 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlottal Closure and Opening Instant Detection from Speech Signals
Dec 28, 2019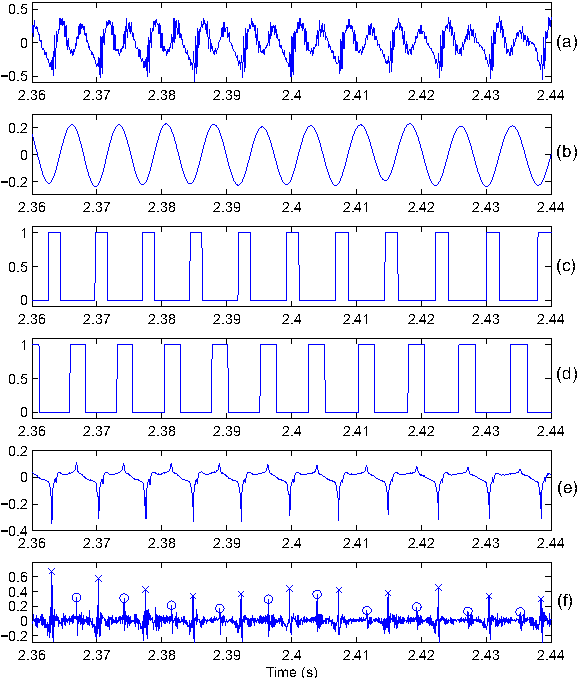
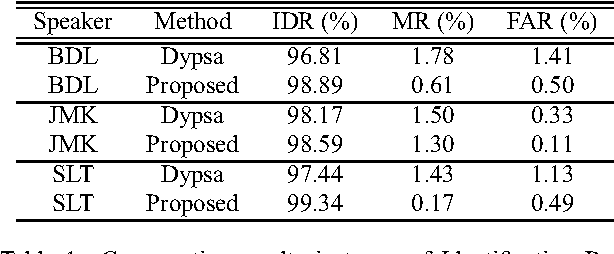
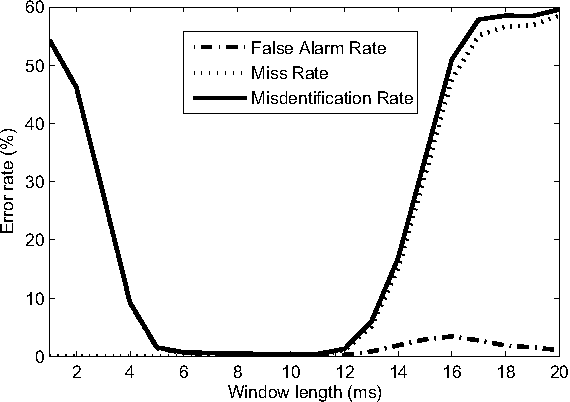
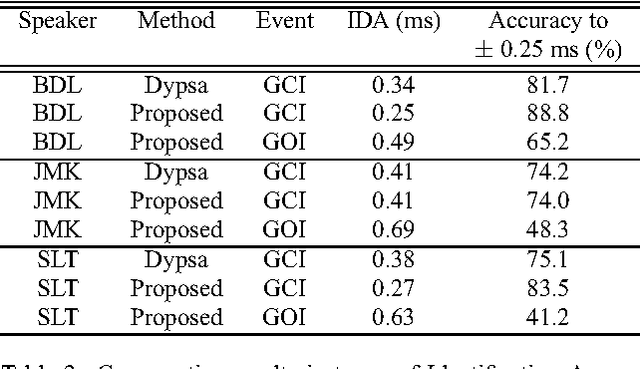
This paper proposes a new procedure to detect Glottal Closure and Opening Instants (GCIs and GOIs) directly from speech waveforms. The procedure is divided into two successive steps. First a mean-based signal is computed, and intervals where speech events are expected to occur are extracted from it. Secondly, at each interval a precise position of the speech event is assigned by locating a discontinuity in the Linear Prediction residual. The proposed method is compared to the DYPSA algorithm on the CMU ARCTIC database. A significant improvement as well as a better noise robustness are reported. Besides, results of GOI identification accuracy are promising for the glottal source characterization.
