 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recommender System for Scientific Datasets and Analysis Pipelines
Aug 20, 2021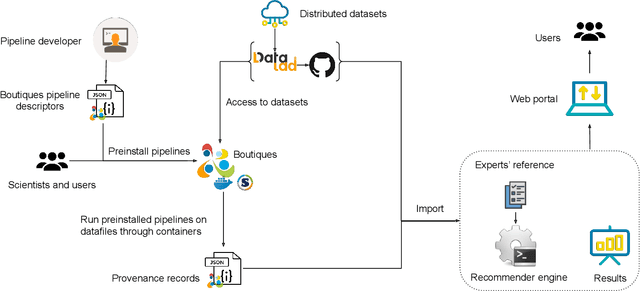
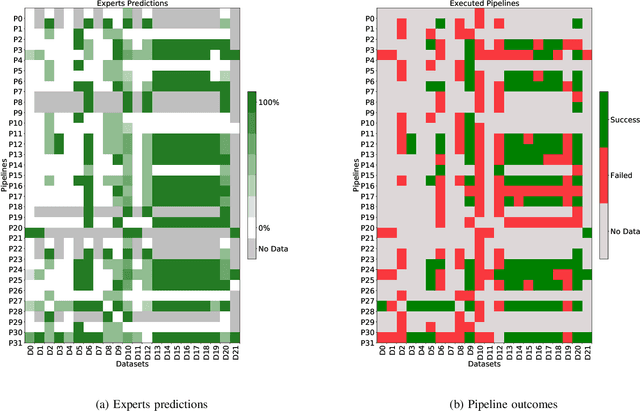
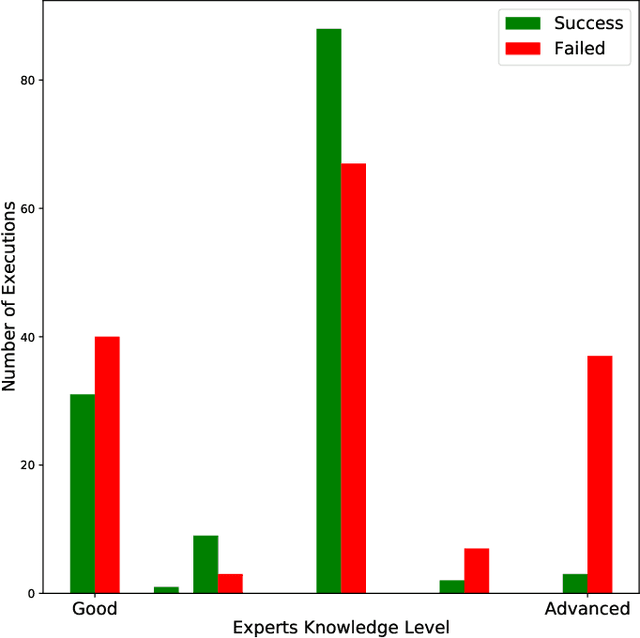
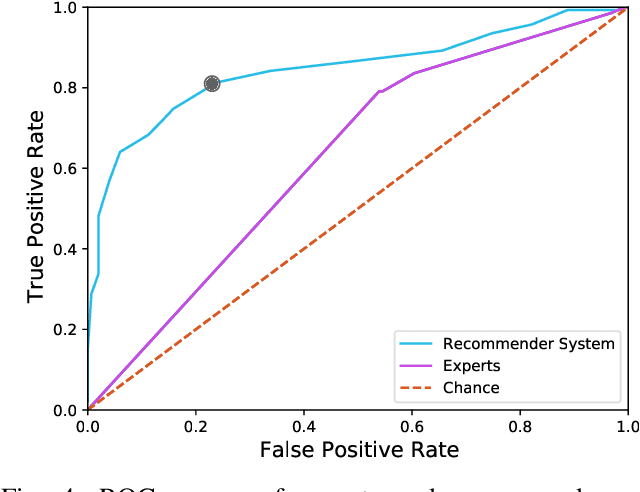
Scientific datasets and analysis pipelines are increasingly being shared publicly in the interest of open science. However, mechanisms are lacking to reliably identify which pipelines and datasets can appropriately be used together. Given the increasing number of high-quality public datasets and pipelines, this lack of clear compatibility threatens the findability and reusability of these resources. We investigate the feasibility of a collaborative filtering system to recommend pipelines and datasets based on provenance records from previous executions. We evaluate our system using datasets and pipelines extracted from the Canadian Open Neuroscience Platform, a national initiative for open neuroscience. The recommendations provided by our system (AUC$=0.83$) are significantly better than chance and outperform recommendations made by domain experts using their previous knowledge as well as pipeline and dataset descriptions (AUC$=0.63$). In particular, domain experts often neglect low-level technical aspects of a pipeline-dataset interaction, such as the level of pre-processing, which are captured by a provenance-based system. We conclude that provenance-based pipeline and dataset recommenders are feasible and beneficial to the sharing and usage of open-science resources. Future work will focus on the collection of more comprehensive provenance traces, and on deploying the system in production.
