 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Neural Network-based Temporal Point Processes
Jan 29, 2024Human activities generate various event sequences such as taxi trip records, bike-sharing pick-ups, crime occurrence, and infectious disease transmission. The point process is widely used in many applications to predict such events related to human activities. However, point processes present two problems in predicting events related to human activities. First, recent high-performance point process models require the input of sufficient numbers of events collected over a long period (i.e., long sequences) for training, which are often unavailable in realistic situations. Second, the long-term predictions required in real-world applications are difficult. To tackle these problems, we propose a novel meta-learning approach for periodicity-aware prediction of future events given short sequences. The proposed method first embeds short sequences into hidden representations (i.e., task representations) via recurrent neural networks for creating predictions from short sequences. It then models the intensity of the point process by monotonic neural networks (MNNs), with the input being the task representations. We transfer the prior knowledge learned from related tasks and can improve event prediction given short sequences of target tasks. We design the MNNs to explicitly take temporal periodic patterns into account, contributing to improved long-term prediction performance. Experiments on multiple real-world datasets demonstrate that the proposed method has higher prediction performance than existing alternatives.
Meta-learning to Calibrate Gaussian Processes with Deep Kernels for Regression Uncertainty Estimation
Dec 13, 2023Although Gaussian processes (GPs) with deep kernels have been successfully used for meta-learning in regression tasks, its uncertainty estimation performance can be poor. We propose a meta-learning method for calibrating deep kernel GPs for improving regression uncertainty estimation performance with a limited number of training data. The proposed method meta-learns how to calibrate uncertainty using data from various tasks by minimizing the test expected calibration error, and uses the knowledge for unseen tasks. We design our model such that the adaptation and calibration for each task can be performed without iterative procedures, which enables effective meta-learning. In particular, a task-specific uncalibrated output distribution is modeled by a GP with a task-shared encoder network, and it is transformed to a calibrated one using a cumulative density function of a task-specific Gaussian mixture model (GMM). By integrating the GP and GMM into our neural network-based model, we can meta-learn model parameters in an end-to-end fashion. Our experiments demonstrate that the proposed method improves uncertainty estimation performance while keeping high regression performance compared with the existing methods using real-world datasets in few-shot settings.
Meta-learning of semi-supervised learning from tasks with heterogeneous attribute spaces
Nov 09, 2023We propose a meta-learning method for semi-supervised learning that learns from multiple tasks with heterogeneous attribute spaces. The existing semi-supervised meta-learning methods assume that all tasks share the same attribute space, which prevents us from learning with a wide variety of tasks. With the proposed method, the expected test performance on tasks with a small amount of labeled data is improved with unlabeled data as well as data in various tasks, where the attribute spaces are different among tasks. The proposed method embeds labeled and unlabeled data simultaneously in a task-specific space using a neural network, and the unlabeled data's labels are estimated by adapting classification or regression models in the embedding space. For the neural network, we develop variable-feature self-attention layers, which enable us to find embeddings of data with different attribute spaces with a single neural network by considering interactions among examples, attributes, and labels. Our experiments on classification and regression datasets with heterogeneous attribute spaces demonstrate that our proposed method outperforms the existing meta-learning and semi-supervised learning methods.
Meta-learning of Physics-informed Neural Networks for Efficiently Solving Newly Given PDEs
Oct 20, 2023



We propose a neural network-based meta-learning method to efficiently solve partial differential equation (PDE) problems. The proposed method is designed to meta-learn how to solve a wide variety of PDE problems, and uses the knowledge for solving newly given PDE problems. We encode a PDE problem into a problem representation using neural networks, where governing equations are represented by coefficients of a polynomial function of partial derivatives, and boundary conditions are represented by a set of point-condition pairs. We use the problem representation as an input of a neural network for predicting solutions, which enables us to efficiently predict problem-specific solutions by the forwarding process of the neural network without updating model parameters. To train our model, we minimize the expected error when adapted to a PDE problem based on the physics-informed neural network framework, by which we can evaluate the error even when solutions are unknown. We demonstrate that our proposed method outperforms existing methods in predicting solutions of PDE problems.
Explanation-Based Training with Differentiable Insertion/Deletion Metric-Aware Regularizers
Oct 20, 2023



