 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTingwen Liu
Towards Generalized Open Information Extraction
Nov 29, 2022
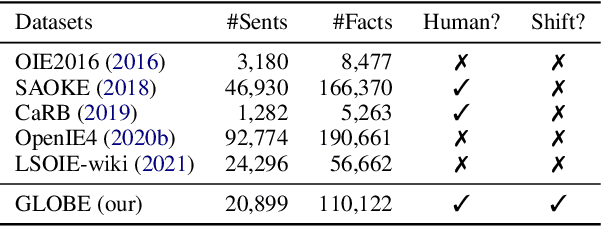
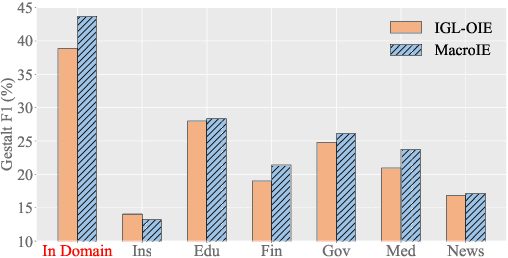
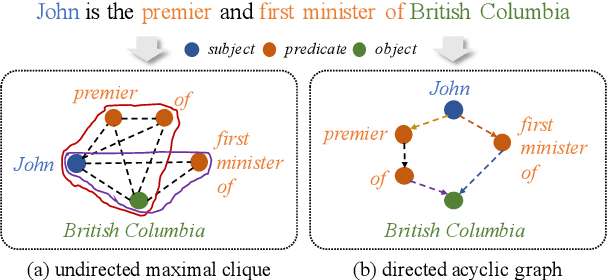
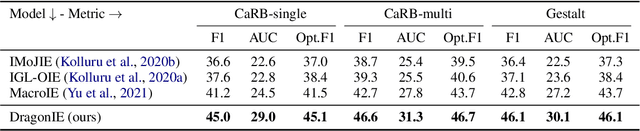
Open Information Extraction (OpenIE) facilitates the open-domain discovery of textual facts. However, the prevailing solutions evaluate OpenIE models on in-domain test sets aside from the training corpus, which certainly violates the initial task principle of domain-independence. In this paper, we propose to advance OpenIE towards a more realistic scenario: generalizing over unseen target domains with different data distributions from the source training domains, termed Generalized OpenIE. For this purpose, we first introduce GLOBE, a large-scale human-annotated multi-domain OpenIE benchmark, to examine the robustness of recent OpenIE models to domain shifts, and the relative performance degradation of up to 70% implies the challenges of generalized OpenIE. Then, we propose DragonIE, which explores a minimalist graph expression of textual fact: directed acyclic graph, to improve the OpenIE generalization. Extensive experiments demonstrate that DragonIE beats the previous methods in both in-domain and out-of-domain settings by as much as 6.0% in F1 score absolutely, but there is still ample room for improvement.
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022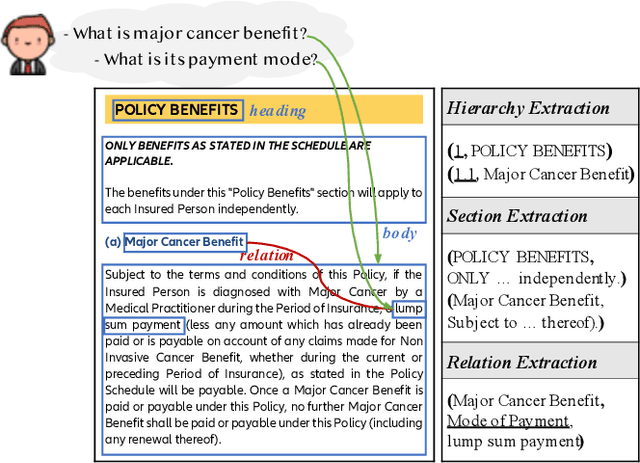
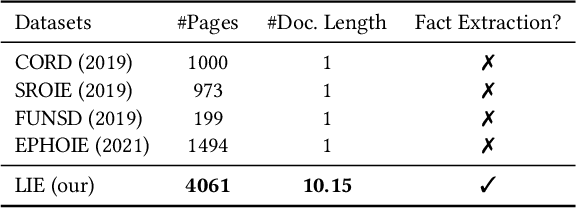

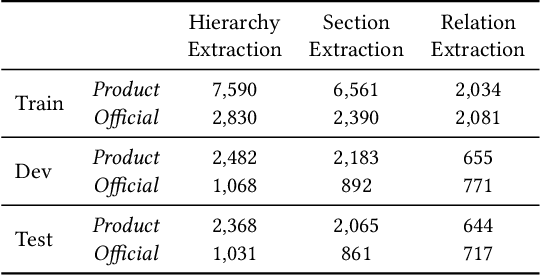
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
