 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVahab Mirrokni
Scalable Differentially Private Clustering via Hierarchically Separated Trees
Jun 17, 2022
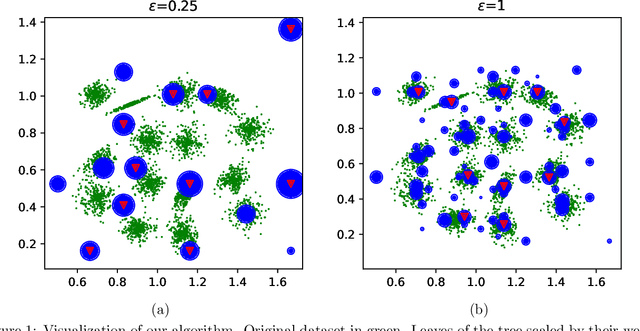
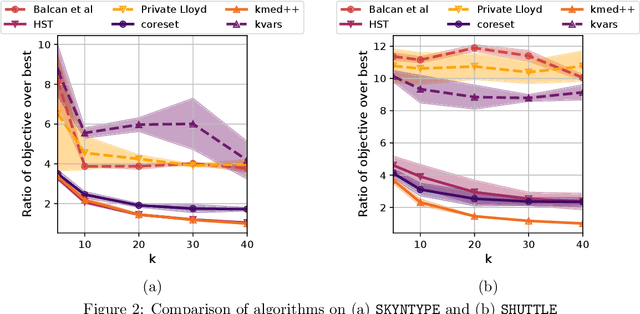
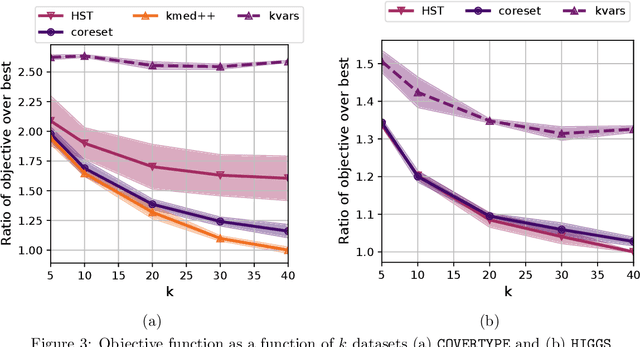
We study the private $k$-median and $k$-means clustering problem in $d$ dimensional Euclidean space. By leveraging tree embeddings, we give an efficient and easy to implement algorithm, that is empirically competitive with state of the art non private methods. We prove that our method computes a solution with cost at most $O(d^{3/2}\log n)\cdot OPT + O(k d^2 \log^2 n / \epsilon^2)$, where $\epsilon$ is the privacy guarantee. (The dimension term, $d$, can be replaced with $O(\log k)$ using standard dimension reduction techniques.) Although the worst-case guarantee is worse than that of state of the art private clustering methods, the algorithm we propose is practical, runs in near-linear, $\tilde{O}(nkd)$, time and scales to tens of millions of points. We also show that our method is amenable to parallelization in large-scale distributed computing environments. In particular we show that our private algorithms can be implemented in logarithmic number of MPC rounds in the sublinear memory regime. Finally, we complement our theoretical analysis with an empirical evaluation demonstrating the algorithm's efficiency and accuracy in comparison to other privacy clustering baselines.
