 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Sub-component Level Segmentation and Classification for Anomaly Detection within Dual-Energy X-Ray Security Imagery
Oct 29, 2022X-ray baggage security screening is in widespread use and crucial to maintaining transport security for threat/anomaly detection tasks. The automatic detection of anomaly, which is concealed within cluttered and complex electronics/electrical items, using 2D X-ray imagery is of primary interest in recent years. We address this task by introducing joint object sub-component level segmentation and classification strategy using deep Convolution Neural Network architecture. The performance is evaluated over a dataset of cluttered X-ray baggage security imagery, consisting of consumer electrical and electronics items using variants of dual-energy X-ray imagery (pseudo-colour, high, low, and effective-Z). The proposed joint sub-component level segmentation and classification approach achieve ~99% true positive and ~5% false positive for anomaly detection task.
On Fine-Tuned Deep Features for Unsupervised Domain Adaptation
Oct 25, 2022Prior feature transformation based approaches to Unsupervised Domain Adaptation (UDA) employ the deep features extracted by pre-trained deep models without fine-tuning them on the specific source or target domain data for a particular domain adaptation task. In contrast, end-to-end learning based approaches optimise the pre-trained backbones and the customised adaptation modules simultaneously to learn domain-invariant features for UDA. In this work, we explore the potential of combining fine-tuned features and feature transformation based UDA methods for improved domain adaptation performance. Specifically, we integrate the prevalent progressive pseudo-labelling techniques into the fine-tuning framework to extract fine-tuned features which are subsequently used in a state-of-the-art feature transformation based domain adaptation method SPL (Selective Pseudo-Labeling). Thorough experiments with multiple deep models including ResNet-50/101 and DeiT-small/base are conducted to demonstrate the combination of fine-tuned features and SPL can achieve state-of-the-art performance on several benchmark datasets.
Does lossy image compression affect racial bias within face recognition?
Aug 16, 2022
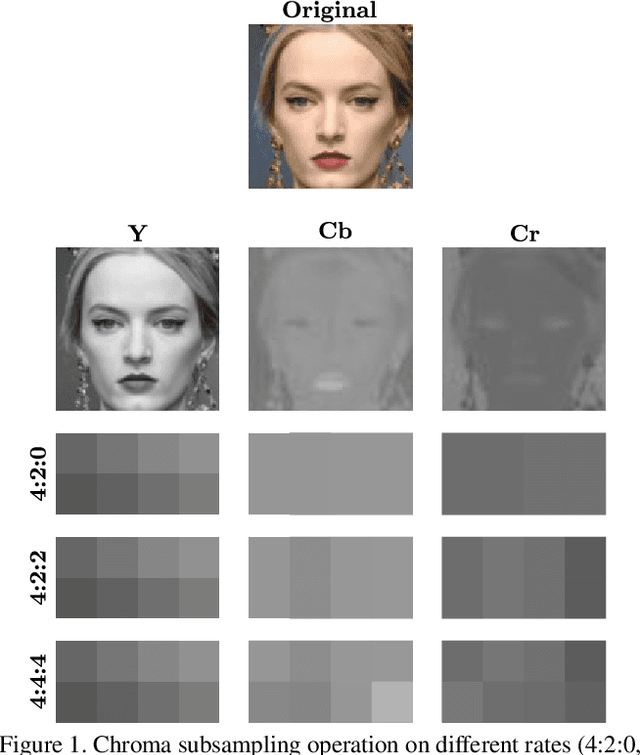
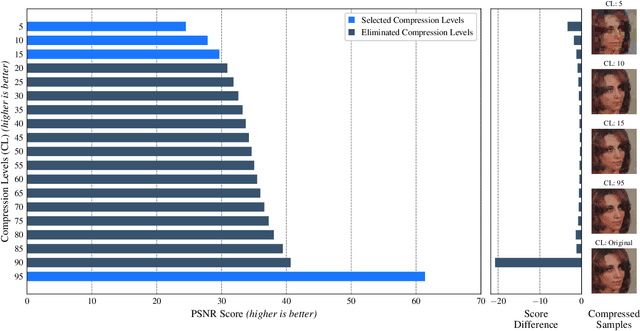
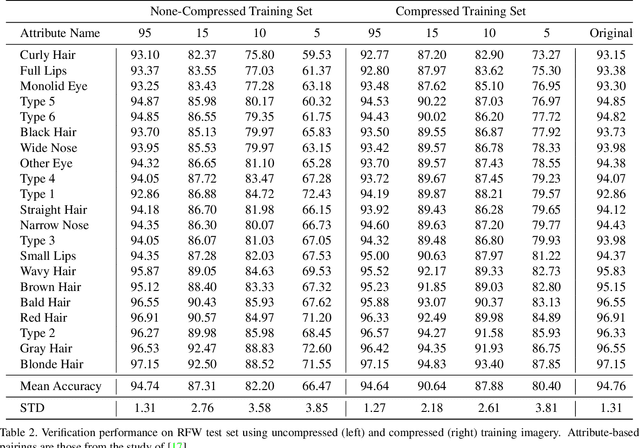
