 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThomas L. Griffiths
Extending rational models of communication from beliefs to actions
May 25, 2021
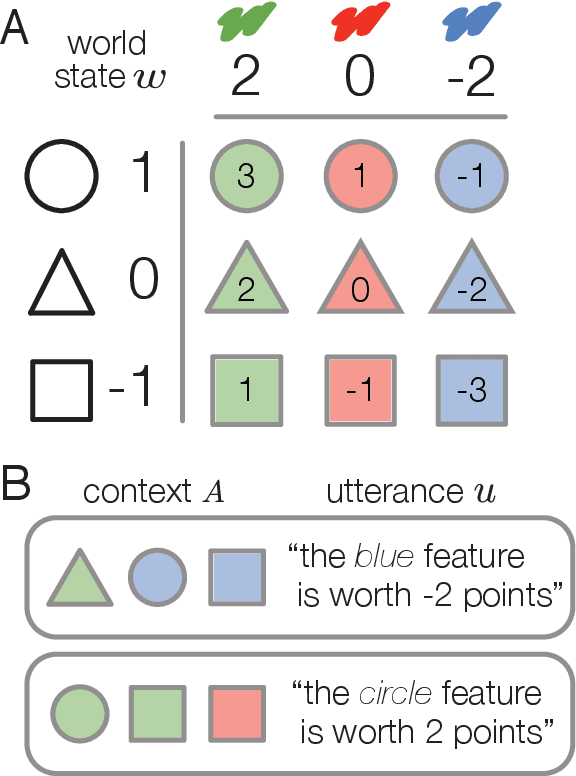

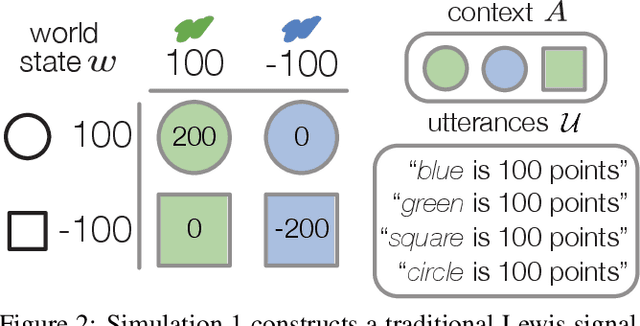

Speakers communicate to influence their partner's beliefs and shape their actions. Belief- and action-based objectives have been explored independently in recent computational models, but it has been challenging to explicitly compare or integrate them. Indeed, we find that they are conflated in standard referential communication tasks. To distinguish these accounts, we introduce a new paradigm called signaling bandits, generalizing classic Lewis signaling games to a multi-armed bandit setting where all targets in the context have some relative value. We develop three speaker models: a belief-oriented speaker with a purely informative objective; an action-oriented speaker with an instrumental objective; and a combined speaker which integrates the two by inducing listener beliefs that generally lead to desirable actions. We then present a series of simulations demonstrating that grounding production choices in future listener actions results in relevance effects and flexible uses of nonliteral language. More broadly, our findings suggest that language games based on richer decision problems are a promising avenue for insight into rational communication.
Are Convolutional Neural Networks or Transformers more like human vision?
