 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVamsi Krishna Ithapu
Egocentric Deep Multi-Channel Audio-Visual Active Speaker Localization
Jan 06, 2022

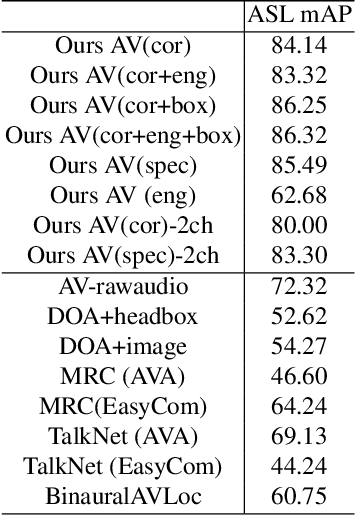
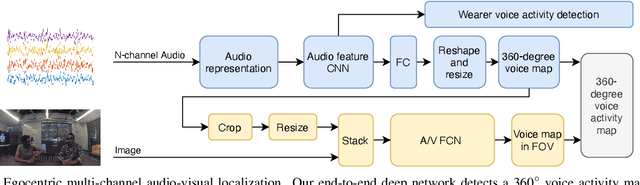
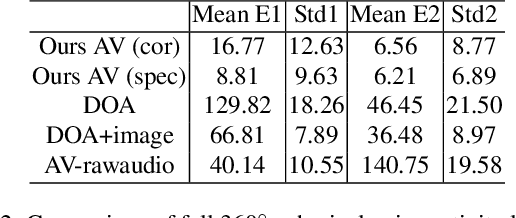
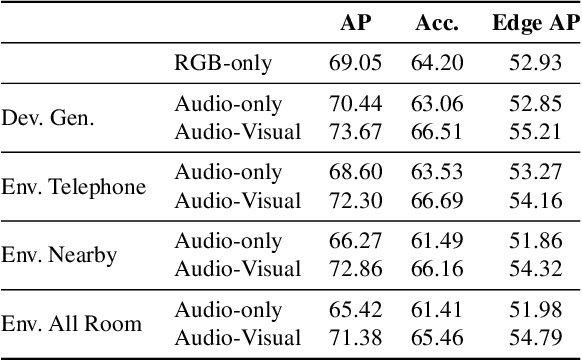
Augmented reality devices have the potential to enhance human perception and enable other assistive functionalities in complex conversational environments. Effectively capturing the audio-visual context necessary for understanding these social interactions first requires detecting and localizing the voice activities of the device wearer and the surrounding people. These tasks are challenging due to their egocentric nature: the wearer's head motion may cause motion blur, surrounding people may appear in difficult viewing angles, and there may be occlusions, visual clutter, audio noise, and bad lighting. Under these conditions, previous state-of-the-art active speaker detection methods do not give satisfactory results. Instead, we tackle the problem from a new setting using both video and multi-channel microphone array audio. We propose a novel end-to-end deep learning approach that is able to give robust voice activity detection and localization results. In contrast to previous methods, our method localizes active speakers from all possible directions on the sphere, even outside the camera's field of view, while simultaneously detecting the device wearer's own voice activity. Our experiments show that the proposed method gives superior results, can run in real time, and is robust against noise and clutter.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Filtered Noise Shaping for Time Domain Room Impulse Response Estimation From Reverberant Speech
