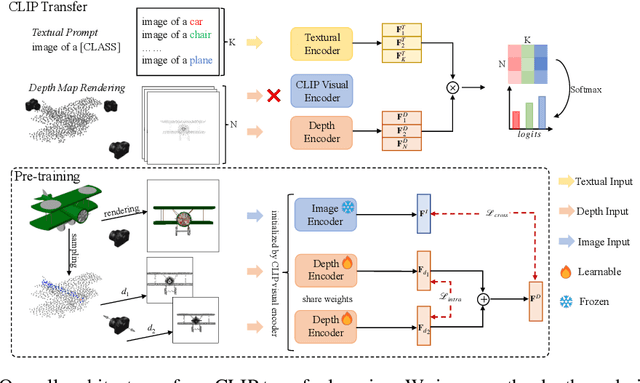

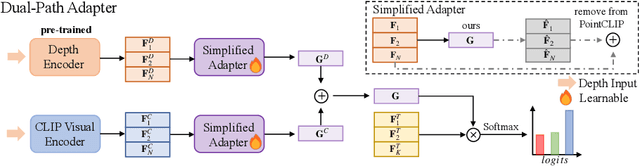

Pre-training across 3D vision and language remains under development because of limited training data. Recent works attempt to transfer vision-language pre-training models to 3D vision. PointCLIP converts point cloud data to multi-view depth maps, adopting CLIP for shape classification. However, its performance is restricted by the domain gap between rendered depth maps and images, as well as the diversity of depth distributions. To address this issue, we propose CLIP2Point, an image-depth pre-training method by contrastive learning to transfer CLIP to the 3D domain, and adapt it to point cloud classification. We introduce a new depth rendering setting that forms a better visual effect, and then render 52,460 pairs of images and depth maps from ShapeNet for pre-training. The pre-training scheme of CLIP2Point combines cross-modality learning to enforce the depth features for capturing expressive visual and textual features and intra-modality learning to enhance the invariance of depth aggregation. Additionally, we propose a novel Dual-Path Adapter (DPA) module, i.e., a dual-path structure with simplified adapters for few-shot learning. The dual-path structure allows the joint use of CLIP and CLIP2Point, and the simplified adapter can well fit few-shot tasks without post-search. Experimental results show that CLIP2Point is effective in transferring CLIP knowledge to 3D vision. Our CLIP2Point outperforms PointCLIP and other self-supervised 3D networks, achieving state-of-the-art results on zero-shot and few-shot classification.
ZoomNAS: Searching for Whole-body Human Pose Estimation in the Wild
Aug 23, 2022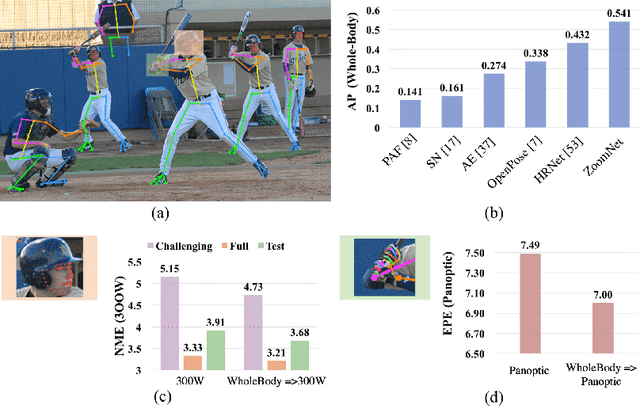
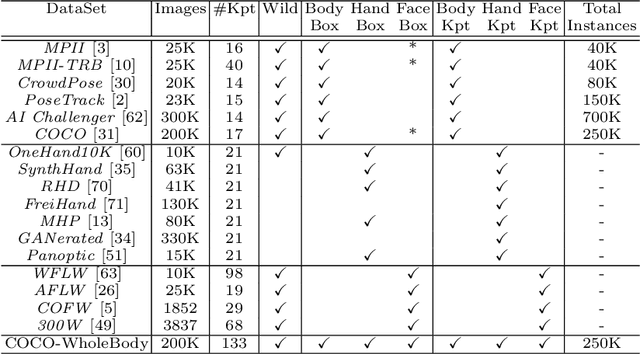