Yes - This study investigates the impact of commonplace lossy image compression on face recognition algorithms with regard to the racial characteristics of the subject. We adopt a recently proposed racial phenotype-based bias analysis methodology to measure the effect of varying levels of lossy compression across racial phenotype categories. Additionally, we determine the relationship between chroma-subsampling and race-related phenotypes for recognition performance. Prior work investigates the impact of lossy JPEG compression algorithm on contemporary face recognition performance. However, there is a gap in how this impact varies with different race-related inter-sectional groups and the cause of this impact. Via an extensive experimental setup, we demonstrate that common lossy image compression approaches have a more pronounced negative impact on facial recognition performance for specific racial phenotype categories such as darker skin tones (by up to 34.55\%). Furthermore, removing chroma-subsampling during compression improves the false matching rate (up to 15.95\%) across all phenotype categories affected by the compression, including darker skin tones, wide noses, big lips, and monolid eye categories. In addition, we outline the characteristics that may be attributable as the underlying cause of such phenomenon for lossy compression algorithms such as JPEG.
Evaluating Gaussian Grasp Maps for Generative Grasping Models
Jun 01, 2022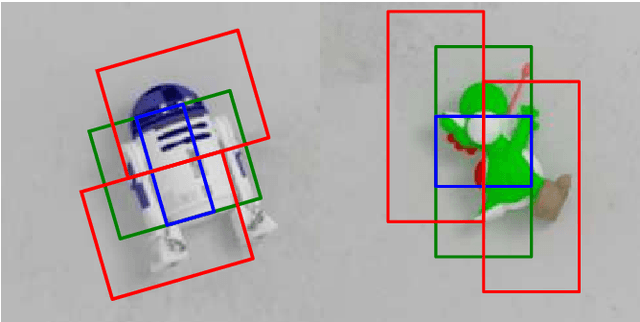
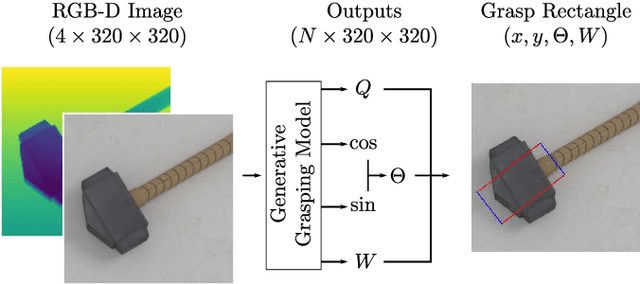
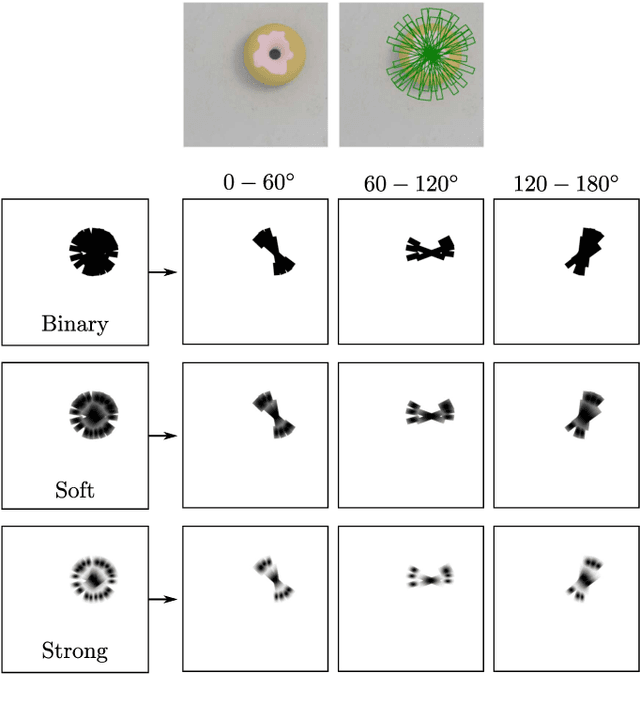

Generalising robotic grasping to previously unseen objects is a key task in general robotic manipulation. The current method for training many antipodal generative grasping models rely on a binary ground truth grasp map generated from the centre thirds of correctly labelled grasp rectangles. However, these binary maps do not accurately reflect the positions in which a robotic arm can correctly grasp a given object. We propose a continuous Gaussian representation of annotated grasps to generate ground truth training data which achieves a higher success rate on a simulated robotic grasping benchmark. Three modern generative grasping networks are trained with either binary or Gaussian grasp maps, along with recent advancements from the robotic grasping literature, such as discretisation of grasp angles into bins and an attentional loss