Cross-Domain Recommendation to Cold-Start Users via Variational Information Bottleneck
Mar 31, 2022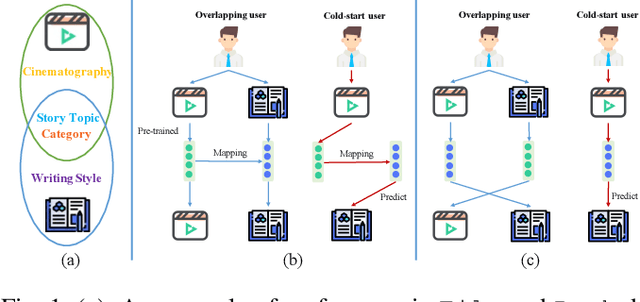
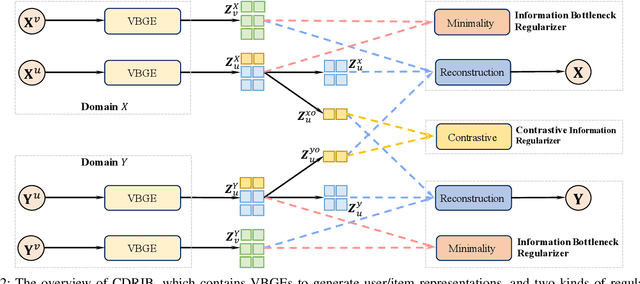
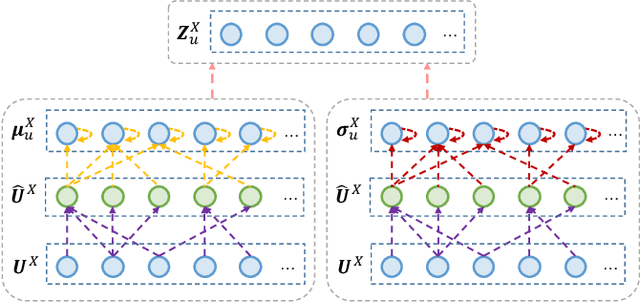
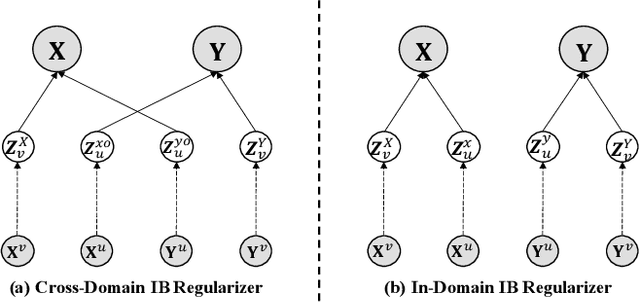
Recommender systems have been widely deployed in many real-world applications, but usually suffer from the long-standing user cold-start problem. As a promising way, Cross-Domain Recommendation (CDR) has attracted a surge of interest, which aims to transfer the user preferences observed in the source domain to make recommendations in the target domain. Previous CDR approaches mostly achieve the goal by following the Embedding and Mapping (EMCDR) idea which attempts to learn a mapping function to transfer the pre-trained user representations (embeddings) from the source domain into the target domain. However, they pre-train the user/item representations independently for each domain, ignoring to consider both domain interactions simultaneously. Therefore, the biased pre-trained representations inevitably involve the domain-specific information which may lead to negative impact to transfer information across domains. In this work, we consider a key point of the CDR task: what information needs to be shared across domains? To achieve the above idea, this paper utilizes the information bottleneck (IB) principle, and proposes a novel approach termed as CDRIB to enforce the representations encoding the domain-shared information. To derive the unbiased representations, we devise two IB regularizers to model the cross-domain/in-domain user-item interactions simultaneously and thereby CDRIB could consider both domain interactions jointly for de-biasing.