Jul 15, 2021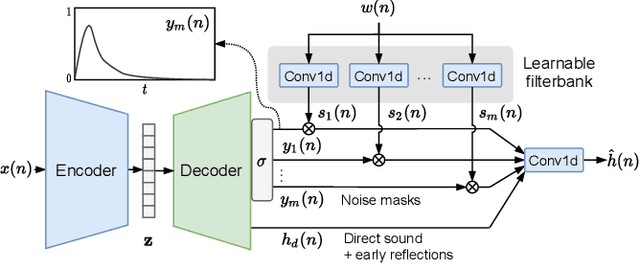
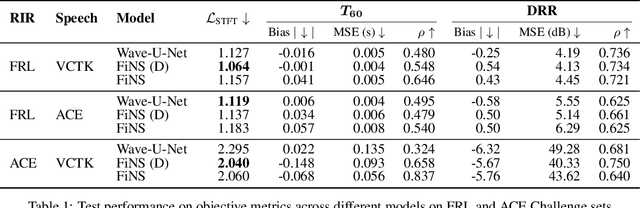
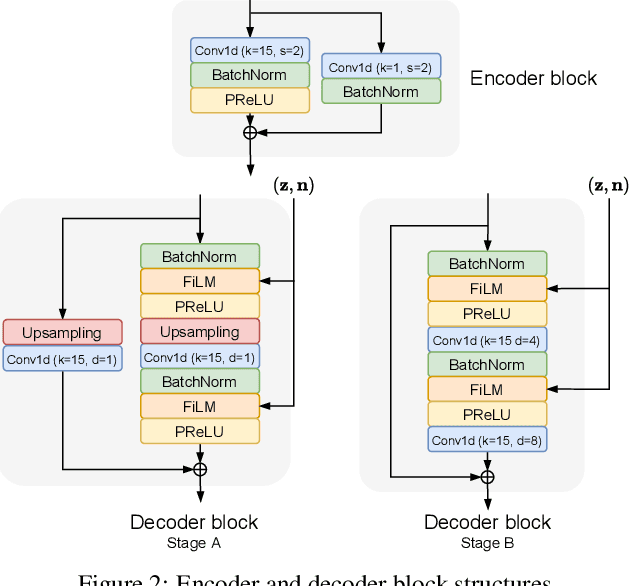
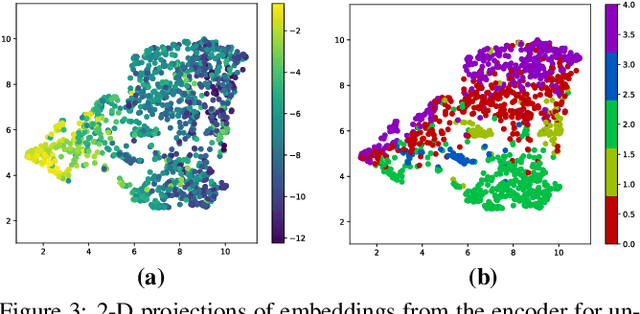
Deep learning approaches have emerged that aim to transform an audio signal so that it sounds as if it was recorded in the same room as a reference recording, with applications both in audio post-production and augmented reality. In this work, we propose FiNS, a Filtered Noise Shaping network that directly estimates the time domain room impulse response (RIR) from reverberant speech. Our domain-inspired architecture features a time domain encoder and a filtered noise shaping decoder that models the RIR as a summation of decaying filtered noise signals, along with direct sound and early reflection components. Previous methods for acoustic matching utilize either large models to transform audio to match the target room or predict parameters for algorithmic reverberators. Instead, blind estimation of the RIR enables efficient and realistic transformation with a single convolution. An evaluation demonstrates our model not only synthesizes RIRs that match parameters of the target room, such as the $T_{60}$ and DRR, but also more accurately reproduces perceptual characteristics of the target room, as shown in a listening test when compared to deep learning baselines.
