 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThomas S. Huang
Robust Emotion Recognition from Low Quality and Low Bit Rate Video: A Deep Learning Approach
Sep 10, 2017

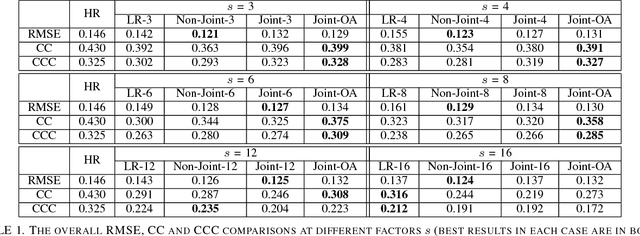
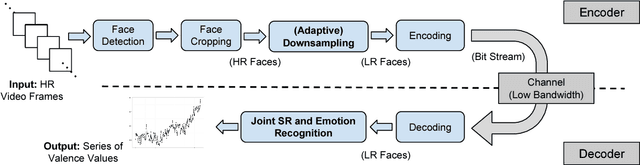
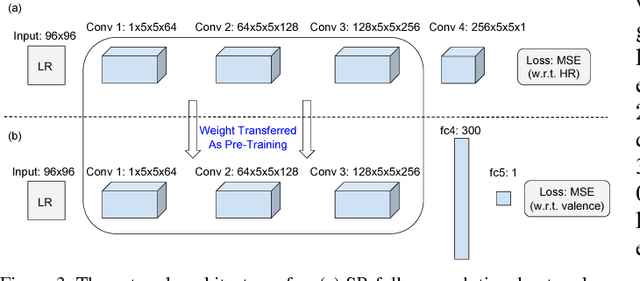
Emotion recognition from facial expressions is tremendously useful, especially when coupled with smart devices and wireless multimedia applications. However, the inadequate network bandwidth often limits the spatial resolution of the transmitted video, which will heavily degrade the recognition reliability. We develop a novel framework to achieve robust emotion recognition from low bit rate video. While video frames are downsampled at the encoder side, the decoder is embedded with a deep network model for joint super-resolution (SR) and recognition. Notably, we propose a novel max-mix training strategy, leading to a single "One-for-All" model that is remarkably robust to a vast range of downsampling factors. That makes our framework well adapted for the varied bandwidths in real transmission scenarios, without hampering scalability or efficiency. The proposed framework is evaluated on the AVEC 2016 benchmark, and demonstrates significantly improved stand-alone recognition performance, as well as rate-distortion (R-D) performance, than either directly recognizing from LR frames, or separating SR and recognition.
Discriminative Similarity for Clustering and Semi-Supervised Learning
Sep 05, 2017Similarity-based clustering and semi-supervised learning methods separate the data into clusters or classes according to the pairwise similarity between the data, and the pairwise similarity is crucial for their performance. In this paper, we propose a novel discriminative similarity learning framework which learns discriminative similarity for either data clustering or semi-supervised learning. The proposed framework learns classifier from each hypothetical labeling, and searches for the optimal labeling by minimizing the generalization error of the learned classifiers associated with the hypothetical labeling. Kernel classifier is employed in our framework. By generalization analysis via Rademacher complexity, the generalization error bound for the kernel classifier learned from hypothetical labeling is expressed as the sum of pairwise similarity between the data from different classes, parameterized by the weights of the kernel classifier. Such pairwise similarity serves as the discriminative similarity for the purpose of clustering and semi-supervised learning, and discriminative similarity with similar form can also be induced by the integrated squared error bound for kernel density classification. Based on the discriminative similarity induced by the kernel classifier, we propose new clustering and semi-supervised learning methods.
On the Suboptimality of Proximal Gradient Descent for $\ell^{0}$ Sparse Approximation
Sep 05, 2017We study the proximal gradient descent (PGD) method for $\ell^{0}$ sparse approximation problem as well as its accelerated optimization with randomized algorithms in this paper. We first offer theoretical analysis of PGD showing the bounded gap between the sub-optimal solution by PGD and the globally optimal solution for the $\ell^{0}$ sparse approximation problem under conditions weaker than Restricted Isometry Property widely used in compressive sensing literature. Moreover, we propose randomized algorithms to accelerate the optimization by PGD using randomized low rank matrix approximation (PGD-RMA) and randomized dimension reduction (PGD-RDR). Our randomized algorithms substantially reduces the computation cost of the original PGD for the $\ell^{0}$ sparse approximation problem, and the resultant sub-optimal solution still enjoys provable suboptimality, namely, the sub-optimal solution to the reduced problem still has bounded gap to the globally optimal solution to the original problem.