Document-Level Event Extraction via Human-Like Reading Process
Feb 07, 2022
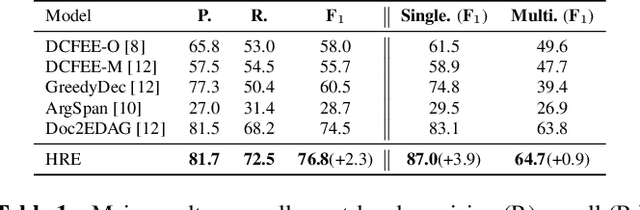
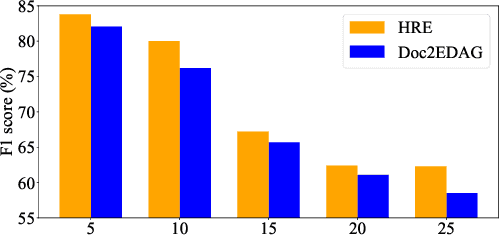
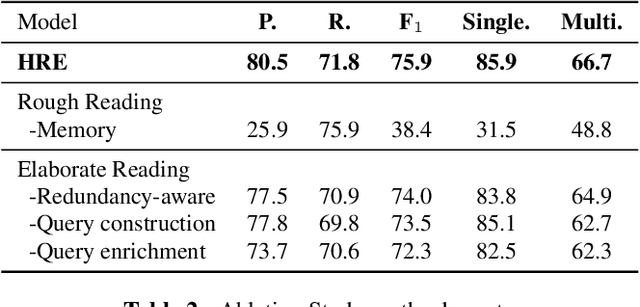
Document-level Event Extraction (DEE) is particularly tricky due to the two challenges it poses: scattering-arguments and multi-events. The first challenge means that arguments of one event record could reside in different sentences in the document, while the second one reflects one document may simultaneously contain multiple such event records. Motivated by humans' reading cognitive to extract information of interests, in this paper, we propose a method called HRE (Human Reading inspired Extractor for Document Events), where DEE is decomposed into these two iterative stages, rough reading and elaborate reading. Specifically, the first stage browses the document to detect the occurrence of events, and the second stage serves to extract specific event arguments. For each concrete event role, elaborate reading hierarchically works from sentences to characters to locate arguments across sentences, thus the scattering-arguments problem is tackled. Meanwhile, rough reading is explored in a multi-round manner to discover undetected events, thus the multi-events problem is handled. Experiment results show the superiority of HRE over prior competitive methods.
Improving Distantly-Supervised Named Entity Recognition with Self-Collaborative Denoising Learning
Oct 09, 2021
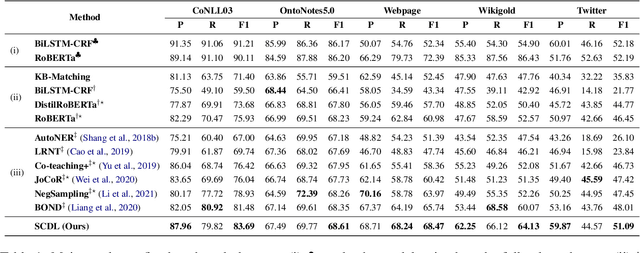
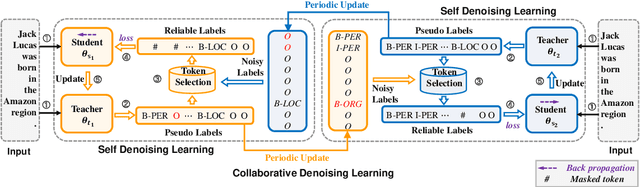
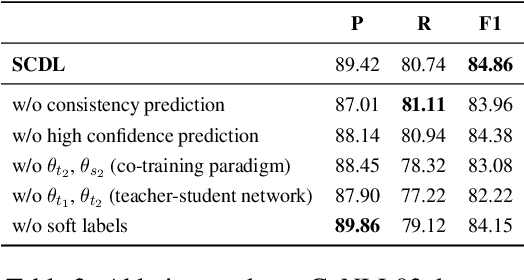
Distantly supervised named entity recognition (DS-NER) efficiently reduces labor costs but meanwhile intrinsically suffers from the label noise due to the strong assumption of distant supervision. Typically, the wrongly labeled instances comprise numbers of incomplete and inaccurate annotation noise, while most prior denoising works are only concerned with one kind of noise and fail to fully explore useful information in the whole training set. To address this issue, we propose a robust learning paradigm named Self-Collaborative Denoising Learning (SCDL), which jointly trains two teacher-student networks in a mutually-beneficial manner to iteratively perform noisy label refinery. Each network is designed to exploit reliable labels via self denoising, and two networks communicate with each other to explore unreliable annotations by collaborative denoising. Extensive experimental results on five real-world datasets demonstrate that SCDL is superior to state-of-the-art DS-NER denoising methods.