Accurate simulation of operating system updates in neuroimaging using Monte-Carlo arithmetic
Aug 06, 2021
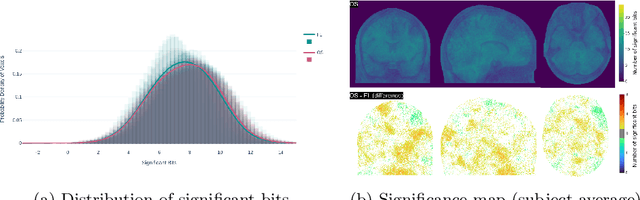
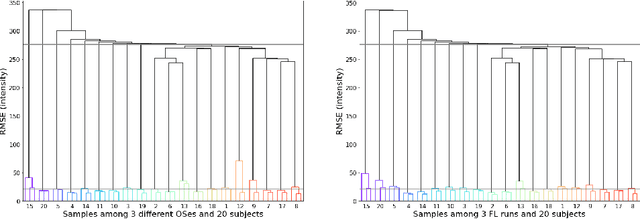
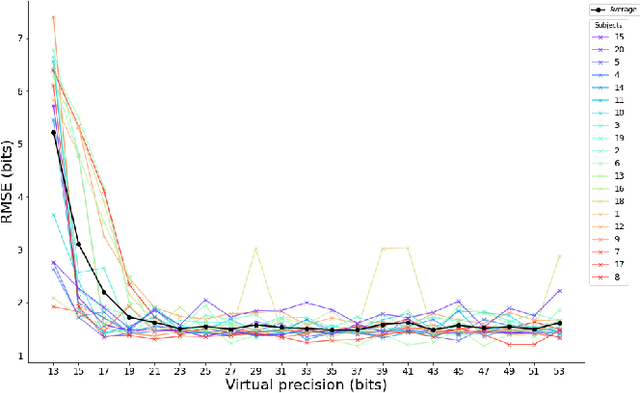
Operating system (OS) updates introduce numerical perturbations that impact the reproducibility of computational pipelines. In neuroimaging, this has important practical implications on the validity of computational results, particularly when obtained in systems such as high-performance computing clusters where the experimenter does not control software updates. We present a framework to reproduce the variability induced by OS updates in controlled conditions. We hypothesize that OS updates impact computational pipelines mainly through numerical perturbations originating in mathematical libraries, which we simulate using Monte-Carlo arithmetic in a framework called "fuzzy libmath" (FL). We applied this methodology to pre-processing pipelines of the Human Connectome Project, a flagship open-data project in neuroimaging. We found that FL-perturbed pipelines accurately reproduce the variability induced by OS updates and that this similarity is only mildly dependent on simulation parameters. Importantly, we also found between-subject differences were preserved in both cases, though the between-run variability was of comparable magnitude for both FL and OS perturbations. We found the numerical precision in the HCP pre-processed images to be relatively low, with less than 8 significant bits among the 24 available, which motivates further investigation of the numerical stability of components in the tested pipeline. Overall, our results establish that FL accurately simulates results variability due to OS updates, and is a practical framework to quantify numerical uncertainty in neuroimaging.
Reducing numerical precision preserves classification accuracy in Mondrian Forests
