 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANDA : Perceptually Aware Neural Detection of Anomalies
Apr 28, 2021
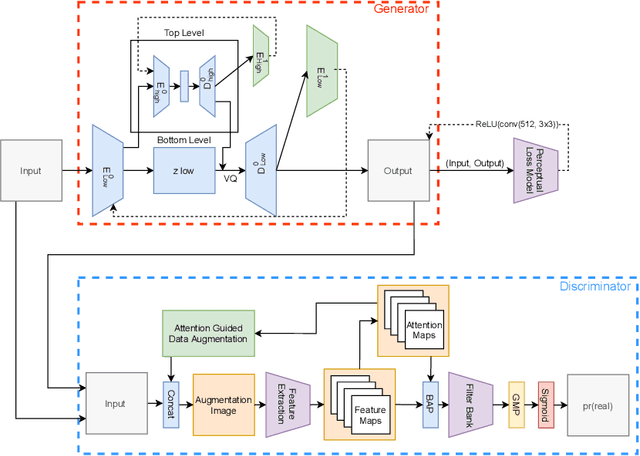
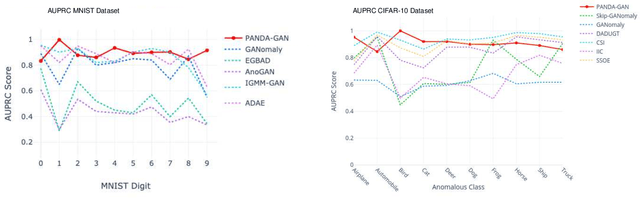

Semi-supervised methods of anomaly detection have seen substantial advancement in recent years. Of particular interest are applications of such methods to diverse, real-world anomaly detection problems where anomalous variations can vary from the visually obvious to the very subtle. In this work, we propose a novel fine-grained VAE-GAN architecture trained in a semi-supervised manner in order to detect both visually distinct and subtle anomalies. With the use of a residually connected dual-feature extractor, a fine-grained discriminator and a perceptual loss function, we are able to detect subtle, low inter-class (anomaly vs. normal) variant anomalies with greater detection capability and smaller margins of deviation in AUC value during inference compared to prior work whilst also remaining time-efficient during inference. We achieve state of-the-art anomaly detection results when compared extensively with prior semi-supervised approaches across a multitude of anomaly detection benchmark tasks including trivial leave-one out tasks (CIFAR-10 - AUPRCavg: 0.91; MNIST - AUPRCavg: 0.90) in addition to challenging real-world anomaly detection tasks (plant leaf disease - AUC: 0.776; threat item X-ray - AUC: 0.51), video frame-level anomaly detection (UCSDPed1 - AUC: 0.95) and high frequency texture with object anomalous defect detection (MVTEC - AUCavg: 0.83).
UAV-ReID: A Benchmark on Unmanned Aerial Vehicle Re-identification
Apr 13, 2021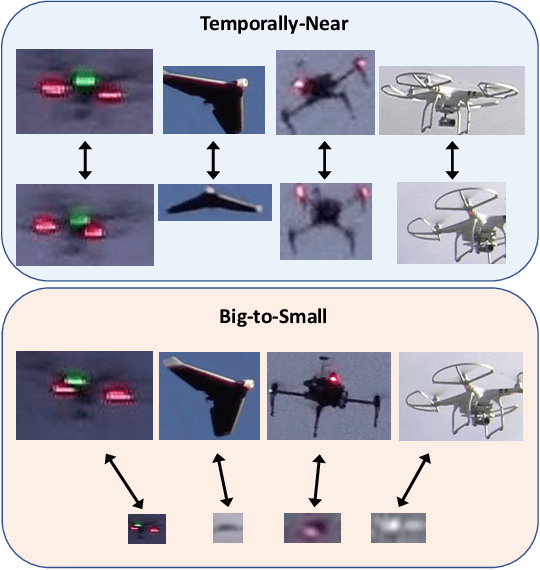
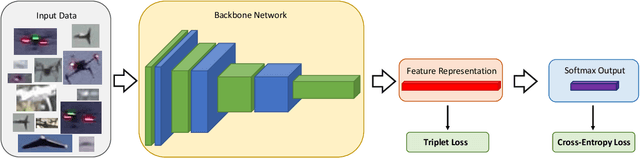

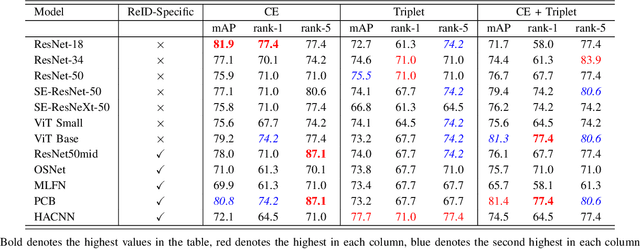
As unmanned aerial vehicles (UAVs) become more accessible with a growing range of applications, the potential risk of UAV disruption increases. Recent development in deep learning allows vision-based counter-UAV systems to detect and track UAVs with a single camera. However, the coverage of a single camera is limited, necessitating the need for multicamera configurations to match UAVs across cameras - a problem known as re-identification (reID). While there has been extensive research on person and vehicle reID to match objects across time and viewpoints, to the