Fast Generation for Convolutional Autoregressive Models
Apr 20, 2017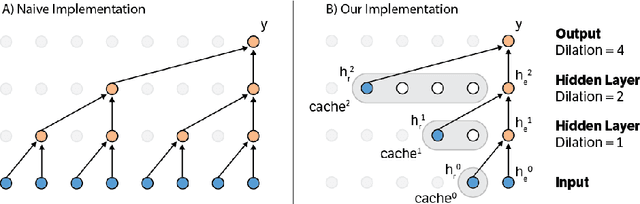
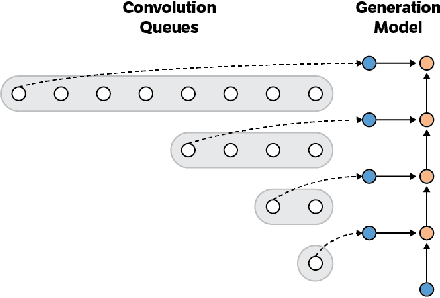
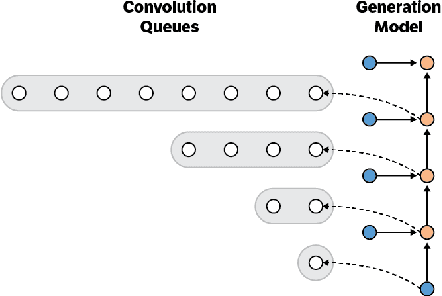
Convolutional autoregressive models have recently demonstrated state-of-the-art performance on a number of generation tasks. While fast, parallel training methods have been crucial for their success, generation is typically implemented in a na\"{i}ve fashion where redundant computations are unnecessarily repeated. This results in slow generation, making such models infeasible for production environments. In this work, we describe a method to speed up generation in convolutional autoregressive models. The key idea is to cache hidden states to avoid redundant computation. We apply our fast generation method to the Wavenet and PixelCNN++ models and achieve up to $21\times$ and $183\times$ speedups respectively.
Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition?
Mar 16, 2017
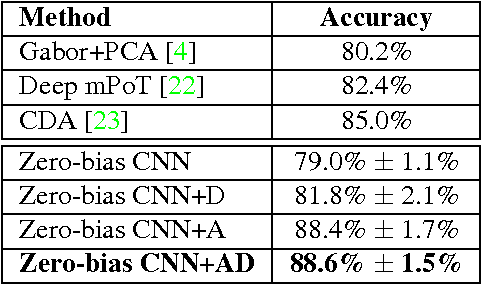
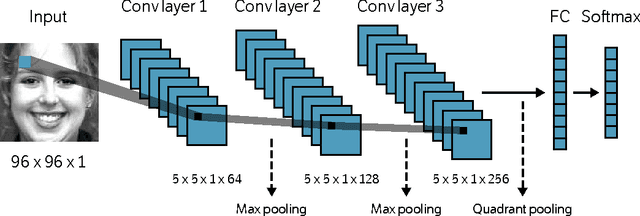
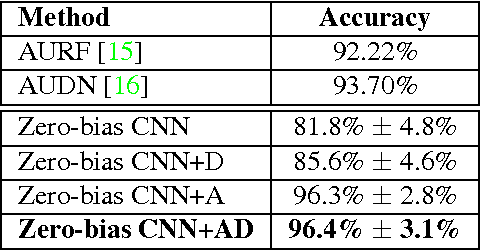
Despite being the appearance-based classifier of choice in recent years, relatively few works have examined how much convolutional neural networks (CNNs) can improve performance on accepted expression recognition benchmarks and, more importantly, examine what it is they actually learn. In this work, not only do we show that CNNs can achieve strong performance, but we also introduce an approach to decipher which portions of the face influence the CNN's predictions. First, we train a zero-bias CNN on facial expression data and achieve, to our knowledge, state-of-the-art performance on two expression recognition benchmarks: the extended Cohn-Kanade (CK+) dataset and the Toronto Face Dataset (TFD). We then qualitatively analyze the network by visualizing the spatial patterns that maximally excite different neurons in the convolutional layers and show how they resemble Facial Action Units (FAUs). Finally, we use the FAU labels provided in the CK+ dataset to verify that the FAUs observed in our filter visualizations indeed align with the subject's facial movements.