Detection of Glottal Closure Instants from Speech Signals: a Quantitative Review
Dec 28, 2019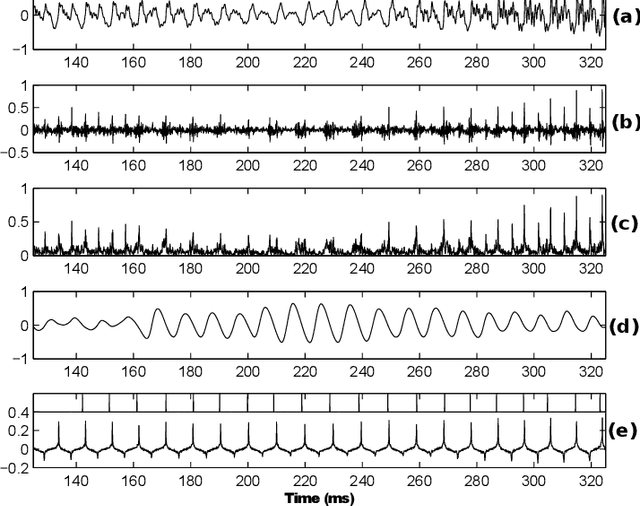
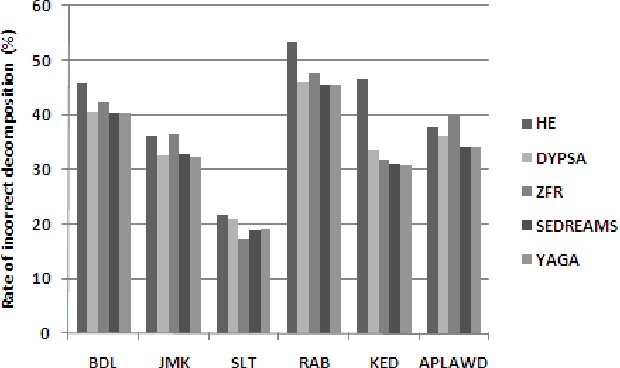
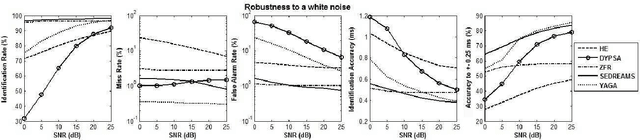
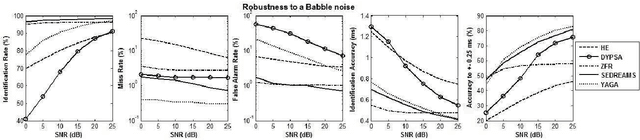
The pseudo-periodicity of voiced speech can be exploited in several speech processing applications. This requires however that the precise locations of the Glottal Closure Instants (GCIs) are available. The focus of this paper is the evaluation of automatic methods for the detection of GCIs directly from the speech waveform. Five state-of-the-art GCI detection algorithms are compared using six different databases with contemporaneous electroglottographic recordings as ground truth, and containing many hours of speech by multiple speakers. The five techniques compared are the Hilbert Envelope-based detection (HE), the Zero Frequency Resonator-based method (ZFR), the Dynamic Programming Phase Slope Algorithm (DYPSA), the Speech Event Detection using the Residual Excitation And a Mean-based Signal (SEDREAMS) and the Yet Another GCI Algorithm (YAGA). The efficacy of these methods is first evaluated on clean speech, both in terms of reliabililty and accuracy. Their robustness to additive noise and to reverberation is also assessed. A further contribution of the paper is the evaluation of their performance on a concrete application of speech processing: the causal-anticausal decomposition of speech. It is shown that for clean speech, SEDREAMS and YAGA are the best performing techniques, both in terms of identification rate and accuracy. ZFR and SEDREAMS also show a superior robustness to additive noise and reverberation.
