 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThorsten Kurth
Hierarchical Roofline Performance Analysis for Deep Learning Applications
Sep 22, 2020
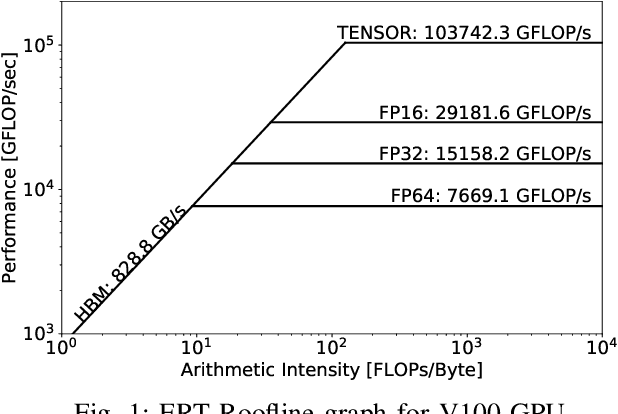
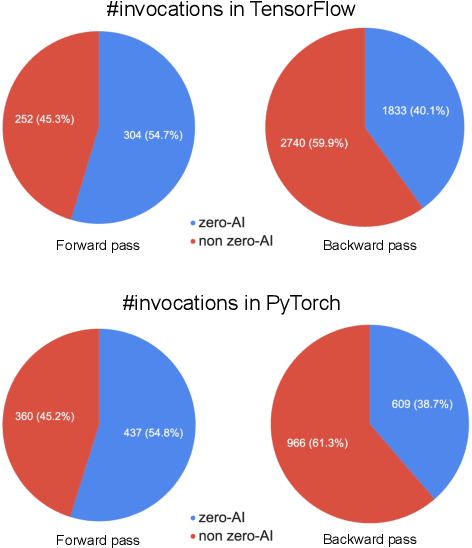
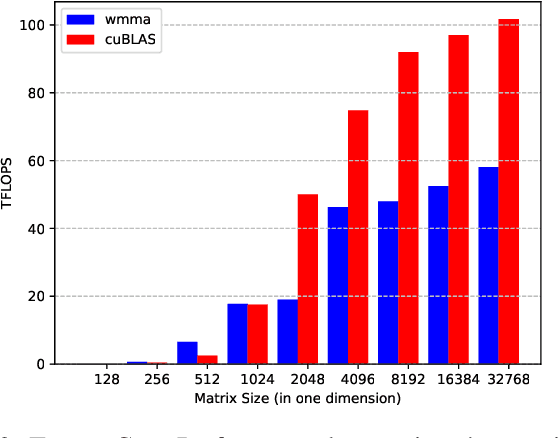
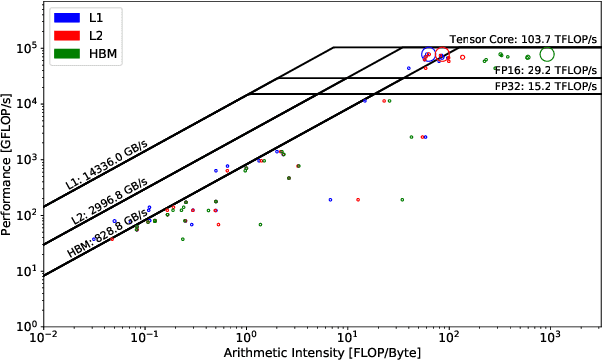
This paper presents a practical methodology for collecting performance data necessary to conduct hierarchical Roofline analysis on NVIDIA GPUs. It discusses the extension of the Empirical Roofline Toolkit for broader support of a range of data precisions and Tensor Core support and introduces a Nsight Compute based method to accurately collect application performance information. This methodology allows for automated machine characterization and application characterization for Roofline analysis across the entire memory hierarchy on NVIDIA GPUs, and it is validated by a complex deep learning application used for climate image segmentation. We use two versions of the code, in TensorFlow and PyTorch respectively, to demonstrate the use and effectiveness of this methodology. We highlight how the application utilizes the compute and memory capabilities on the GPU and how the implementation and performance differ in two deep learning frameworks.