The quality of explanations for the predictions of complex machine learning predictors is often measured using insertion and deletion metrics, which assess the faithfulness of the explanations, i.e., how correctly the explanations reflect the predictor's behavior. To improve the faithfulness, we propose insertion/deletion metric-aware explanation-based optimization (ID-ExpO), which optimizes differentiable predictors to improve both insertion and deletion scores of the explanations while keeping their predictive accuracy. Since the original insertion and deletion metrics are indifferentiable with respect to the explanations and directly unavailable for gradient-based optimization, we extend the metrics to be differentiable and use them to formalize insertion and deletion metric-based regularizers. The experimental results on image and tabular datasets show that the deep neural networks-based predictors fine-tuned using ID-ExpO enable popular post-hoc explainers to produce more faithful and easy-to-interpret explanations while keeping high predictive accuracy.
Information-theoretic Analysis of Test Data Sensitivity in Uncertainty
Jul 23, 2023



Bayesian inference is often utilized for uncertainty quantification tasks. A recent analysis by Xu and Raginsky 2022 rigorously decomposed the predictive uncertainty in Bayesian inference into two uncertainties, called aleatoric and epistemic uncertainties, which represent the inherent randomness in the data-generating process and the variability due to insufficient data, respectively. They analyzed those uncertainties in an information-theoretic way, assuming that the model is well-specified and treating the model's parameters as latent variables. However, the existing information-theoretic analysis of uncertainty cannot explain the widely believed property of uncertainty, known as the sensitivity between the test and training data. It implies that when test data are similar to training data in some sense, the epistemic uncertainty should become small. In this work, we study such uncertainty sensitivity using our novel decomposition method for the predictive uncertainty. Our analysis successfully defines such sensitivity using information-theoretic quantities. Furthermore, we extend the existing analysis of Bayesian meta-learning and show the novel sensitivities among tasks for the first time.
Meta-learning for heterogeneous treatment effect estimation with closed-form solvers
May 19, 2023


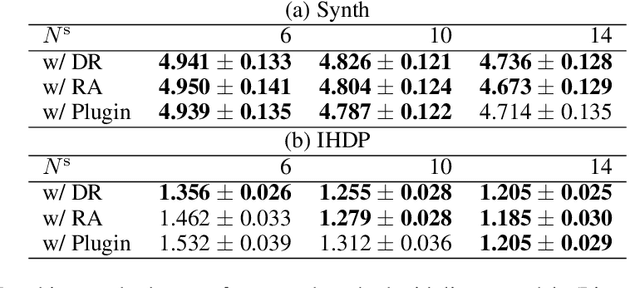
This article proposes a meta-learning method for estimating the conditional average treatment effect (CATE) from a few observational data. The proposed method learns how to estimate CATEs from multiple tasks and uses the knowledge for unseen tasks. In the proposed method, based on the meta-learner framework, we decompose the CATE estimation problem into sub-problems. For each sub-problem, we formulate our estimation models using neural networks with task-shared and task-specific parameters. With our formulation, we can obtain optimal task-specific parameters in a closed form that are differentiable with respect to task-shared parameters, making it possible to perform effective meta-learning. The task-shared parameters are trained such that the expected CATE estimation performance in few-shot settings is improved by minimizing the difference between a CATE estimated with a large amount of data and one estimated with just a few data. Our experimental results demonstrate that our method outperforms the existing meta-learning approaches and CATE estimation methods.
Modeling Nonlinear Dynamics in Continuous Time with Inductive Biases on Decay Rates and/or Frequencies
Dec 26, 2022
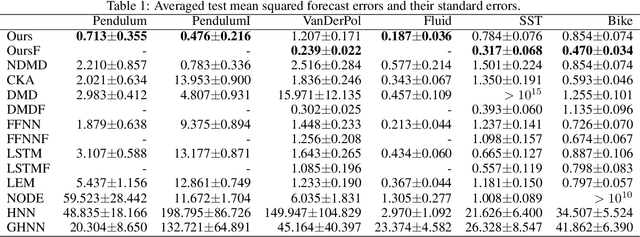
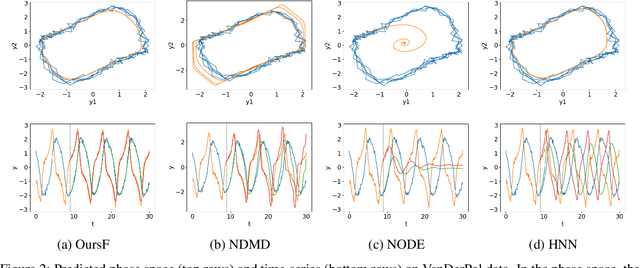