EasyCom: An Augmented Reality Dataset to Support Algorithms for Easy Communication in Noisy Environments
Jul 09, 2021

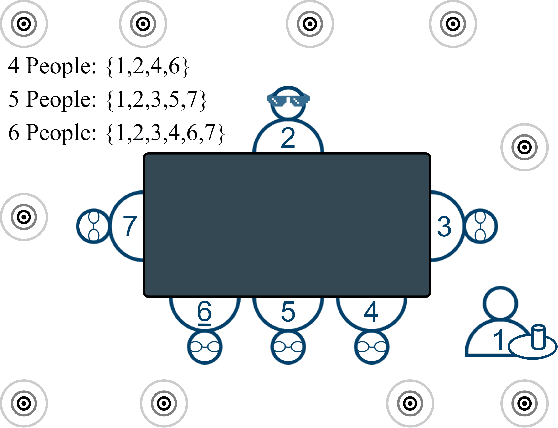
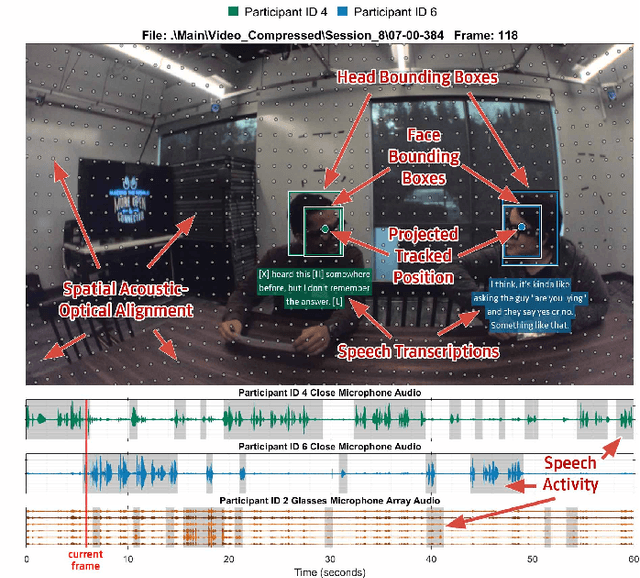
Augmented Reality (AR) as a platform has the potential to facilitate the reduction of the cocktail party effect. Future AR headsets could potentially leverage information from an array of sensors spanning many different modalities. Training and testing signal processing and machine learning algorithms on tasks such as beam-forming and speech enhancement require high quality representative data. To the best of the author's knowledge, as of publication there are no available datasets that contain synchronized egocentric multi-channel audio and video with dynamic movement and conversations in a noisy environment. In this work, we describe, evaluate and release a dataset that contains over 5 hours of multi-modal data useful for training and testing algorithms for the application of improving conversations for an AR glasses wearer. We provide speech intelligibility, quality and signal-to-noise ratio improvement results for a baseline method and show improvements across all tested metrics. The dataset we are releasing contains AR glasses egocentric multi-channel microphone array audio, wide field-of-view RGB video, speech source pose, headset microphone audio, annotated voice activity, speech transcriptions, head bounding boxes, target of speech and source identification labels. We have created and are releasing this dataset to facilitate research in multi-modal AR solutions to the cocktail party problem.
Do sound event representations generalize to other audio tasks? A case study in audio transfer learning
Jun 21, 2021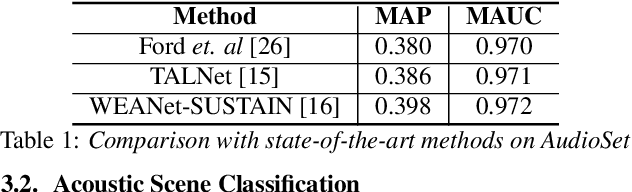
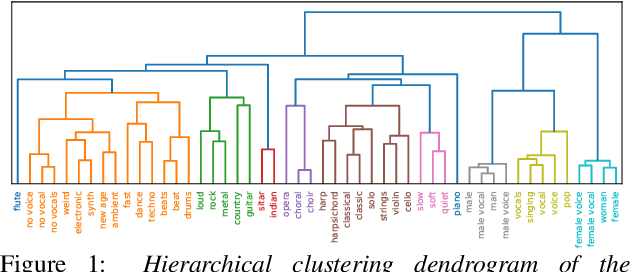
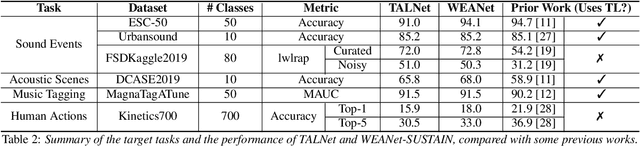
Transfer learning is critical for efficient information transfer across multiple related learning problems. A simple, yet effective transfer learning approach utilizes deep neural networks trained on a large-scale task for feature extraction. Such representations are then used to learn related downstream tasks. In this paper, we investigate transfer learning capacity of audio representations obtained from neural networks trained on a large-scale sound event detection dataset. We build and evaluate these representations across a wide range of other audio tasks, via a simple linear classifier transfer mechanism. We show that such simple linear transfer is already powerful enough to achieve high performance on the downstream tasks. We also provide insights into the attributes of sound event representations that enable such efficient information transfer.
