 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanli Ouyang
Bidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
Dec 31, 2022
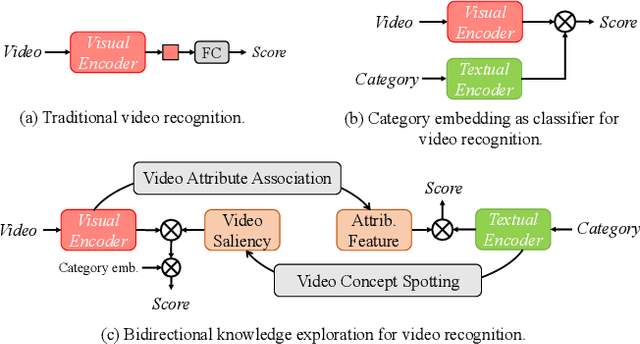
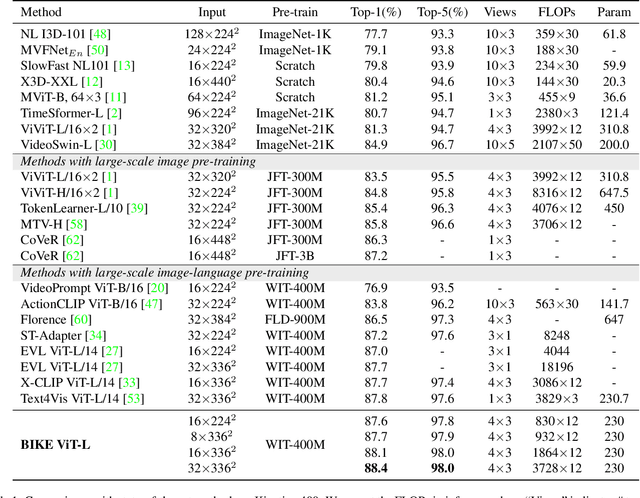
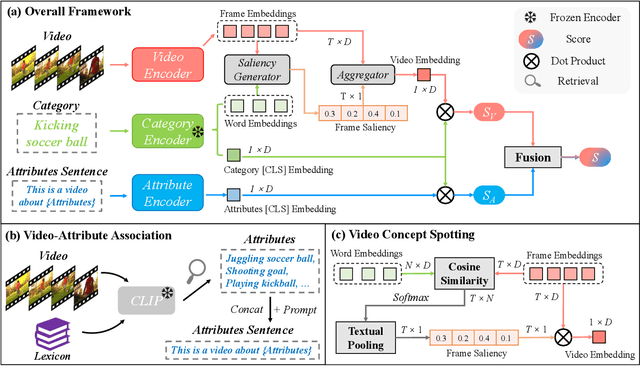
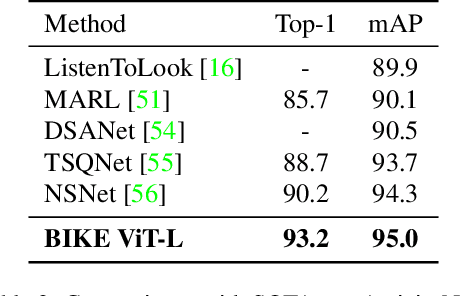
Vision-language models (VLMs) that are pre-trained on large-scale image-text pairs have demonstrated impressive transferability on a wide range of visual tasks. Transferring knowledge from such powerful pre-trained VLMs is emerging as a promising direction for building effective video recognition models. However, the current exploration is still limited. In our opinion, the greatest charm of pre-trained vision-language models is to build a bridge between visual and textual domains. In this paper, we present a novel framework called BIKE which utilizes the cross-modal bridge to explore bidirectional knowledge: i) We propose a Video Attribute Association mechanism which leverages the Video-to-Text knowledge to generate textual auxiliary attributes to complement video recognition. ii) We also present a Temporal Concept Spotting mechanism which uses the Text-to-Video expertise to capture temporal saliency in a parameter-free manner to yield enhanced video representation. The extensive studies on popular video datasets (ie, Kinetics-400 & 600, UCF-101, HMDB-51 and ActivityNet) show that our method achieves state-of-the-art performance in most recognition scenarios, eg, general, zero-shot, and few-shot video recognition. To the best of our knowledge, our best model achieves a state-of-the-art accuracy of 88.4% on challenging Kinetics-400 with the released CLIP pre-trained model.