We propose a neural network-based model for nonlinear dynamics in continuous time that can impose inductive biases on decay rates and/or frequencies. Inductive biases are helpful for training neural networks especially when training data are small. The proposed model is based on the Koopman operator theory, where the decay rate and frequency information is used by restricting the eigenvalues of the Koopman operator that describe linear evolution in a Koopman space. We use neural networks to find an appropriate Koopman space, which are trained by minimizing multi-step forecasting and backcasting errors using irregularly sampled time-series data. Experiments on various time-series datasets demonstrate that the proposed method achieves higher forecasting performance given a single short training sequence than the existing methods.
Linear Embedding-based High-dimensional Batch Bayesian Optimization without Reconstruction Mappings
Nov 02, 2022



The optimization of high-dimensional black-box functions is a challenging problem. When a low-dimensional linear embedding structure can be assumed, existing Bayesian optimization (BO) methods often transform the original problem into optimization in a low-dimensional space. They exploit the low-dimensional structure and reduce the computational burden. However, we reveal that this approach could be limited or inefficient in exploring the high-dimensional space mainly due to the biased reconstruction of the high-dimensional queries from the low-dimensional queries. In this paper, we investigate a simple alternative approach: tackling the problem in the original high-dimensional space using the information from the learned low-dimensional structure. We provide a theoretical analysis of the exploration ability. Furthermore, we show that our method is applicable to batch optimization problems with thousands of dimensions without any computational difficulty. We demonstrate the effectiveness of our method on high-dimensional benchmarks and a real-world function.
Active Learning for Regression with Aggregated Outputs
Oct 04, 2022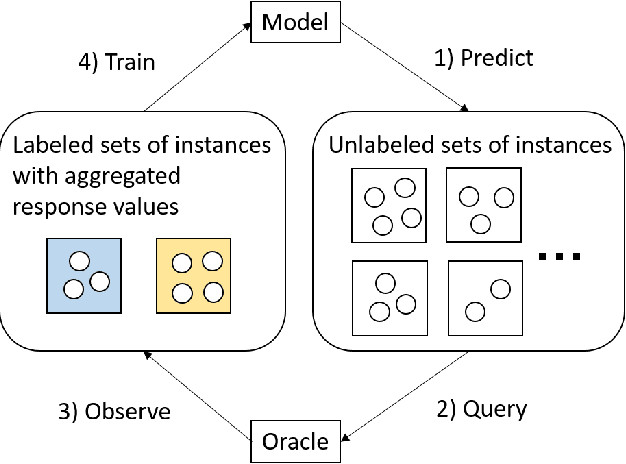

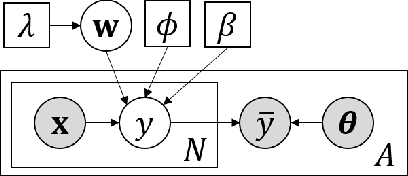
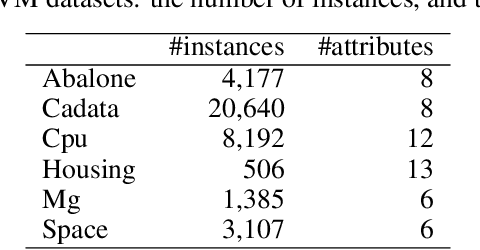
Due to the privacy protection or the difficulty of data collection, we cannot observe individual outputs for each instance, but we can observe aggregated outputs that are summed over multiple instances in a set in some real-world applications. To reduce the labeling cost for training regression models for such aggregated data, we propose an active learning method that sequentially selects sets to be labeled to improve the predictive performance with fewer labeled sets. For the selection measurement, the proposed method uses the mutual information, which quantifies the reduction of the uncertainty of the model parameters by observing the aggregated output. With Bayesian linear basis functions for modeling outputs given an input, which include approximated Gaussian processes and neural networks, we can efficiently calculate the mutual information in a closed form. With the experiments using various datasets, we demonstrate that the proposed method achieves better predictive performance with fewer labeled sets than existing methods.