function. Despite negligible difference according to the standard rectangle metric, Gaussian maps better reproduce the training data and therefore improve success rates when tested on the same simulated robot arm by avoiding collisions with the object: achieving 87.94\% accuracy. Furthermore, the best performing model is shown to operate with a high success rate when transferred to a real robotic arm, at high inference speeds, without the need for transfer learning. The system is then shown to be capable of performing grasps on an antagonistic physical object dataset benchmark.
Lost in Compression: the Impact of Lossy Image Compression on Variable Size Object Detection within Infrared Imagery
May 16, 2022



Lossy image compression strategies allow for more efficient storage and transmission of data by encoding data to a reduced form. This is essential enable training with larger datasets on less storage-equipped environments. However, such compression can cause severe decline in performance of deep Convolution Neural Network (CNN) architectures even when mild compression is applied and the resulting compressed imagery is visually identical. In this work, we apply the lossy JPEG compression method with six discrete levels of increasing compression {95, 75, 50, 15, 10, 5} to infrared band (thermal) imagery. Our study quantitatively evaluates the affect that increasing levels of lossy compression has upon the performance of characteristically diverse object detection architectures (Cascade-RCNN, FSAF and Deformable DETR) with respect to varying sizes of objects present in the dataset. When training and evaluating on uncompressed data as a baseline, we achieve maximal mean Average Precision (mAP) of 0.823 with Cascade R-CNN across the FLIR dataset, outperforming prior work. The impact of the lossy compression is more extreme at higher compression levels (15, 10, 5) across all three CNN architectures. However, re-training models on lossy compressed imagery notably ameliorated performances for all three CNN models with an average increment of ~76% (at higher compression level 5). Additionally, we demonstrate the relative sensitivity of differing object areas {tiny, small, medium, large} with respect to the compression level. We show that tiny and small objects are more sensitive to compression than medium and large objects. Overall, Cascade R-CNN attains the maximal mAP across most of the object area categories.
Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes
Nov 24, 2021
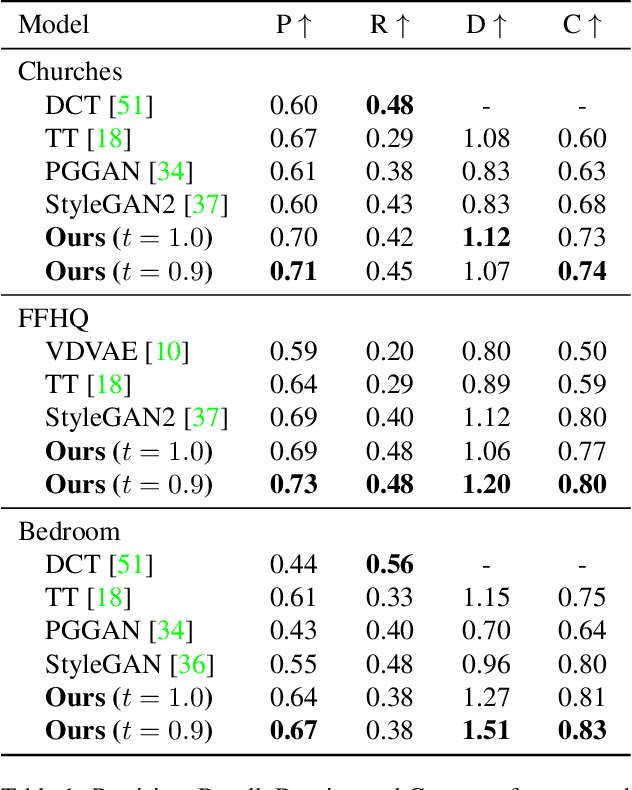
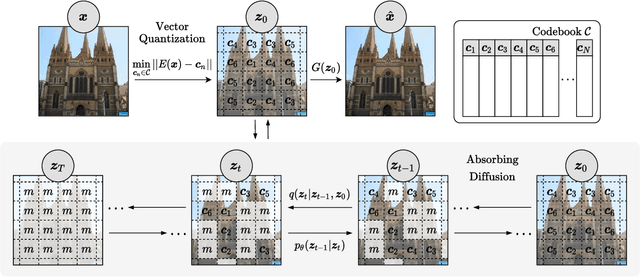
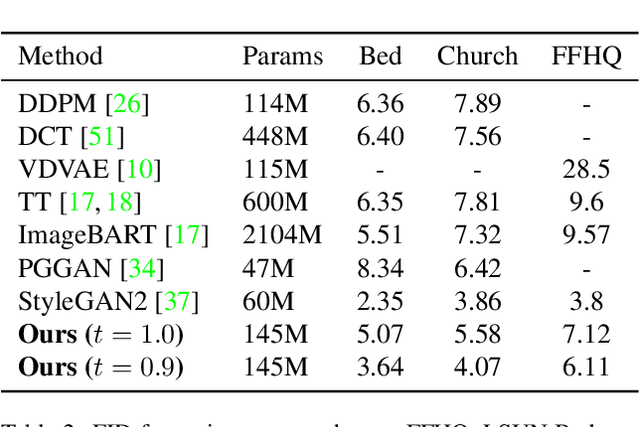
Whilst diffusion probabilistic models can generate high quality image content, key limitations remain in terms of both generating high-resolution imagery and their associated high computational requirements. Recent Vector-Quantized image models have overcome this limitation of image resolution but are prohibitively slow and unidirectional as they generate tokens via element-wise autoregressive sampling from the prior. By contrast, in this paper we propose a novel discrete diffusion probabilistic model prior which enables parallel prediction of Vector-Quantized tokens by using an unconstrained Transformer architecture as the backbone. During training, tokens are randomly masked in an order-agnostic manner and the Transformer learns to predict the original tokens. This parallelism of Vector-Quantized token prediction in turn facilitates unconditional generation of globally consistent high-resolution and diverse imagery at a fraction of the computational expense. In this manner, we can generate image resolutions exceeding that of the original training set samples whilst additionally provisioning per-image likelihood estimates (in a departure from generative adversarial approaches). Our approach achieves state-of-the-art results in terms of Density (LSUN Bedroom: 1.51; LSUN Churches: 1.12; FFHQ: 1.20) and Coverage (LSUN Bedroom: 0.83; LSUN Churches: 0.73; FFHQ: 0.80), and performs competitively on FID (LSUN Bedroom: 3.64; LSUN Churches: 4.07; FFHQ: 6.11) whilst offering advantages in terms of both computation and reduced training set requirements.