Egocentric Pose Estimation from Human Vision Span
Apr 12, 2021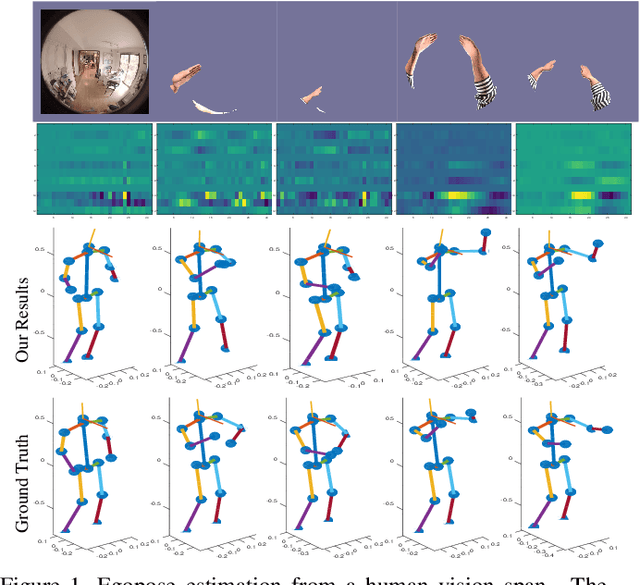
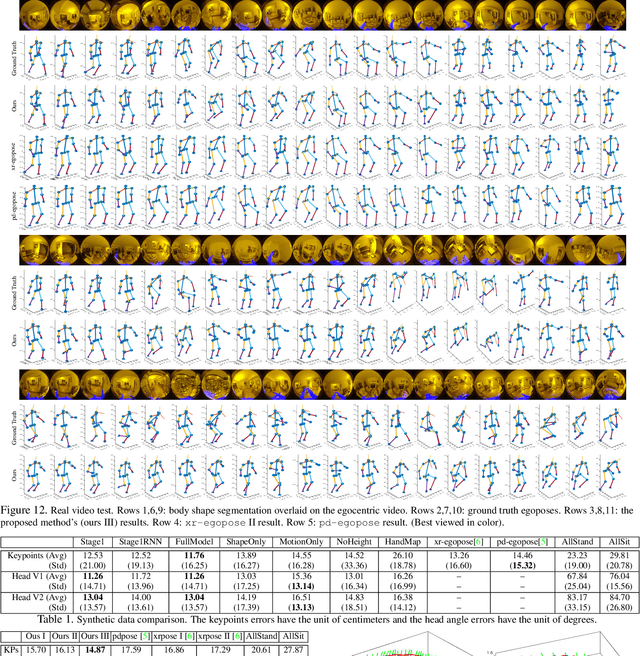
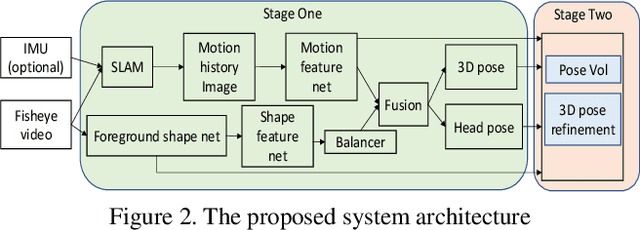
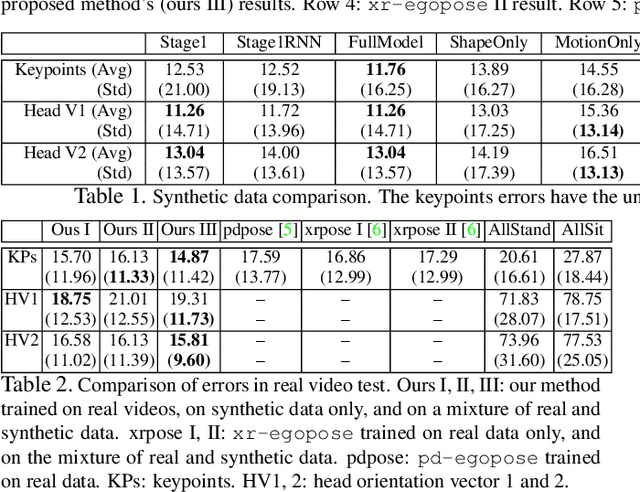
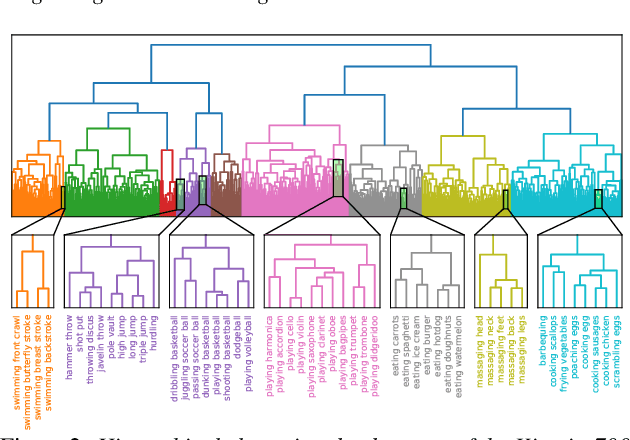
Estimating camera wearer's body pose from an egocentric view (egopose) is a vital task in augmented and virtual reality. Existing approaches either use a narrow field of view front facing camera that barely captures the wearer, or an extruded head-mounted top-down camera for maximal wearer visibility. In this paper, we tackle the egopose estimation from a more natural human vision span, where camera wearer can be seen in the peripheral view and depending on the head pose the wearer may become invisible or has a limited partial view. This is a realistic visual field for user-centric wearable devices like glasses which have front facing wide angle cameras. Existing solutions are not appropriate for this setting, and so, we propose a novel deep learning system taking advantage of both the dynamic features from camera SLAM and the body shape imagery. We compute 3D head pose, 3D body pose, the figure/ground separation, all at the same time while explicitly enforcing a certain geometric consistency across pose attributes. We further show that this system can be trained robustly with lots of existing mocap data so we do not have to collect and annotate large new datasets. Lastly, our system estimates egopose in real time and on the fly while maintaining high accuracy.