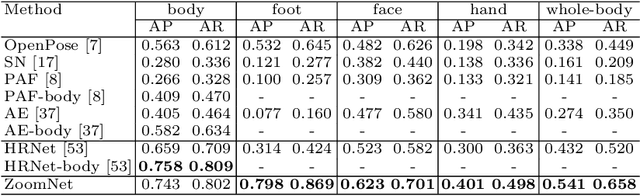
This paper investigates the task of 2D whole-body human pose estimation, which aims to localize dense landmarks on the entire human body including body, feet, face, and hands. We propose a single-network approach, termed ZoomNet, to take into account the hierarchical structure of the full human body and solve the scale variation of different body parts. We further propose a neural architecture search framework, termed ZoomNAS, to promote both the accuracy and efficiency of whole-body pose estimation. ZoomNAS jointly searches the model architecture and the connections between different sub-modules, and automatically allocates computational complexity for searched sub-modules. To train and evaluate ZoomNAS, we introduce the first large-scale 2D human whole-body dataset, namely COCO-WholeBody V1.0, which annotates 133 keypoints for in-the-wild images. Extensive experiments demonstrate the effectiveness of ZoomNAS and the significance of COCO-WholeBody V1.0.
An Empirical Study of Pseudo-Labeling for Image-based 3D Object Detection
Aug 15, 2022

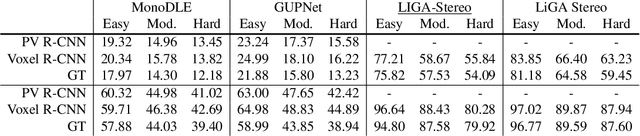
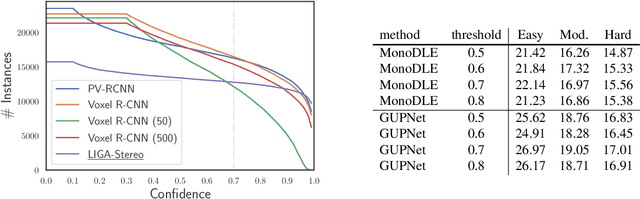
Image-based 3D detection is an indispensable component of the perception system for autonomous driving. However, it still suffers from the unsatisfying performance, one of the main reasons for which is the limited training data. Unfortunately, annotating the objects in the 3D space is extremely time/resource-consuming, which makes it hard to extend the training set arbitrarily. In this work, we focus on the semi-supervised manner and explore the feasibility of a cheaper alternative, i.e. pseudo-labeling, to leverage the unlabeled data. For this purpose, we conduct extensive experiments to investigate whether the pseudo-labels can provide effective supervision for the baseline models under varying settings. The experimental results not only demonstrate the effectiveness of the pseudo-labeling mechanism for image-based 3D detection (e.g. under monocular setting, we achieve 20.23 AP for moderate level on the KITTI-3D testing set without bells and whistles, improving the baseline model by 6.03 AP), but also show several interesting and noteworthy findings (e.g. the models trained with pseudo-labels perform better than that trained with ground-truth annotations based on the same training data). We hope this work can provide insights for the image-based 3D detection community under a semi-supervised setting. The codes, pseudo-labels, and pre-trained models will be publicly available.
Fine-grained Retrieval Prompt Tuning
Jul 29, 2022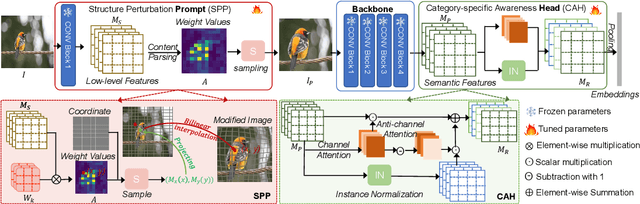
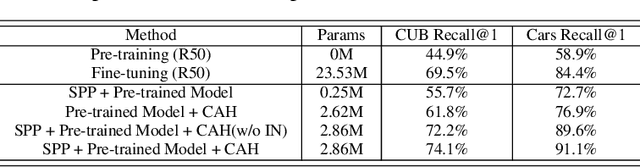
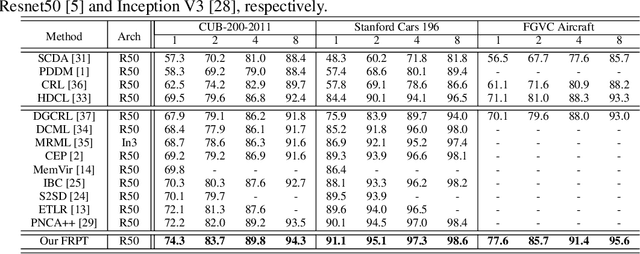