Progressively Select and Reject Pseudo-labelled Samples for Open-Set Domain Adaptation
Oct 25, 2021

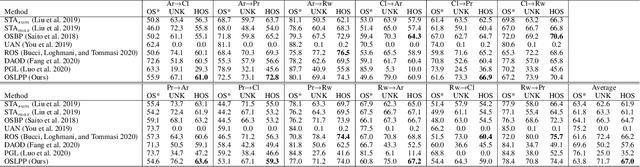
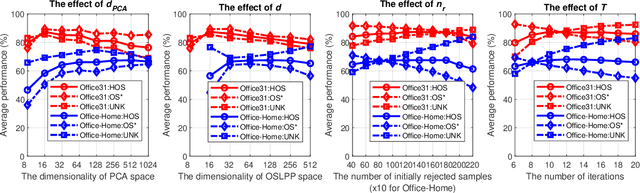
Domain adaptation solves image classification problems in the target domain by taking advantage of the labelled source data and unlabelled target data. Usually, the source and target domains share the same set of classes. As a special case, Open-Set Domain Adaptation (OSDA) assumes there exist additional classes in the target domain but not present in the source domain. To solve such a domain adaptation problem, our proposed method learns discriminative common subspaces for the source and target domains using a novel Open-Set Locality Preserving Projection (OSLPP) algorithm. The source and target domain data are aligned in the learned common spaces class-wisely. To handle the open-set classification problem, our method progressively selects target samples to be pseudo-labelled as known classes and rejects the outliers if they are detected as from unknown classes. The common subspace learning algorithm OSLPP simultaneously aligns the labelled source data and pseudo-labelled target data from known classes and pushes the rejected target data away from the known classes. The common subspace learning and the pseudo-labelled sample selection/rejection facilitate each other in an iterative learning framework and achieves state-of-the-art performance on benchmark datasets Office-31 and Office-Home with the average HOS of 87.4% and 67.0% respectively.
Measuring Hidden Bias within Face Recognition via Racial Phenotypes
Oct 19, 2021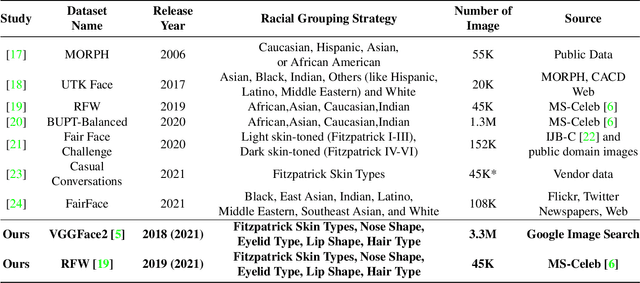
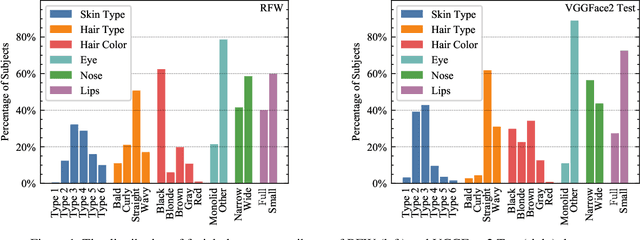

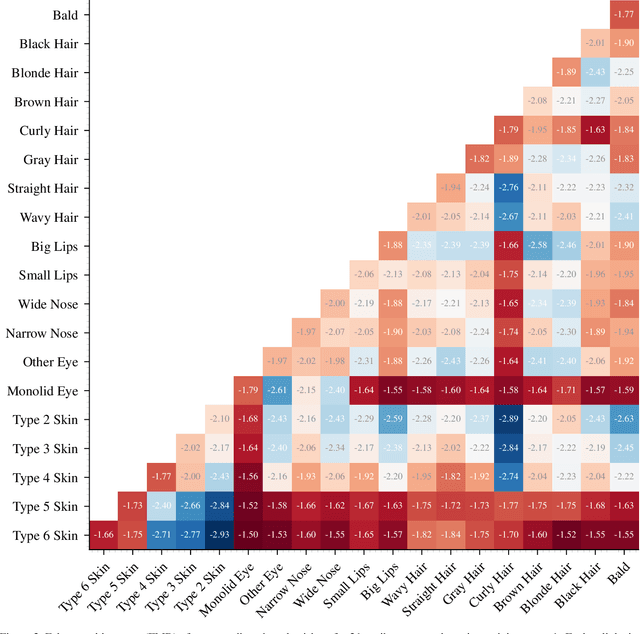
Recent work reports disparate performance for intersectional racial groups across face recognition tasks: face verification and identification. However, the definition of those racial groups has a significant impact on the underlying findings of such racial bias analysis. Previous studies define these groups based on either demographic information (e.g. African, Asian etc.) or skin tone (e.g. lighter or darker skins). The use of such sensitive or broad group definitions has disadvantages for bias investigation and subsequent counter-bias solutions design. By contrast, this study introduces an alternative racial bias analysis