How Deep Neural Networks Can Improve Emotion Recognition on Video Data
Jan 10, 2017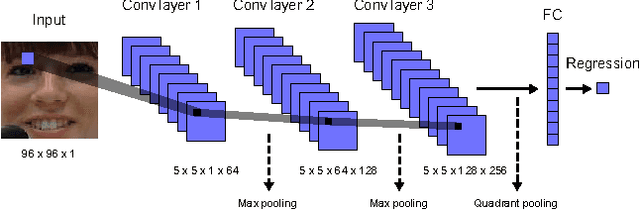
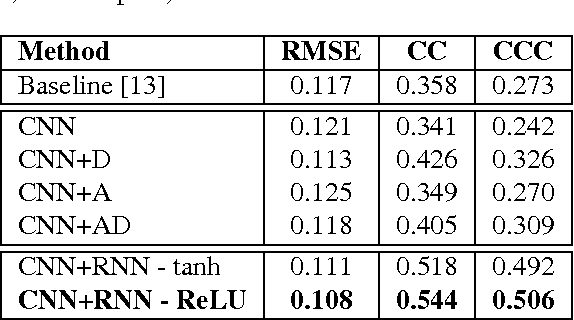
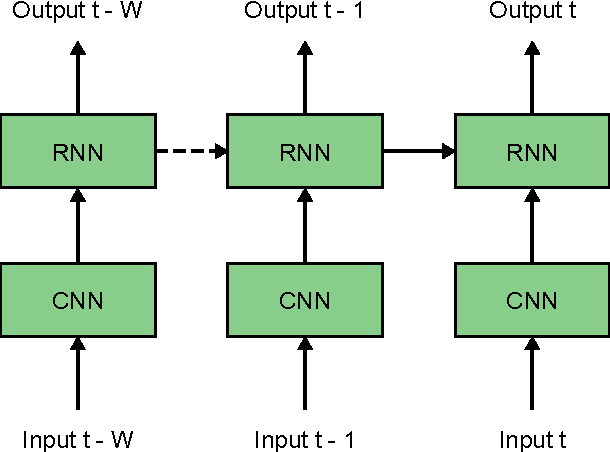
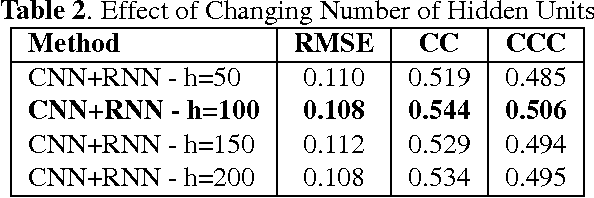
We consider the task of dimensional emotion recognition on video data using deep learning. While several previous methods have shown the benefits of training temporal neural network models such as recurrent neural networks (RNNs) on hand-crafted features, few works have considered combining convolutional neural networks (CNNs) with RNNs. In this work, we present a system that performs emotion recognition on video data using both CNNs and RNNs, and we also analyze how much each neural network component contributes to the system's overall performance. We present our findings on videos from the Audio/Visual+Emotion Challenge (AV+EC2015). In our experiments, we analyze the effects of several hyperparameters on overall performance while also achieving superior performance to the baseline and other competing methods.