Tackling Provably Hard Representative Selection via Graph Neural Networks
May 20, 2022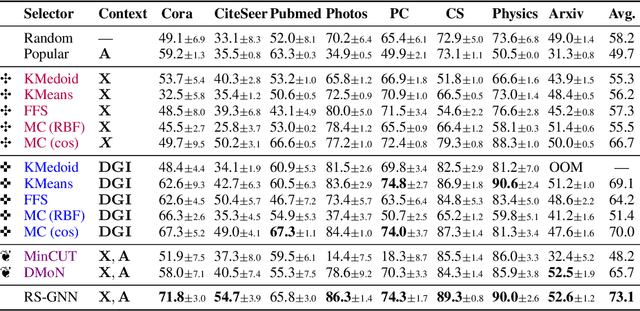
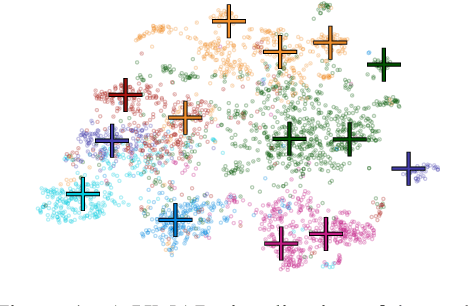
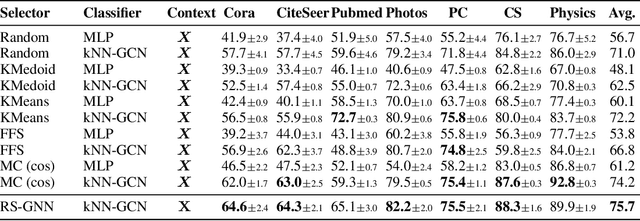
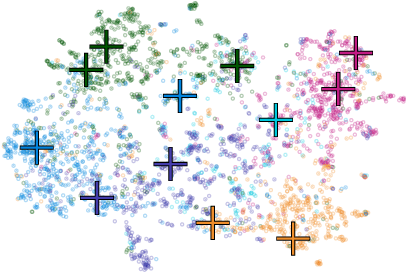
Representative selection (RS) is the problem of finding a small subset of exemplars from an unlabeled dataset, and has numerous applications in summarization, active learning, data compression and many other domains. In this paper, we focus on finding representatives that optimize the accuracy of a model trained on the selected representatives. We study RS for data represented as attributed graphs. We develop RS-GNN, a representation learning-based RS model based on Graph Neural Networks. Empirically, we demonstrate the effectiveness of RS-GNN on problems with predefined graph structures as well as problems with graphs induced from node feature similarities, by showing that RS-GNN achieves significant improvements over established baselines that optimize surrogate functions. Theoretically, we establish a new hardness result for RS by proving that RS is hard to approximate in polynomial time within any reasonable factor, which implies a significant gap between the optimum solution of widely-used surrogate functions and the actual accuracy of the model, and provides justification for the superiority of representation learning-based approaches such as RS-GNN over surrogate functions.
Improved Approximations for Euclidean $k$-means and $k$-median, via Nested Quasi-Independent Sets
Apr 12, 2022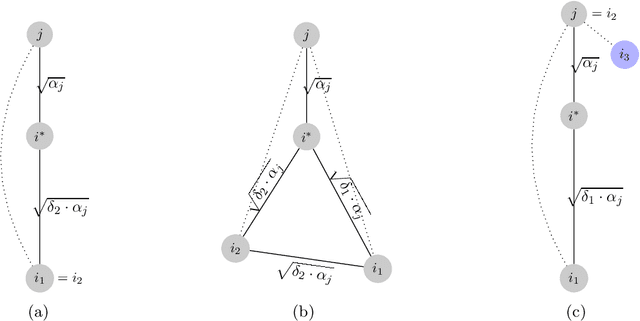
Motivated by data analysis and machine learning applications, we consider the popular high-dimensional Euclidean $k$-median and $k$-means problems. We propose a new primal-dual algorithm, inspired by the classic algorithm of Jain and Vazirani and the recent algorithm of Ahmadian, Norouzi-Fard, Svensson, and Ward. Our algorithm achieves an approximation ratio of $2.406$ and $5.912$ for Euclidean $k$-median and $k$-means, respectively, improving upon the 2.633 approximation ratio of Ahmadian et al. and the 6.1291 approximation ratio of Grandoni, Ostrovsky, Rabani, Schulman, and Venkat. Our techniques involve a much stronger exploitation of the Euclidean metric than previous work on Euclidean clustering. In addition, we introduce a new method of removing excess centers using a variant of independent sets over graphs that we dub a "nested quasi-independent set". In turn, this technique may be of interest for other optimization problems in Euclidean and $\ell_p$ metric spaces.