Joint Robust Voicing Detection and Pitch Estimation Based on Residual Harmonics
Dec 28, 2019
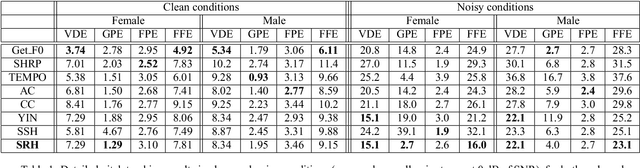
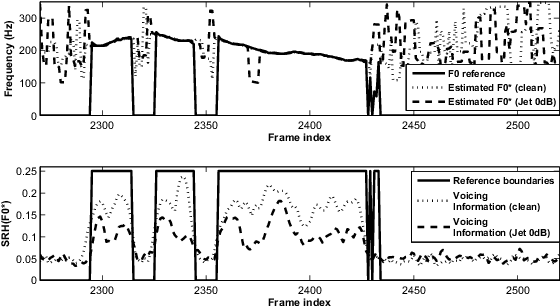
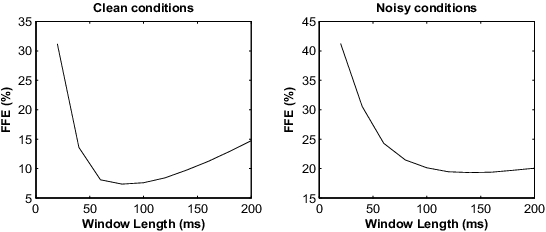
This paper focuses on the problem of pitch tracking in noisy conditions. A method using harmonic information in the residual signal is presented. The proposed criterion is used both for pitch estimation, as well as for determining the voicing segments of speech. In the experiments, the method is compared to six state-of-the-art pitch trackers on the Keele and CSTR databases. The proposed technique is shown to be particularly robust to additive noise, leading to a significant improvement in adverse conditions.
Singing Synthesis: with a little help from my attention
Dec 12, 2019

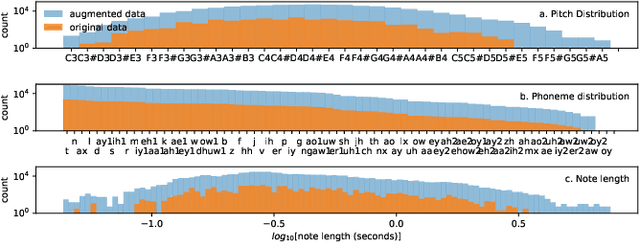
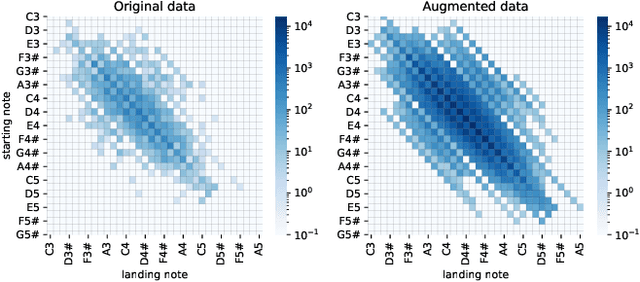
We present a novel system for singing synthesis, based on attention. Starting from a musical score with notes and lyrics, we build a phoneme-level multi stream note embedding. The embedding contains the information encoded in the score regarding pitch, duration and the phonemes to be pronounced on each note. This note representation is used to condition an attention-based sequence-to-sequence architecture, in order to generate mel-spectrograms. Our model demonstrates attention can be successfully applied to the singing synthesis field. The system requires considerably less explicit modelling of voice features such as F0 patterns, vibratos, and note and phoneme durations, than most models in the literature. However, we observe that completely dispensing with any duration modelling introduces occasional instabilities in the generated spectrograms. We train an autoregressive WaveNet to be used as a neural vocoder to synthesise the mel-spectrograms produced by the sequence-to-sequence architecture, using a combination of speech and singing data.