Deep Structural Point Process for Learning Temporal Interaction Networks
Jul 08, 2021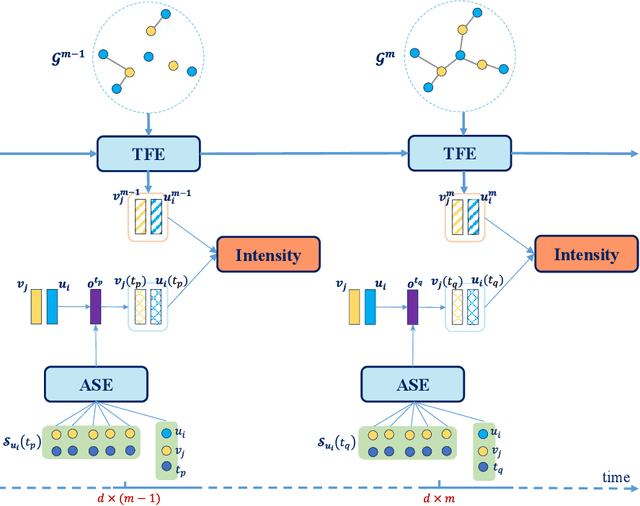

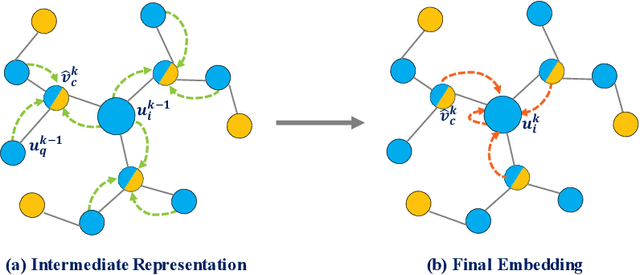
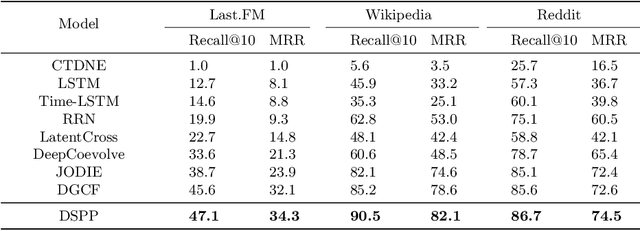
This work investigates the problem of learning temporal interaction networks. A temporal interaction network consists of a series of chronological interactions between users and items. Previous methods tackle this problem by using different variants of recurrent neural networks to model sequential interactions, which fail to consider the structural information of temporal interaction networks and inevitably lead to sub-optimal results. To this end, we propose a novel Deep Structural Point Process termed as DSPP for learning temporal interaction networks. DSPP simultaneously incorporates the topological structure and long-range dependency structure into our intensity function to enhance model expressiveness. To be specific, by using the topological structure as a strong prior, we first design a topological fusion encoder to obtain node embeddings. An attentive shift encoder is then developed to learn the long-range dependency structure between users and items in continuous time. The proposed two modules enable our model to capture the user-item correlation and dynamic influence in temporal interaction networks. DSPP is evaluated on three real-world datasets for both tasks of item prediction and time prediction. Extensive experiments demonstrate that our model achieves consistent and significant improvements over state-of-the-art baselines.
CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction
Jul 04, 2021
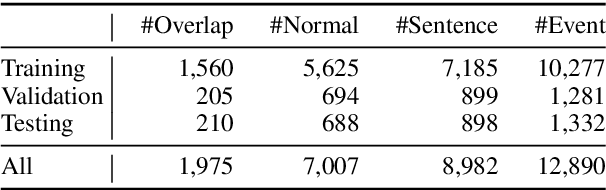
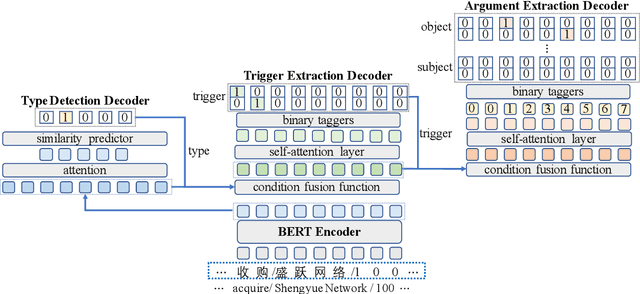
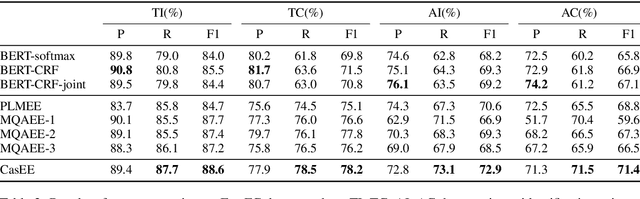
Event extraction (EE) is a crucial information extraction task that aims to extract event information in texts. Most existing methods assume that events appear in sentences without overlaps, which are not applicable to the complicated overlapping event extraction. This work systematically studies the realistic event overlapping problem, where a word may serve as triggers with several types or arguments with different roles. To tackle the above problem, we propose a novel joint learning framework with cascade decoding for overlapping event extraction, termed as CasEE. Particularly, CasEE sequentially performs type detection, trigger extraction and argument extraction, where the overlapped targets are extracted separately conditioned on the specific former prediction. All the subtasks are jointly learned in a framework to capture dependencies among the subtasks. The evaluation on a public event extraction benchmark FewFC demonstrates that CasEE achieves significant improvements on overlapping event extraction over previous competitive methods.
Discontinuous Named Entity Recognition as Maximal Clique Discovery
Jun 01, 2021
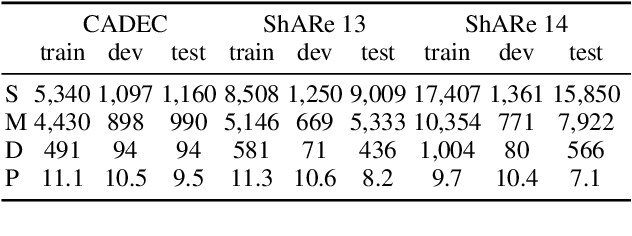
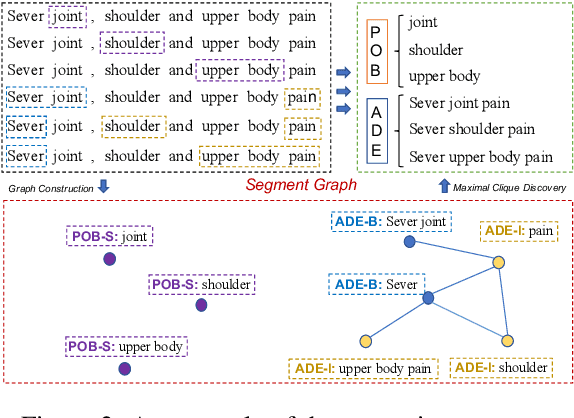
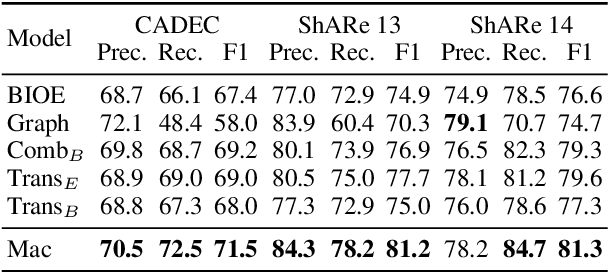
Named entity recognition (NER) remains challenging when entity mentions can be discontinuous. Existing methods break the recognition process into several sequential steps. In training, they predict conditioned on the golden intermediate results, while at inference relying on the model output of the previous steps, which introduces exposure bias. To solve this problem, we first construct a segment graph for each sentence, in which each node denotes a segment (a continuous entity on its own, or a part of discontinuous entities), and an edge links two nodes that belong to the same entity. The nodes and edges can be generated respectively in one stage with a grid tagging scheme and learned jointly using a novel architecture named Mac. Then discontinuous NER can be reformulated as a non-parametric process of discovering maximal cliques in the graph and concatenating the spans in each clique. Experiments on three benchmarks show that our method outperforms the state-of-the-art (SOTA) results, with up to 3.5 percentage points improvement on F1, and achieves 5x speedup over the SOTA model.