May 15, 2021
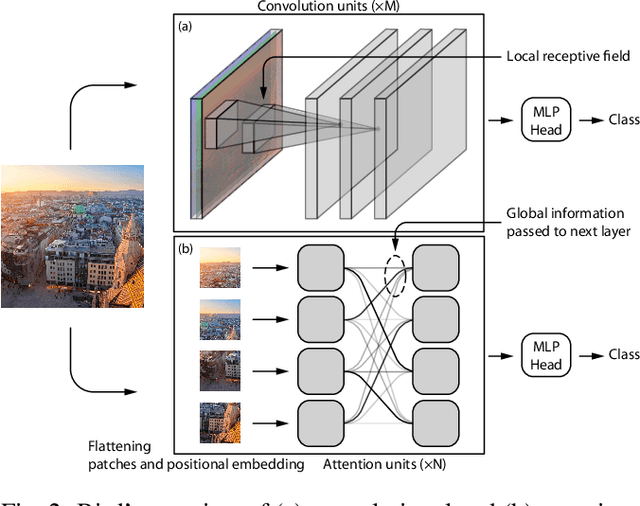
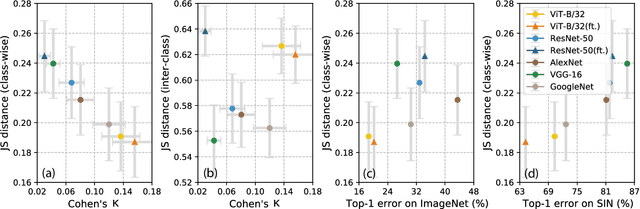
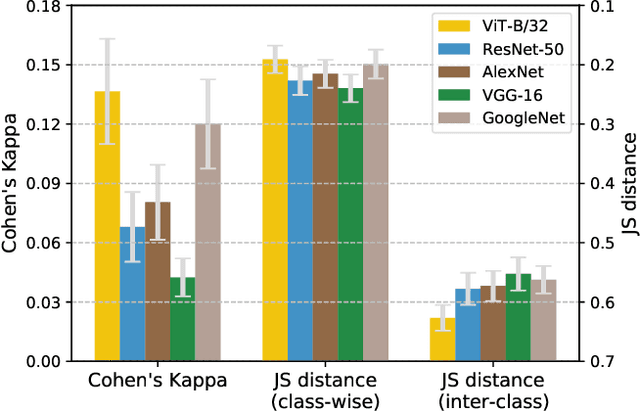
Modern machine learning models for computer vision exceed humans in accuracy on specific visual recognition tasks, notably on datasets like ImageNet. However, high accuracy can be achieved in many ways. The particular decision function found by a machine learning system is determined not only by the data to which the system is exposed, but also the inductive biases of the model, which are typically harder to characterize. In this work, we follow a recent trend of in-depth behavioral analyses of neural network models that go beyond accuracy as an evaluation metric by looking at patterns of errors. Our focus is on comparing a suite of standard Convolutional Neural Networks (CNNs) and a recently-proposed attention-based network, the Vision Transformer (ViT), which relaxes the translation-invariance constraint of CNNs and therefore represents a model with a weaker set of inductive biases. Attention-based networks have previously been shown to achieve higher accuracy than CNNs on vision tasks, and we demonstrate, using new metrics for examining error consistency with more granularity, that their errors are also more consistent with those of humans. These results have implications both for building more human-like vision models, as well as for understanding visual object recognition in humans.
Control of mental representations in human planning
May 14, 2021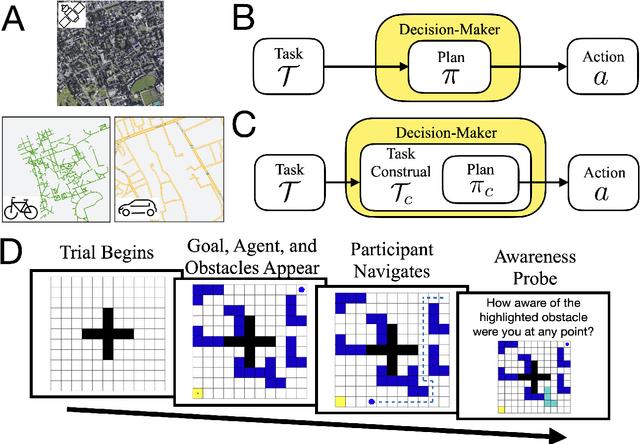
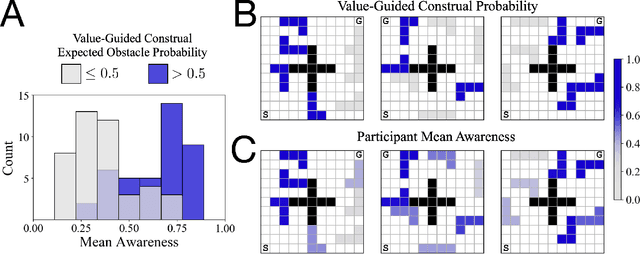
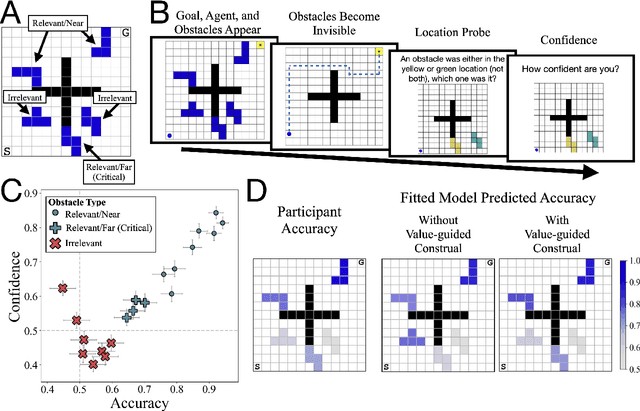
One of the most striking features of human cognition is the capacity to plan. Two aspects of human planning stand out: its efficiency, even in complex environments, and its flexibility, even in changing environments. Efficiency is especially impressive because directly computing an optimal plan is intractable, even for