 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Speech Recognition Using Template Model for Man-Machine Interface
May 09, 2013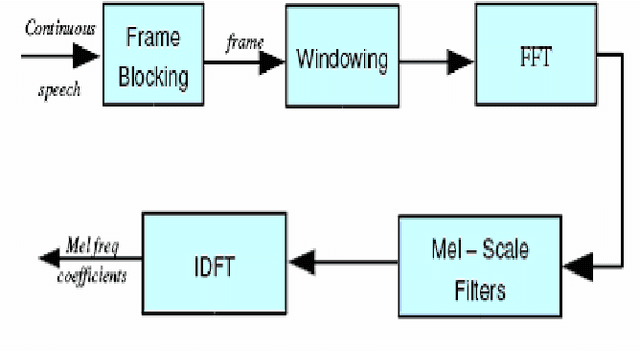
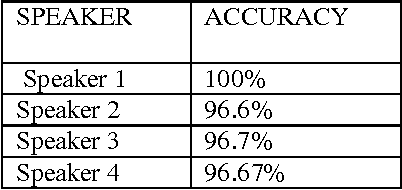
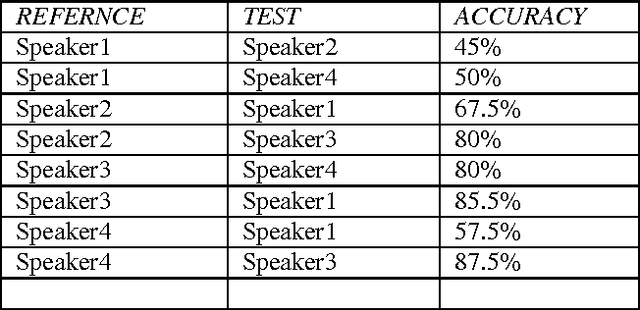
Speech is a natural form of communication for human beings, and computers with the ability to understand speech and speak with a human voice are expected to contribute to the development of more natural man-machine interfaces. Computers with this kind of ability are gradually becoming a reality, through the evolution of speech recognition technologies. Speech is being an important mode of interaction with computers. In this paper Feature extraction is implemented using well-known Mel-Frequency Cepstral Coefficients (MFCC).Pattern matching is done using Dynamic time warping (DTW) algorithm.
An Overview of Hindi Speech Recognition
May 09, 2013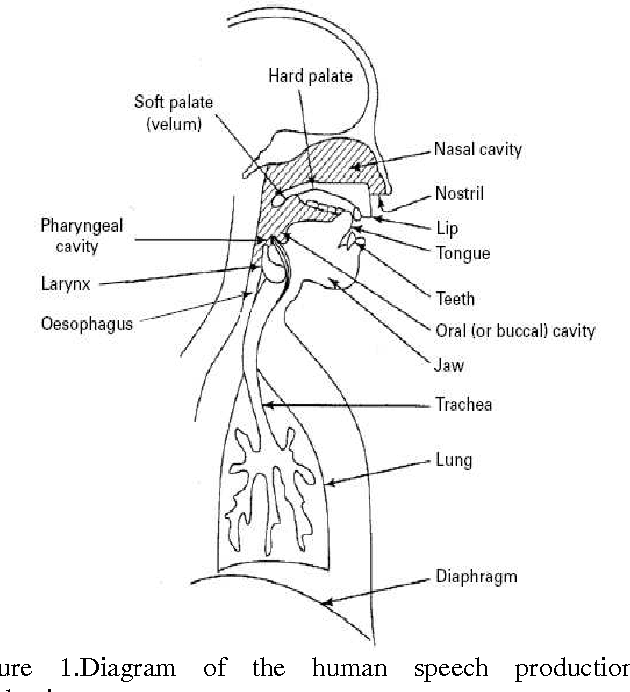

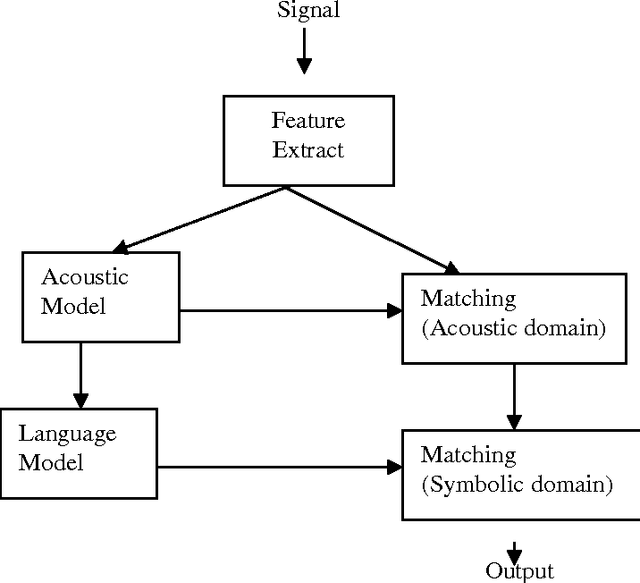
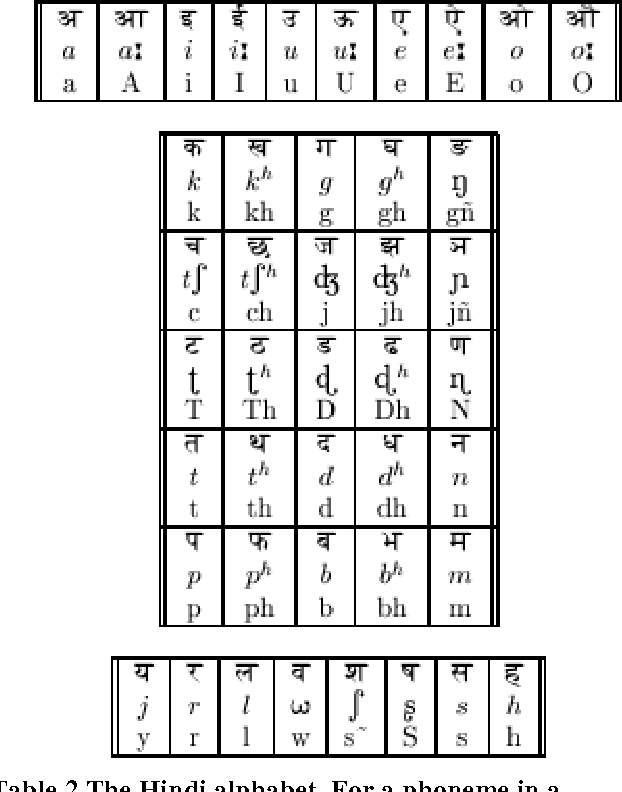
In this age of information technology, information access in a convenient manner has gained importance. Since speech is a primary mode of communication among human beings, it is natural for people to expect to be able to carry out spoken dialogue with computer. Speech recognition system permits ordinary people to speak to the computer to retrieve information. It is desirable to have a human