Fine-grained object retrieval aims to learn discriminative representation to retrieve visually similar objects. However, existing top-performing works usually impose pairwise similarities on the semantic embedding spaces to continually fine-tune the entire model in limited-data regimes, thus resulting in easily converging to suboptimal solutions. In this paper, we develop Fine-grained Retrieval Prompt Tuning (FRPT), which steers a frozen pre-trained model to perform the fine-grained retrieval task from the perspectives of sample prompt and feature adaptation. Specifically, FRPT only needs to learn fewer parameters in the prompt and adaptation instead of fine-tuning the entire model, thus solving the convergence to suboptimal solutions caused by fine-tuning the entire model. Technically, as sample prompts, a structure perturbation prompt (SPP) is introduced to zoom and even exaggerate some pixels contributing to category prediction via a content-aware inhomogeneous sampling operation. In this way, SPP can make the fine-grained retrieval task aided by the perturbation prompts close to the solved task during the original pre-training. Besides, a category-specific awareness head is proposed and regarded as feature adaptation, which removes the species discrepancies in the features extracted by the pre-trained model using instance normalization, and thus makes the optimized features only include the discrepancies among subcategories. Extensive experiments demonstrate that our FRPT with fewer learnable parameters achieves the state-of-the-art performance on three widely-used fine-grained datasets.
3D Interacting Hand Pose Estimation by Hand De-occlusion and Removal
Jul 22, 2022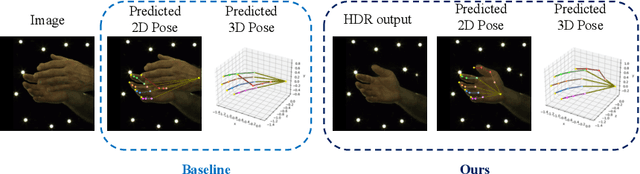
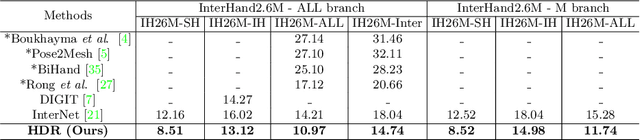
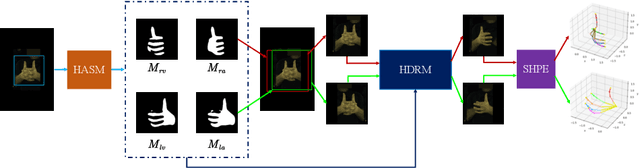
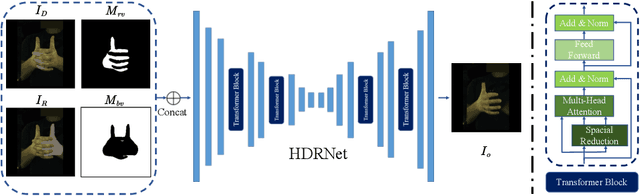
Estimating 3D interacting hand pose from a single RGB image is essential for understanding human actions. Unlike most previous works that directly predict the 3D poses of two interacting hands simultaneously, we propose to decompose the challenging interacting hand pose estimation task and estimate the pose of each hand separately. In this way, it is straightforward to take advantage of the latest research progress on the single-hand pose estimation system. However, hand pose estimation in interacting scenarios is very challenging, due to (1) severe hand-hand occlusion and (2) ambiguity caused by the homogeneous appearance of hands. To tackle these two challenges, we propose a novel Hand De-occlusion and Removal (HDR) framework to perform hand de-occlusion and distractor removal. We also propose the first large-scale synthetic amodal hand dataset, termed Amodal InterHand Dataset (AIH), to facilitate model training and promote the development of the related research. Experiments show that the proposed method significantly outperforms previous state-of-the-art interacting hand pose estimation approaches. Codes and data are available at https://github.com/MengHao666/HDR.
NSNet: Non-saliency Suppression Sampler for Efficient Video Recognition
Jul 21, 2022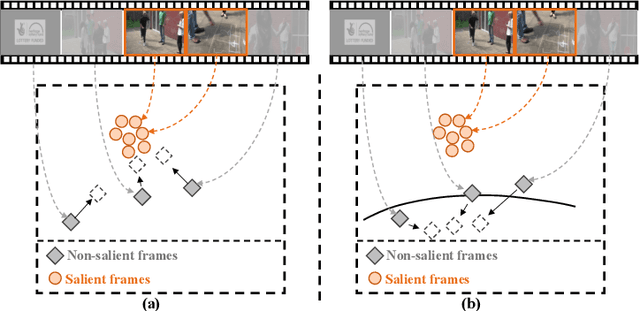
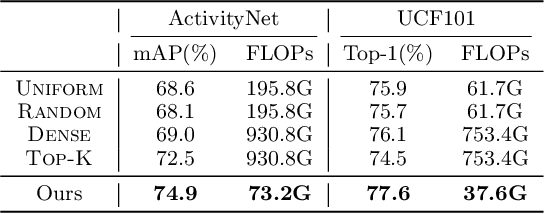