modestly complex tasks, and yet people successfully solve myriad everyday problems despite limited cognitive resources. Standard accounts in psychology, economics, and artificial intelligence have suggested this is because people have a mental representation of a task and then use heuristics to plan in that representation. However, this approach generally assumes that mental representations are fixed. Here, we propose that mental representations can be controlled and that this provides opportunities to adaptively simplify problems so they can be more easily reasoned about -- a process we refer to as construal. We construct a formal model of this process and, in a series of large, pre-registered behavioral experiments, show both that construal is subject to online cognitive control and that people form value-guided construals that optimally balance the complexity of a representation and its utility for planning and acting. These results demonstrate how strategically perceiving and conceiving problems facilitates the effective use of limited cognitive resources.
Shades of confusion: Lexical uncertainty modulates ad hoc coordination in an interactive communication task
May 13, 2021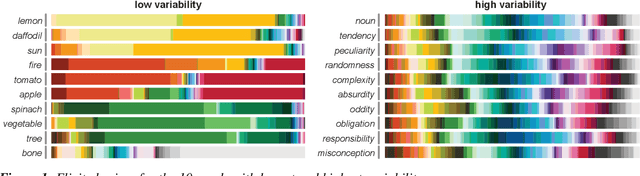
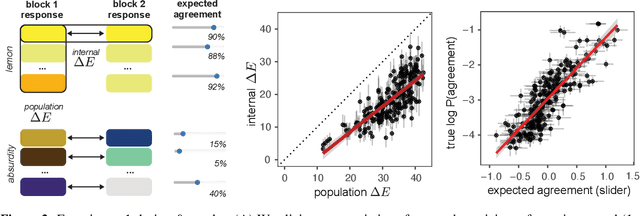
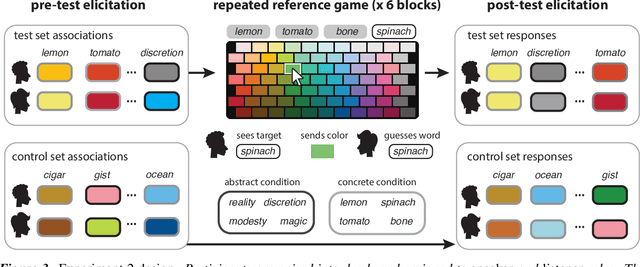
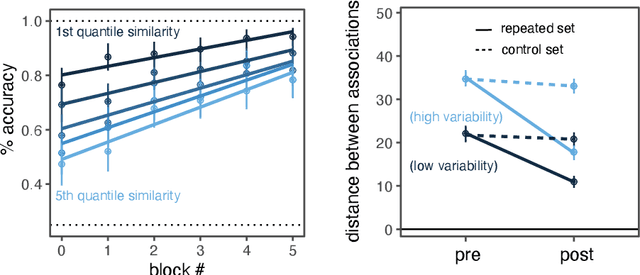
There is substantial variability in the expectations that communication partners bring into interactions, creating the potential for misunderstandings. To directly probe these gaps and our ability to overcome them, we propose a communication task based on color-concept associations. In Experiment 1, we establish several key properties of the mental representations of these expectations, or \emph{lexical priors}, based on recent probabilistic theories. Associations are more variable for abstract concepts, variability is represented as uncertainty within each individual, and uncertainty enables