From Online Optimization to PID Controllers: Mirror Descent with Momentum
Feb 12, 2022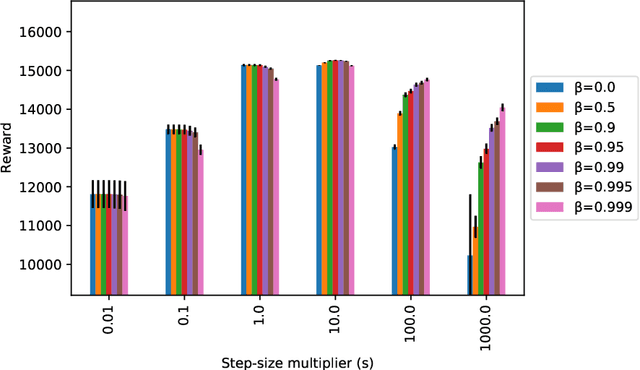
We study a family of first-order methods with momentum based on mirror descent for online convex optimization, which we dub online mirror descent with momentum (OMDM). Our algorithms include as special cases gradient descent and exponential weights update with momentum. We provide a new and simple analysis of momentum-based methods in a stochastic setting that yields a regret bound that decreases as momentum increases. This immediately establishes that momentum can help in the convergence of stochastic subgradient descent in convex nonsmooth optimization. We showcase the robustness of our algorithm by also providing an analysis in an adversarial setting that gives the first non-trivial regret bounds for OMDM. Our work aims to provide a better understanding of the benefits of momentum-based methods, which despite their recent empirical success, is incomplete. Finally, we discuss how OMDM can be applied to stochastic online allocation problems, which are central problems in computer science and operations research. In doing so, we establish an important connection between OMDM and popular approaches from optimal control such as PID controllers, thereby providing regret bounds on the performance of PID controllers. The improvements of momentum are most pronounced when the step-size is large, thereby indicating that momentum provides a robustness to misspecification of tuning parameters. We provide a numerical evaluation that verifies the robustness of our algorithms.
Synthetic Design: An Optimization Approach to Experimental Design with Synthetic Controls
Dec 01, 2021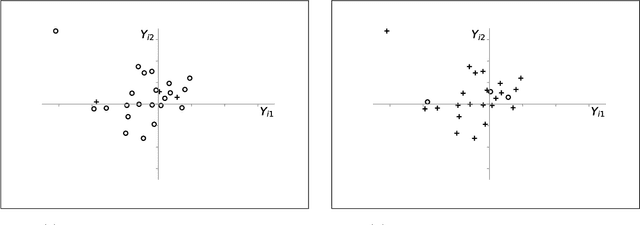
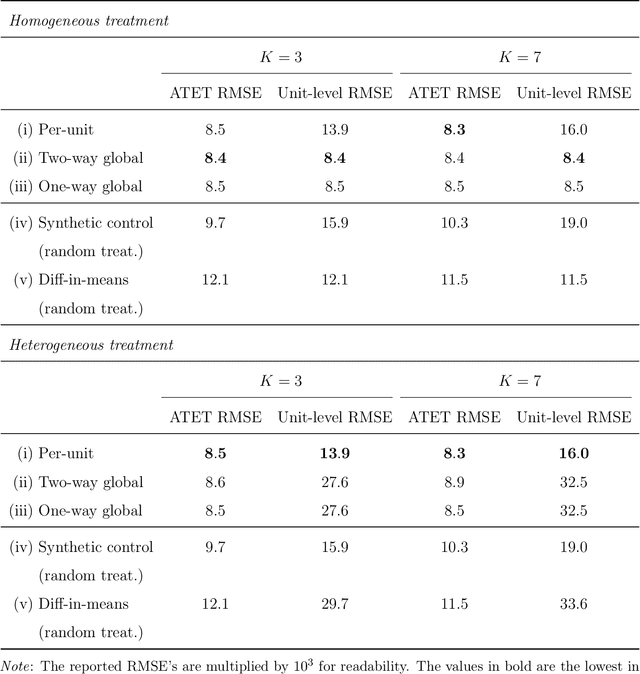
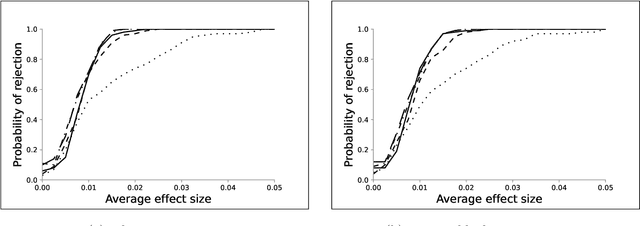
We investigate the optimal design of experimental studies that have pre-treatment outcome data available. The average treatment effect is estimated as the difference between the weighted average outcomes of the treated and control units. A number of commonly used approaches fit this formulation, including the difference-in-means estimator and a variety of synthetic-control techniques. We propose several methods for choosing the set of treated units in conjunction with the weights. Observing the NP-hardness of the problem, we introduce a mixed-integer programming formulation which selects both the treatment and control sets and unit weightings. We prove that these proposed approaches lead to qualitatively different experimental units being selected for treatment. We use simulations based on publicly available data from the US Bureau of Labor Statistics that show improvements in terms of mean squared error and statistical power when compared to simple and commonly used alternatives such as randomized trials.
