 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeselin Stoyanov
SemEval-2015 Task 10: Sentiment Analysis in Twitter
Dec 05, 2019
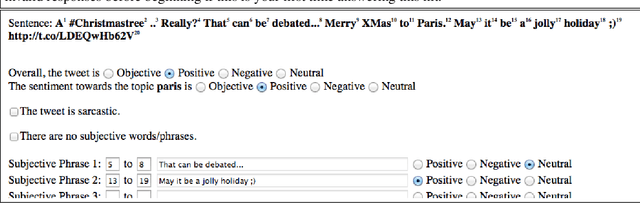

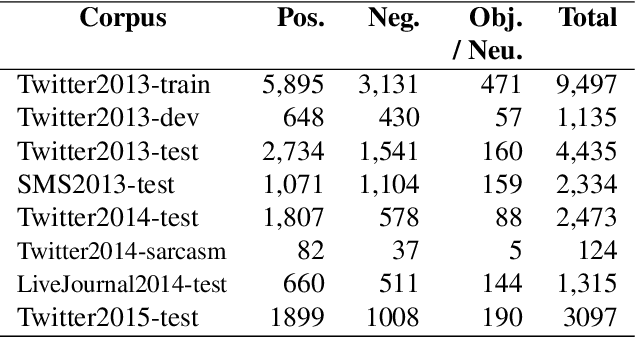
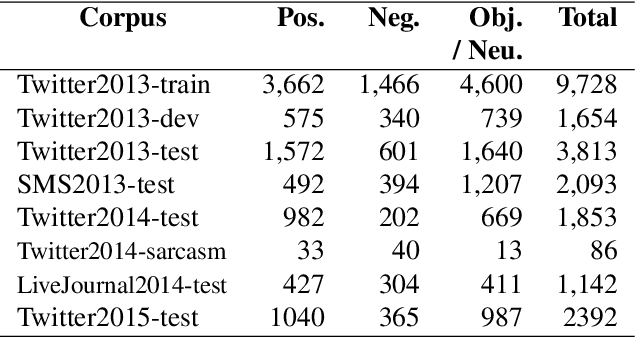
In this paper, we describe the 2015 iteration of the SemEval shared task on Sentiment Analysis in Twitter. This was the most popular sentiment analysis shared task to date with more than 40 teams participating in each of the last three years. This year's shared task competition consisted of five sentiment prediction subtasks. Two were reruns from previous years: (A) sentiment expressed by a phrase in the context of a tweet, and (B) overall sentiment of a tweet. We further included three new subtasks asking to predict (C) the sentiment towards a topic in a single tweet, (D) the overall sentiment towards a topic in a set of tweets, and (E) the degree of prior polarity of a phrase.
* Sentiment analysis, sentiment towards a topic, quantification, microblog sentiment analysis; Twitter opinion mining
SemEval-2016 Task 4: Sentiment Analysis in Twitter
Dec 03, 2019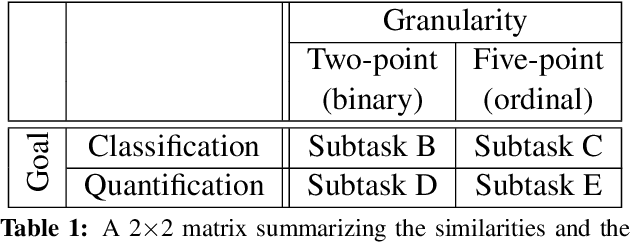
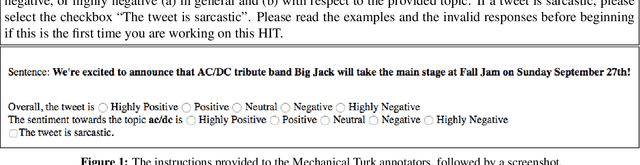
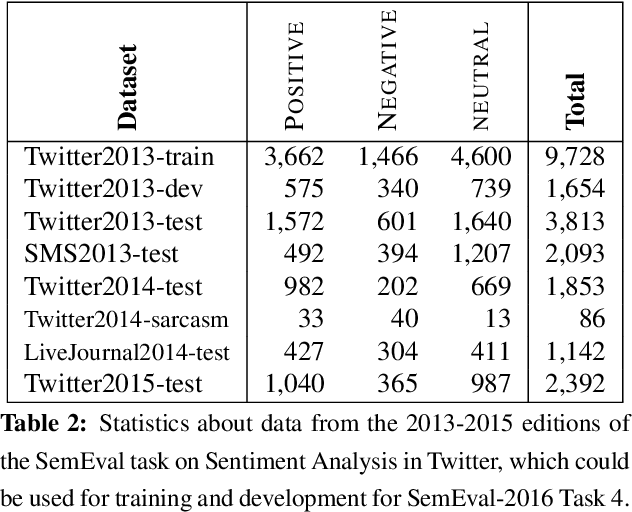
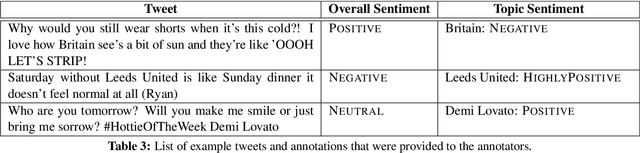
This paper discusses the fourth year of the ``Sentiment Analysis in Twitter Task''. SemEval-2016 Task 4 comprises five subtasks, three of which represent a significant departure from previous editions. The first two subtasks are