best of our knowledge, there has been no research in UAV reID. UAVs are challenging to re-identify: they are much smaller than pedestrians and vehicles and they are often detected in the air so appear at a greater range of angles. Because no UAV data sets currently use multiple cameras, we propose the first new UAV re-identification data set, UAV-reID, that facilitates the development of machine learning solutions in this emerging area. UAV-reID has two settings: Temporally-Near to evaluate performance across views to assist tracking frameworks, and Big-to-Small to evaluate reID performance across scale and to allow early reID when UAVs are detected from a long distance. We conduct a benchmark study by extensively evaluating different reID backbones and loss functions. We demonstrate that with the right setup, deep networks are powerful enough to learn good representations for UAVs, achieving 81.9% mAP on the Temporally-Near setting and 46.5% on the challenging Big-to-Small setting. Furthermore, we find that vision transformers are the most robust to extreme variance of scale.
UNIT-DDPM: UNpaired Image Translation with Denoising Diffusion Probabilistic Models
Apr 12, 2021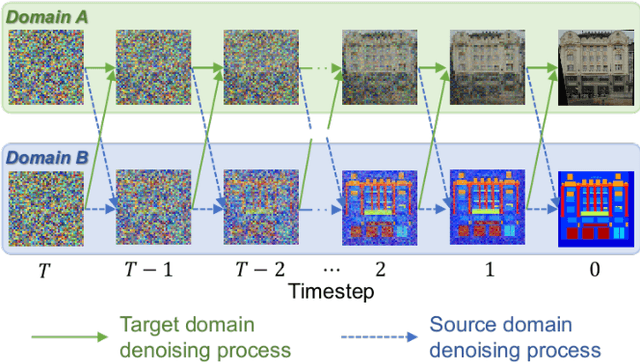
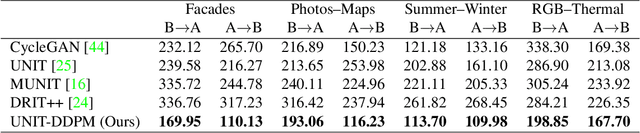
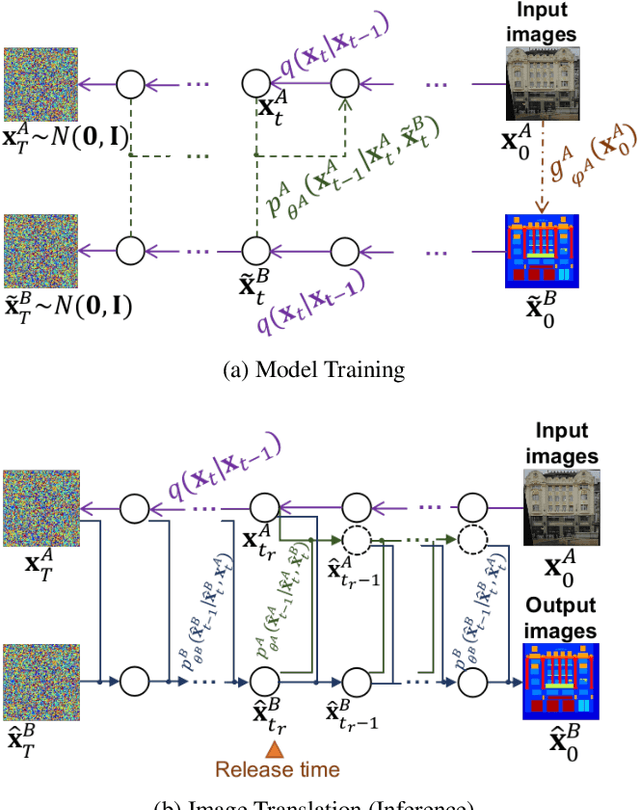

We propose a novel unpaired image-to-image translation method that uses denoising diffusion probabilistic models without requiring adversarial training. Our method, UNpaired Image Translation with Denoising Diffusion Probabilistic Models (UNIT-DDPM), trains a generative model to infer the joint distribution of images over both domains as a Markov chain by minimising a denoising score matching objective conditioned on the other domain. In particular, we update both domain translation models simultaneously, and we generate target domain images by a denoising Markov Chain Monte Carlo approach that is conditioned on the input source domain images, based on Langevin dynamics. Our approach provides stable model training for image-to-image translation and generates high-quality image outputs. This enables state-of-the-art Fr\'echet Inception Distance (FID) performance on several public datasets, including both colour and multispectral imagery, significantly outperforming the contemporary adversarial image-to-image translation methods.
Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark
Mar 29, 2021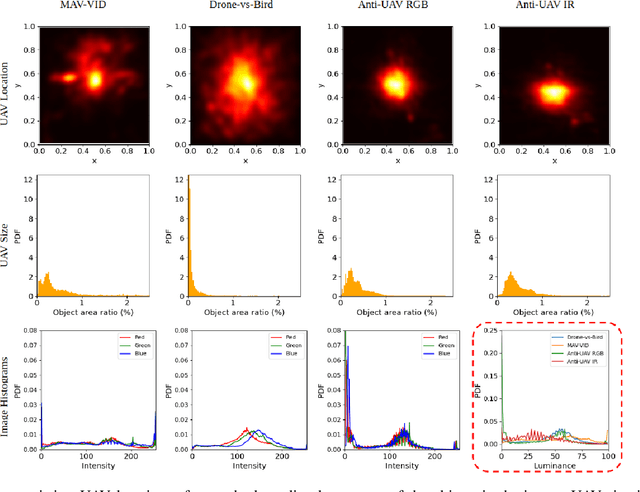
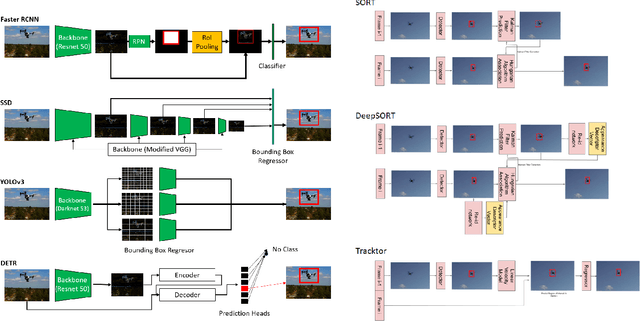
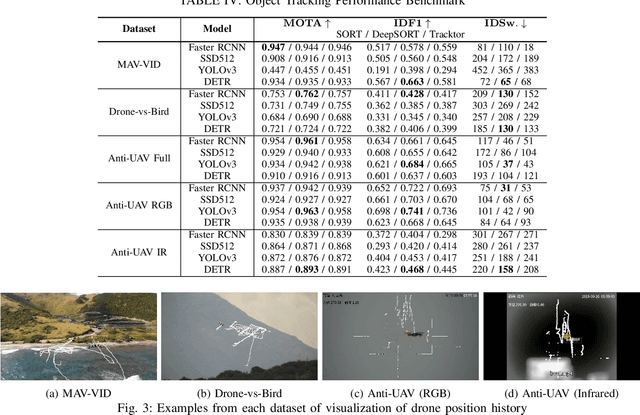
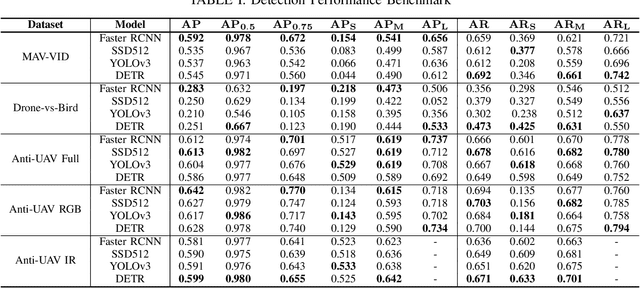
Unmanned Aerial Vehicles (UAV) can pose a major risk for aviation safety, due to both negligent and malicious use. For this reason, the automated detection and tracking of UAV is a fundamental task in aerial security systems. Common technologies for UAV detection include visible-band and thermal infrared imaging, radio frequency and radar. Recent advances in deep neural networks (DNNs) for image-based object detection open the possibility to use visual information for this detection and tracking task. Furthermore, these detection architectures can be implemented as backbones for visual tracking systems, thereby enabling persistent tracking of UAV incursions. To date, no comprehensive performance benchmark exists that applies DNNs to visible-band imagery for UAV detection and tracking. To this end, three datasets with varied environmental conditions for UAV detection and tracking, comprising a total of 241 videos (331,486 images), are assessed using four detection architectures and three tracking frameworks. The best performing detector architecture obtains an mAP of 98.6% and the best performing tracking framework obtains a MOTA of 96.3%. Cross-modality evaluation is carried out between visible and infrared spectrums, achieving a maximal 82.8% mAP on visible images when training in the infrared modality. These results provide the first public multi-approach benchmark for state-of-the-art deep learning-based methods and give insight into which detection and tracking architectures are effective in the UAV domain.