Bipartite Graph Embedding via Mutual Information Maximization
Dec 10, 2020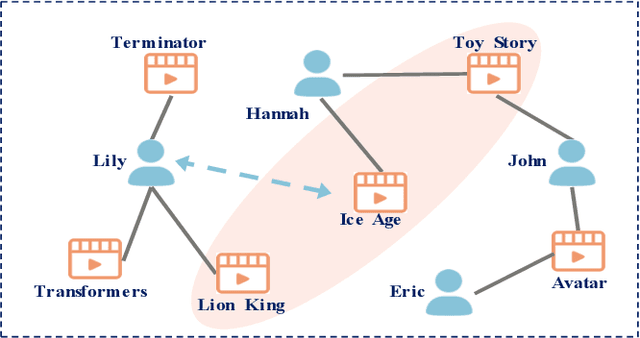
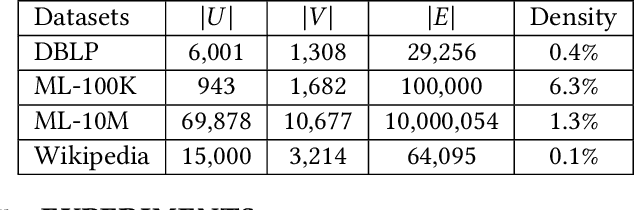
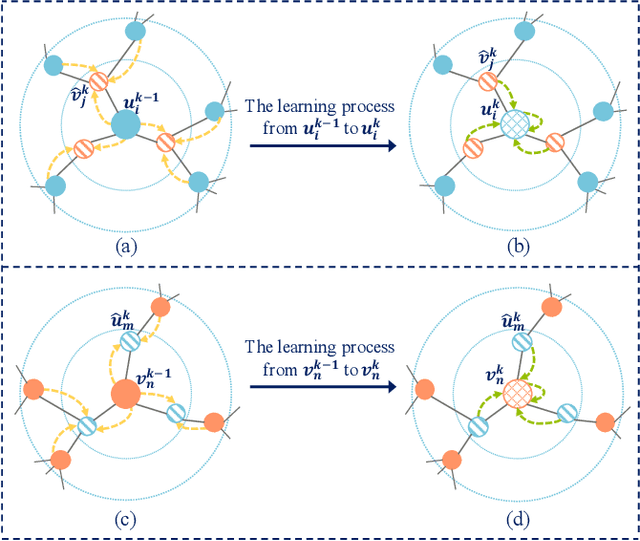
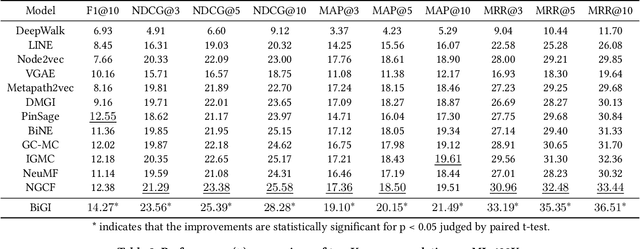
Bipartite graph embedding has recently attracted much attention due to the fact that bipartite graphs are widely used in various application domains. Most previous methods, which adopt random walk-based or reconstruction-based objectives, are typically effective to learn local graph structures. However, the global properties of bipartite graph, including community structures of homogeneous nodes and long-range dependencies of heterogeneous nodes, are not well preserved. In this paper, we propose a bipartite graph embedding called BiGI to capture such global properties by introducing a novel local-global infomax objective. Specifically, BiGI first generates a global representation which is composed of two prototype representations. BiGI then encodes sampled edges as local representations via the proposed subgraph-level attention mechanism. Through maximizing the mutual information between local and global representations, BiGI enables nodes in bipartite graph to be globally relevant. Our model is evaluated on various benchmark datasets for the tasks of top-K recommendation and link prediction. Extensive experiments demonstrate that BiGI achieves consistent and significant improvements over state-of-the-art baselines. Detailed analyses verify the high effectiveness of modeling the global properties of bipartite graph.