reruns from prior years and ask to predict the overall sentiment, and the sentiment towards a topic in a tweet. The three new subtasks focus on two variants of the basic ``sentiment classification in Twitter'' task. The first variant adopts a five-point scale, which confers an ordinal character to the classification task. The second variant focuses on the correct estimation of the prevalence of each class of interest, a task which has been called quantification in the supervised learning literature. The task continues to be very popular, attracting a total of 43 teams.
* Sentiment analysis, sentiment towards a topic, quantification, microblog sentiment analysis; Twitter opinion mining. arXiv admin note: text overlap with arXiv:1912.00741
Emerging Cross-lingual Structure in Pretrained Language Models
Nov 10, 2019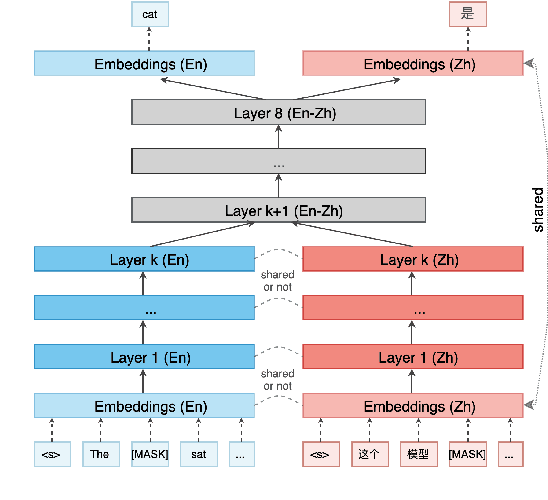
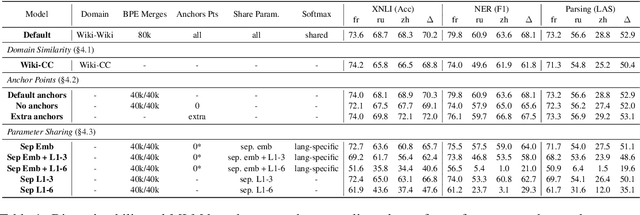
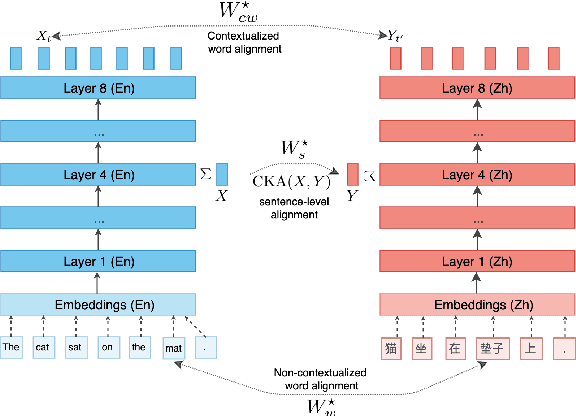
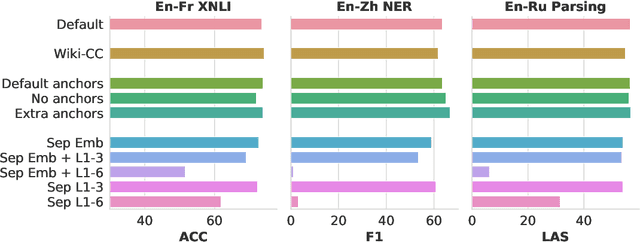
We study the problem of multilingual masked language modeling, i.e. the training of a single model on concatenated text from multiple languages, and present a detailed study of several factors that influence why these models are so effective for cross-lingual transfer. We show, contrary to what was previously hypothesized, that transfer is possible even when there is no shared vocabulary across the monolingual corpora and also when the text comes from very different domains. The only requirement is that there are some shared