Contraband Materials Detection Within Volumetric 3D Computed Tomography Baggage Security Screening Imagery
Dec 21, 2020
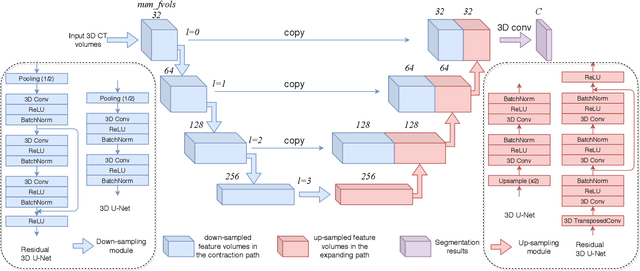
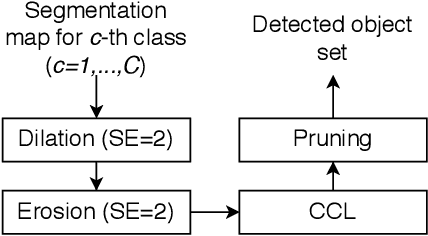
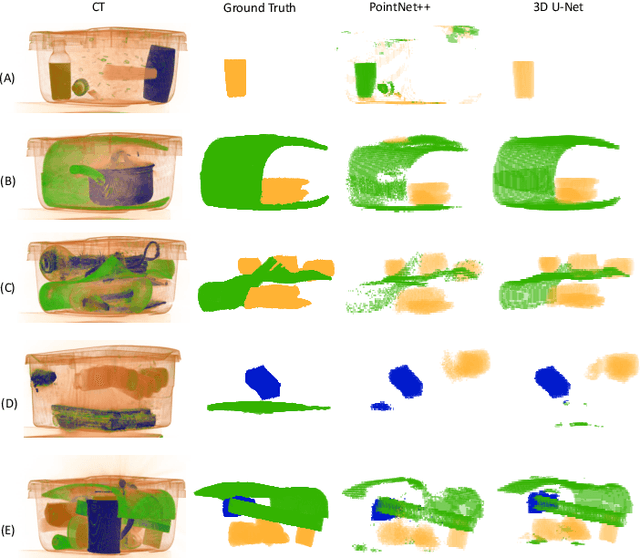
Automatic prohibited object detection within 2D/3D X-ray Computed Tomography (CT) has been studied in literature to enhance the aviation security screening at checkpoints. Deep Convolutional Neural Networks (CNN) have demonstrated superior performance in 2D X-ray imagery. However, there exists very limited proof of how deep neural networks perform in materials detection within volumetric 3D CT baggage screening imagery. We attempt to close this gap by applying Deep Neural Networks in 3D contraband substance detection based on their material signatures. Specifically, we formulate it as a 3D semantic segmentation problem to identify material types for all voxels based on which contraband materials can be detected. To this end, we firstly investigate 3D CNN based semantic segmentation algorithms such as 3D U-Net and its variants. In contrast to the original dense representation form of volumetric 3D CT data, we propose to convert the CT volumes into sparse point clouds which allows the use of point cloud processing approaches such as PointNet++ towards more efficient processing. Experimental results on a publicly available dataset (NEU ATR) demonstrate the effectiveness of both 3D U-Net and PointNet++ in materials detection in 3D CT imagery for baggage security screening.