Audio-Visual Floorplan Reconstruction
Dec 31, 2020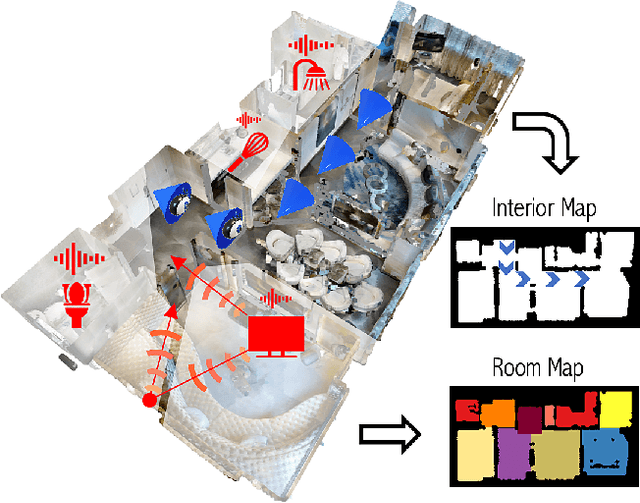
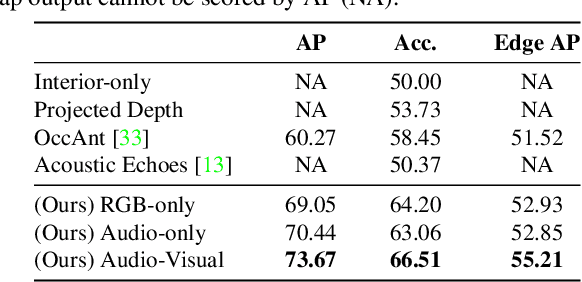
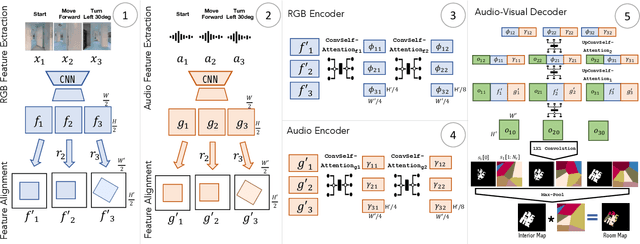
Given only a few glimpses of an environment, how much can we infer about its entire floorplan? Existing methods can map only what is visible or immediately apparent from context, and thus require substantial movements through a space to fully map it. We explore how both audio and visual sensing together can provide rapid floorplan reconstruction from limited viewpoints. Audio not only helps sense geometry outside the camera's field of view, but it also reveals the existence of distant freespace (e.g., a dog barking in another room) and suggests the presence of rooms not visible to the camera (e.g., a dishwasher humming in what must be the kitchen to the left). We introduce AV-Map, a novel multi-modal encoder-decoder framework that reasons jointly about audio and vision to reconstruct a floorplan from a short input video sequence. We train our model to predict both the interior structure of the environment and the associated rooms' semantic labels. Our results on 85 large real-world environments show the impact: with just a few glimpses spanning 26% of an area, we can estimate the whole area with 66% accuracy -- substantially better than the state of the art approach for extrapolating visual maps.
A Sequential Self Teaching Approach for Improving Generalization in Sound Event Recognition
Jun 30, 2020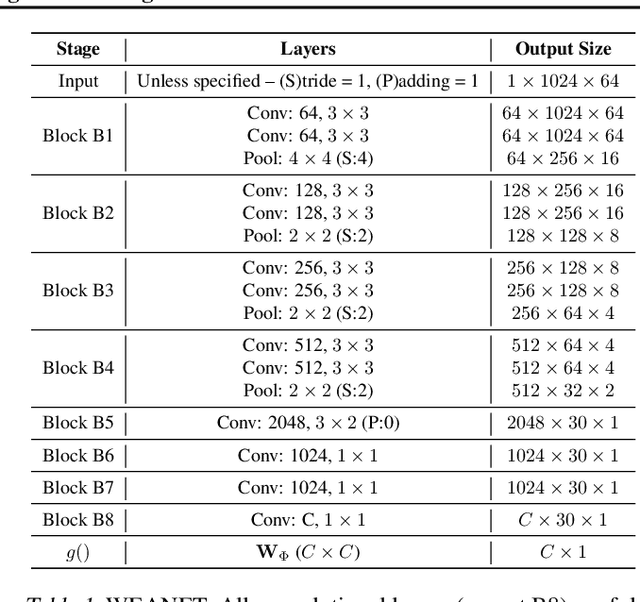
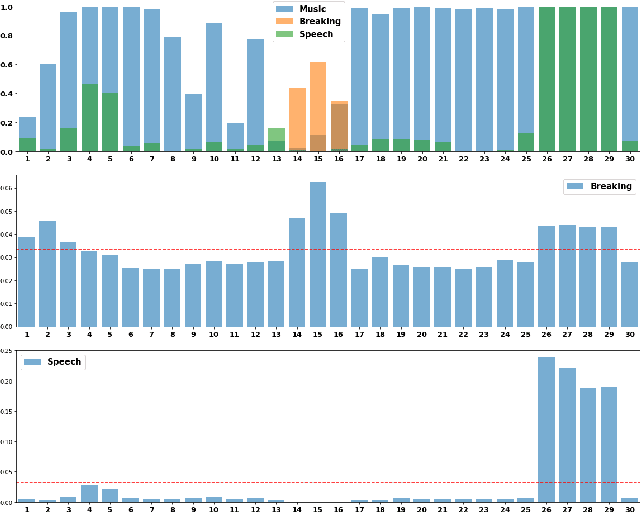
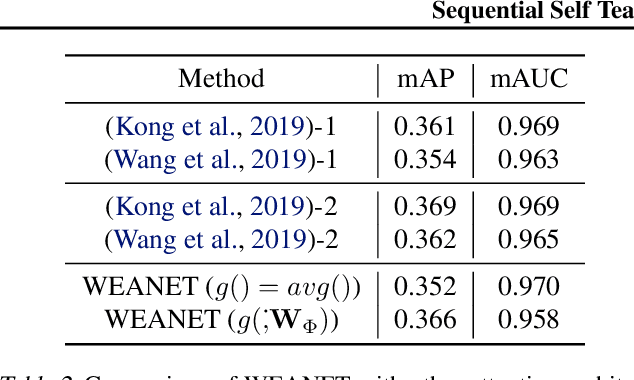