Jun 28, 2021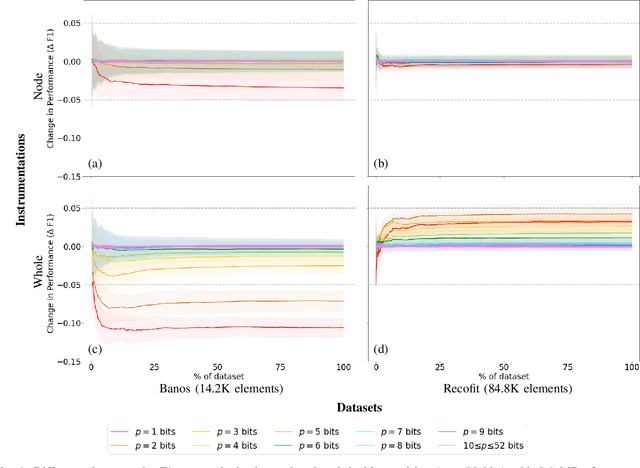
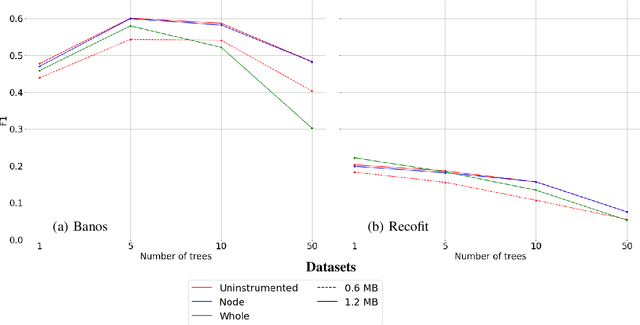

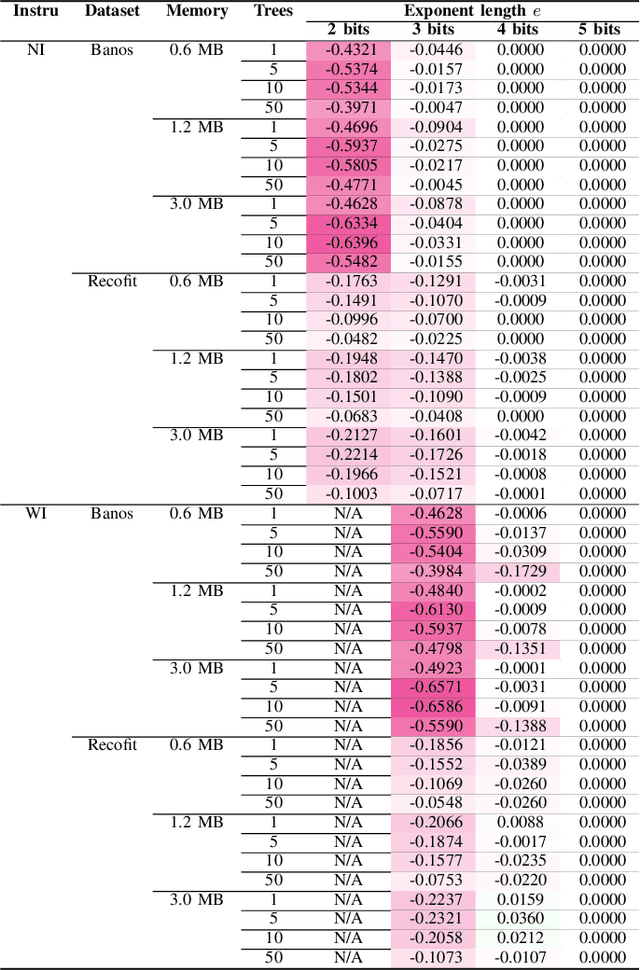
Mondrian Forests are a powerful data stream classification method, but their large memory footprint makes them ill-suited for low-resource platforms such as connected objects. We explored using reduced-precision floating-point representations to lower memory consumption and evaluated its effect on classification performance. We applied the Mondrian Forest implementation provided by OrpailleCC, a C++ collection of data stream algorithms, to two canonical datasets in human activity recognition: Recofit and Banos \emph{et al}. Results show that the precision of floating-point values used by tree nodes can be reduced from 64 bits to 8 bits with no significant difference in F1 score. In some cases, reduced precision was shown to improve classification performance, presumably due to its regularization effect. We conclude that numerical precision is a relevant hyperparameter in the Mondrian Forest, and that commonly-used double precision values may not be necessary for optimal performance. Future work will evaluate the generalizability of these findings to other data stream classifiers.
A benchmark of data stream classification for human activity recognition on connected objects
Aug 27, 2020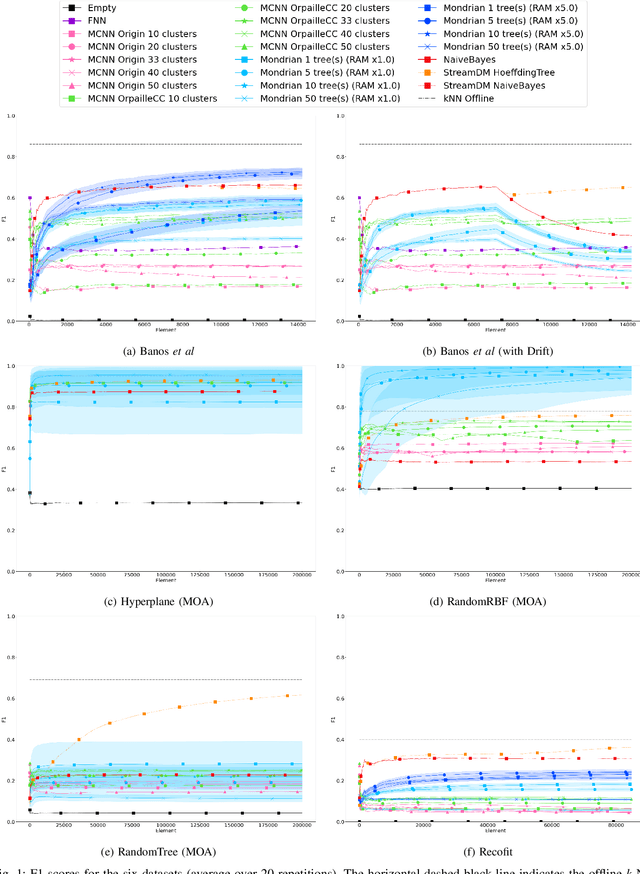
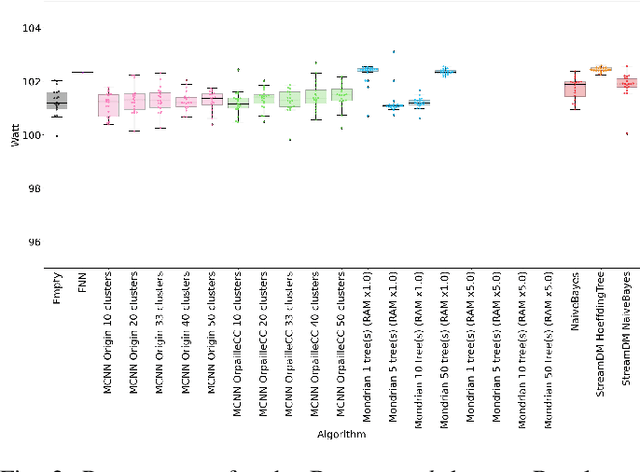
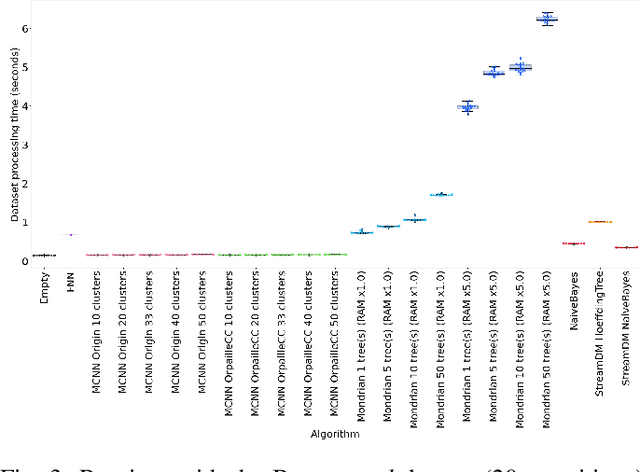
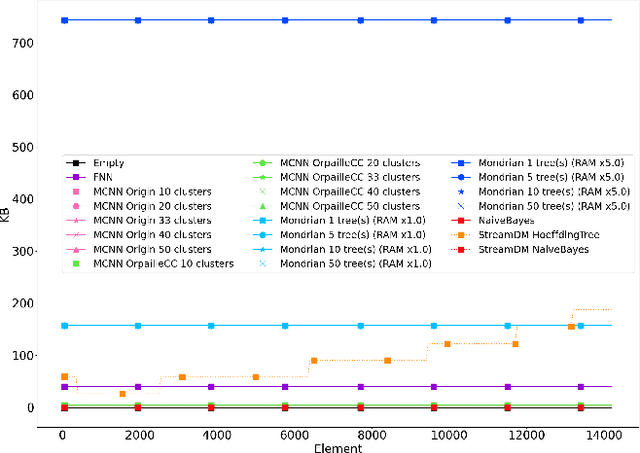
This paper evaluates data stream classifiers from the perspective of connected devices, focusing on the use case of HAR. We measure both classification performance and resource consumption (runtime, memory, and power) of five usual stream classification algorithms, implemented in a consistent library, and applied to two real human activity datasets and to three synthetic datasets. Regarding classification performance, results show an overall