computer dialogue in local language. Hindi being the most widely spoken Language in India is the natural primary human language candidate for human machine interaction. There are five pairs of vowels in Hindi languages; one member is longer than the other one. This paper describes an overview of speech recognition system that includes how speech is produced and the properties and characteristics of Hindi Phoneme.
Opportunities & Challenges In Automatic Speech Recognition
May 09, 2013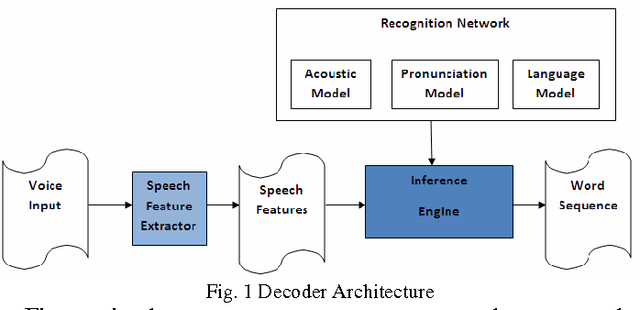
Automatic speech recognition enables a wide range of current and emerging applications such as automatic transcription, multimedia content analysis, and natural human-computer interfaces. This paper provides a glimpse of the opportunities and challenges that parallelism provides for automatic speech recognition and related application research from the point of view of speech researchers. The increasing parallelism in computing platforms opens three major possibilities for speech recognition systems: improving recognition accuracy in non-ideal, everyday noisy environments; increasing recognition throughput in batch processing of speech data; and reducing recognition latency in realtime usage scenarios. This paper describes technical challenges, approaches taken, and possible directions for future research to guide the design of efficient parallel software and hardware infrastructures.