Feedback Neural Network for Weakly Supervised Geo-Semantic Segmentation
Dec 08, 2016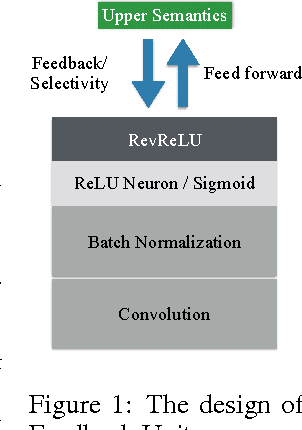

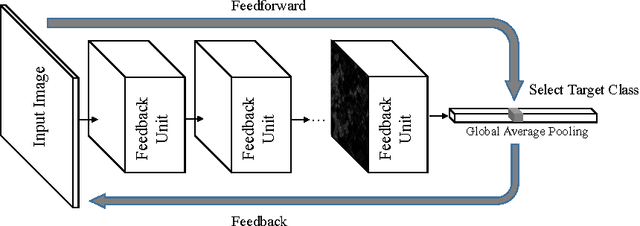

Learning from weakly-supervised data is one of the main challenges in machine learning and computer vision, especially for tasks such as image semantic segmentation where labeling is extremely expensive and subjective. In this paper, we propose a novel neural network architecture to perform weakly-supervised learning by suppressing irrelevant neuron activations. It localizes objects of interest by learning from image-level categorical labels in an end-to-end manner. We apply this algorithm to a practical challenge of transforming satellite images into a map of settlements and individual buildings. Experimental results show that the proposed algorithm achieves superior performance and efficiency when compared with various baseline models.
Fast Wavenet Generation Algorithm
Nov 29, 2016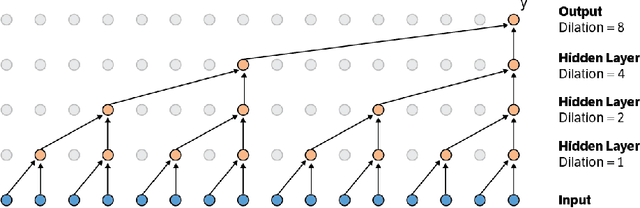
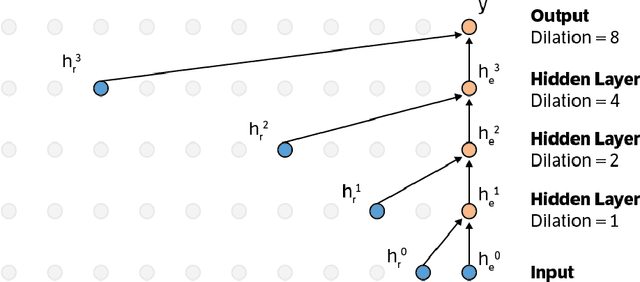
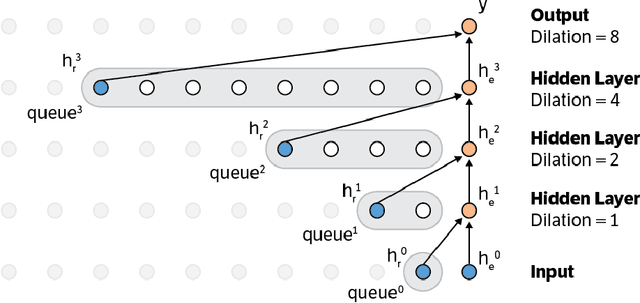
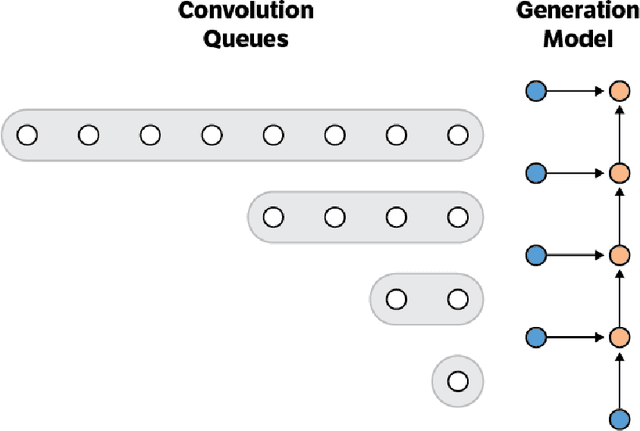
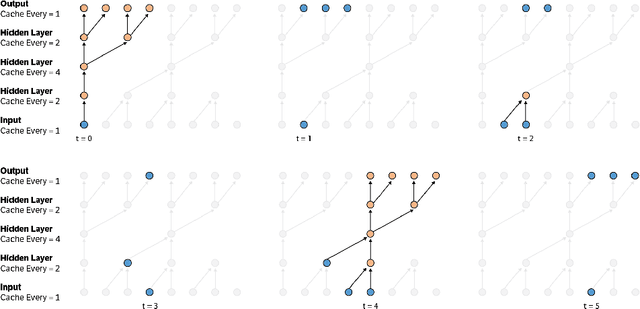
This paper presents an efficient implementation of the Wavenet generation process called Fast Wavenet. Compared to a naive implementation that has complexity O(2^L) (L denotes the number of layers in the network), our proposed approach removes redundant convolution operations by caching previous calculations, thereby reducing the complexity to O(L) time. Timing experiments show significant advantages of our fast implementation over a naive one. While this method is presented for Wavenet, the same scheme can be applied anytime one wants to perform autoregressive generation or online prediction using a model with dilated convolution layers. The code for our method is publicly available.
