 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThomas Tanay
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020
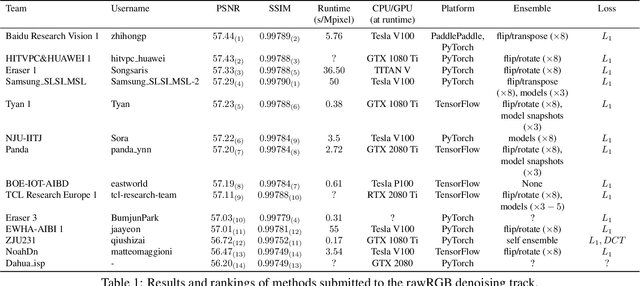
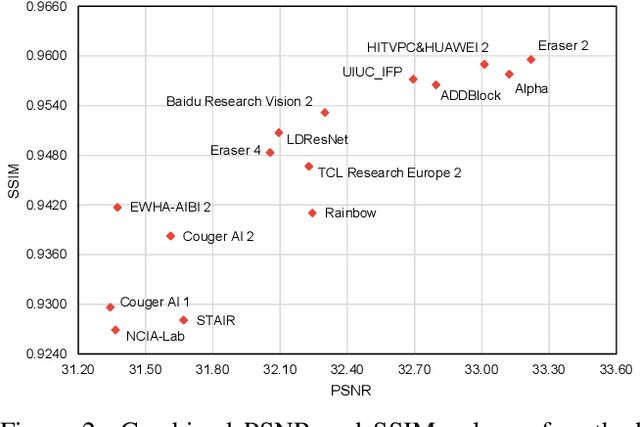
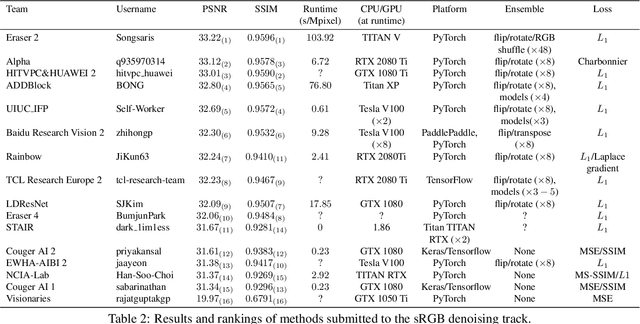
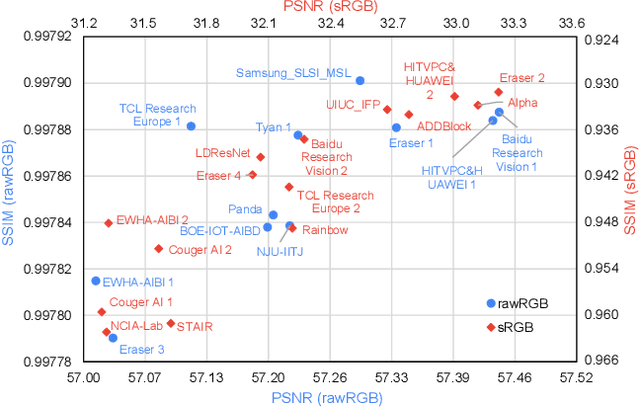
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Multiple-Identity Image Attacks Against Face-based Identity Verification
Jun 20, 2019

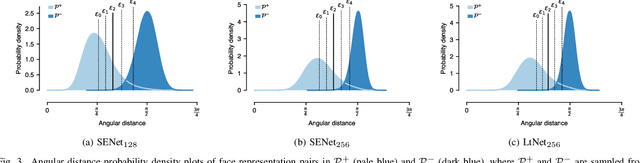
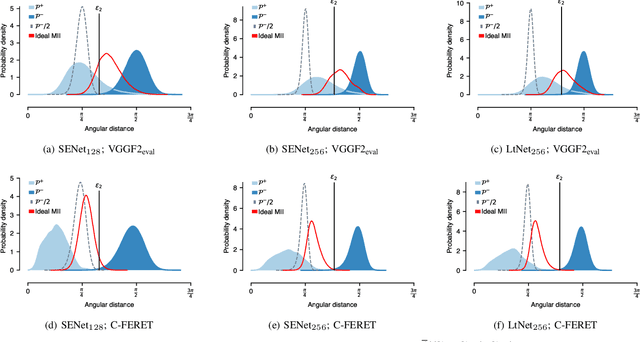
Facial verification systems are vulnerable to poisoning attacks that make use of multiple-identity images (MIIs)---face images stored in a database that resemble multiple persons, such that novel images of any of the constituent persons are verified as matching the identity of the MII. Research on this mode of attack has focused on defence by detection, with no explanation as to why the vulnerability exists. New quantitative results are presented that support an explanation in terms of the geometry of the representations spaces used by the verification systems. In the spherical geometry of those spaces, the angular distance distributions of matching and non-matching pairs of face representations are only modestly separated, approximately centred at 90 and 40-60 degrees, respectively. This is sufficient for open-set verification on normal data but provides an opportunity for MII attacks. Our analysis considers ideal MII algorithms, demonstrating that, if realisable, they would deliver faces roughly 45 degrees from their constituent faces, thus classed as matching them. We study the performance of three methods for MII generation---gallery search, image space morphing, and representation space inversion---and show that the latter two realise the ideal well enough to produce effective attacks, while the former could succeed but only with an implausibly large gallery to search. Gallery search and inversion MIIs depend on having access to a facial comparator, for optimisation, but our results show that these attacks can still be effective when attacking disparate comparators, thus securing a deployed comparator is an insufficient defence.
Batch Normalization is a Cause of Adversarial Vulnerability
May 29, 2019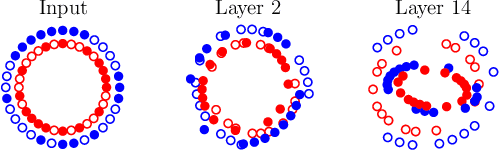