methodology via facial phenotype attributes for face recognition. We use the set of observable characteristics of an individual face where a race-related facial phenotype is hence specific to the human face and correlated to the racial profile of the subject. We propose categorical test cases to investigate the individual influence of those attributes on bias within face recognition tasks. We compare our phenotype-based grouping methodology with previous grouping strategies and show that phenotype-based groupings uncover hidden bias without reliance upon any potentially protected attributes or ill-defined grouping strategies. Furthermore, we contribute corresponding phenotype attribute category labels for two face recognition tasks: RFW for face verification and VGGFace2 (test set) for face identification.
Operationalizing Convolutional Neural Network Architectures for Prohibited Object Detection in X-Ray Imagery
Oct 10, 2021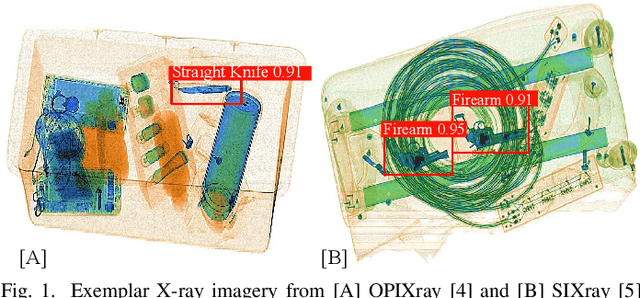
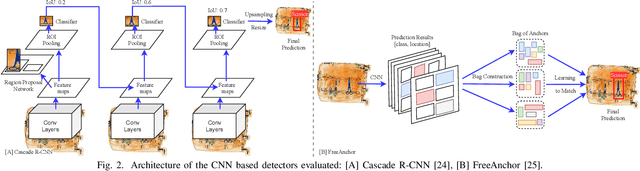
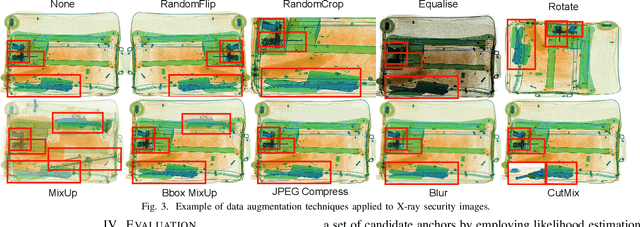
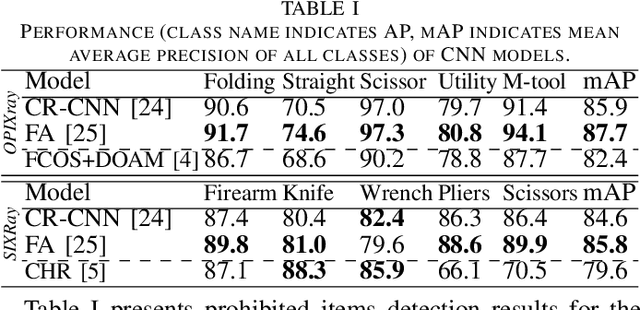
The recent advancement in deep Convolutional Neural Network (CNN) has brought insight into the automation of X-ray security screening for aviation security and beyond. Here, we explore the viability of two recent end-to-end object detection CNN architectures, Cascade R-CNN and FreeAnchor, for prohibited item detection by balancing processing time and the impact of image data compression from an operational viewpoint. Overall, we achieve maximal detection performance using a FreeAnchor architecture with a ResNet50 backbone, obtaining mean Average Precision (mAP) of 87.7 and 85.8 for using the OPIXray and SIXray benchmark datasets, showing superior performance over prior work on both. With fewer parameters and less training time, FreeAnchor achieves the highest detection inference speed of ~13 fps (3.9 ms per image). Furthermore, we evaluate the impact of lossy image compression upon detector performance. The CNN models display substantial resilience to the lossy compression, resulting in only a 1.1% decrease in mAP at the JPEG compression level of 50. Additionally, a thorough evaluation of data augmentation techniques is provided, including adaptions of MixUp and CutMix strategy as well as other standard transformations, further improving the detection accuracy.