Deep Double Sparsity Encoder: Learning to Sparsify Not Only Features But Also Parameters
Oct 02, 2016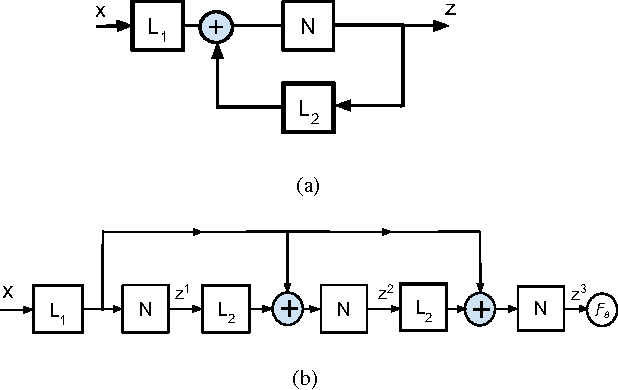
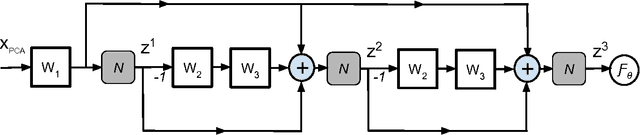
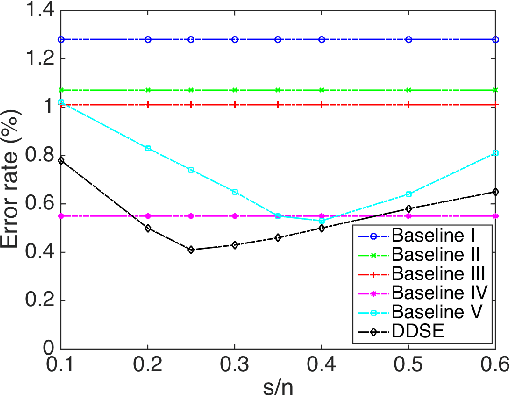
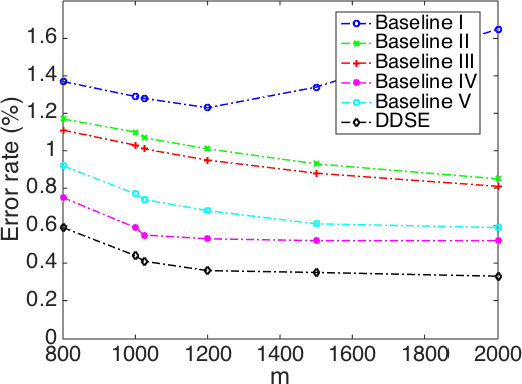
This paper emphasizes the significance to jointly exploit the problem structure and the parameter structure, in the context of deep modeling. As a specific and interesting example, we describe the deep double sparsity encoder (DDSE), which is inspired by the double sparsity model for dictionary learning. DDSE simultaneously sparsities the output features and the learned model parameters, under one unified framework. In addition to its intuitive model interpretation, DDSE also possesses compact model size and low complexity. Extensive simulations compare DDSE with several carefully-designed baselines, and verify the consistently superior performance of DDSE. We further apply DDSE to the novel application domain of brain encoding, with promising preliminary results achieved.
Stacked Approximated Regression Machine: A Simple Deep Learning Approach
Sep 08, 2016

With the agreement of my coauthors, I Zhangyang Wang would like to withdraw the manuscript "Stacked Approximated Regression Machine: A Simple Deep Learning Approach". Some experimental procedures were not included in the manuscript, which makes a part of important claims not meaningful. In the relevant research, I was solely responsible for carrying out the experiments; the other coauthors joined in the discussions leading to the main algorithm. Please see the updated text for more details.