 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTomas Mikolov
Combinatory Chemistry: Towards a Simple Model of Emergent Evolution
Mar 17, 2020


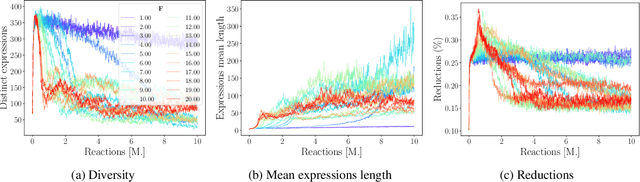
Researching the conditions for the emergence of life -- not necessarily as it is, but as it could be -- is one of the main goals of Artificial Life. Answering this question requires a model that can first explain the emergence of evolvable units, namely, structures that (1) preserve themselves in time (2) self-reproduce and (3) can tolerate a certain amount of variation when reproducing. To tackle this challenge, here we introduce Combinatory Chemistry, an Algorithmic Artificial Chemistry based on a simple computational paradigm named Combinatory Logic. The dynamics of this system comprise very few rules, it is initialized with an elementary tabula rasa state, and features conservation laws replicating natural resource constraints. Our experiments show that a single run of this dynamical system discovers a wide range of emergent patterns with no external intervention. All these structures rely on acquiring basic constituents from the environment and decomposing them in a process that is remarkably similar to biological metabolisms. These patterns involve autopoietic structures that maintain their organisation, recursive ones that grow in linear chains or binary-branching trees, and most notably, patterns able to reproduce themselves, duplicating their number at each generation.
Evolving Structures in Complex Systems
Nov 04, 2019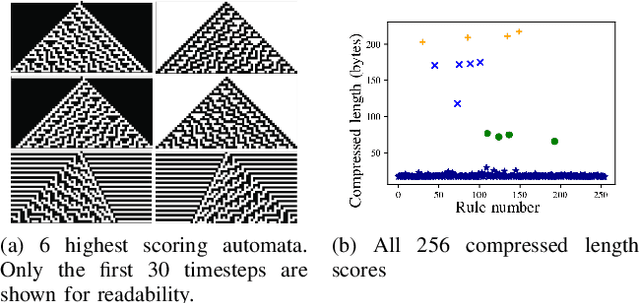



In this paper we propose an approach for measuring growth of complexity of emerging patterns in complex systems such as cellular automata. We discuss several ways how a metric for measuring the complexity growth can be defined. This includes approaches based on compression algorithms and artificial neural networks. We believe such a metric can be useful for designing systems that could exhibit open-ended evolution, which itself might be a prerequisite for development of general artificial intelligence. We conduct experiments on 1D and 2D grid worlds and demonstrate that using the proposed metric we can automatically construct computational models with emerging properties similar to those found in the Conway's Game of Life, as well as many other emergent phenomena. Interestingly, some of the patterns we observe resemble forms of artificial life. Our metric of structural complexity growth can be applied to a wide range of complex systems, as it is not limited to cellular automata.
* IEEE Symposium Series on Computational Intelligence 2019 (IEEE SSCI 2019)
Updating Pre-trained Word Vectors and Text Classifiers using Monolingual Alignment
Oct 15, 2019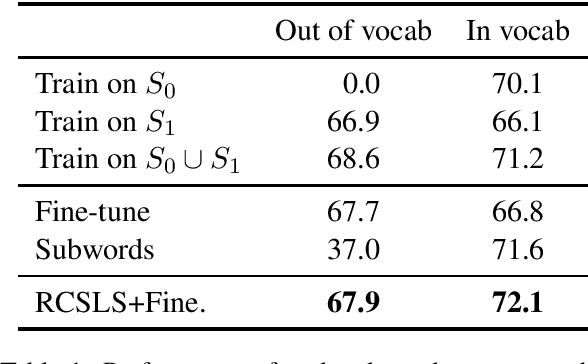
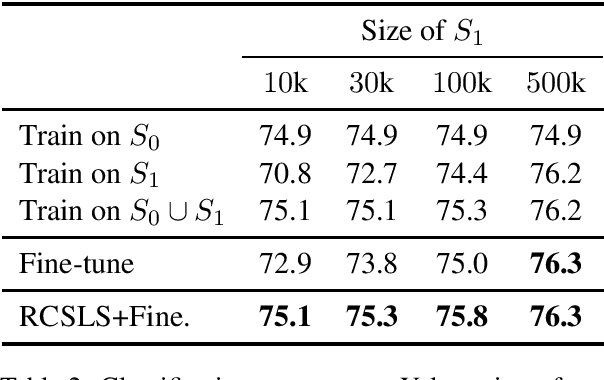
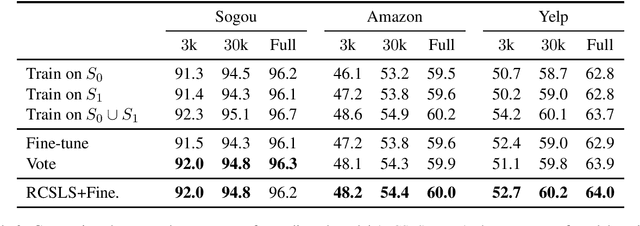
In this paper, we focus on the problem of adapting word vector-based models to new textual data. Given a model pre-trained on large reference data, how can we adapt it to a smaller piece of data with a slightly different language distribution? We frame the adaptation problem as a monolingual word vector alignment problem, and simply average models after alignment. We align vectors using the RCSLS criterion. Our formulation results in a simple and efficient algorithm that allows adapting general-purpose models to changing word distributions. In our evaluation, we consider applications to word embedding and text classification models. We show that the proposed approach yields good performance in all setups and outperforms a baseline consisting in fine-tuning the model on new data.