Multi-Model Learning for Real-Time Automotive Semantic Foggy Scene Understanding via Domain Adaptation
Dec 09, 2020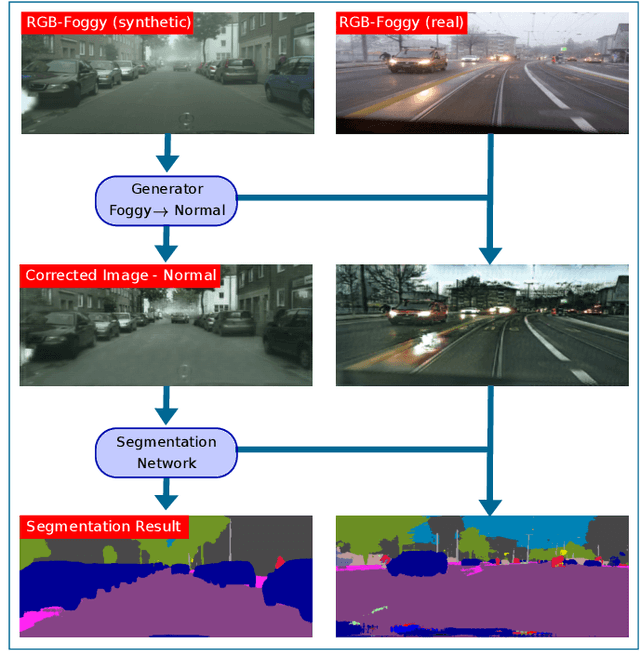
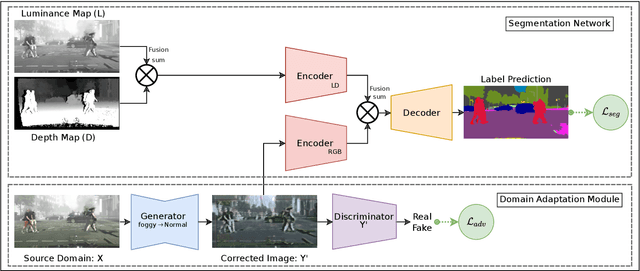
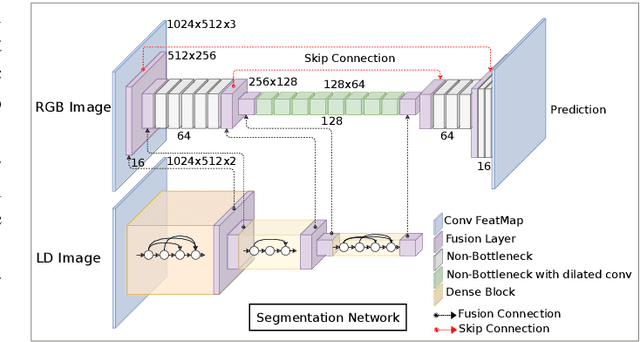

Robust semantic scene segmentation for automotive applications is a challenging problem in two key aspects: (1) labelling every individual scene pixel and (2) performing this task under unstable weather and illumination changes (e.g., foggy weather), which results in poor outdoor scene visibility. Such visibility limitations lead to non-optimal performance of generalised deep convolutional neural network-based semantic scene segmentation. In this paper, we propose an efficient end-to-end automotive semantic scene understanding approach that is robust to foggy weather conditions. As an end-to-end pipeline, our proposed approach provides: (1) the transformation of imagery from foggy to clear weather conditions using a domain transfer approach (correcting for poor visibility) and (2) semantically segmenting the scene using a competitive encoder-decoder architecture with low computational complexity (enabling real-time performance). Our approach incorporates RGB colour, depth and luminance images via distinct encoders with dense connectivity and features fusion to effectively exploit information from different inputs, which contributes to an optimal feature representation within the overall model. Using this architectural formulation with dense skip connections, our model achieves comparable performance to contemporary approaches at a fraction of the overall model complexity.