Time-Based Roofline for Deep Learning Performance Analysis
Sep 22, 2020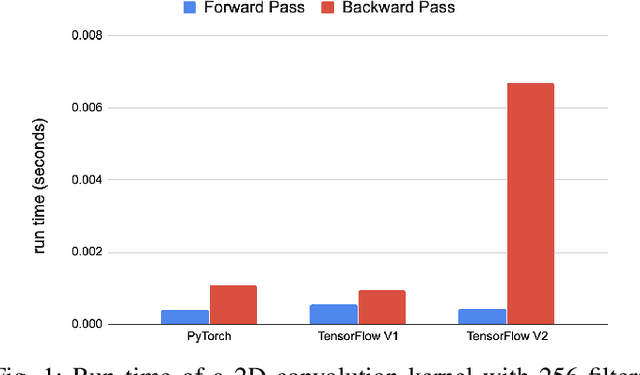
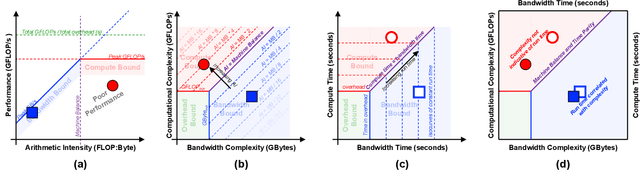
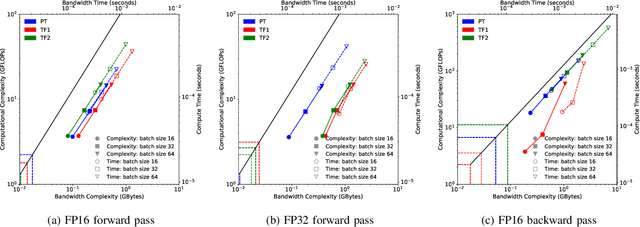
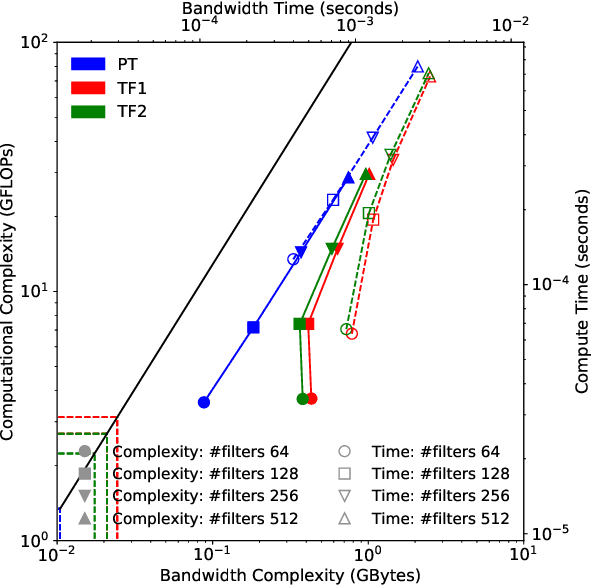
Deep learning applications are usually very compute-intensive and require a long run time for training and inference. This has been tackled by researchers from both hardware and software sides, and in this paper, we propose a Roofline-based approach to performance analysis to facilitate the optimization of these applications. This approach is an extension of the Roofline model widely used in traditional high-performance computing applications, and it incorporates both compute/bandwidth complexity and run time in its formulae to provide insights into deep learning-specific characteristics. We take two sets of representative kernels, 2D convolution and long short-term memory, to validate and demonstrate the use of this new approach, and investigate how arithmetic intensity, cache locality, auto-tuning, kernel launch overhead, and Tensor Core usage can affect performance. Compared to the common ad-hoc approach, this study helps form a more systematic way to analyze code performance and identify optimization opportunities for deep learning applications.