Place Deduplication with Embeddings
Sep 29, 2019
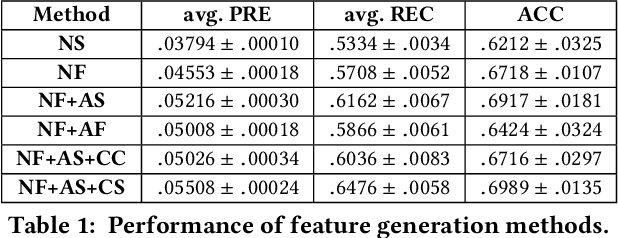
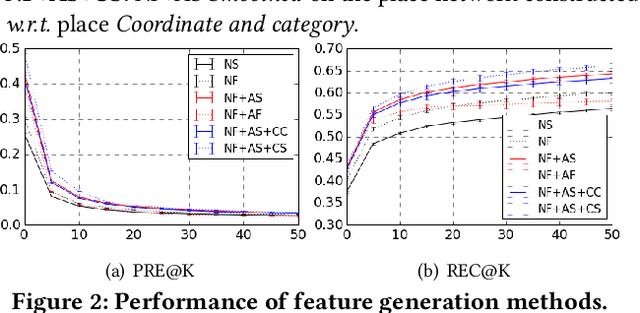
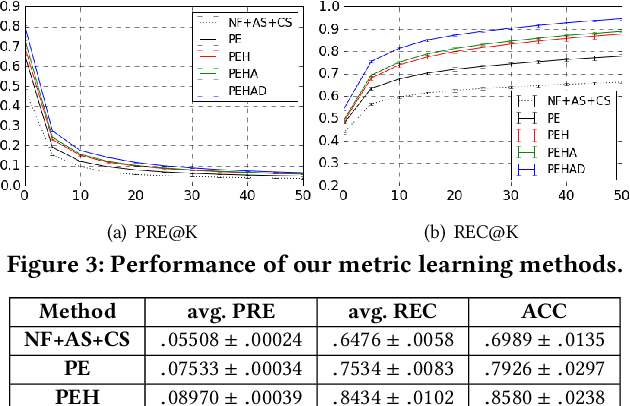
Thanks to the advancing mobile location services, people nowadays can post about places to share visiting experience on-the-go. A large place graph not only helps users explore interesting destinations, but also provides opportunities for understanding and modeling the real world. To improve coverage and flexibility of the place graph, many platforms import places data from multiple sources, which unfortunately leads to the emergence of numerous duplicated places that severely hinder subsequent location-related services. In this work, we take the anonymous place graph from Facebook as an example to systematically study the problem of place deduplication: We carefully formulate the problem, study its connections to various related tasks that lead to several promising basic models, and arrive at a systematic two-step data-driven pipeline based on place embedding with multiple novel techniques that works significantly better than the state-of-the-art.
Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion
Sep 05, 2018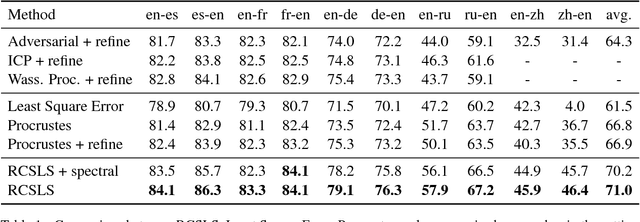
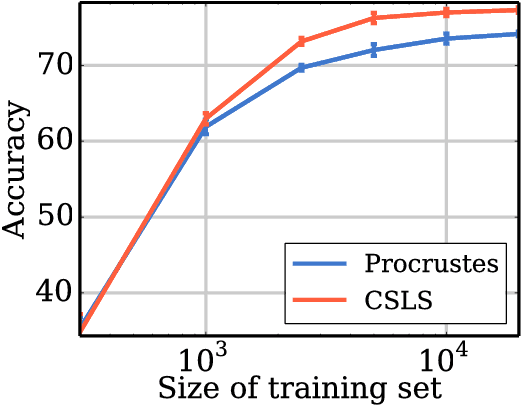
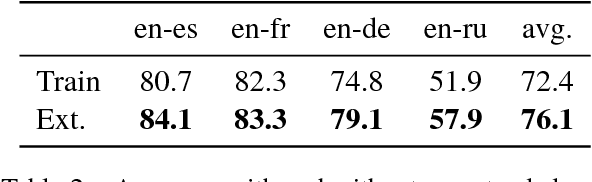
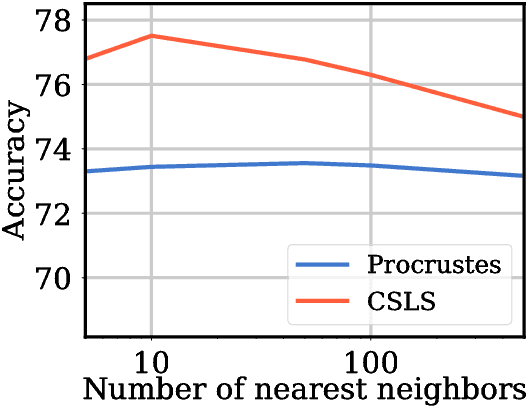
Continuous word representations learned separately on distinct languages can be aligned so that their words become comparable in a common space. Existing works typically solve a least-square regression problem to learn a rotation aligning a small bilingual lexicon, and use a retrieval criterion for inference. In this paper, we propose an unified formulation that directly optimizes a retrieval criterion in an end-to-end fashion. Our experiments on standard benchmarks show that our approach outperforms the state of the art on word translation, with the biggest improvements observed for distant language pairs such as English-Chinese.
Learning Word Vectors for 157 Languages
Mar 28, 2018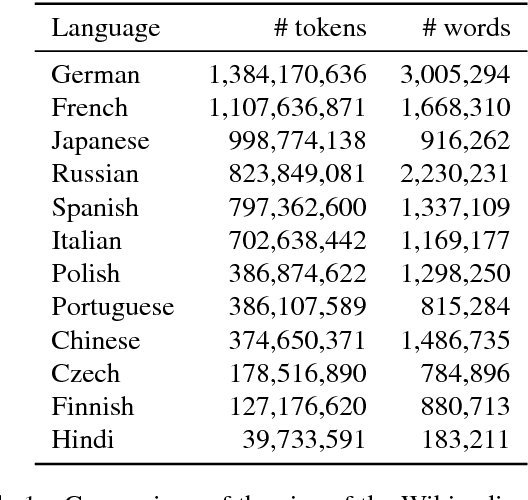
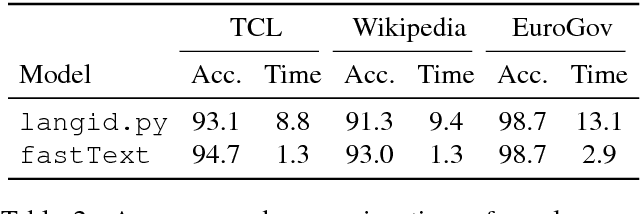
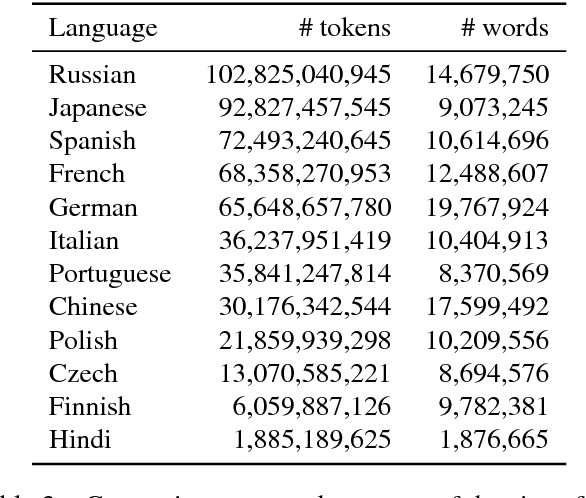
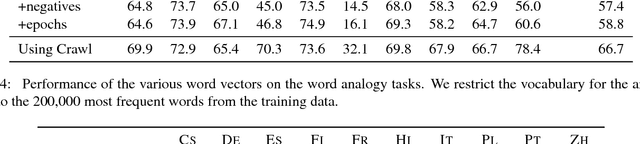
Distributed word representations, or word vectors, have recently been applied to many tasks in natural language processing, leading to state-of-the-art performance. A key ingredient to the successful application of these representations is to train them on very large corpora, and use these pre-trained models in downstream tasks. In this paper, we describe how we trained such high quality word representations for 157 languages. We used two sources of data to train these models: the free online encyclopedia Wikipedia and data from the common crawl project. We also introduce three new word analogy datasets to evaluate these word vectors, for French, Hindi and Polish. Finally, we evaluate our pre-trained word vectors on 10 languages for which evaluation datasets exists, showing very strong performance compared to previous models.