parameters in the top layers of the multi-lingual encoder. To better understand this result, we also show that representations from independently trained models in different languages can be aligned post-hoc quite effectively, strongly suggesting that, much like for non-contextual word embeddings, there are universal latent symmetries in the learned embedding spaces. For multilingual masked language modeling, these symmetries seem to be automatically discovered and aligned during the joint training process.
Unsupervised Cross-lingual Representation Learning at Scale
Nov 05, 2019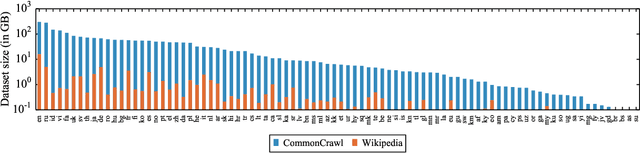
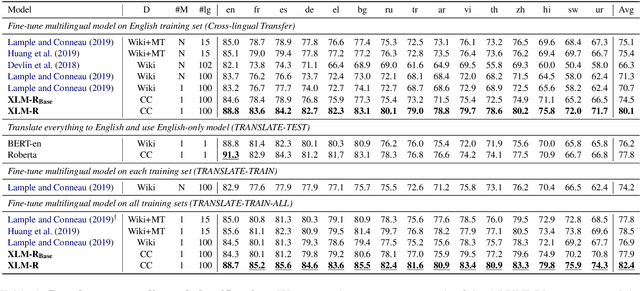
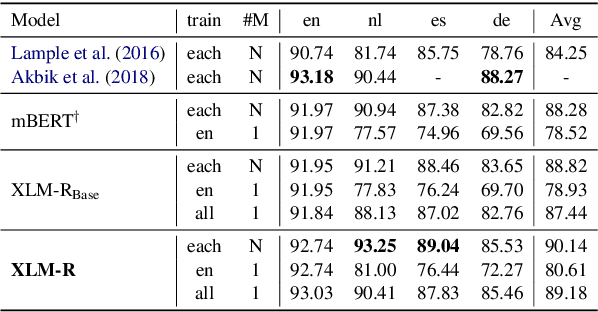
This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a wide range of cross-lingual transfer tasks. We train a Transformer-based masked language model on one hundred languages, using more than two terabytes of filtered CommonCrawl data. Our model, dubbed XLM-R, significantly outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model. We also present a detailed empirical evaluation of the key factors that are required to achieve these gains, including the trade-offs between (1) positive transfer and capacity dilution and (2) the performance of high and low resource languages at scale. Finally, we show, for the first time, the possibility of multilingual modeling without sacrificing per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We will make XLM-R code, data, and models publicly available.