superiority of the HT, the MF, and the NB classifiers over the FNN and the Micro Cluster Nearest Neighbor (MCNN) classifiers on 4 datasets out of 6, including the real ones. In addition, the HT, and to some extent MCNN, are the only classifiers that can recover from a concept drift. Overall, the three leading classifiers still perform substantially lower than an offline classifier on the real datasets. Regarding resource consumption, the HT and the MF are the most memory intensive and have the longest runtime, however, no difference in power consumption is found between classifiers. We conclude that stream learning for HAR on connected objects is challenged by two factors which could lead to interesting future work: a high memory consumption and low F1 scores overall.
Can we Estimate Truck Accident Risk from Telemetric Data using Machine Learning?
Jul 17, 2020
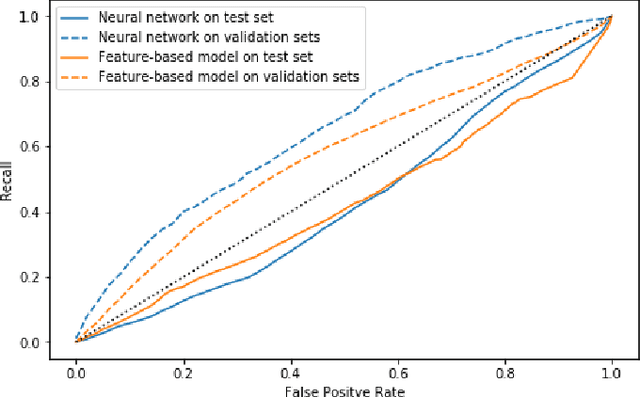
Road accidents have a high societal cost that could be reduced through improved risk predictions using machine learning. This study investigates whether telemetric data collected on long-distance trucks can be used to predict the risk of accidents associated with a driver. We use a dataset provided by a truck transportation company containing the driving data of 1,141 drivers for 18 months. We evaluate two different machine learning approaches to perform this task. In the first approach, features are extracted from the time series data using the FRESH algorithm and then used to estimate the risk using Random Forests. In the second approach, we use a convolutional neural network to directly estimate the risk from the time-series data. We find that neither approach is able to successfully estimate the risk of accidents on this dataset, in spite of many methodological attempts. We discuss the difficulties of using telemetric data for the estimation of the risk of accidents that could explain this negative result.