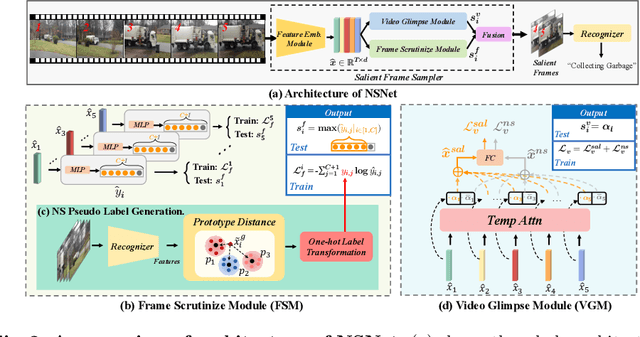
It is challenging for artificial intelligence systems to achieve accurate video recognition under the scenario of low computation costs. Adaptive inference based efficient video recognition methods typically preview videos and focus on salient parts to reduce computation costs. Most existing works focus on complex networks learning with video classification based objectives. Taking all frames as positive samples, few of them pay attention to the discrimination between positive samples (salient frames) and negative samples (non-salient frames) in supervisions. To fill this gap, in this paper, we propose a novel Non-saliency Suppression Network (NSNet), which effectively suppresses the responses of non-salient frames. Specifically, on the frame level, effective pseudo labels that can distinguish between salient and non-salient frames are generated to guide the frame saliency learning. On the video level, a temporal attention module is learned under dual video-level supervisions on both the salient and the non-salient representations. Saliency measurements from both two levels are combined for exploitation of multi-granularity complementary information. Extensive experiments conducted on four well-known benchmarks verify our NSNet not only achieves the state-of-the-art accuracy-efficiency trade-off but also present a significantly faster (2.4~4.3x) practical inference speed than state-of-the-art methods. Our project page is at https://lawrencexia2008.github.io/projects/nsnet .
Pose for Everything: Towards Category-Agnostic Pose Estimation
Jul 21, 2022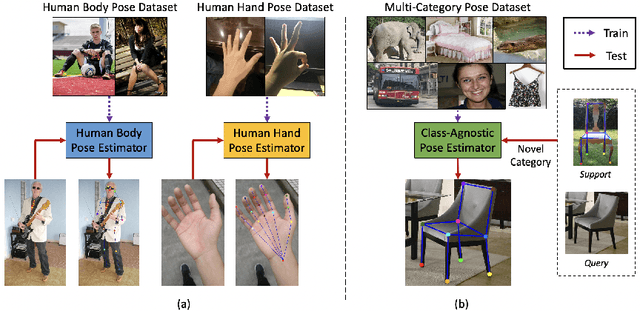
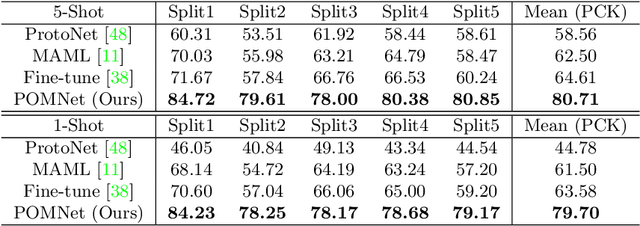
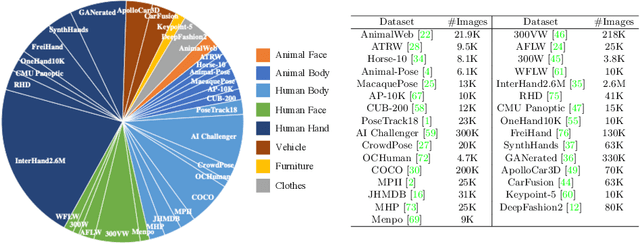

Existing works on 2D pose estimation mainly focus on a certain category, e.g. human, animal, and vehicle. However, there are lots of application scenarios that require detecting the poses/keypoints of the unseen class of objects. In this paper, we introduce the task of Category-Agnostic Pose Estimation (CAPE), which aims to create a pose estimation model capable of detecting the pose of any class of object given only a few samples with keypoint definition. To achieve this goal, we formulate the pose estimation problem as a keypoint matching problem and design a novel CAPE framework, termed POse Matching Network (POMNet). A transformer-based Keypoint Interaction Module (KIM) is proposed to capture both the interactions among different keypoints and the relationship between the support and query images. We also introduce Multi-category Pose (MP-100) dataset, which is a 2D pose dataset of 100 object categories containing over 20K instances and is well-designed for developing CAPE algorithms. Experiments show that our method outperforms other baseline approaches by a large margin. Codes and data are available at https://github.com/luminxu/Pose-for-Everything.