Bridging the domain gap in cross-lingual document classification
Sep 20, 2019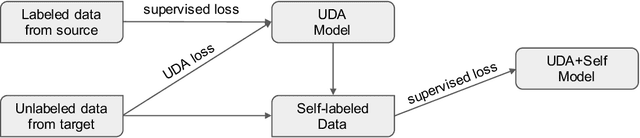
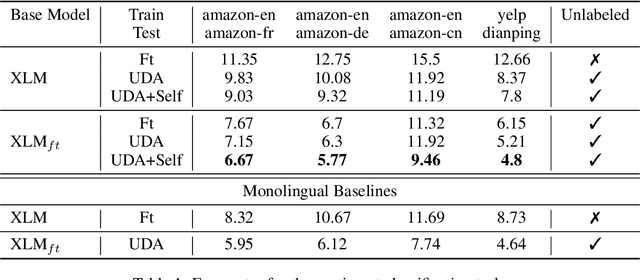
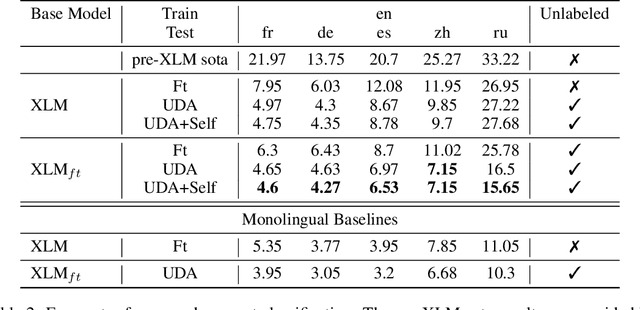
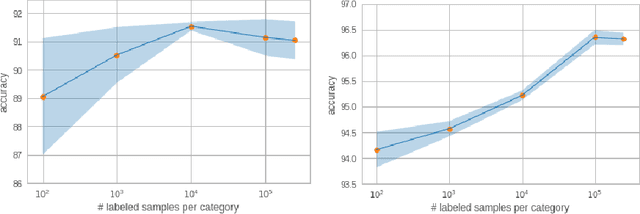
The scarcity of labeled training data often prohibits the internationalization of NLP models to multiple languages. Recent developments in cross-lingual understanding (XLU) has made progress in this area, trying to bridge the language barrier using language universal representations. However, even if the language problem was resolved, models trained in one language would not transfer to another language perfectly due to the natural domain drift across languages and cultures. We consider the setting of semi-supervised cross-lingual understanding, where labeled data is available in a source language (English), but only unlabeled data is available in the target language. We combine state-of-the-art cross-lingual methods with recently proposed methods for weakly supervised learning such as unsupervised pre-training and unsupervised data augmentation to simultaneously close both the language gap and the domain gap in XLU. We show that addressing the domain gap is crucial. We improve over strong baselines and achieve a new state-of-the-art for cross-lingual document classification.