accurate predictions about whether others are likely to share the same association. In Experiment 2, we then examine the downstream consequences of these representations for communication. Accuracy is initially low when communicating about concepts with more variable associations, but rapidly increases as participants form ad hoc conventions. Together, our findings suggest that people cope with variability by maintaining well-calibrated uncertainty about their partner and appropriately adaptable representations of their own.
From partners to populations: A hierarchical Bayesian account of coordination and convention
Apr 12, 2021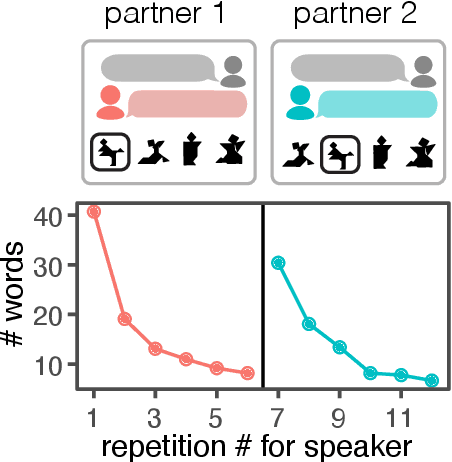
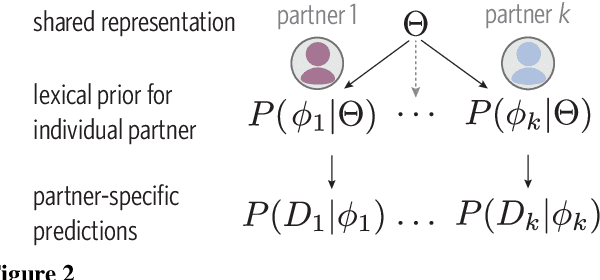
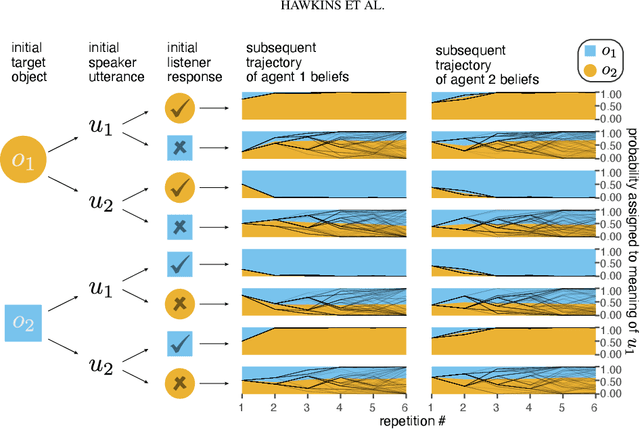
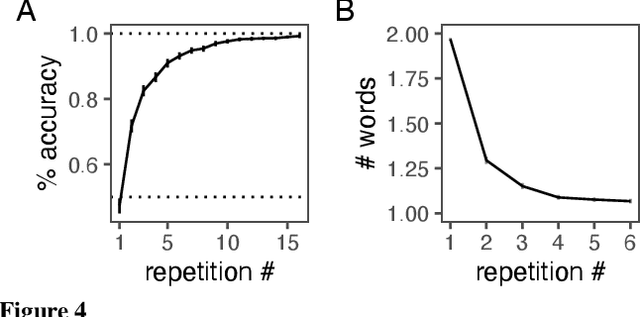
Languages are powerful solutions to coordination problems: they provide stable, shared expectations about how the words we say correspond to the beliefs and intentions in our heads. Yet language use in a variable and non-stationary social environment requires linguistic representations to be flexible: old words acquire new ad hoc or partner-specific meanings on the fly. In this paper, we introduce a hierarchical Bayesian theory of convention formation that aims to reconcile the long-standing tension between these two basic observations. More specifically, we argue that the central computational problem of communication is not simply transmission, as in classical formulations, but learning and adaptation over multiple timescales. Under our account, rapid learning within dyadic interactions allows for coordination on partner-specific common ground, while social conventions are stable priors that have been abstracted away from interactions with multiple partners. We present new empirical data alongside simulations showing how our model provides a cognitive foundation for explaining several phenomena that have posed a challenge for previous accounts: (1) the convergence to more efficient referring expressions across repeated interaction with the same partner, (2) the gradual transfer of partner-specific common ground to novel partners, and (3) the influence of communicative context on which conventions eventually form.