Highly-scalable, physics-informed GANs for learning solutions of stochastic PDEs
Oct 29, 2019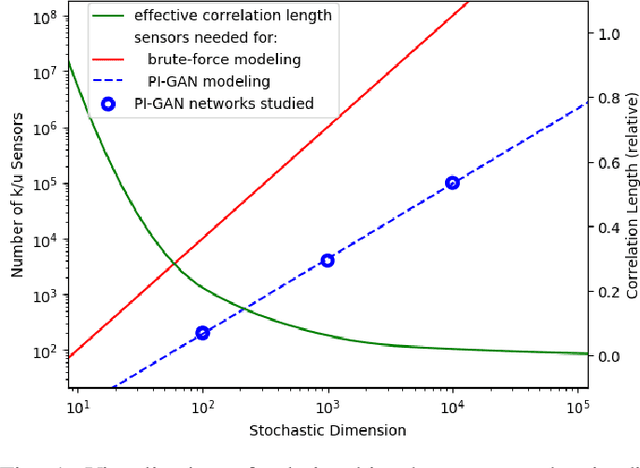
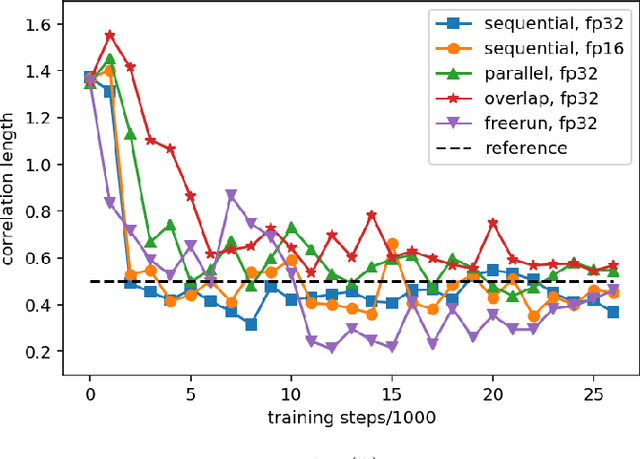
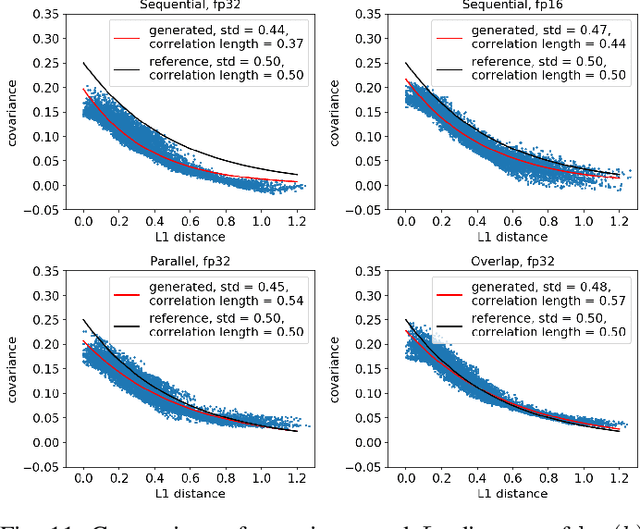
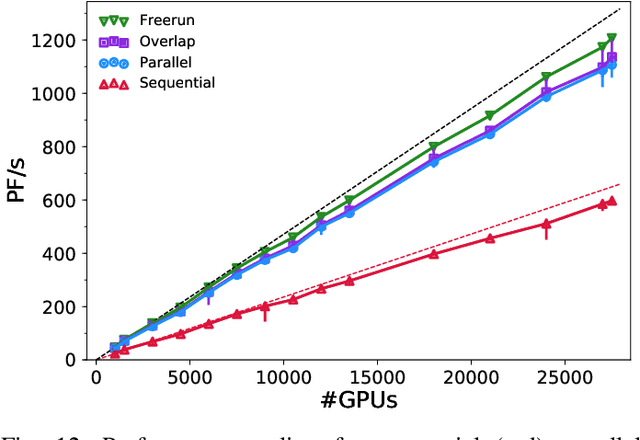
Uncertainty quantification for forward and inverse problems is a central challenge across physical and biomedical disciplines. We address this challenge for the problem of modeling subsurface flow at the Hanford Site by combining stochastic computational models with observational data using physics-informed GAN models. The geographic extent, spatial heterogeneity, and multiple correlation length scales of the Hanford Site require training a computationally intensive GAN model to thousands of dimensions. We develop a hierarchical scheme for exploiting domain parallelism, map discriminators and generators to multiple GPUs, and employ efficient communication schemes to ensure training stability and convergence. We developed a highly optimized implementation of this scheme that scales to 27,500 NVIDIA Volta GPUs and 4584 nodes on the Summit supercomputer with a 93.1% scaling efficiency, achieving peak and sustained half-precision rates of 1228 PF/s and 1207 PF/s.