Few-Shot Event Detection with Prototypical Amortized Conditional Random Field
Dec 04, 2020
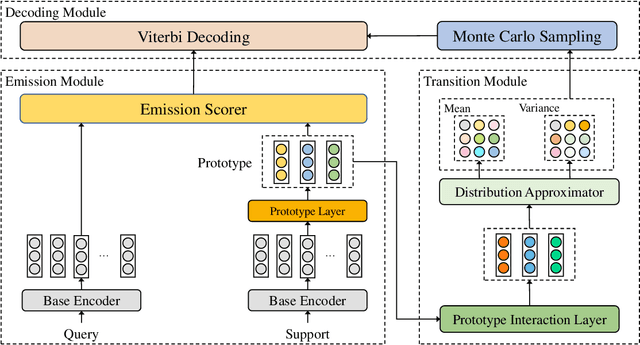
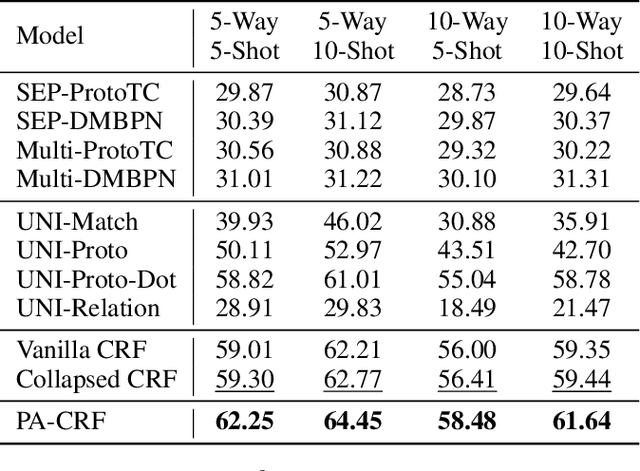
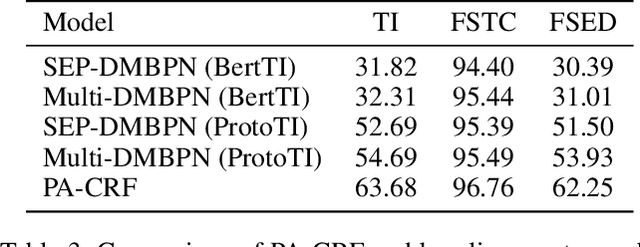
Event Detection, a fundamental task of Information Extraction, tends to struggle when it needs to recognize novel event types with a few samples, i.e. Few-Shot Event Detection (FSED). Previous identify-then-classify paradigm attempts to solve this problem in the pipeline manner but ignores the trigger discrepancy between event types, thus suffering from the error propagation. In this paper, we present a novel unified joint model which converts the task to a few-shot tagging problem with a double-part tagging scheme. To this end, we first design the Prototypical Amortized Conditional Random Field (PA-CRF) to model the label dependency in the few-shot scenario, which builds prototypical amortization networks to approximate the transition scores between labels based on the label prototypes. Then Gaussian distribution is introduced for the modeling of the transition scores in PA-CRF to alleviate the uncertain estimation resulting from insufficient data. We conduct experiments on the benchmark dataset FewEvent and the experimental results show that the tagging based methods are better than existing pipeline and joint learning methods. In addition, the proposed PA-CRF achieves the best results on the public dataset.