Evaluating Models of Robust Word Recognition with Serial Reproduction
Jan 24, 2021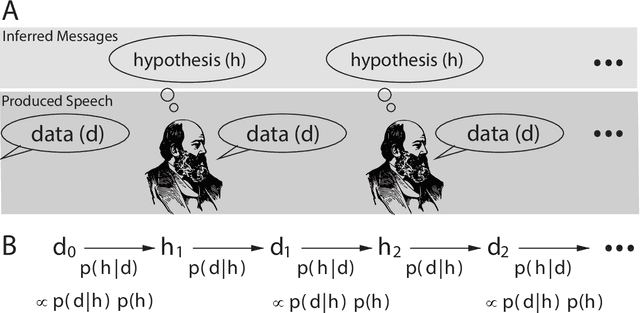
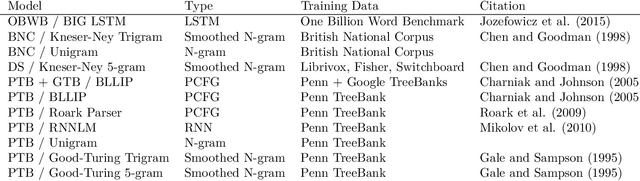

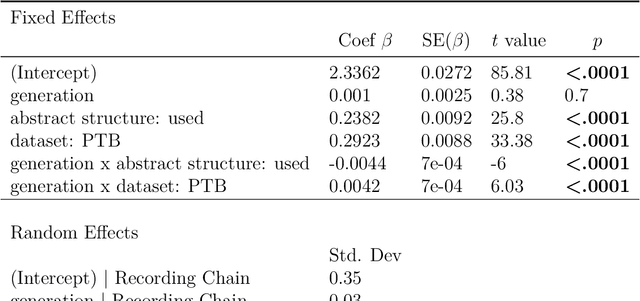
Spoken communication occurs in a "noisy channel" characterized by high levels of environmental noise, variability within and between speakers, and lexical and syntactic ambiguity. Given these properties of the received linguistic input, robust spoken word recognition -- and language processing more generally -- relies heavily on listeners' prior knowledge to evaluate whether candidate interpretations of that input are more or less likely. Here we compare several broad-coverage probabilistic generative language models in their ability to capture human linguistic expectations. Serial reproduction, an experimental paradigm where spoken utterances are reproduced by successive participants similar to the children's game of "Telephone," is used to elicit a sample that reflects the linguistic expectations of English-speaking adults. When we evaluate a suite of probabilistic generative language models against the yielded chains of utterances, we find that those models that make use of abstract representations of preceding linguistic context (i.e., phrase structure) best predict the changes made by people in the course of serial reproduction. A logistic regression model predicting which words in an utterance are most likely to be lost or changed in the course of spoken transmission corroborates this result. We interpret these findings in light of research highlighting the interaction of memory-based constraints and representations in language processing.