Competitive Simplicity for Multi-Task Learning for Real-Time Foggy Scene Understanding via Domain Adaptation
Dec 09, 2020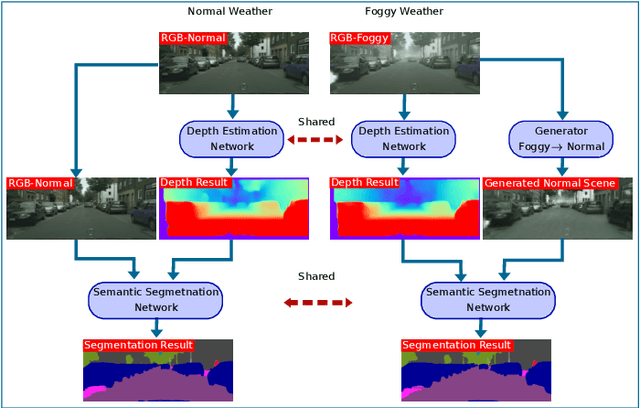
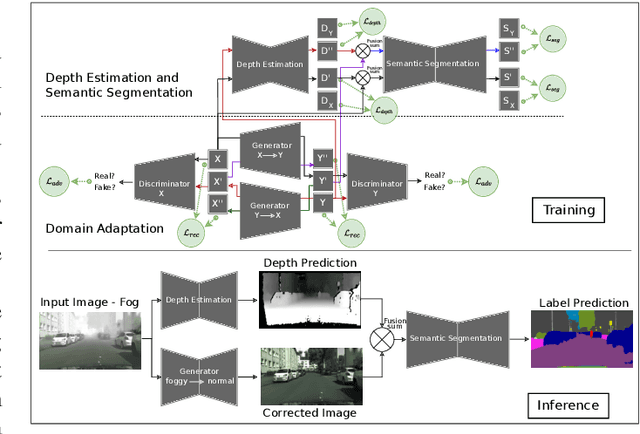
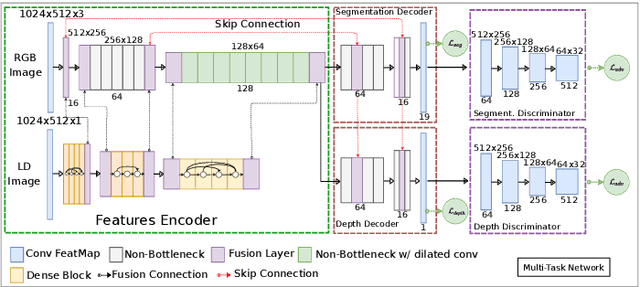
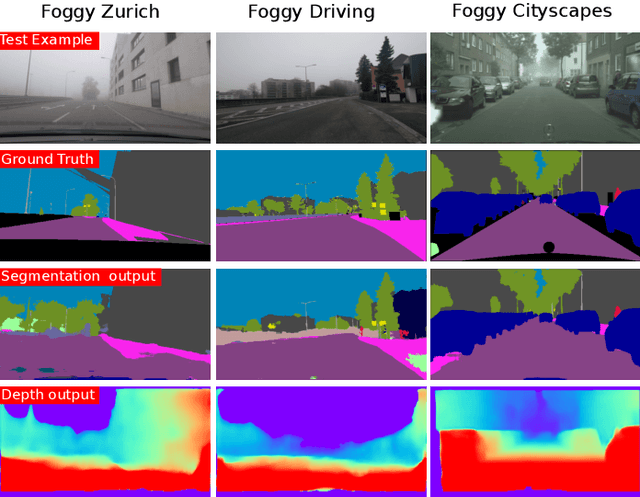
Automotive scene understanding under adverse weather conditions raises a realistic and challenging problem attributable to poor outdoor scene visibility (e.g. foggy weather). However, because most contemporary scene understanding approaches are applied under ideal-weather conditions, such approaches may not provide genuinely optimal performance when compared to established a priori insights on extreme-weather understanding. In this paper, we propose a complex but competitive multi-task learning approach capable of performing in real-time semantic scene understanding and monocular depth estimation under foggy weather conditions by leveraging both recent advances in adversarial training and domain adaptation. As an end-to-end pipeline, our model provides a novel solution to surpass degraded visibility in foggy weather conditions by transferring scenes from foggy to normal using a GAN-based model. For optimal performance in semantic segmentation, our model generates depth to be used as complementary source information with RGB in the segmentation network. We provide a robust method for foggy scene understanding by training two models (normal and foggy) simultaneously with shared weights (each model is trained on each weather condition independently). Our model incorporates RGB colour, depth, and luminance images via distinct encoders with dense connectivity and features fusing, and leverages skip connections to produce consistent depth and segmentation predictions. Using this architectural formulation with light computational complexity at inference time, we are able to achieve comparable performance to contemporary approaches at a fraction of the overall model complexity.