High-Resolution Road Vehicle Collision Prediction for the City of Montreal
May 21, 2019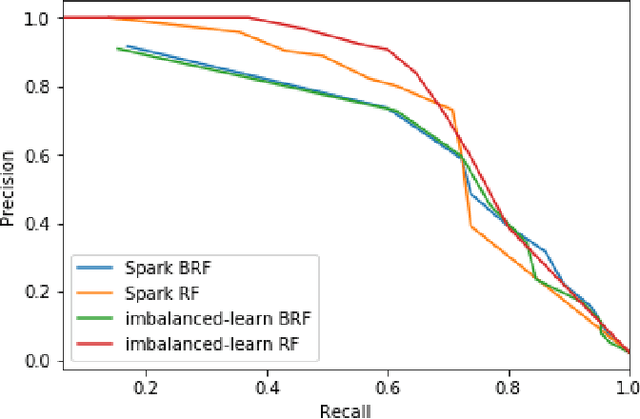
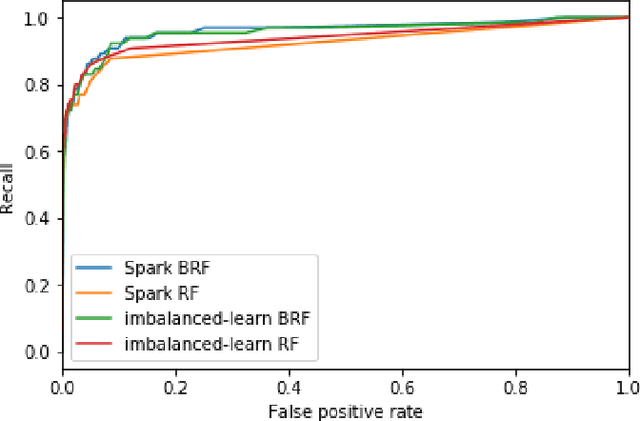
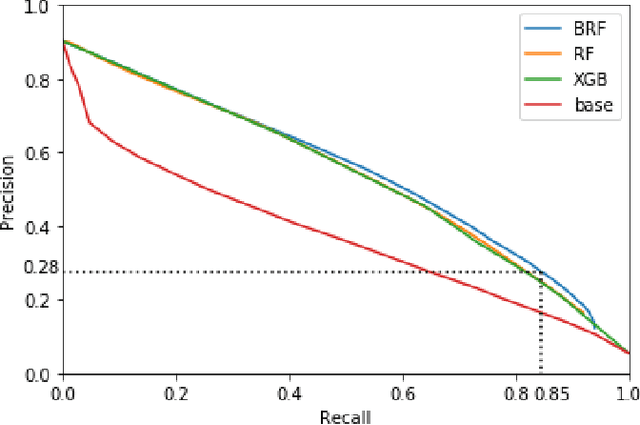
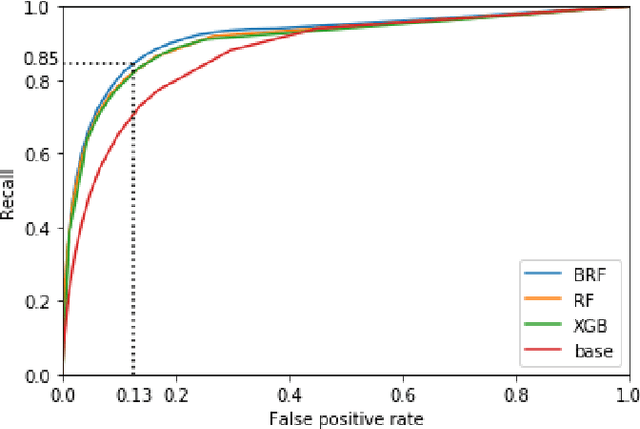
Road accidents are an important issue of our modern societies, responsible for millions of deaths and injuries every year in the world. In Quebec only, road accidents are responsible for hundreds of deaths and tens of thousands of injuries. In this paper, we show how one can leverage open datasets of a city like Montreal, Canada, to create high-resolution accident prediction models, using state-of-the-art big data analytics. Compared to other studies in road accident prediction, we have a much higher prediction resolution, i.e., our models predict the occurrence of an accident within an hour, on road segments defined by intersections. Such models could be used in the context of road accident prevention, but also to identify key factors that can lead to a road accident, and consequently, help elaborate new policies. We tested various machine learning methods to deal with the severe class imbalance inherent to accident prediction problems. In particular, we implemented the Balanced Random Forest algorithm, a variant of the Random Forest machine learning algorithm in Apache Spark. Experimental results show that 85% of road vehicle collisions are detected by our model with a false positive rate of 13%. The examples identified as positive are likely to correspond to high-risk situations. In addition, we identify the most important predictors of vehicle collisions for the area of Montreal: the count of accidents on the same road segment during previous years, the temperature, the day of the year, the hour and the visibility.