Dynamic Prosody Generation for Speech Synthesis using Linguistics-Driven Acoustic Embedding Selection
Dec 02, 2019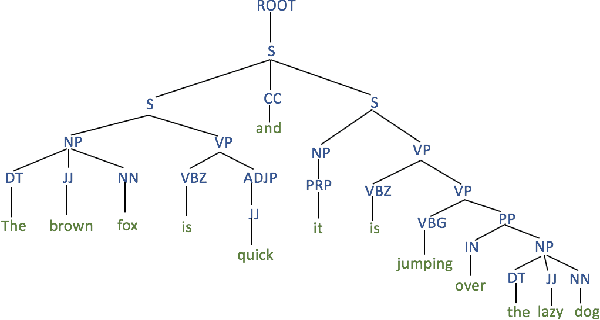

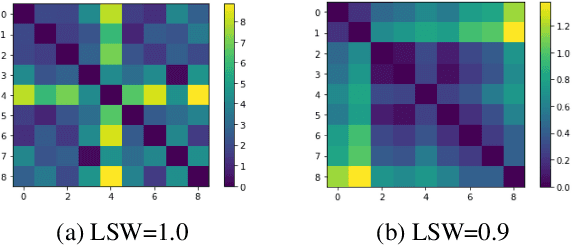
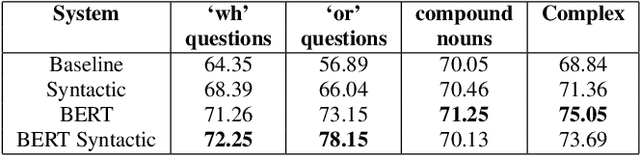
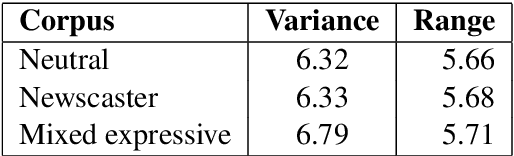
Recent advances in Text-to-Speech (TTS) have improved quality and naturalness to near-human capabilities when considering isolated sentences. But something which is still lacking in order to achieve human-like communication is the dynamic variations and adaptability of human speech. This work attempts to solve the problem of achieving a more dynamic and natural intonation in TTS systems, particularly for stylistic speech such as the newscaster speaking style. We propose a novel embedding selection approach which exploits linguistic information, leveraging the speech variability present in the training dataset. We analyze the contribution of both semantic and syntactic features. Our results show that the approach improves the prosody and naturalness for complex utterances as well as in Long Form Reading (LFR).
Interpretable Deep Learning Model for the Detection and Reconstruction of Dysarthric Speech
Jul 10, 2019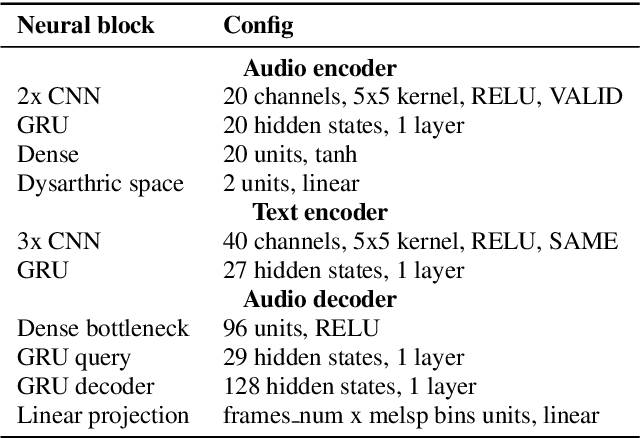
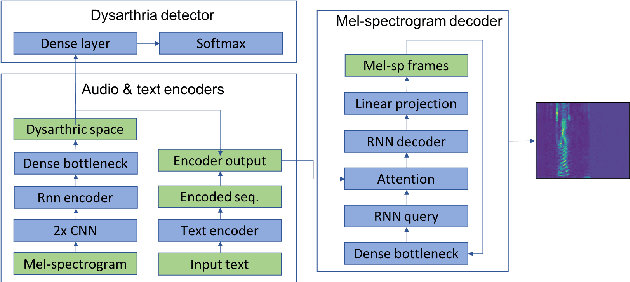
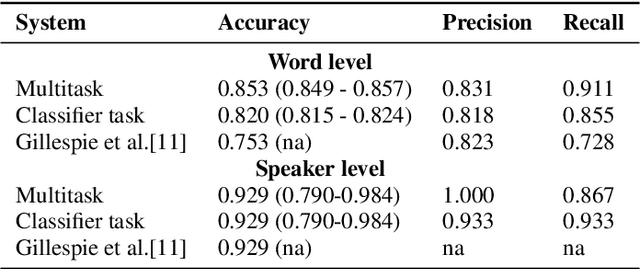
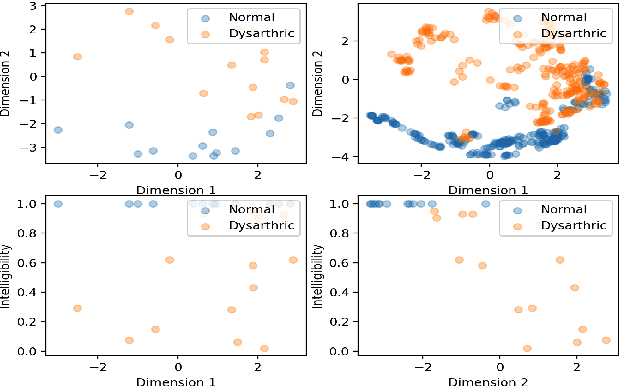
This paper proposed a novel approach for the detection and reconstruction of dysarthric speech. The encoder-decoder model factorizes speech into a low-dimensional latent space and encoding of the input text. We showed that the latent space conveys interpretable characteristics of dysarthria, such as intelligibility and fluency of speech. MUSHRA perceptual test demonstrated that the adaptation of the latent space let the model generate speech of improved