Data Augmentation with norm-VAE for Unsupervised Domain Adaptation
Dec 01, 2020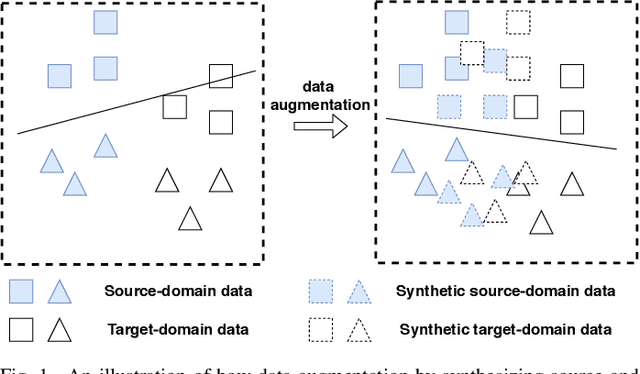
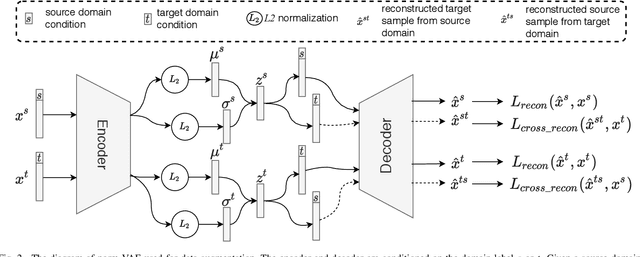

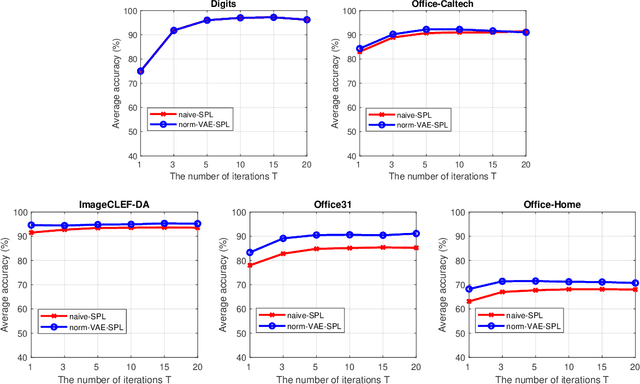
We address the Unsupervised Domain Adaptation (UDA) problem in image classification from a new perspective. In contrast to most existing works which either align the data distributions or learn domain-invariant features, we directly learn a unified classifier for both domains within a high-dimensional homogeneous feature space without explicit domain adaptation. To this end, we employ the effective Selective Pseudo-Labelling (SPL) techniques to take advantage of the unlabelled samples in the target domain. Surprisingly, data distribution discrepancy across the source and target domains can be well handled by a computationally simple classifier (e.g., a shallow Multi-Layer Perceptron) trained in the original feature space. Besides, we propose a novel generative model norm-VAE to generate synthetic features for the target domain as a data augmentation strategy to enhance classifier training. Experimental results on several benchmark datasets demonstrate the pseudo-labelling strategy itself can lead to comparable performance to many state-of-the-art methods whilst the use of norm-VAE for feature augmentation can further improve the performance in most cases. As a result, our proposed methods (i.e. naive-SPL and norm-VAE-SPL) can achieve new state-of-the-art performance with the average accuracy of 93.4% and 90.4% on Office-Caltech and ImageCLEF-DA datasets, and comparable performance on Digits, Office31 and Office-Home datasets with the average accuracy of 97.2%, 87.6% and 67.9% respectively.
Efficient and Compact Convolutional Neural Network Architectures for Non-temporal Real-time Fire Detection
Oct 17, 2020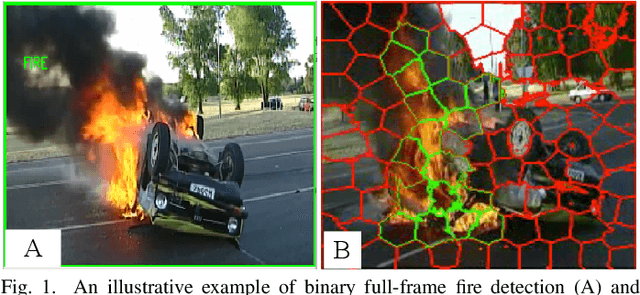
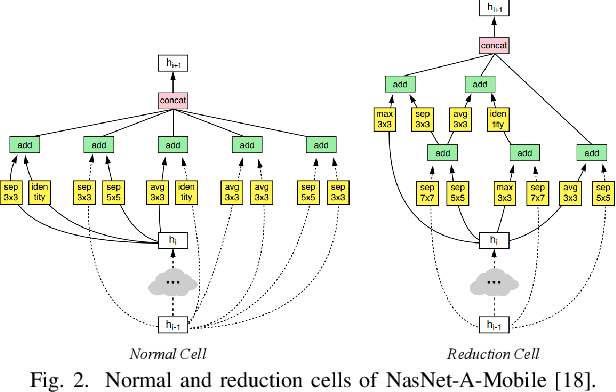
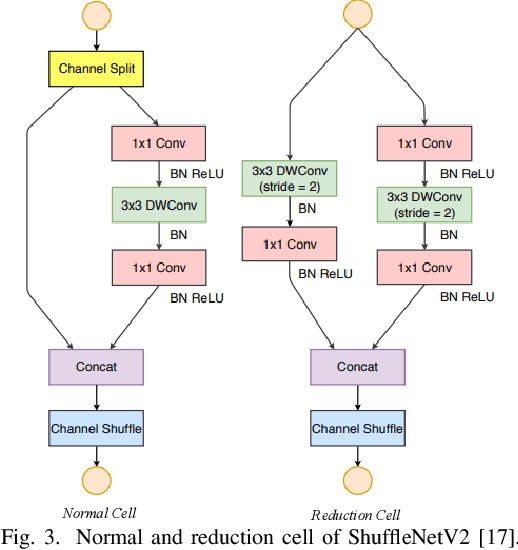
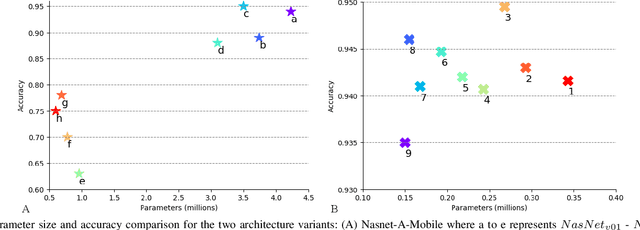
Automatic visual fire detection is used to complement traditional fire detection sensor systems (smoke/heat). In this work, we investigate different Convolutional Neural Network (CNN) architectures and their variants for the non-temporal real-time bounds detection of fire pixel regions in video (or still) imagery. Two reduced complexity compact CNN architectures (NasNet-A-OnFire and ShuffleNetV2-OnFire) are proposed through