On the impact of using X-ray energy response imagery for object detection via Convolutional Neural Networks
Aug 27, 2021
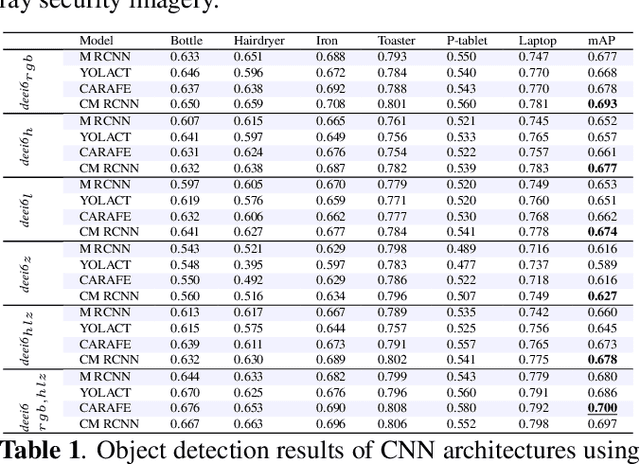
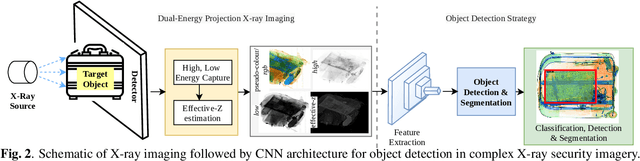
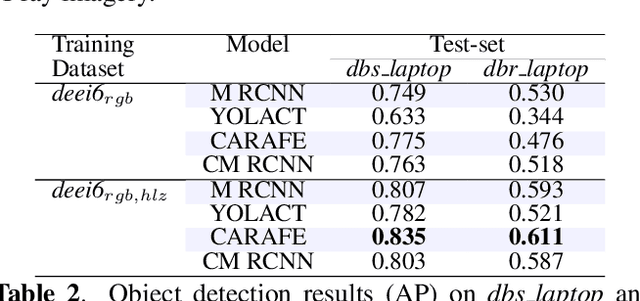
Automatic detection of prohibited items within complex and cluttered X-ray security imagery is essential to maintaining transport security, where prior work on automatic prohibited item detection focus primarily on pseudo-colour (rgb}) X-ray imagery. In this work we study the impact of variant X-ray imagery, i.e., X-ray energy response (high, low}) and effective-z compared to rgb, via the use of deep Convolutional Neural Networks (CNN) for the joint object detection and segmentation task posed within X-ray baggage security screening. We evaluate state-of-the-art CNN architectures (Mask R-CNN, YOLACT, CARAFE and Cascade Mask R-CNN) to explore the transferability of models trained with such 'raw' variant imagery between the varying X-ray security scanners that exhibits differing imaging geometries, image resolutions and material colour profiles. Overall, we observe maximal detection performance using CARAFE, attributable to training using combination of rgb, high, low, and effective-z X-ray imagery, obtaining 0.7 mean Average Precision (mAP) for a six class object detection problem. Our results also exhibit a remarkable degree of generalisation capability in terms of cross-scanner transferability (AP: 0.835/0.611) for a one class object detection problem by combining rgb, high, low, and effective-z imagery.