fluency. The multi-task supervised approach for predicting both the probability of dysarthric speech and the mel-spectrogram helps improve the detection of dysarthria with higher accuracy. This is thanks to a low-dimensional latent space of the auto-encoder as opposed to directly predicting dysarthria from a highly dimensional mel-spectrogram.
Fine-grained robust prosody transfer for single-speaker neural text-to-speech
Jul 04, 2019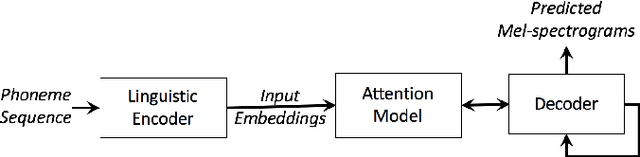
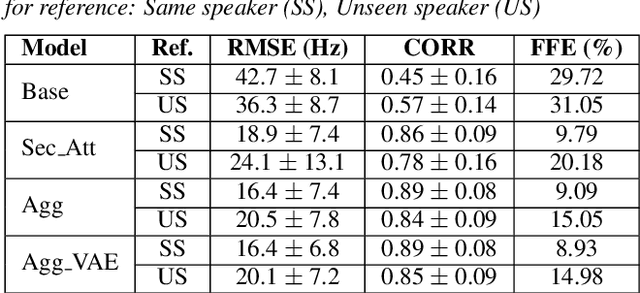
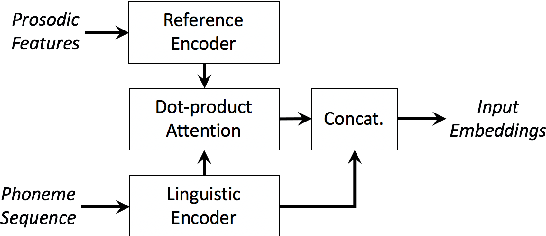
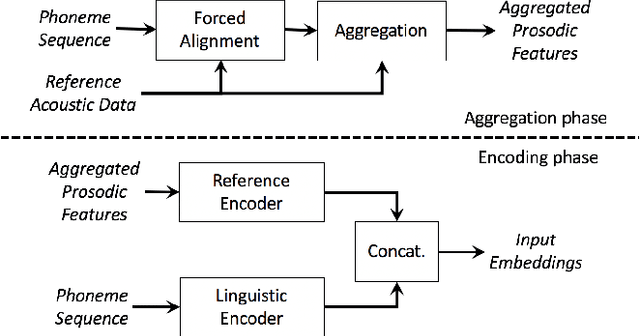
We present a neural text-to-speech system for fine-grained prosody transfer from one speaker to another. Conventional approaches for end-to-end prosody transfer typically use either fixed-dimensional or variable-length prosody embedding via a secondary attention to encode the reference signal. However, when trained on a single-speaker dataset, the conventional prosody transfer systems are not robust enough to speaker variability, especially in the case of a reference signal coming from an unseen speaker. Therefore, we propose decoupling of the reference signal alignment from the overall system. For this purpose, we pre-compute phoneme-level time stamps and use them to aggregate prosodic features per phoneme, injecting them into a sequence-to-sequence text-to-speech system. We incorporate a variational auto-encoder to further enhance the latent representation of prosody embeddings. We show that our proposed approach is significantly more stable and achieves reliable prosody transplantation from an unseen speaker. We also propose a solution to the use case in which the transcription of the reference signal is absent. We evaluate all our proposed methods using both objective and subjective listening tests.