Show or Tell? Demonstration is More Robust to Changes in Shared Perception than Explanation
Dec 16, 2020


Successful teaching entails a complex interaction between a teacher and a learner. The teacher must select and convey information based on what they think the learner perceives and believes. Teaching always involves misaligned beliefs, but studies of pedagogy often focus on situations where teachers and learners share perceptions. Nonetheless, a teacher and learner may not always experience or attend to the same aspects of the environment. Here, we study how misaligned perceptions influence communication. We hypothesize that the efficacy of different forms of communication depends on the shared perceptual state between teacher and learner. We develop a cooperative teaching game to test whether concrete mediums (demonstrations, or "showing") are more robust than abstract ones (language, or "telling") when the teacher and learner are not perceptually aligned. We find evidence that (1) language-based teaching is more affected by perceptual misalignment, but (2) demonstration-based teaching is less likely to convey nuanced information. We discuss implications for human pedagogy and machine learning.
Competition in Cross-situational Word Learning: A Computational Study
Dec 06, 2020

Children learn word meanings by tapping into the commonalities across different situations in which words are used and overcome the high level of uncertainty involved in early word learning experiences. In a set of computational studies, we show that to successfully learn word meanings in the face of uncertainty, a learner needs to use two types of competition: words competing for association to a referent when learning from an observation and referents competing for a word when the word is used.
Investigating representations of verb bias in neural language models
Oct 15, 2020
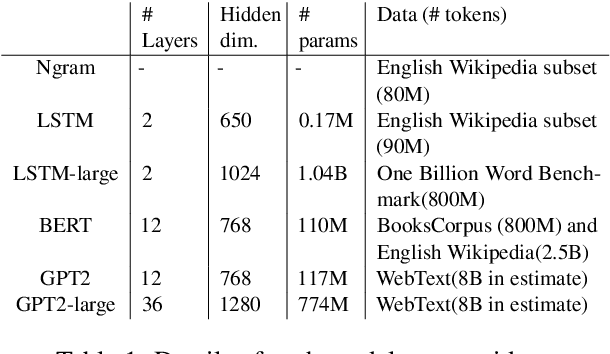
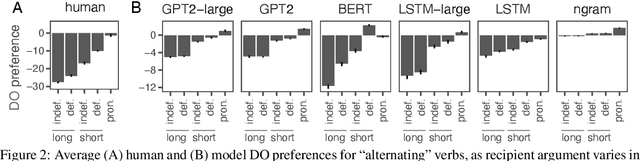
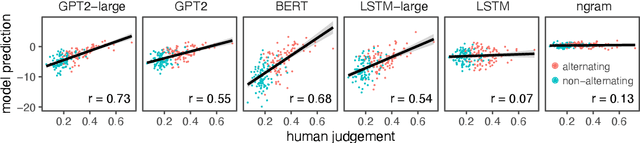
Languages typically provide more than one grammatical construction to express certain types of messages. A speaker's choice of construction is known to depend on multiple factors, including the choice of main verb -- a phenomenon known as \emph{verb bias}. Here we introduce DAIS, a large benchmark dataset containing 50K human judgments for 5K distinct sentence pairs in the English dative alternation. This dataset includes 200 unique verbs and systematically varies the definiteness and length of arguments. We use this dataset, as well as an existing corpus of naturally occurring data, to evaluate how well recent neural language models capture human preferences. Results show that larger models perform better than smaller models, and transformer architectures (e.g. GPT-2) tend to out-perform recurrent architectures (e.g. LSTMs) even under comparable parameter and training settings. Additional analyses of internal feature representations suggest that transformers may better integrate specific lexical information with grammatical constructions.