Ponder: Point Cloud Pre-training via Neural Rendering
Dec 31, 2022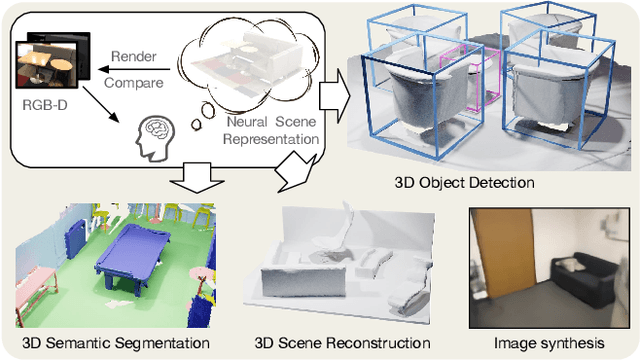
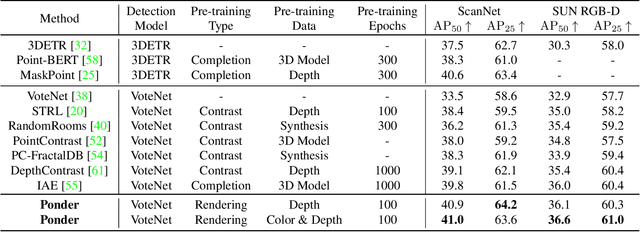
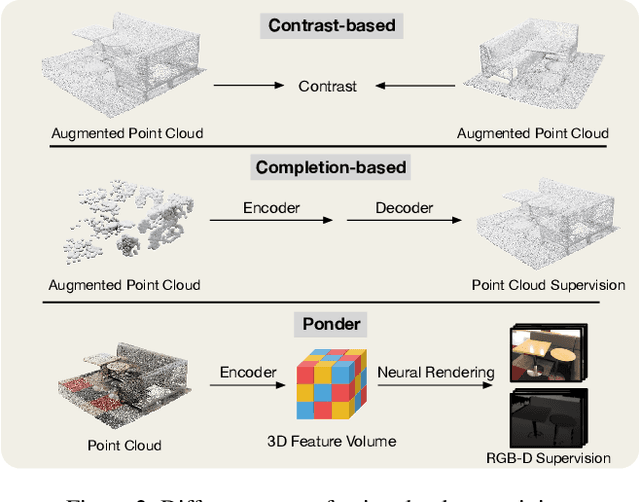
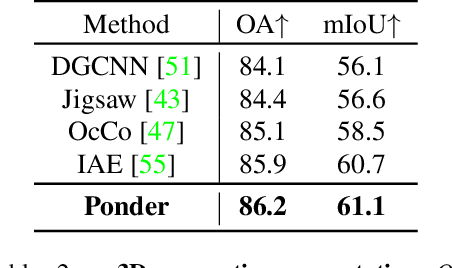
We propose a novel approach to self-supervised learning of point cloud representations by differentiable neural rendering. Motivated by the fact that informative point cloud features should be able to encode rich geometry and appearance cues and render realistic images, we train a point-cloud encoder within a devised point-based neural renderer by comparing the rendered images with real images on massive RGB-D data. The learned point-cloud encoder can be easily integrated into various downstream tasks, including not only high-level tasks like 3D detection and segmentation, but low-level tasks like 3D reconstruction and image synthesis. Extensive experiments on various tasks demonstrate the superiority of our approach compared to existing pre-training methods.
MM-3DScene: 3D Scene Understanding by Customizing Masked Modeling with Informative-Preserved Reconstruction and Self-Distilled Consistency
Dec 20, 2022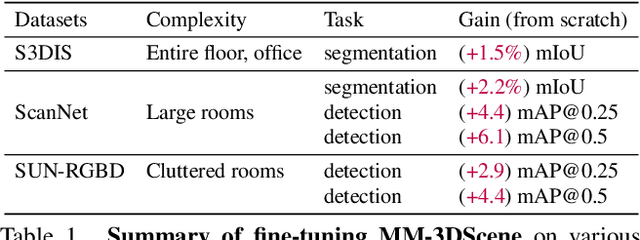
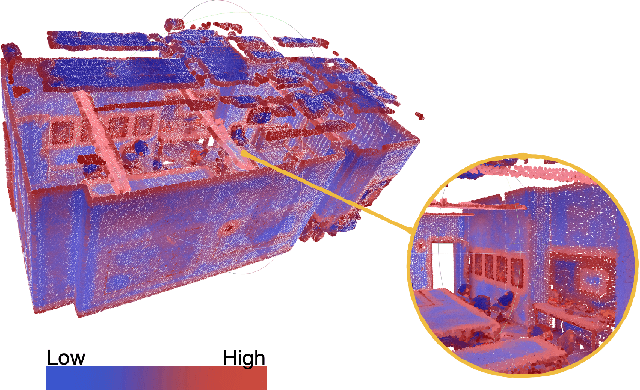

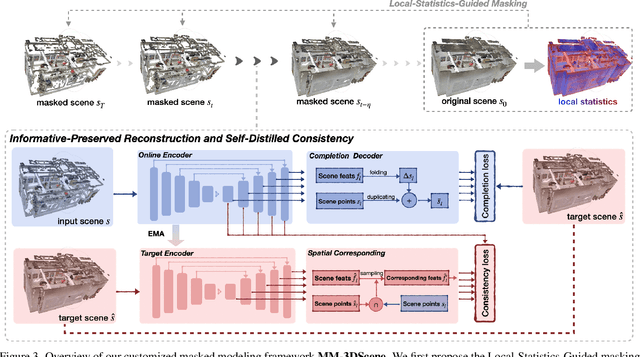
Masked Modeling (MM) has demonstrated widespread success in various vision challenges, by reconstructing masked visual patches. Yet, applying MM for large-scale 3D scenes remains an open problem due to the data sparsity and scene complexity. The conventional random masking paradigm used in 2D images often causes a high risk of ambiguity when recovering the masked region of 3D scenes. To this end, we propose a novel informative-preserved reconstruction, which explores local statistics to discover and preserve the representative structured points, effectively enhancing the pretext masking task for 3D scene understanding. Integrated with a progressive reconstruction manner, our method can concentrate on modeling regional geometry and enjoy less ambiguity for masked reconstruction. Besides, such scenes with progressive masking ratios can also serve to self-distill their intrinsic spatial consistency, requiring to learn the consistent representations from unmasked areas. By elegantly combining informative-preserved reconstruction on masked areas and consistency self-distillation from unmasked areas, a unified framework called MM-3DScene is yielded. We conduct comprehensive experiments on a host of downstream tasks. The consistent improvement (e.g., +6.1 mAP@0.5 on object detection and +2.2% mIoU on semantic segmentation) demonstrates the superiority of our approach.
3D Point Cloud Pre-training with Knowledge Distillation from 2D Images
Dec 17, 2022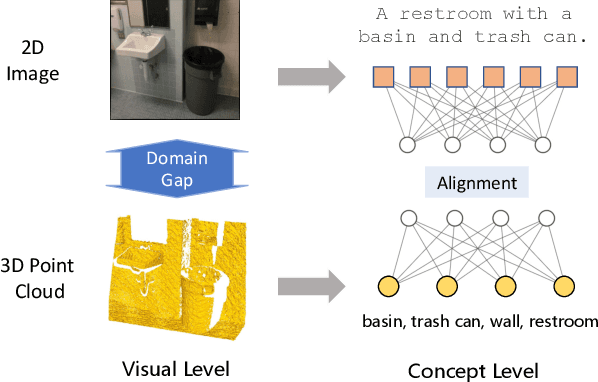
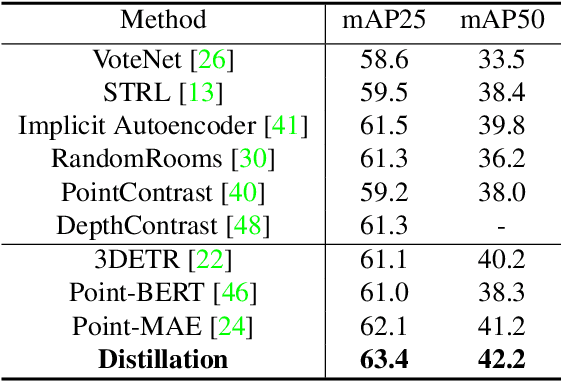
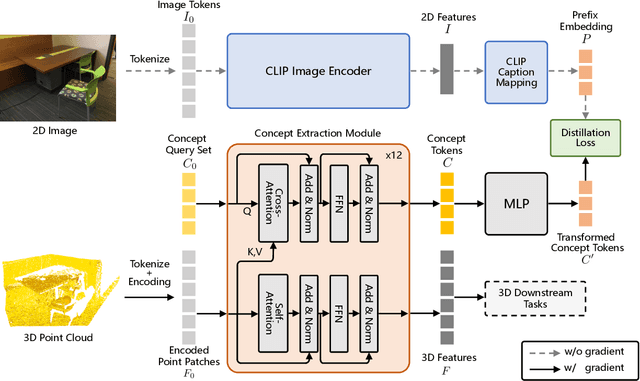
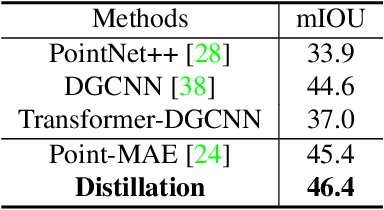
The recent success of pre-trained 2D vision models is mostly attributable to learning from large-scale datasets. However, compared with 2D image datasets, the current pre-training data of 3D point cloud is limited. To overcome this limitation, we propose a knowledge distillation method for 3D point cloud pre-trained models to acquire knowledge directly from the 2D representation learning model, particularly the image encoder of CLIP, through concept alignment. Specifically, we introduce a cross-attention mechanism to extract concept features from 3D point cloud and compare them with the semantic information from 2D images. In this scheme, the point cloud pre-trained models learn directly from rich information contained in 2D teacher models. Extensive experiments demonstrate that the proposed knowledge distillation scheme achieves higher accuracy than the state-of-the-art 3D pre-training methods for synthetic and real-world datasets on downstream tasks, including object classification, object detection, semantic segmentation, and part segmentation.
Frozen CLIP Model is An Efficient Point Cloud Backbone
Dec 09, 2022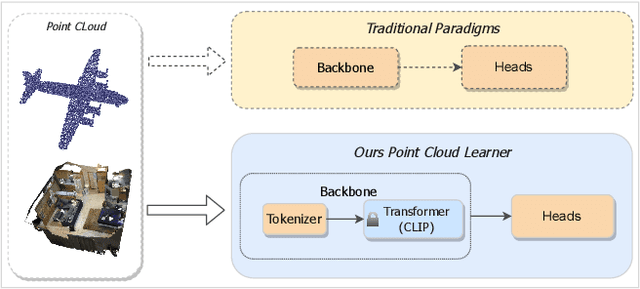

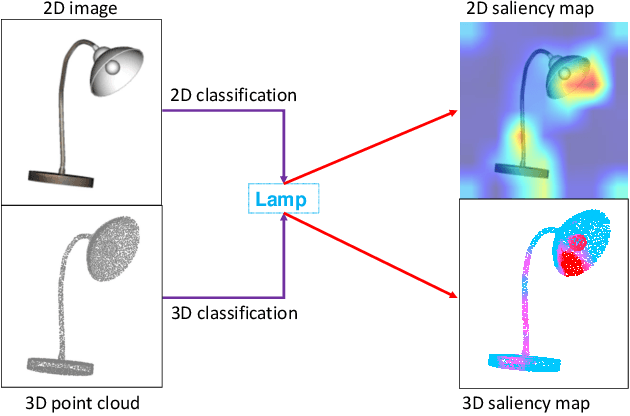
The pretraining-finetuning paradigm has demonstrated great success in NLP and 2D image fields because of the high-quality representation ability and transferability of their pretrained models. However, pretraining such a strong model is difficult in the 3D point cloud field since the training data is limited and point cloud collection is expensive. This paper introduces Efficient Point Cloud Learning (EPCL), an effective and efficient point cloud learner for directly training high-quality point cloud models with a frozen CLIP model. Our EPCL connects the 2D and 3D modalities by semantically aligning the 2D features and point cloud features without paired 2D-3D data. Specifically, the input point cloud is divided into a sequence of tokens and directly fed into the frozen CLIP model to learn point cloud representation. Furthermore, we design a task token to narrow the gap between 2D images and 3D point clouds. Comprehensive experiments on 3D detection, semantic segmentation, classification and few-shot learning demonstrate that the 2D CLIP model can be an efficient point cloud backbone and our method achieves state-of-the-art accuracy on both real-world and synthetic downstream tasks. Code will be available.
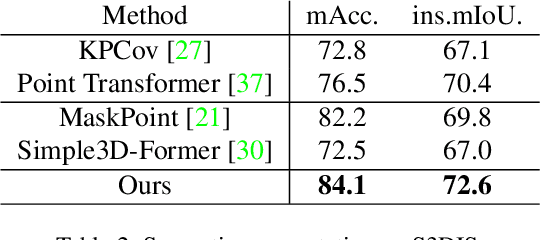
GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
Dec 07, 2022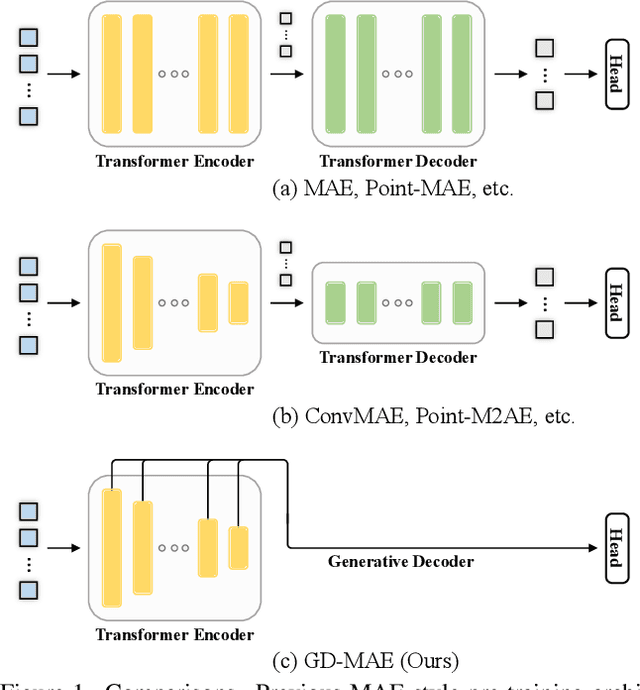
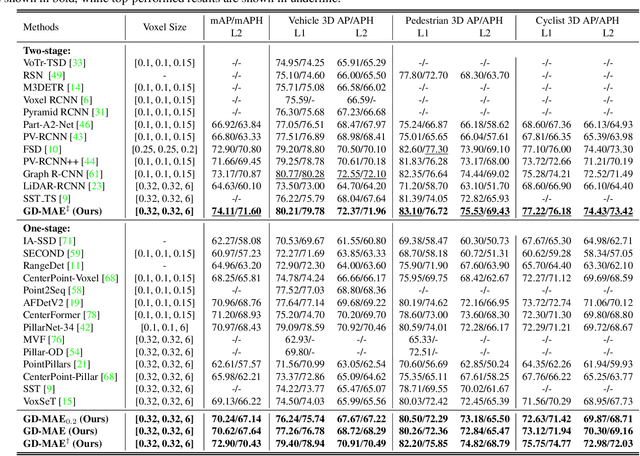
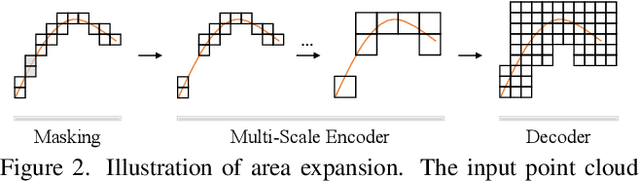
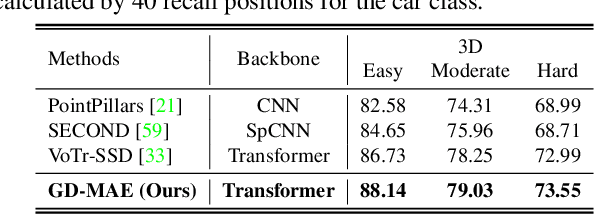
Despite the tremendous progress of Masked Autoencoders (MAE) in developing vision tasks such as image and video, exploring MAE in large-scale 3D point clouds remains challenging due to the inherent irregularity. In contrast to previous 3D MAE frameworks, which either design a complex decoder to infer masked information from maintained regions or adopt sophisticated masking strategies, we instead propose a much simpler paradigm. The core idea is to apply a \textbf{G}enerative \textbf{D}ecoder for MAE (GD-MAE) to automatically merges the surrounding context to restore the masked geometric knowledge in a hierarchical fusion manner. In doing so, our approach is free from introducing the heuristic design of decoders and enjoys the flexibility of exploring various masking strategies. The corresponding part costs less than \textbf{12\%} latency compared with conventional methods, while achieving better performance. We demonstrate the efficacy of the proposed method on several large-scale benchmarks: Waymo, KITTI, and ONCE. Consistent improvement on downstream detection tasks illustrates strong robustness and generalization capability. Not only our method reveals state-of-the-art results, but remarkably, we achieve comparable accuracy even with \textbf{20\%} of the labeled data on the Waymo dataset. The code will be released at \url{https://github.com/Nightmare-n/GD-MAE}.
ACE: Cooperative Multi-agent Q-learning with Bidirectional Action-Dependency
Dec 02, 2022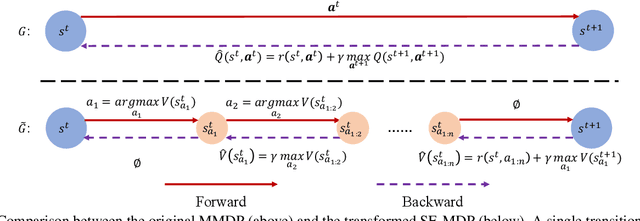
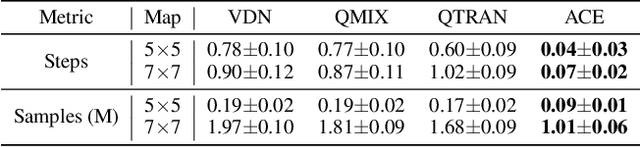
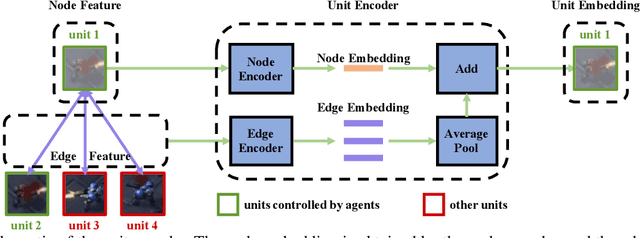
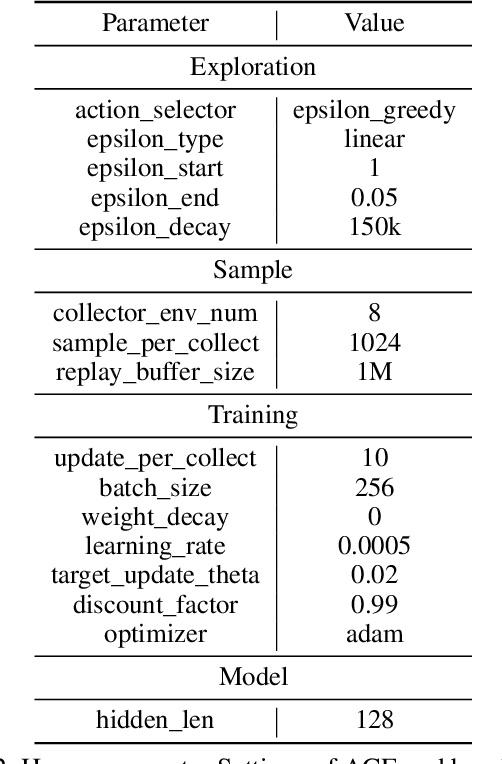
Multi-agent reinforcement learning (MARL) suffers from the non-stationarity problem, which is the ever-changing targets at every iteration when multiple agents update their policies at the same time. Starting from first principle, in this paper, we manage to solve the non-stationarity problem by proposing bidirectional action-dependent Q-learning (ACE). Central to the development of ACE is the sequential decision-making process wherein only one agent is allowed to take action at one time. Within this process, each agent maximizes its value function given the actions taken by the preceding agents at the inference stage. In the learning phase, each agent minimizes the TD error that is dependent on how the subsequent agents have reacted to their chosen action. Given the design of bidirectional dependency, ACE effectively turns a multiagent MDP into a single-agent MDP. We implement the ACE framework by identifying the proper network representation to formulate the action dependency, so that the sequential decision process is computed implicitly in one forward pass. To validate ACE, we compare it with strong baselines on two MARL benchmarks. Empirical experiments demonstrate that ACE outperforms the state-of-the-art algorithms on Google Research Football and StarCraft Multi-Agent Challenge by a large margin. In particular, on SMAC tasks, ACE achieves 100% success rate on almost all the hard and super-hard maps. We further study extensive research problems regarding ACE, including extension, generalization, and practicability. Code is made available to facilitate further research.
Reconstructing Hand-Held Objects from Monocular Video
Nov 30, 2022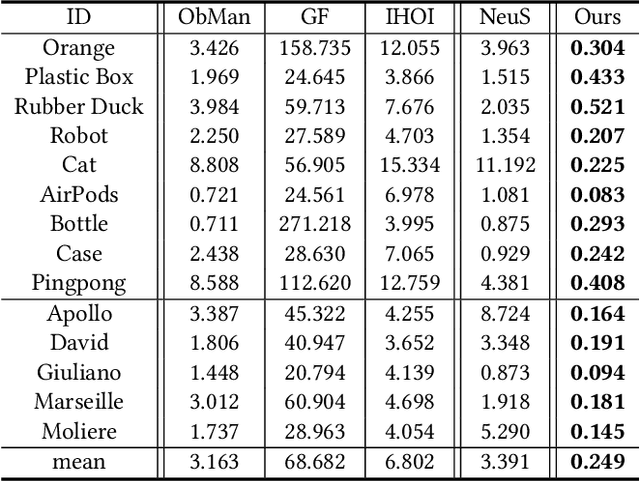
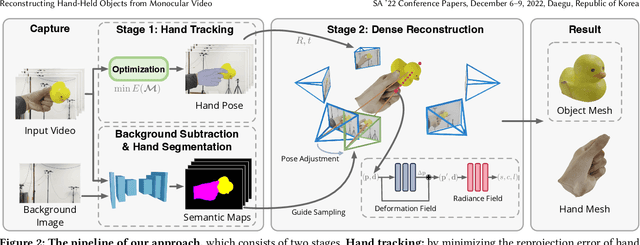


This paper presents an approach that reconstructs a hand-held object from a monocular video. In contrast to many recent methods that directly predict object geometry by a trained network, the proposed approach does not require any learned prior about the object and is able to recover more accurate and detailed object geometry. The key idea is that the hand motion naturally provides multiple views of the object and the motion can be reliably estimated by a hand pose tracker. Then, the object geometry can be recovered by solving a multi-view reconstruction problem. We devise an implicit neural representation-based method to solve the reconstruction problem and address the issues of imprecise hand pose estimation, relative hand-object motion, and insufficient geometry optimization for small objects. We also provide a newly collected dataset with 3D ground truth to validate the proposed approach.