Subject Cross Validation in Human Activity Recognition
Apr 09, 2019
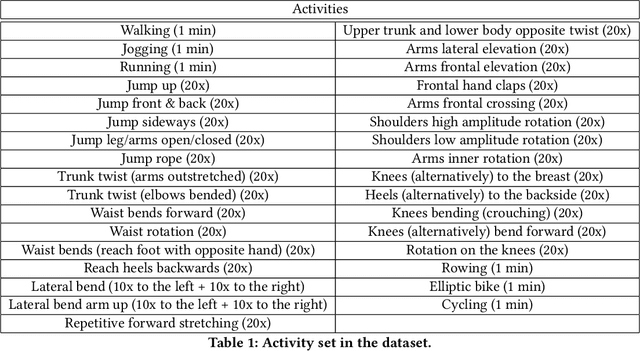
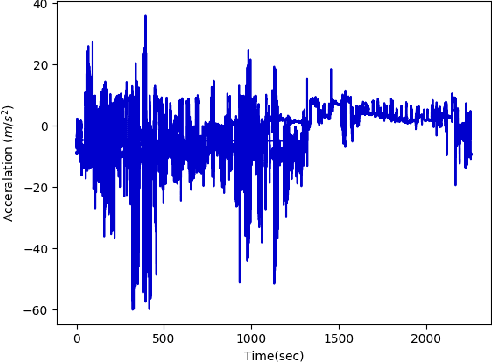
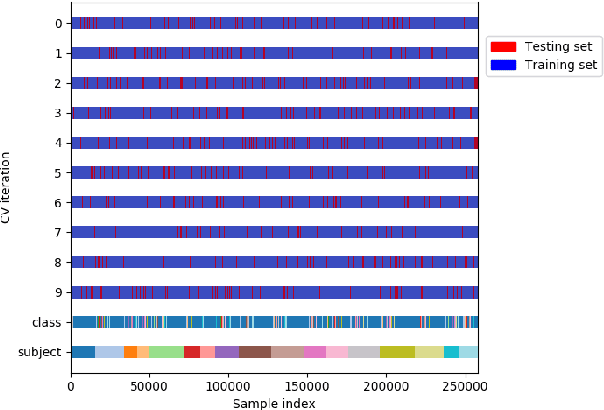
K-fold Cross Validation is commonly used to evaluate classifiers and tune their hyperparameters. However, it assumes that data points are Independent and Identically Distributed (i.i.d.) so that samples used in the training and test sets can be selected randomly and uniformly. In Human Activity Recognition datasets, we note that the samples produced by the same subjects are likely to be correlated due to diverse factors. Hence, k-fold cross validation may overestimate the performance of activity recognizers, in particular when overlapping sliding windows are used. In this paper, we investigate the effect of Subject Cross Validation on the performance of Human Activity Recognition, both with non-overlapping and with overlapping sliding windows. Results show that k-fold cross validation artificially increases the performance of recognizers by about 10%, and even by 16% when overlapping windows are used. In addition, we do not observe any performance gain from the use of overlapping windows. We conclude that Human Activity Recognition systems should be evaluated by Subject Cross Validation, and that overlapping windows are not worth their extra computational cost.