In Other News: A Bi-style Text-to-speech Model for Synthesizing Newscaster Voice with Limited Data
Apr 04, 2019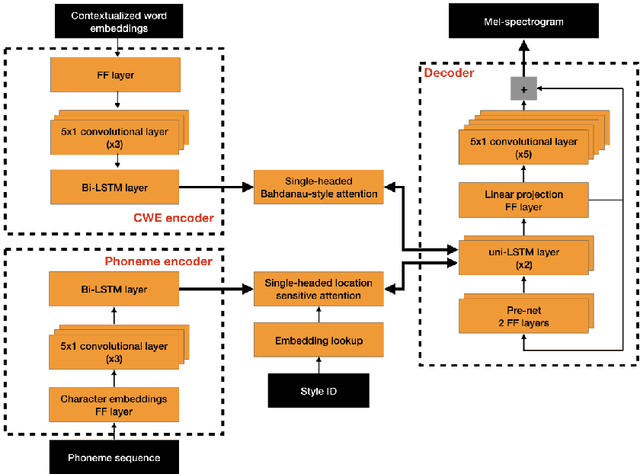

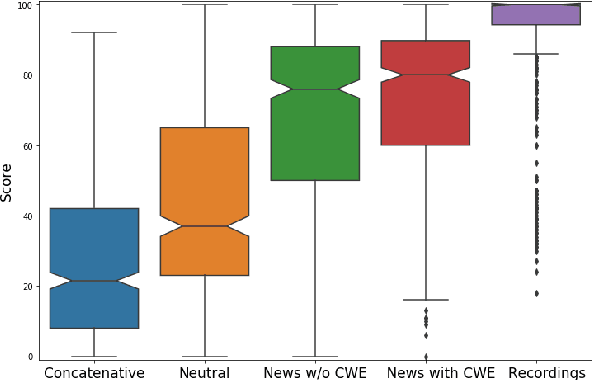
Neural text-to-speech synthesis (NTTS) models have shown significant progress in generating high-quality speech, however they require a large quantity of training data. This makes creating models for multiple styles expensive and time-consuming. In this paper different styles of speech are analysed based on prosodic variations, from this a model is proposed to synthesise speech in the style of a newscaster, with just a few hours of supplementary data. We pose the problem of synthesising in a target style using limited data as that of creating a bi-style model that can synthesise both neutral-style and newscaster-style speech via a one-hot vector which factorises the two styles. We also propose conditioning the model on contextual word embeddings, and extensively evaluate it against neutral NTTS, and neutral concatenative-based synthesis. This model closes the gap in perceived style-appropriateness between natural recordings for newscaster-style of speech, and neutral speech synthesis by approximately two-thirds.