An important problem in machine auditory perception is to recognize and detect sound events. In this paper, we propose a sequential self-teaching approach to learning sounds. Our main proposition is that it is harder to learn sounds in adverse situations such as from weakly labeled and/or noisy labeled data, and in these situations a single stage of learning is not sufficient. Our proposal is a sequential stage-wise learning process that improves generalization capabilities of a given modeling system. We justify this method via technical results and on Audioset, the largest sound events dataset, our sequential learning approach can lead to up to 9% improvement in performance. A comprehensive evaluation also shows that the method leads to improved transferability of knowledge from previously trained models, thereby leading to improved generalization capabilities on transfer learning tasks.
Audio-Visual Embodied Navigation
Dec 24, 2019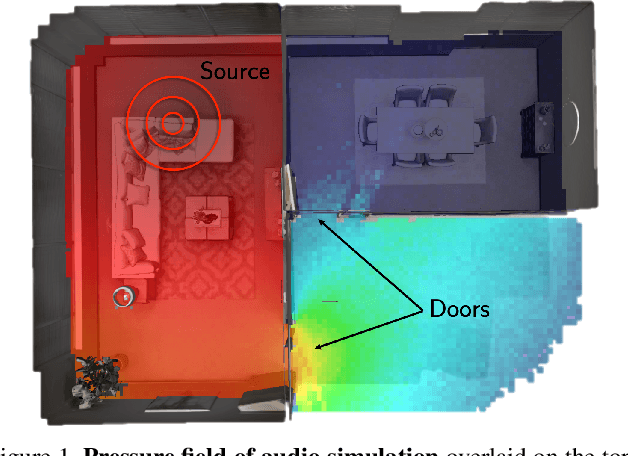
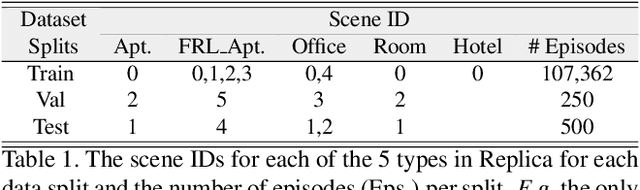


Moving around in the world is naturally a multisensory experience, but today's embodied agents are deaf - restricted to solely their visual perception of the environment. We introduce audio-visual navigation for complex, acoustically and visually realistic 3D environments. By both seeing and hearing, the agent must learn to navigate to an audio-based target. We develop a multi-modal deep reinforcement learning pipeline to train navigation policies end-to-end from a stream of egocentric audio-visual observations, allowing the agent to (1) discover elements of the geometry of the physical space indicated by the reverberating audio and (2) detect and follow sound-emitting targets. We further introduce audio renderings based on geometrical acoustic simulations for a set of publicly available 3D assets and instrument AI-Habitat to support the new sensor, making it possible to insert arbitrary sound sources in an array of apartment, office, and hotel environments. Our results show that audio greatly benefits embodied visual navigation in 3D spaces.