Data models for service failure prediction in supply-chain networks
Oct 20, 2018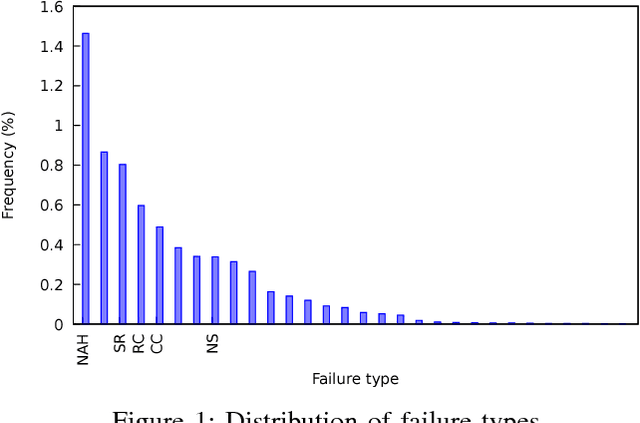
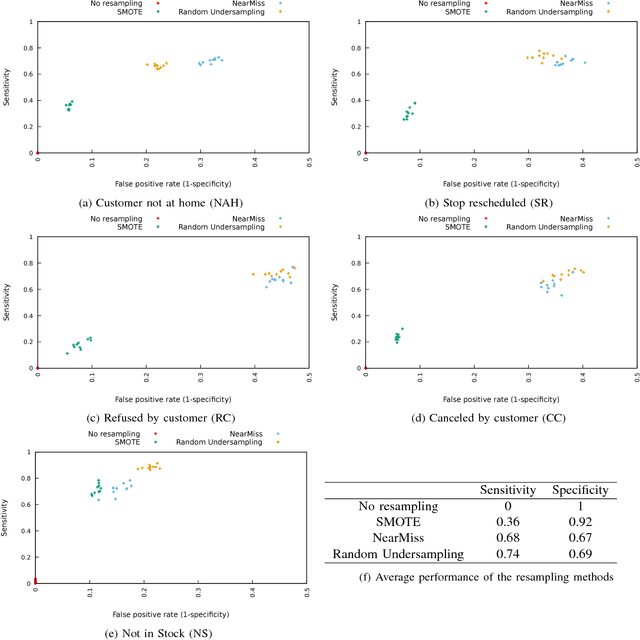
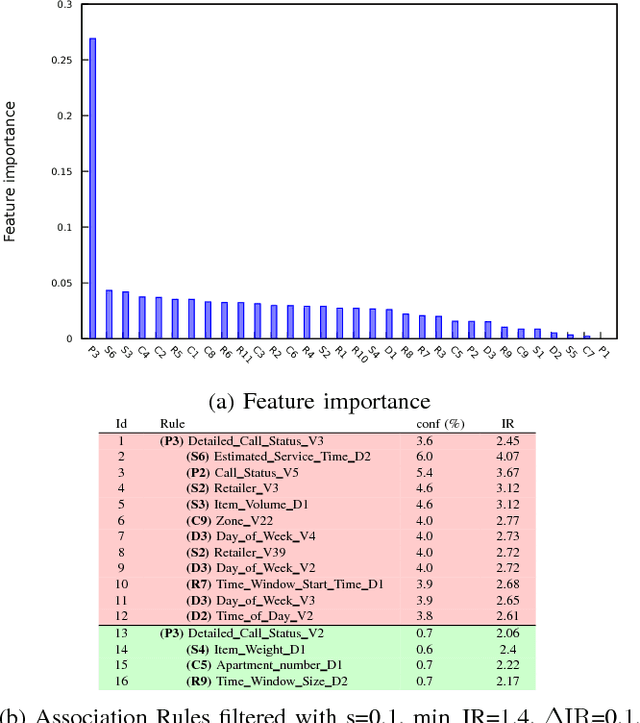
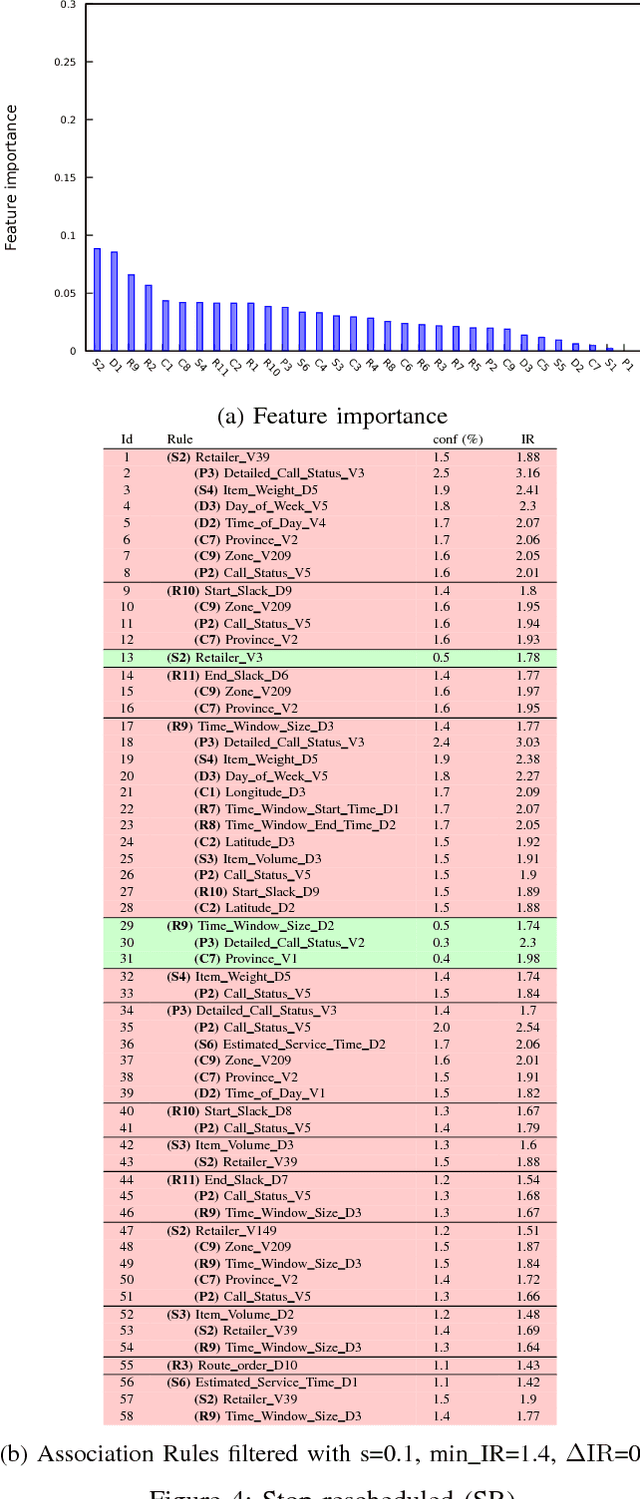
We aim to predict and explain service failures in supply-chain networks, more precisely among last-mile pickup and delivery services to customers. We analyze a dataset of 500,000 services using (1) supervised classification with Random Forests, and (2) Association Rules. Our classifier reaches an average sensitivity of 0.7 and an average specificity of 0.7 for the 5 studied types of failure. Association Rules reassert the importance of confirmation calls to prevent failures due to customers not at home, show the importance of the time window size, slack time, and geographical location of the customer for the other failure types, and highlight the effect of the retailer company on several failure types. To reduce the occurrence of service failures, our data models could be coupled to optimizers, or used to define counter-measures to be taken by human dispatchers.