Active and Semi-Supervised Learning in ASR: Benefits on the Acoustic and Language Models
Mar 07, 2019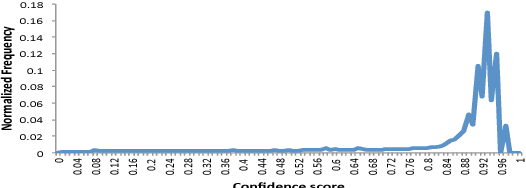
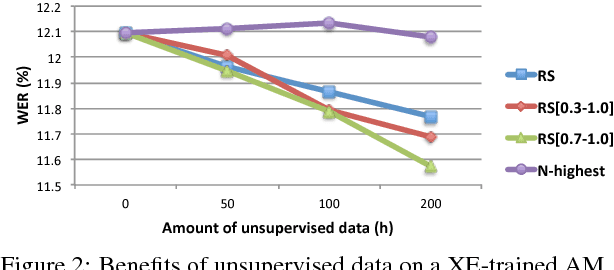
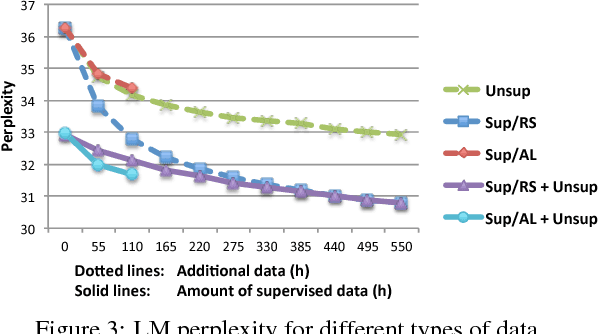
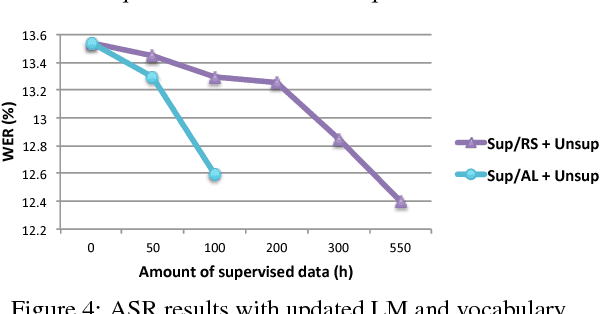
The goal of this paper is to simulate the benefits of jointly applying active learning (AL) and semi-supervised training (SST) in a new speech recognition application. Our data selection approach relies on confidence filtering, and its impact on both the acoustic and language models (AM and LM) is studied. While AL is known to be beneficial to AM training, we show that it also carries out substantial improvements to the LM when combined with SST. Sophisticated confidence models, on the other hand, did not prove to yield any data selection gain. Our results indicate that, while SST is crucial at the beginning of the labeling process, its gains degrade rapidly as AL is set in place. The final simulation reports that AL allows a transcription cost reduction of about 70% over random selection. Alternatively, for a fixed transcription budget, the proposed approach improves the word error rate by about 12.5% relative.
Traditional Machine Learning for Pitch Detection
Mar 04, 2019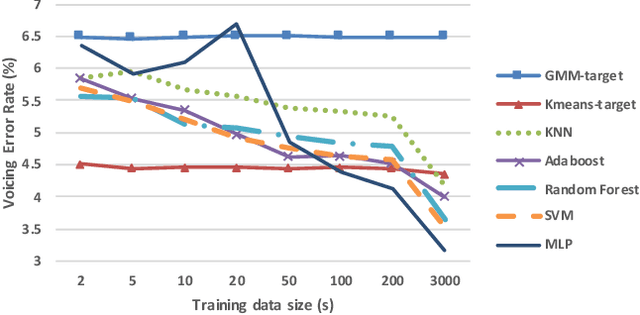

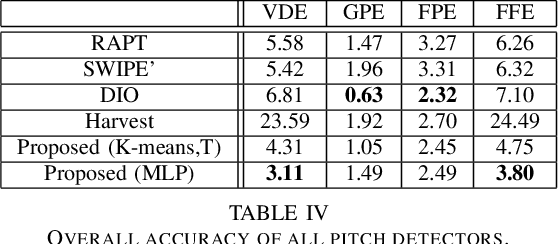
Pitch detection is a fundamental problem in speech processing as F0 is used in a large number of applications. Recent articles have proposed deep learning for robust pitch tracking. In this paper, we consider voicing detection as a classification problem and F0 contour estimation as a regression problem. For both tasks, acoustic features from multiple domains and traditional machine learning methods are used. The discrimination power of existing and proposed features is assessed through mutual information. Multiple supervised and unsupervised approaches are compared. A significant relative reduction of voicing errors over the best baseline is obtained: 20% with the best clustering method (K-means) and 45% with a Multi-Layer Perceptron. For F0 contour estimation, the benefits of regression techniques are limited though. We investigate whether those objective gains translate in a parametric synthesis task. Clear perceptual preferences are observed for the proposed approach over two widely-used baselines (RAPT and DIO).