experimental analysis to optimise the computational efficiency for this task. The results improve upon the current state-of-the-art solution for fire detection, achieving an accuracy of 95% for full-frame binary classification and 97% for superpixel localisation. We notably achieve a classification speed up by a factor of 2.3x for binary classification and 1.3x for superpixel localisation, with runtime of 40 fps and 18 fps respectively, outperforming prior work in the field presenting an efficient, robust and real-time solution for fire region detection. Subsequent implementation on low-powered devices (Nvidia Xavier-NX, achieving 49 fps for full-frame classification via ShuffleNetV2-OnFire) demonstrates our architectures are suitable for various real-world deployment applications.
Not 3D Re-ID: a Simple Single Stream 2D Convolution for Robust Video Re-identification
Aug 17, 2020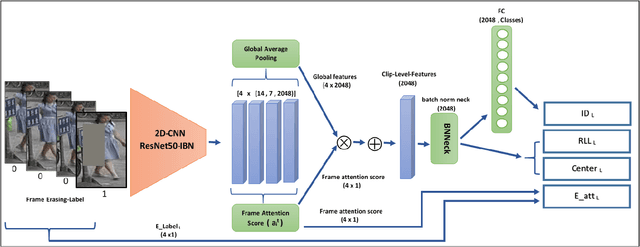

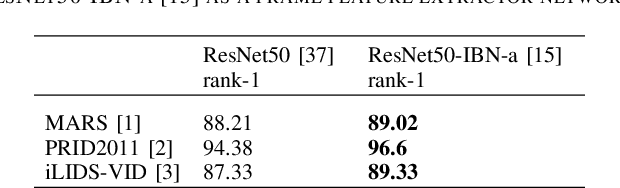
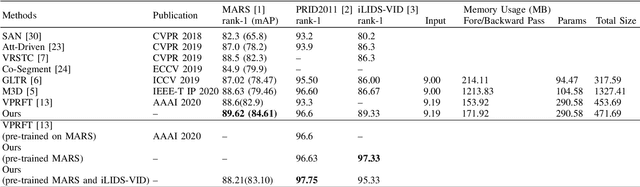
Video-based person re-identification has received increasing attention recently, as it plays an important role within surveillance video analysis. Video-based Re-ID is an expansion of earlier image-based re-identification methods by learning features from a video via multiple image frames for each person. Most contemporary video Re-ID methods utilise complex CNNbased network architectures using 3D convolution or multibranch networks to extract spatial-temporal video features. By contrast, in this paper, we illustrate superior performance from a simple single stream 2D convolution network leveraging the ResNet50-IBN architecture to extract frame-level features followed by temporal attention for clip level features. These clip level features can be generalised to extract video level features by averaging without any significant additional cost. Our approach uses best video Re-ID practice and transfer learning between datasets to outperform existing state-of-the-art approaches on the MARS, PRID2011 and iLIDS-VID datasets with 89:62%, 97:75%, 97:33% rank-1 accuracy respectively and with 84:61% mAP for MARS, without reliance on complex and memory intensive 3D convolutions or multi-stream networks architectures as found in other contemporary work. Conversely, our work shows that global features extracted by the 2D convolution network are a sufficient representation for robust state of the art video Re-ID.