 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThien Huu Nguyen
Tutorial Recommendation for Livestream Videos using Discourse-Level Consistency and Ontology-Based Filtering
Sep 11, 2022

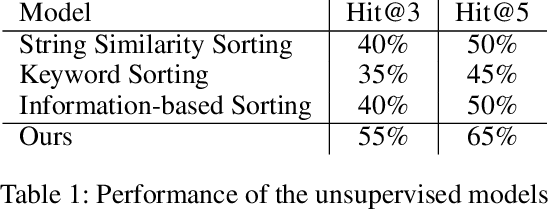
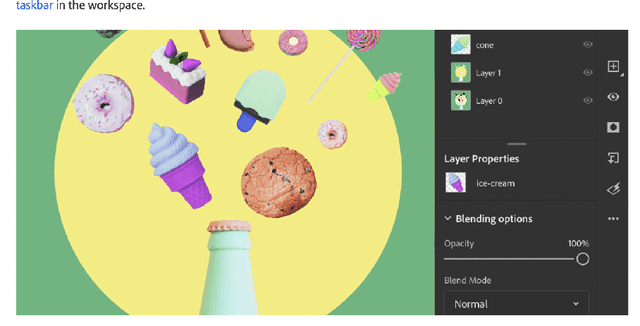
Streaming videos is one of the methods for creators to share their creative works with their audience. In these videos, the streamer share how they achieve their final objective by using various tools in one or several programs for creative projects. To this end, the steps required to achieve the final goal can be discussed. As such, these videos could provide substantial educational content that can be used to learn how to employ the tools used by the streamer. However, one of the drawbacks is that the streamer might not provide enough details for every step. Therefore, for the learners, it might be difficult to catch up with all the steps. In order to alleviate this issue, one solution is to link the streaming videos with the relevant tutorial available for the tools used in the streaming video. More specifically, a system can analyze the content of the live streaming video and recommend the most relevant tutorials. Since the existing document recommendation models cannot handle this situation, in this work, we present a novel dataset and model for the task of tutorial recommendation for live-streamed videos. We conduct extensive analyses on the proposed dataset and models, revealing the challenging nature of this task.
Improving Keyphrase Extraction with Data Augmentation and Information Filtering
Sep 11, 2022


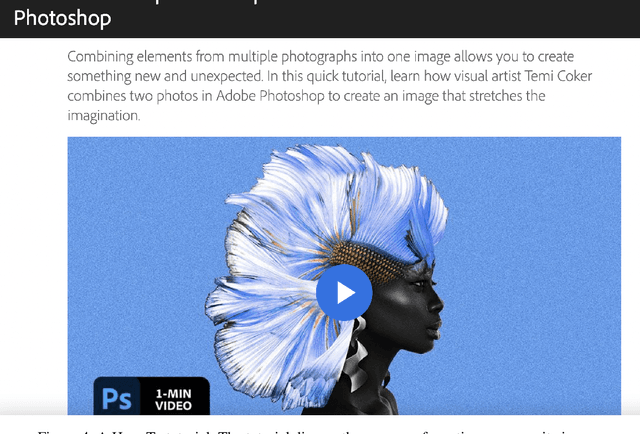
Keyphrase extraction is one of the essential tasks for document understanding in NLP. While the majority of the prior works are dedicated to the formal setting, e.g., books, news or web-blogs, informal texts such as video transcripts are less explored. To address this limitation, in this work we present a novel corpus and method for keyphrase extraction from the transcripts of the videos streamed on the Behance platform. More specifically, in this work, a novel data augmentation is proposed to enrich the model with the background knowledge about the keyphrase extraction task from other domains. Extensive experiments on the proposed dataset dataset show the effectiveness of the introduced method.
Symlink: A New Dataset for Scientific Symbol-Description Linking
Apr 26, 2022
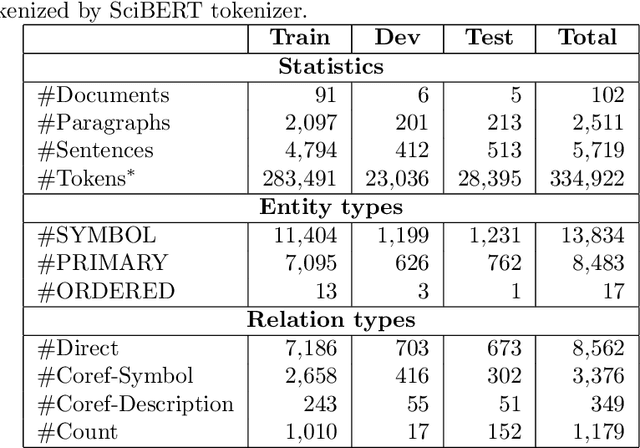
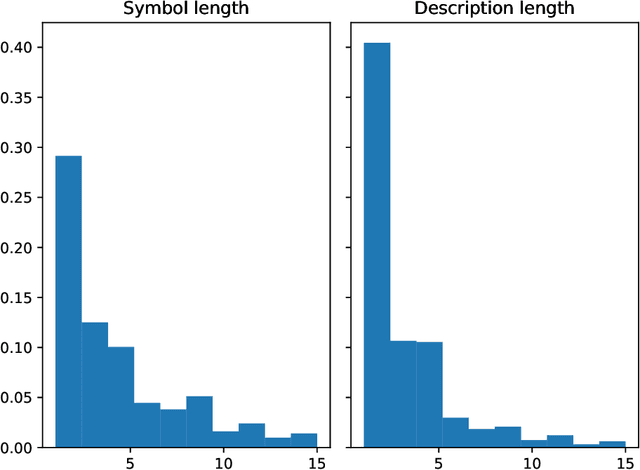
Mathematical symbols and descriptions appear in various forms across document section boundaries without explicit markup. In this paper, we present a new large-scale dataset that emphasizes extracting symbols and descriptions in scientific documents. Symlink annotates scientific papers of 5 different domains (i.e., computer science, biology, physics, mathematics, and economics). