 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUC: Nonparametric Estimators and Their Smoothness
Jul 30, 2019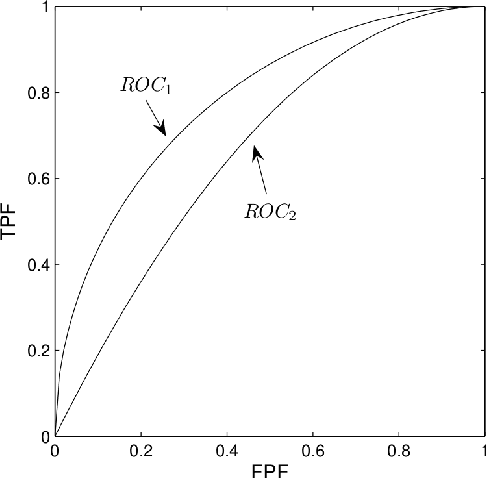

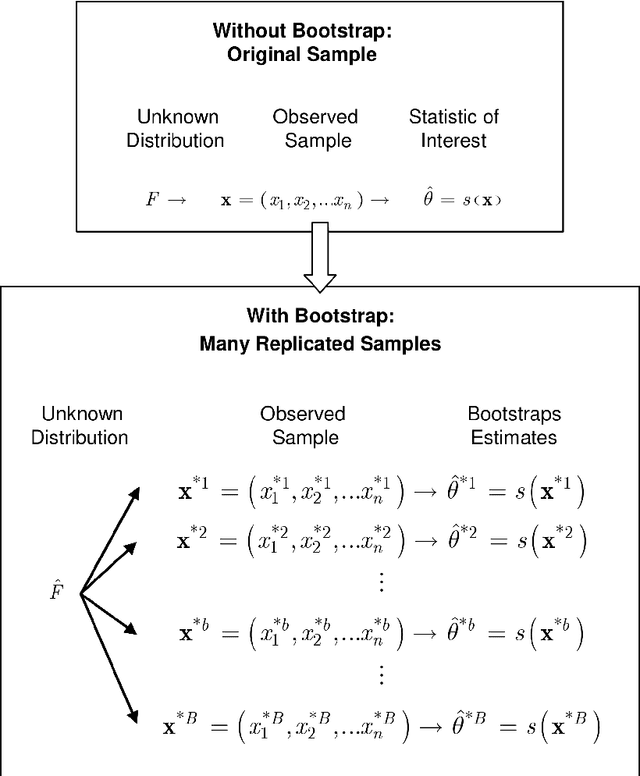
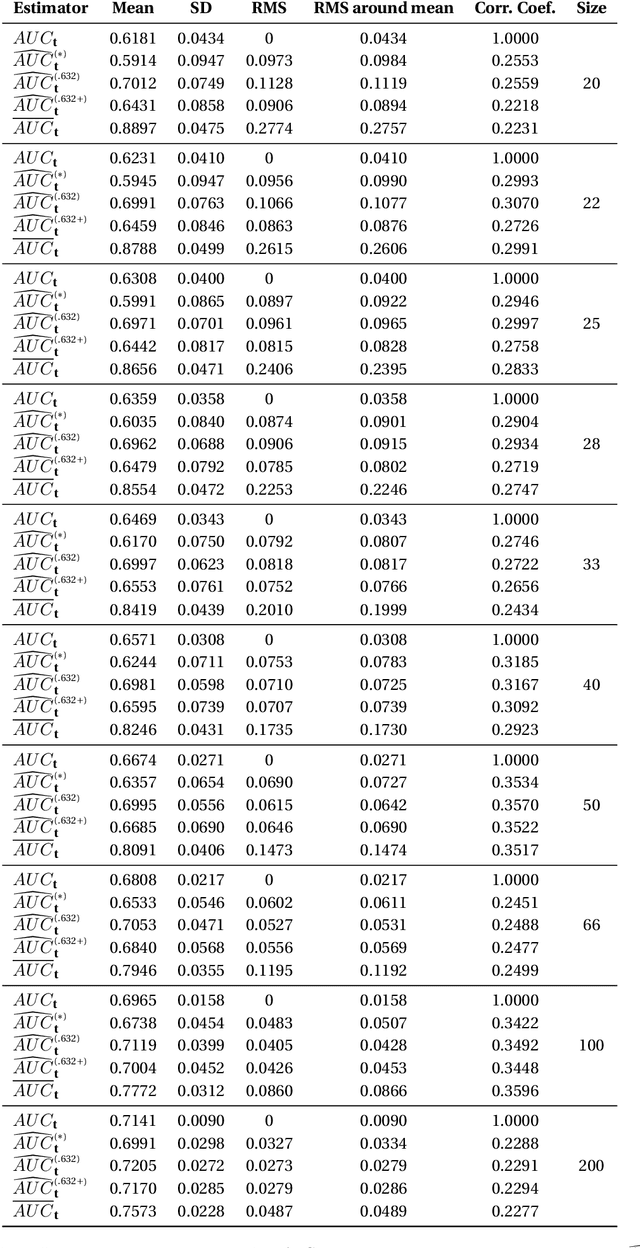
Nonparametric estimation of a statistic, in general, and of the error rate of a classification rule, in particular, from just one available dataset through resampling is well mathematically founded in the literature using several versions of bootstrap and influence function. This article first provides a concise review of this literature to establish the theoretical framework that we use to construct, in a single coherent framework, nonparametric estimators of the AUC (a two-sample statistic) other than the error rate (a one-sample statistic). In addition, the smoothness of some of these estimators is well investigated and explained. Our experiments show that the behavior of the designed AUC estimators confirms the findings of the literature for the behavior of error rate estimators in many aspects including: the weak correlation between the bootstrap-based estimators and the true conditional AUC; and the comparable accuracy of the different versions of the bootstrap estimators in terms of the RMS with little superiority of the .632+ bootstrap estimator.
A Review of Statistical Learning Machines from ATR to DNA Microarrays: design, assessment, and advice for practitioners
Jun 25, 2019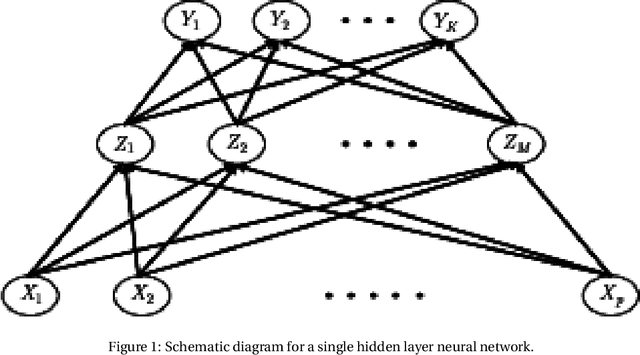
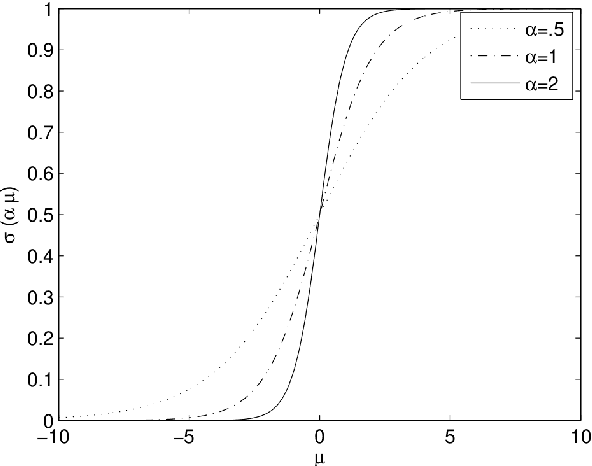
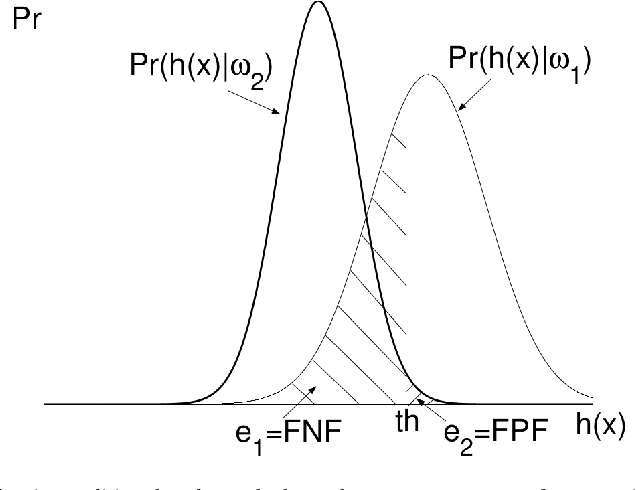
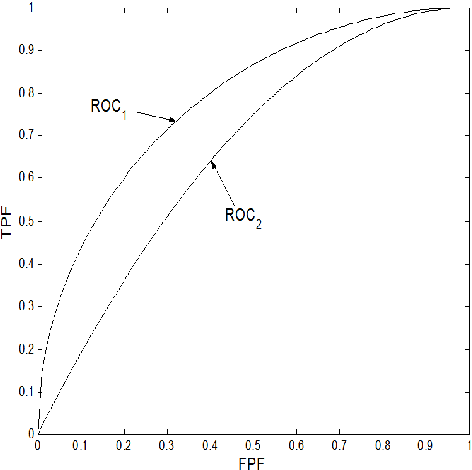
Statistical Learning is the process of estimating an unknown probabilistic input-output relationship of a system using a limited number of observations; and a statistical learning machine (SLM) is the machine that learned such a process. While their roots grow deeply in Probability Theory, SLMs are ubiquitous in the modern world. Automatic Target Recognition (ATR) in military applications, Computer Aided Diagnosis (CAD) in medical imaging, DNA microarrays in Genomics, Optical Character Recognition (OCR), Speech Recognition (SR), spam email filtering, stock market prediction, etc., are few examples and applications for SLM; diverse fields but one theory. The field of Statistical Learning can be decomposed to two basic subfields, Design and Assessment. Three main groups of specializations-namely statisticians, engineers, and computer scientists (ordered ascendingly by programming capabilities and descendingly by mathematical rigor)-exist on the venue of this field and each takes its elephant bite. Exaggerated rigorous analysis of statisticians sometimes deprives them from considering new ML techniques and methods that, yet, have no "complete" mathematical theory. On the other hand, immoderate add-hoc simulations of computer scientists sometimes derive them towards unjustified and immature results. A prudent approach is needed that has the enough flexibility to utilize simulations and trials and errors without sacrificing any rigor. If this prudent attitude is necessary for this field it is necessary, as well, in other fields of Engineering.
Learning meters of Arabic and English poems with Recurrent Neural Networks: a step forward for language understanding and synthesis
May 07, 2019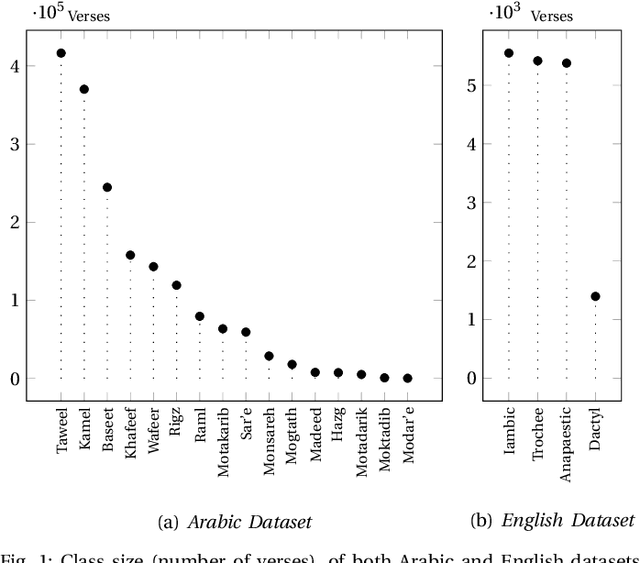
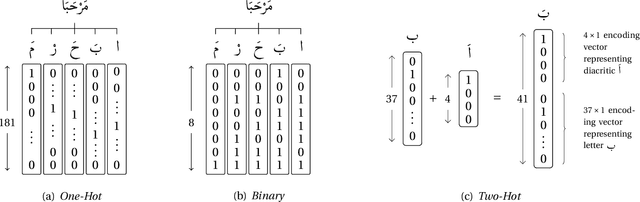
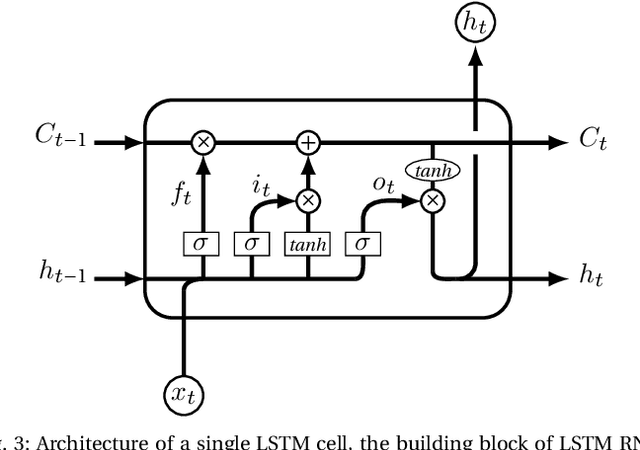
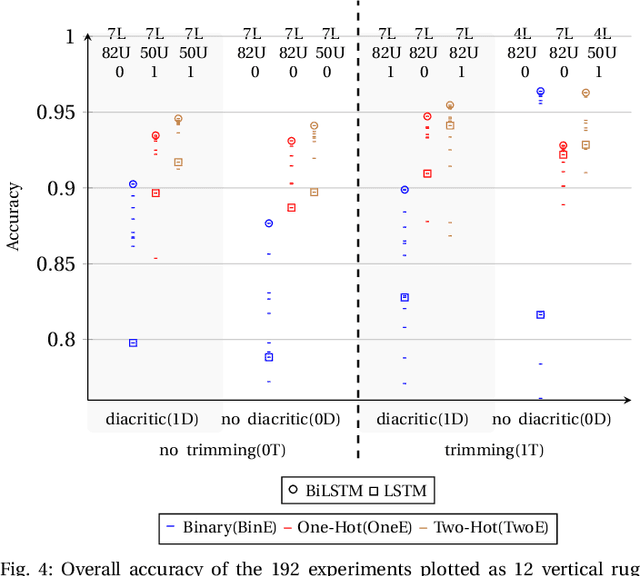
Recognizing a piece of writing as a poem or prose is usually easy for the majority of people; however, only specialists can determine which meter a poem belongs to. In this paper, we build Recurrent Neural Network (RNN) models that can classify poems according to their meters from plain text. The input text is encoded at the character level and directly fed to the models without feature handcrafting. This is a step forward for machine understanding and synthesis of languages in general, and Arabic language in particular. Among the 16 poem meters of Arabic and the 4 meters of English the networks were able to correctly classify poem with an overall accuracy of 96.38\% and 82.31\% respectively. The poem datasets used to conduct this research were massive, over 1.5 million of verses, and were crawled from different nontechnical sources, almost Arabic and English literature sites, and in different heterogeneous and unstructured formats. These datasets are now made publicly available in clean, structured, and documented format for other future research. To the best of the authors' knowledge, this research is the first to address classifying poem meters in a machine learning approach, in general, and in RNN featureless based approach, in particular. In addition, the dataset is the first publicly available dataset ready for the purpose of future computational research.
Matlab vs. OpenCV: A Comparative Study of Different Machine Learning Algorithms
May 03, 2019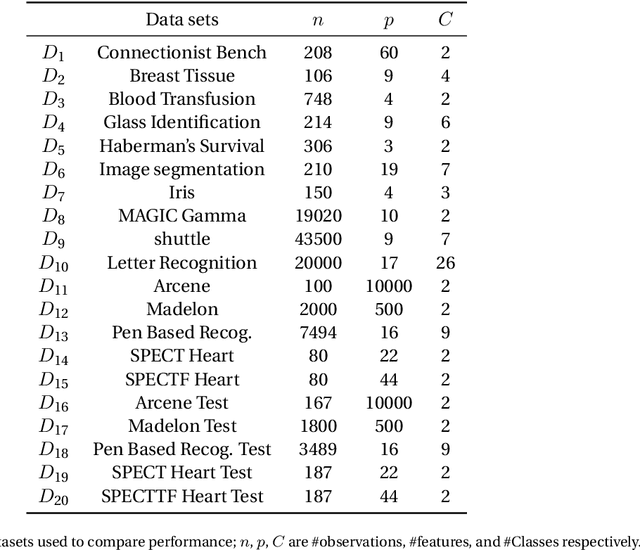
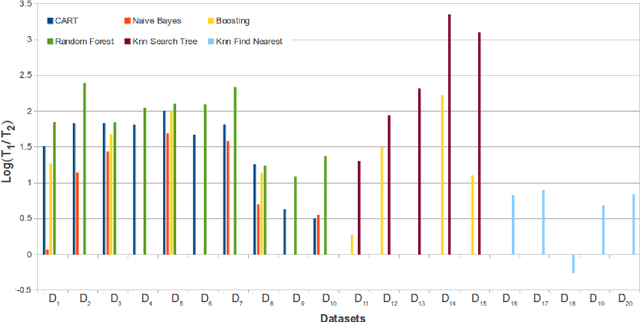
Scientific Computing relies on executing computer algorithms coded in some programming languages. Given a particular available hardware, algorithms speed is a crucial factor. There are many scientific computing environments used to code such algorithms. Matlab is one of the most tremendously successful and widespread scientific computing environments that is rich of toolboxes, libraries, and data visualization tools. OpenCV is a (C++)-based library written primarily for Computer Vision and its related areas. This paper presents a comparative study using 20 different real datasets to compare the speed of Matlab and OpenCV for some Machine Learning algorithms. Although Matlab is more convenient in developing and data presentation, OpenCV is much faster in execution, where the speed ratio reaches more than 80 in some cases. The best of two worlds can be achieved by exploring using Matlab or similar environments to select the most successful algorithm; then, implementing the selected algorithm using OpenCV or similar environments to gain a speed factor.