 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaIntegrator: Transformer Action Search for Symbolic Integration Proofs
Oct 03, 2024We present the first correct-by-construction learning-based system for step-by-step mathematical integration. The key idea is to learn a policy, represented by a GPT transformer model, which guides the search for the right mathematical integration rule, to be carried out by a symbolic solver. Concretely, we introduce a symbolic engine with axiomatically correct actions on mathematical expressions, as well as the first dataset for step-by-step integration. Our GPT-style transformer model, trained on this synthetic data, demonstrates strong generalization by surpassing its own data generator in accuracy and efficiency, using 50% fewer search steps. Our experimental results with SoTA LLMs also demonstrate that the standard approach of fine-tuning LLMs on a set of question-answer pairs is insufficient for solving this mathematical task. This motivates the importance of discovering creative methods for combining LLMs with symbolic reasoning engines, of which our work is an instance.
Scalable Inference of Symbolic Adversarial Examples
Jul 26, 2020

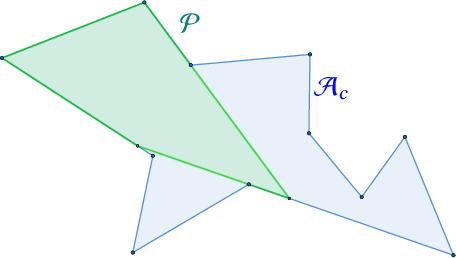
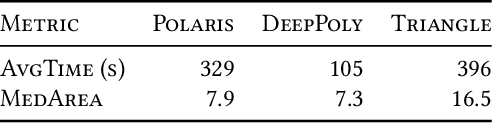
We present a novel method for generating symbolic adversarial examples: input regions guaranteed to only contain adversarial examples for the given neural network. These regions can generate real-world adversarial examples as they summarize trillions of adversarial examples. We theoretically show that computing optimal symbolic adversarial examples is computationally expensive. We present a method for approximating optimal examples in a scalable manner. Our method first selectively uses adversarial attacks to generate a candidate region and then prunes this region with hyperplanes that fit points obtained via specialized sampling. It iterates until arriving at a symbolic adversarial example for which it can prove, via state-of-the-art convex relaxation techniques, that the region only contains adversarial examples. Our experimental results demonstrate that our method is practically effective: it only needs a few thousand attacks to infer symbolic summaries guaranteed to contain $\approx 10^{258}$ adversarial examples.
Robustness Certification of Generative Models
Apr 30, 2020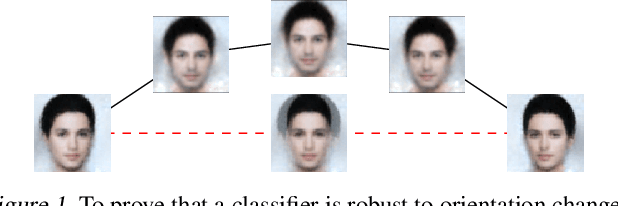
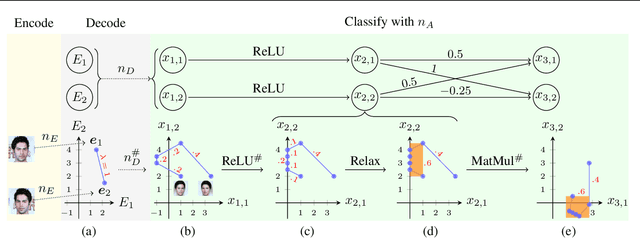
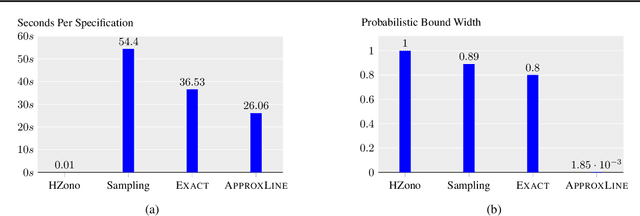
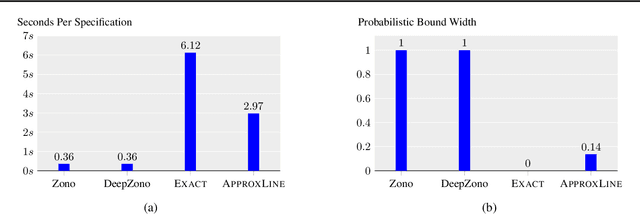
Generative neural networks can be used to specify continuous transformations between images via latent-space interpolation. However, certifying that all images captured by the resulting path in the image manifold satisfy a given property can be very challenging. This is because this set is highly non-convex, thwarting existing scalable robustness analysis methods, which are often based on convex relaxations. We present ApproxLine, a scalable certification method that successfully verifies non-trivial specifications involving generative models and classifiers. ApproxLine can provide both sound deterministic and probabilistic guarantees, by capturing either infinite non-convex sets of neural network activation vectors or distributions over such sets. We show that ApproxLine is practically useful and can verify interesting interpolations in the networks latent space.