3D-QueryIS: A Query-based Framework for 3D Instance Segmentation
Nov 17, 2022Previous top-performing methods for 3D instance segmentation often maintain inter-task dependencies and the tendency towards a lack of robustness. Besides, inevitable variations of different datasets make these methods become particularly sensitive to hyper-parameter values and manifest poor generalization capability. In this paper, we address the aforementioned challenges by proposing a novel query-based method, termed as 3D-QueryIS, which is detector-free, semantic segmentation-free, and cluster-free. Specifically, we propose to generate representative points in an implicit manner, and use them together with the initial queries to generate the informative instance queries. Then, the class and binary instance mask predictions can be produced by simply applying MLP layers on top of the instance queries and the extracted point cloud embeddings. Thus, our 3D-QueryIS is free from the accumulated errors caused by the inter-task dependencies. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and efficiency of our proposed 3D-QueryIS method.
Boosting Semi-Supervised 3D Object Detection with Semi-Sampling
Nov 15, 2022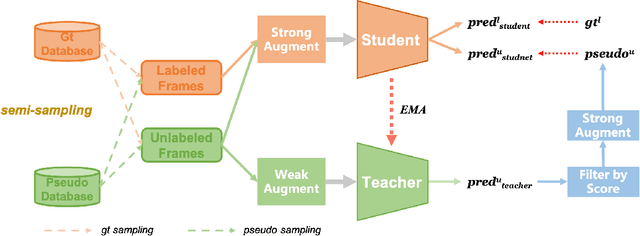
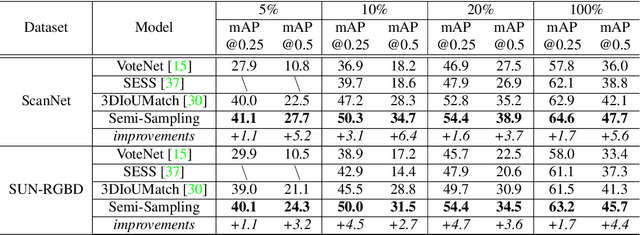

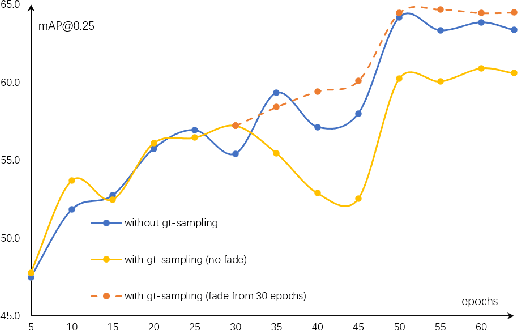
Current 3D object detection methods heavily rely on an enormous amount of annotations. Semi-supervised learning can be used to alleviate this issue. Previous semi-supervised 3D object detection methods directly follow the practice of fully-supervised methods to augment labeled and unlabeled data, which is sub-optimal. In this paper, we design a data augmentation method for semi-supervised learning, which we call Semi-Sampling. Specifically, we use ground truth labels and pseudo labels to crop gt samples and pseudo samples on labeled frames and unlabeled frames, respectively. Then we can generate a gt sample database and a pseudo sample database. When training a teacher-student semi-supervised framework, we randomly select gt samples and pseudo samples to both labeled frames and unlabeled frames, making a strong data augmentation for them. Our semi-sampling can be regarded as an extension of gt-sampling to semi-supervised learning. Our method is simple but effective. We consistently improve state-of-the-art methods on ScanNet, SUN-RGBD, and KITTI benchmarks by large margins. For example, when training using only 10% labeled data on ScanNet, we achieve 3.1 mAP and 6.4 mAP improvement upon 3DIoUMatch in terms of mAP@0.25 and mAP@0.5. When training using only 1% labeled data on KITTI, we boost 3DIoUMatch by 3.5 mAP, 6.7 mAP and 14.1 mAP on car, pedestrian and cyclist classes. Codes will be made publicly available at https://github.com/LittlePey/Semi-Sampling.