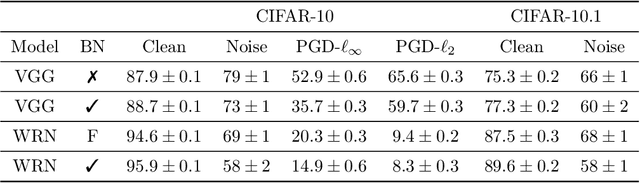
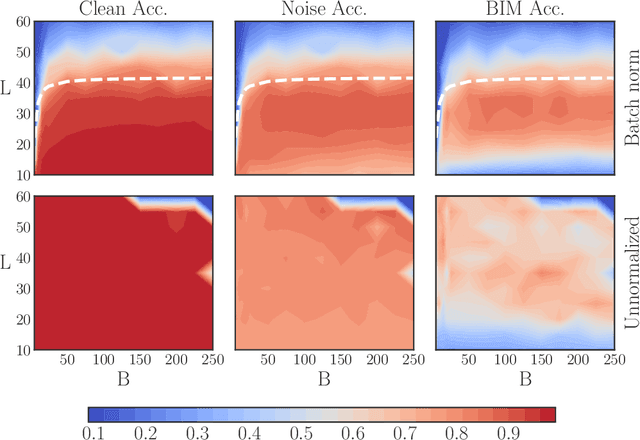
Batch normalization (batch norm) is often used in an attempt to stabilize and accelerate training in deep neural networks. In many cases it indeed decreases the number of parameter updates required to achieve low training error. However, it also reduces robustness to small adversarial input perturbations and noise by double-digit percentages, as we show on five standard datasets. Furthermore, substituting weight decay for batch norm is sufficient to nullify the relationship between adversarial vulnerability and the input dimension. Our work is consistent with a mean-field analysis that found that batch norm causes exploding gradients.
Adversarial Training Versus Weight Decay
Jul 23, 2018



Performance-critical machine learning models should be robust to input perturbations not seen during training. Adversarial training is a method for improving a model's robustness to some perturbations by including them in the training process, but this tends to exacerbate other vulnerabilities of the model. The adversarial training framework has the effect of translating the data with respect to the cost function, while weight decay has a scaling effect. Although weight decay could be considered a crude regularization technique, it appears superior to adversarial training as it remains stable over a broader range of regimes and reduces all generalization errors. Equipped with these abstractions, we provide key baseline results and methodology for characterizing robustness. The two approaches can be combined to yield one small model that demonstrates good robustness to several white-box attacks associated with different metrics.
A New Angle on L2 Regularization
Jun 28, 2018Imagine two high-dimensional clusters and a hyperplane separating them. Consider in particular the angle between: the direction joining the two clusters' centroids and the normal to the hyperplane. In linear classification, this angle depends on the level of L2 regularization used. Can you explain why?
Built-in Vulnerabilities to Imperceptible Adversarial Perturbations
Jun 19, 2018



Designing models that are robust to small adversarial perturbations of their inputs has proven remarkably difficult. In this work we show that the reverse problem---making models more vulnerable---is surprisingly easy. After presenting some proofs of concept on MNIST, we introduce a generic tilting attack that injects vulnerabilities into the linear layers of pre-trained networks without affecting their performance on natural data. We illustrate this attack on a multilayer perceptron trained on SVHN and use it to design a stand-alone adversarial module which we call a steganogram decoder. Finally, we show on CIFAR-10 that a state-of-the-art network can be trained to misclassify images in the presence of imperceptible backdoor signals. These different results suggest that adversarial perturbations are not always informative of the true features used by a model.
A Boundary Tilting Persepective on the Phenomenon of Adversarial Examples
Aug 27, 2016


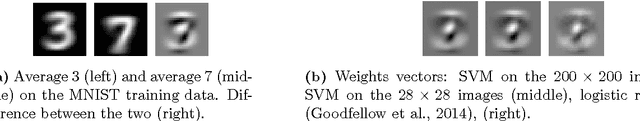
Deep neural networks have been shown to suffer from a surprising weakness: their classification outputs can be changed by small, non-random perturbations of their inputs. This adversarial example phenomenon has been explained as originating from deep networks being "too linear" (Goodfellow et al., 2014). We show here that the linear explanation of adversarial examples presents a number of limitations: the formal argument is not convincing, linear classifiers do not always suffer from the phenomenon, and when they do their adversarial examples are different from the ones affecting deep networks. We propose a new perspective on the phenomenon. We argue that adversarial examples exist when the classification boundary lies close to the submanifold of sampled data, and present a mathematical analysis of this new perspective in the linear case. We define the notion of adversarial strength and show that it can be reduced to the deviation angle between the classifier considered and the nearest centroid classifier. Then, we show that the adversarial strength can be made arbitrarily high independently of the classification performance due to a mechanism that we call boundary tilting. This result leads us to defining a new taxonomy of adversarial examples. Finally, we show that the adversarial strength observed in practice is directly dependent on the level of regularisation used and the strongest adversarial examples, symptomatic of overfitting, can be avoided by using a proper level of regularisation.