Speech Enhancement Using Pitch Detection Approach For Noisy Environment
May 09, 2013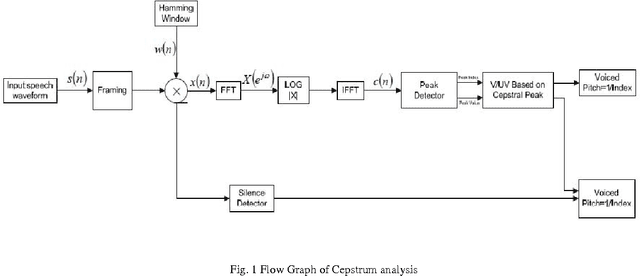
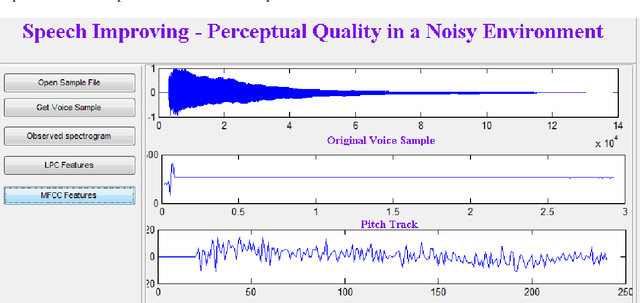
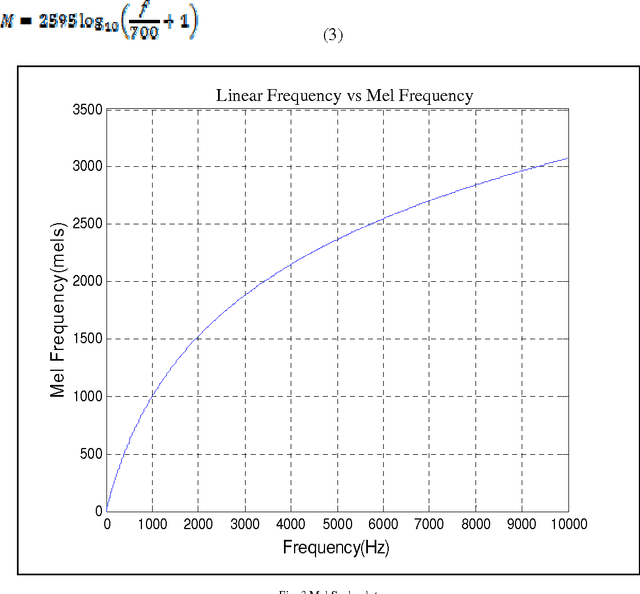
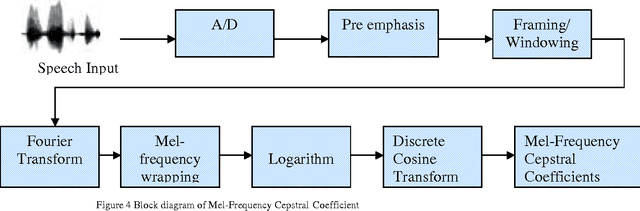
Acoustical mismatch among training and testing phases degrades outstandingly speech recognition results. This problem has limited the development of real-world nonspecific applications, as testing conditions are highly variant or even unpredictable during the training process. Therefore the background noise has to be removed from the noisy speech signal to increase the signal intelligibility and to reduce the listener fatigue. Enhancement techniques applied, as pre-processing stages; to the systems remarkably improve recognition results. In this paper, a novel approach is used to enhance the perceived quality of the speech signal when the additive noise cannot be directly controlled. Instead of controlling the background noise, we propose to reinforce the speech signal so that it can be heard more clearly in noisy environments. The subjective evaluation shows that the proposed method improves perceptual quality of speech in various noisy environments. As in some cases speaking may be more convenient than typing, even for rapid typists: many mathematical symbols are missing from the keyboard but can be easily spoken and recognized. Therefore, the proposed system can be used in an application designed for mathematical symbol recognition (especially symbols not available on the keyboard) in schools.
* Pages: 06 Figures : 05
Techniques for Feature Extraction In Speech Recognition System : A Comparative Study
May 06, 2013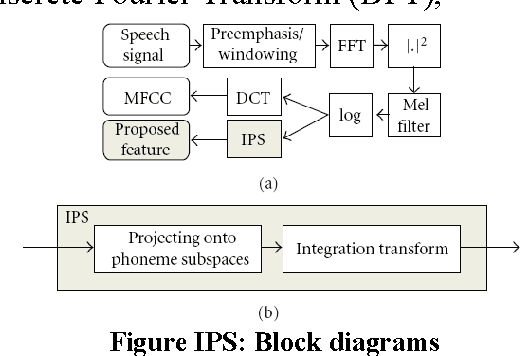
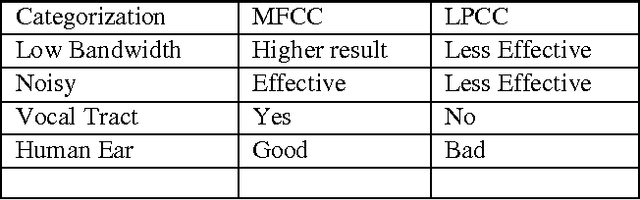
The time domain waveform of a speech signal carries all of the auditory information. From the phonological point of view, it little can be said on the basis of the waveform itself. However, past research in mathematics, acoustics, and speech technology have provided many methods for converting data that can be considered as information if interpreted correctly. In order to find some statistically relevant information from incoming data, it is important to have mechanisms for reducing the information of each segment in the audio signal into a relatively small number of parameters, or features. These features should describe each segment in such a characteristic way that other similar segments can be grouped together by comparing their features. There are enormous interesting and exceptional ways to describe the speech signal in terms of parameters. Though, they all have their strengths and weaknesses, we have presented some of the most used methods with their importance.
* Pages: 9 Figures : 3