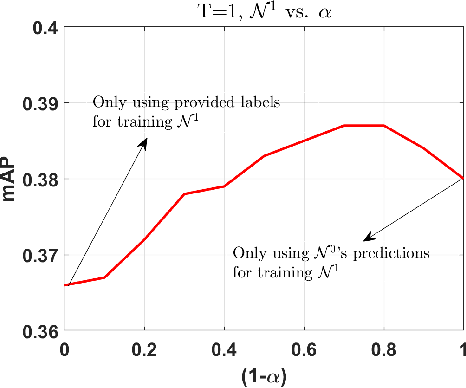
SeCoST: Sequential Co-Supervision for Weakly Labeled Audio Event Detection
Oct 25, 2019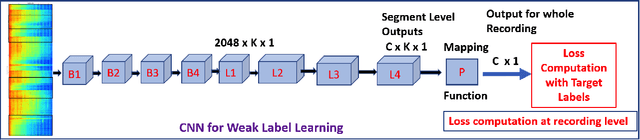
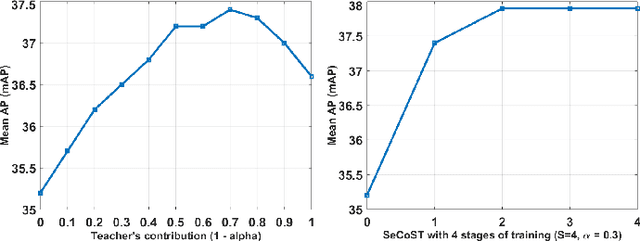
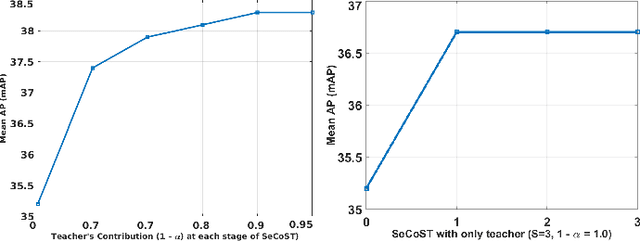
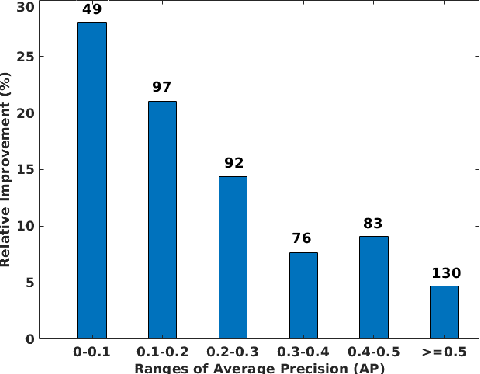
Weakly supervised learning algorithms are critical for scaling audio event detection to several hundreds of sound categories. Such learning models should not only disambiguate sound events efficiently with minimal class-specific annotation but also be robust to label noise, which is more apparent with weak labels instead of strong annotations. In this work, we propose a new framework for designing learning models with weak supervision by bridging ideas from sequential learning and knowledge distillation. We refer to the proposed methodology as SeCoST (pronounced Sequest) --- Sequential Co-supervision for training generations of Students. SeCoST incrementally builds a cascade of student-teacher pairs via a novel knowledge transfer method. Our evaluations on Audioset (the largest weakly labeled dataset available) show that SeCoST achieves a mean average precision of 0.383 while outperforming prior state of the art by a considerable margin.