Predicting computational reproducibility of data analysis pipelines in large population studies using collaborative filtering
Sep 26, 2018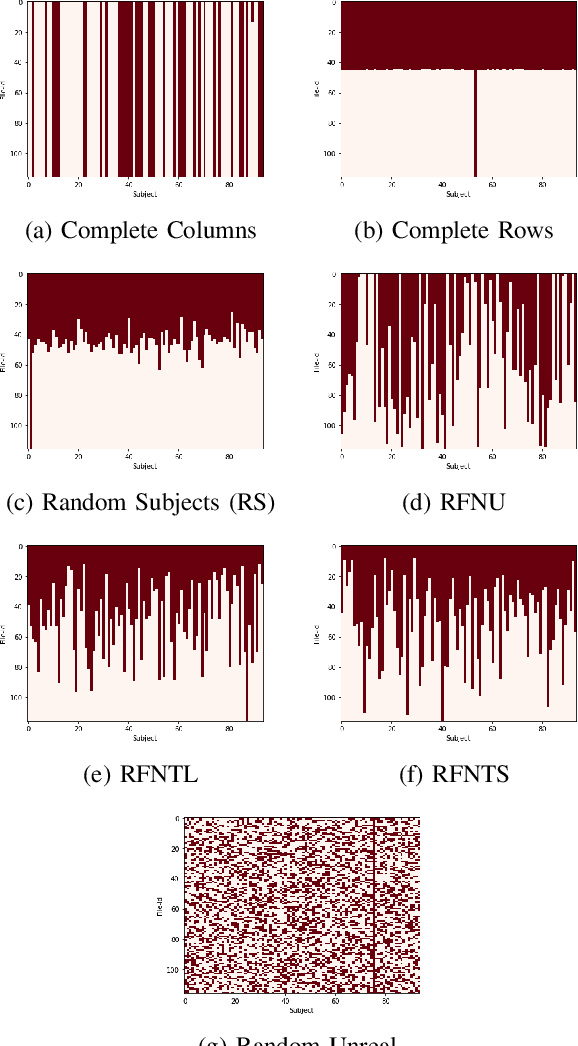
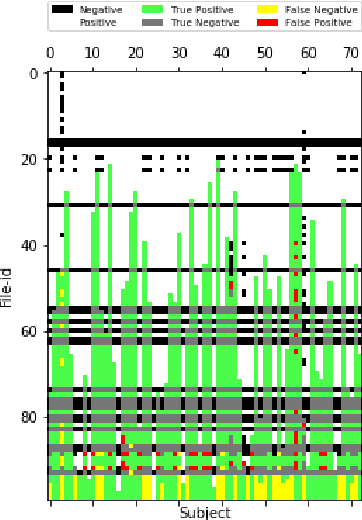
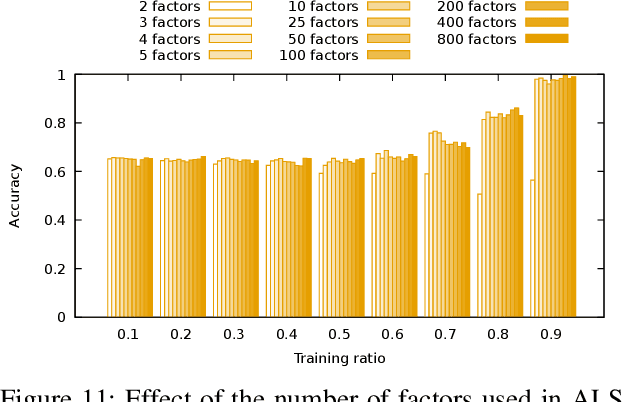
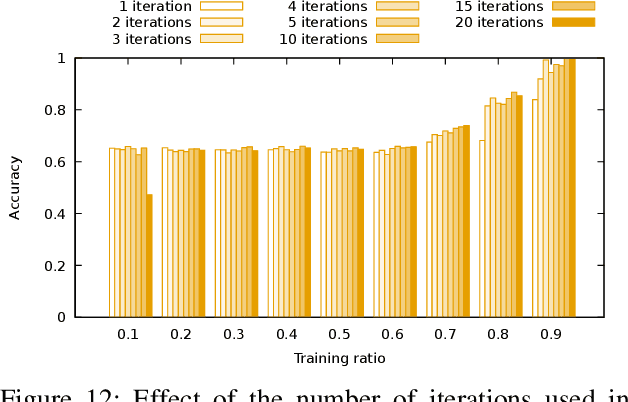
Evaluating the computational reproducibility of data analysis pipelines has become a critical issue. It is, however, a cumbersome process for analyses that involve data from large populations of subjects, due to their computational and storage requirements. We present a method to predict the computational reproducibility of data analysis pipelines in large population studies. We formulate the problem as a collaborative filtering process, with constraints on the construction of the training set. We propose 6 different strategies to build the training set, which we evaluate on 2 datasets, a synthetic one modeling a population with a growing number of subject types, and a real one obtained with neuroinformatics pipelines. Results show that one sampling method, "Random File Numbers (Uniform)" is able to predict computational reproducibility with a good accuracy. We also analyze the relevance of including file and subject biases in the collaborative filtering model. We conclude that the proposed method is able to speedup reproducibility evaluations substantially, with a reduced accuracy loss.