Advances in Pre-Training Distributed Word Representations
Dec 26, 2017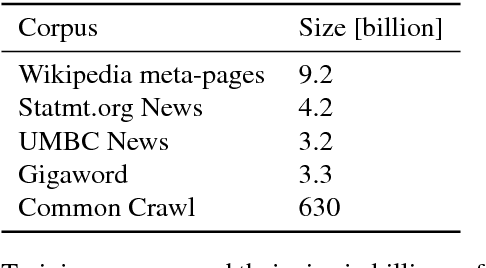

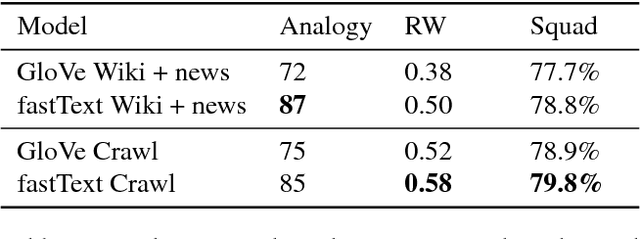
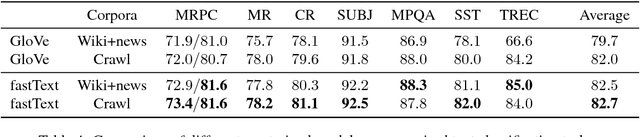
Many Natural Language Processing applications nowadays rely on pre-trained word representations estimated from large text corpora such as news collections, Wikipedia and Web Crawl. In this paper, we show how to train high-quality word vector representations by using a combination of known tricks that are however rarely used together. The main result of our work is the new set of publicly available pre-trained models that outperform the current state of the art by a large margin on a number of tasks.
Fast Linear Model for Knowledge Graph Embeddings
Oct 30, 2017



This paper shows that a simple baseline based on a Bag-of-Words (BoW) representation learns surprisingly good knowledge graph embeddings. By casting knowledge base completion and question answering as supervised classification problems, we observe that modeling co-occurences of entities and relations leads to state-of-the-art performance with a training time of a few minutes using the open sourced library fastText.
Learning Simpler Language Models with the Differential State Framework
Jul 16, 2017Learning useful information across long time lags is a critical and difficult problem for temporal neural models in tasks such as language modeling. Existing architectures that address the issue are often complex and costly to train. The Differential State Framework (DSF) is a simple and high-performing design that unifies previously introduced gated neural models. DSF models maintain longer-term memory by learning to interpolate between a fast-changing data-driven representation and a slowly changing, implicitly stable state. This requires hardly any more parameters than a classical, simple recurrent network. Within the DSF framework, a new architecture is presented, the Delta-RNN. In language modeling at the word and character levels, the Delta-RNN outperforms popular complex architectures, such as the Long Short Term Memory (LSTM) and the Gated Recurrent Unit (GRU), and, when regularized, performs comparably to several state-of-the-art baselines. At the subword level, the Delta-RNN's performance is comparable to that of complex gated architectures.
Enriching Word Vectors with Subword Information
Jun 19, 2017Continuous word representations, trained on large unlabeled corpora are useful for many natural language processing tasks. Popular models that learn such representations ignore the morphology of words, by assigning a distinct vector to each word. This is a limitation, especially for languages with large vocabularies and many rare words. In this paper, we propose a new approach based on the skipgram model, where each word is represented as a bag of character $n$-grams. A vector representation is associated to each character $n$-gram; words being represented as the sum of these representations. Our method is fast, allowing to train models on large corpora quickly and allows us to compute word representations for words that did not appear in the training data. We evaluate our word representations on nine different languages, both on word similarity and analogy tasks. By comparing to recently proposed morphological word representations, we show that our vectors achieve state-of-the-art performance on these tasks.