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Jul 26, 2019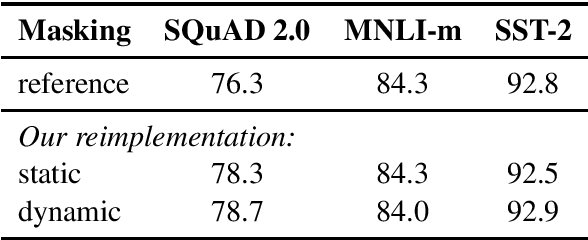
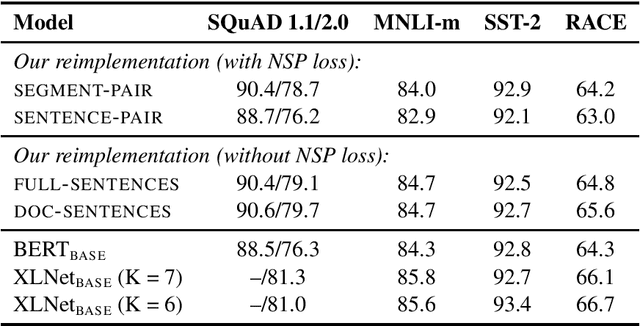
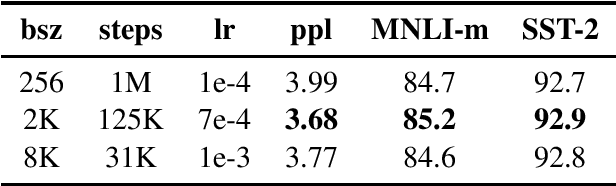
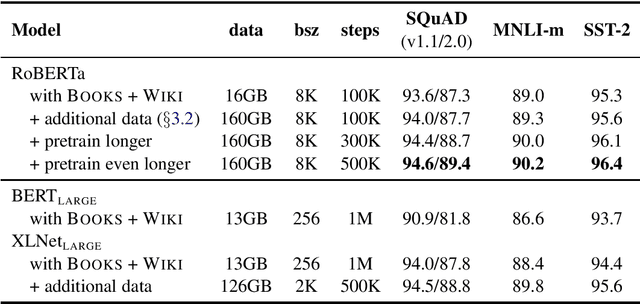
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
Knowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition
Apr 09, 2019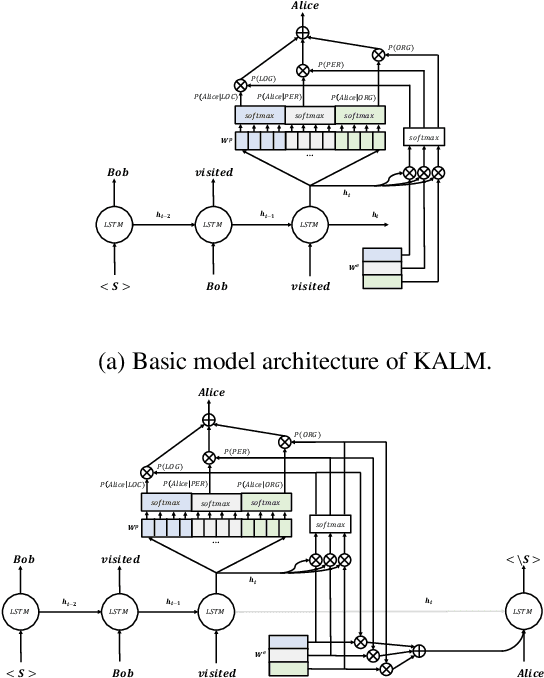
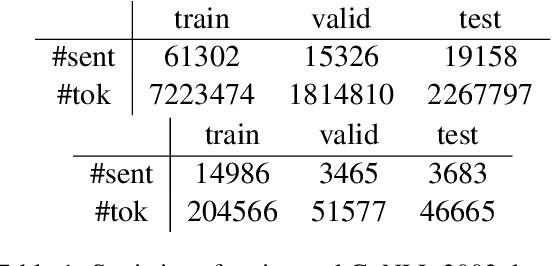
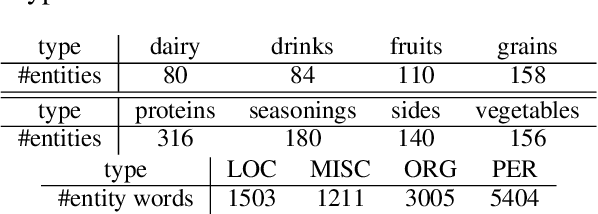
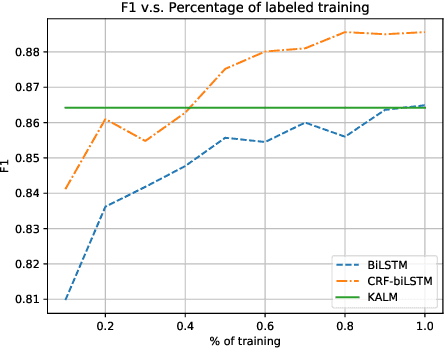
Traditional language models are unable to efficiently model entity names observed in text. All but the most popular named entities appear infrequently in text providing insufficient context. Recent efforts have recognized that context can be generalized between entity names that share the same type (e.g., \emph{person} or \emph{location}) and have equipped language models with access to an external knowledge base (KB). Our Knowledge-Augmented Language Model (KALM) continues this line of work by augmenting a traditional model with a KB. Unlike previous methods, however, we train with an end-to-end predictive objective optimizing the perplexity of text. We do not require any additional information such as named entity tags. In addition to improving language modeling performance, KALM learns to recognize named entities in an entirely unsupervised way by using entity type information latent in the model. On a Named Entity Recognition (NER) task, KALM achieves performance comparable with state-of-the-art supervised models. Our work demonstrates that named entities (and possibly other types of world knowledge) can be modeled successfully using predictive learning and training on large corpora of text without any additional information.