Tight and Robust Private Mean Estimation with Few Users
Oct 22, 2021


In this work, we study high-dimensional mean estimation under user-level differential privacy, and attempt to design an $(\epsilon,\delta)$-differentially private mechanism using as few users as possible. In particular, we provide a nearly optimal trade-off between the number of users and the number of samples per user required for private mean estimation, even when the number of users is as low as $O(\frac{1}{\epsilon}\log\frac{1}{\delta})$. Interestingly our bound $O(\frac{1}{\epsilon}\log\frac{1}{\delta})$ on the number of users is independent of the dimension, unlike the previous work that depends polynomially on the dimension, solving a problem left open by Amin et al.~(ICML'2019). Our mechanism enjoys robustness up to the point that even if the information of $49\%$ of the users are corrupted, our final estimation is still approximately accurate. Finally, our results also apply to a broader range of problems such as learning discrete distributions, stochastic convex optimization, empirical risk minimization, and a variant of stochastic gradient descent via a reduction to differentially private mean estimation.
Label differential privacy via clustering
Oct 05, 2021
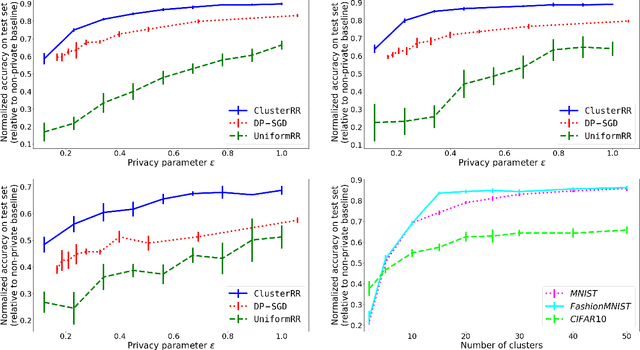
We present new mechanisms for \emph{label differential privacy}, a relaxation of differentially private machine learning that only protects the privacy of the labels in the training set. Our mechanisms cluster the examples in the training set using their (non-private) feature vectors, randomly re-sample each label from examples in the same cluster, and output a training set with noisy labels as well as a modified version of the true loss function. We prove that when the clusters are both large and high-quality, the model that minimizes the modified loss on the noisy training set converges to small excess risk at a rate that is comparable to the rate for non-private learning. We describe both a centralized mechanism in which the entire training set is stored by a trusted curator, and a distributed mechanism where each user stores a single labeled example and replaces her label with the label of a randomly selected user from the same cluster. We also describe a learning problem in which large clusters are necessary to achieve both strong privacy and either good precision or good recall. Our experiments show that randomizing the labels within each cluster significantly improves the privacy vs. accuracy trade-off compared to applying uniform randomized response to the labels, and also compared to learning a model via DP-SGD.