Deep Neural Networks for Physics Analysis on low-level whole-detector data at the LHC
Nov 29, 2017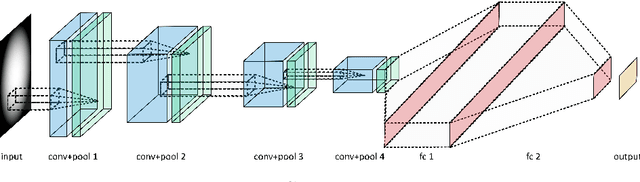
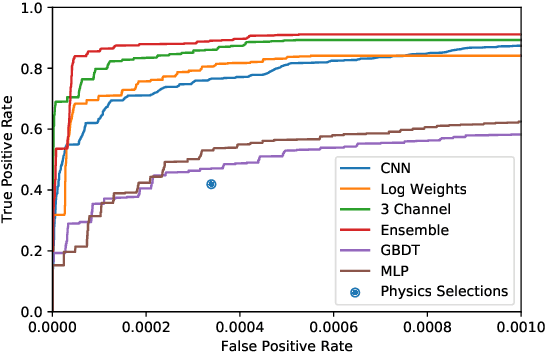
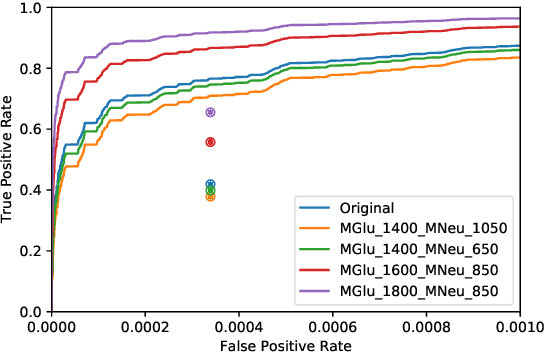
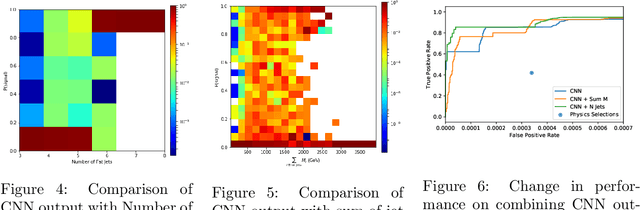
There has been considerable recent activity applying deep convolutional neural nets (CNNs) to data from particle physics experiments. Current approaches on ATLAS/CMS have largely focussed on a subset of the calorimeter, and for identifying objects or particular particle types. We explore approaches that use the entire calorimeter, combined with track information, for directly conducting physics analyses: i.e. classifying events as known-physics background or new-physics signals. We use an existing RPV-Supersymmetry analysis as a case study and explore CNNs on multi-channel, high-resolution sparse images: applied on GPU and multi-node CPU architectures (including Knights Landing (KNL) Xeon Phi nodes) on the Cori supercomputer at NERSC.
Deep Learning at 15PF: Supervised and Semi-Supervised Classification for Scientific Data
Aug 17, 2017
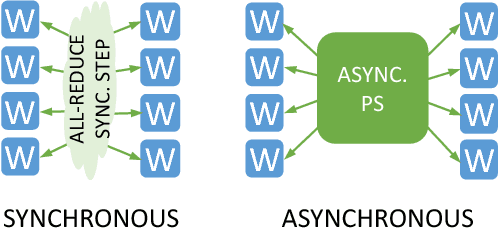
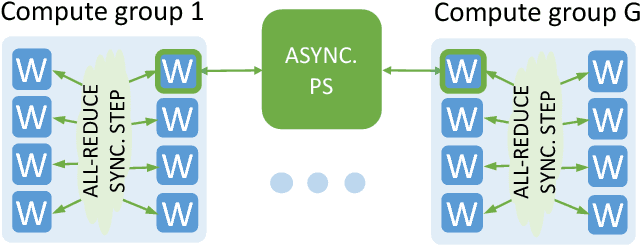
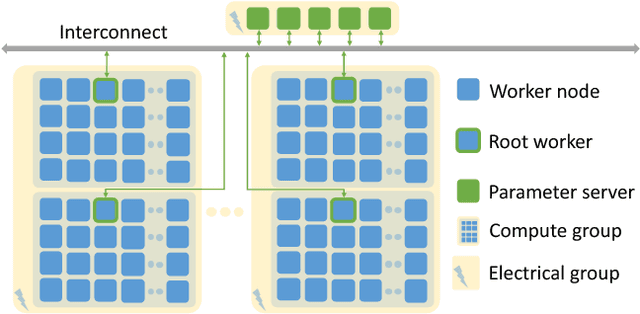
This paper presents the first, 15-PetaFLOP Deep Learning system for solving scientific pattern classification problems on contemporary HPC architectures. We develop supervised convolutional architectures for discriminating signals in high-energy physics data as well as semi-supervised architectures for localizing and classifying extreme weather in climate data. Our Intelcaffe-based implementation obtains $\sim$2TFLOP/s on a single Cori Phase-II Xeon-Phi node. We use a hybrid strategy employing synchronous node-groups, while using asynchronous communication across groups. We use this strategy to scale training of a single model to $\sim$9600 Xeon-Phi nodes; obtaining peak performance of 11.73-15.07 PFLOP/s and sustained performance of 11.41-13.27 PFLOP/s. At scale, our HEP architecture produces state-of-the-art classification accuracy on a dataset with 10M images, exceeding that achieved by selections on high-level physics-motivated features. Our semi-supervised architecture successfully extracts weather patterns in a 15TB climate dataset. Our results demonstrate that Deep Learning can be optimized and scaled effectively on many-core, HPC systems.