XNLI: Evaluating Cross-lingual Sentence Representations
Sep 13, 2018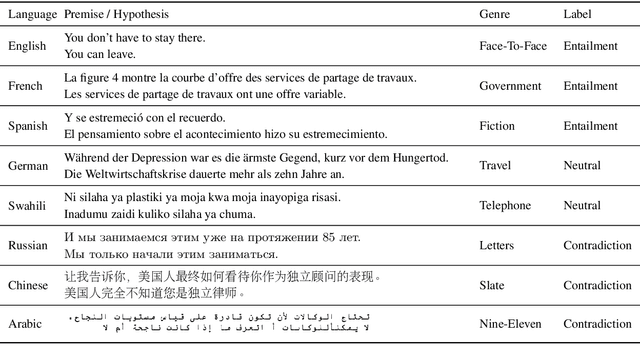
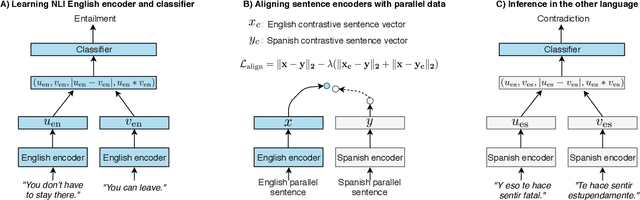

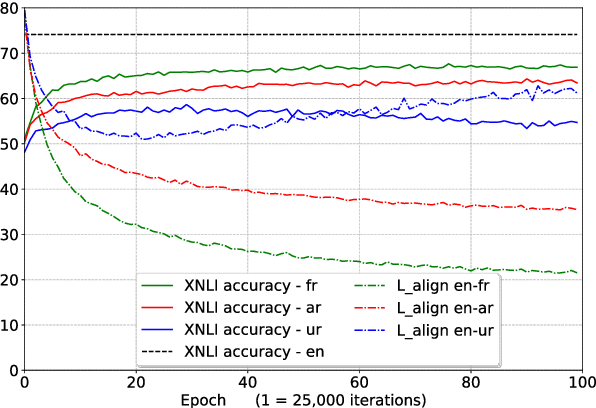
State-of-the-art natural language processing systems rely on supervision in the form of annotated data to learn competent models. These models are generally trained on data in a single language (usually English), and cannot be directly used beyond that language. Since collecting data in every language is not realistic, there has been a growing interest in cross-lingual language understanding (XLU) and low-resource cross-language transfer. In this work, we construct an evaluation set for XLU by extending the development and test sets of the Multi-Genre Natural Language Inference Corpus (MultiNLI) to 15 languages, including low-resource languages such as Swahili and Urdu. We hope that our dataset, dubbed XNLI, will catalyze research in cross-lingual sentence understanding by providing an informative standard evaluation task. In addition, we provide several baselines for multilingual sentence understanding, including two based on machine translation systems, and two that use parallel data to train aligned multilingual bag-of-words and LSTM encoders. We find that XNLI represents a practical and challenging evaluation suite, and that directly translating the test data yields the best performance among available baselines.