Scalable Community Detection via Parallel Correlation Clustering
Jul 27, 2021
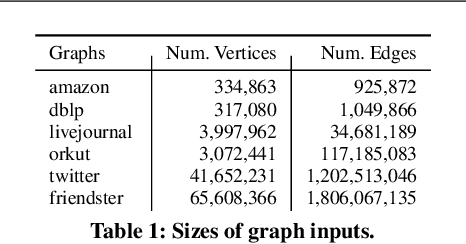
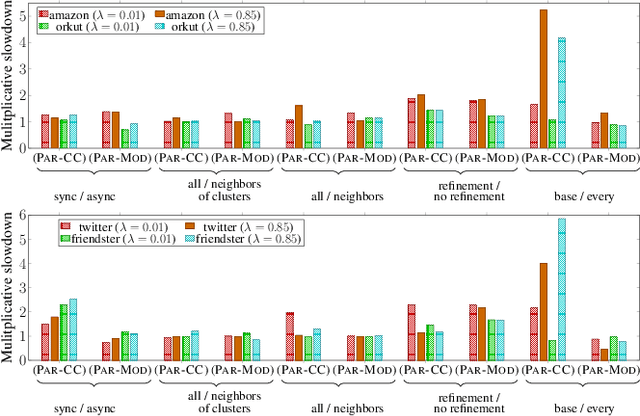
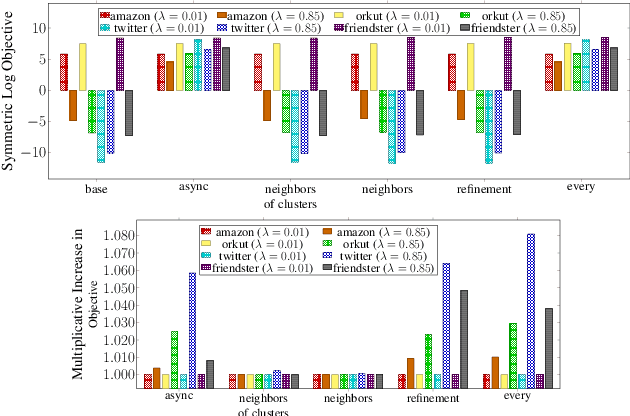
Graph clustering and community detection are central problems in modern data mining. The increasing need for analyzing billion-scale data calls for faster and more scalable algorithms for these problems. There are certain trade-offs between the quality and speed of such clustering algorithms. In this paper, we design scalable algorithms that achieve high quality when evaluated based on ground truth. We develop a generalized sequential and shared-memory parallel framework based on the LambdaCC objective (introduced by Veldt et al.), which encompasses modularity and correlation clustering. Our framework consists of highly-optimized implementations that scale to large data sets of billions of edges and that obtain high-quality clusters compared to ground-truth data, on both unweighted and weighted graphs. Our empirical evaluation shows that this framework improves the state-of-the-art trade-offs between speed and quality of scalable community detection. For example, on a 30-core machine with two-way hyper-threading, our implementations achieve orders of magnitude speedups over other correlation clustering baselines, and up to 28.44x speedups over our own sequential baselines while maintaining or improving quality.
Almost Tight Approximation Algorithms for Explainable Clustering
Jul 15, 2021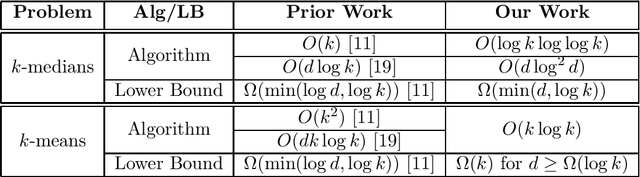



Recently, due to an increasing interest for transparency in artificial intelligence, several methods of explainable machine learning have been developed with the simultaneous goal of accuracy and interpretability by humans. In this paper, we study a recent framework of explainable clustering first suggested by Dasgupta et al.~\cite{dasgupta2020explainable}. Specifically, we focus on the $k$-means and $k$-medians problems and provide nearly tight upper and lower bounds. First, we provide an $O(\log k \log \log k)$-approximation algorithm for explainable $k$-medians, improving on the best known algorithm of $O(k)$~\cite{dasgupta2020explainable} and nearly matching the known $\Omega(\log k)$ lower bound~\cite{dasgupta2020explainable}. In addition, in low-dimensional spaces $d \ll \log k$, we show that our algorithm also provides an $O(d \log^2 d)$-approximate solution for explainable $k$-medians. This improves over the best known bound of $O(d \log k)$ for low dimensions~\cite{laber2021explainable}, and is a constant for constant dimensional spaces. To complement this, we show a nearly matching $\Omega(d)$ lower bound. Next, we study the $k$-means problem in this context and provide an $O(k \log k)$-approximation algorithm for explainable $k$-means, improving over the $O(k^2)$ bound of Dasgupta et al. and the $O(d k \log k)$ bound of \cite{laber2021explainable}. To complement this we provide an almost tight $\Omega(k)$ lower bound, improving over the $\Omega(\log k)$ lower bound of Dasgupta et al. Given an approximate solution to the classic $k$-means and $k$-medians, our algorithm for $k$-medians runs in time $O(kd \log^2 k )$ and our algorithm for $k$-means runs in time $ O(k^2 d)$.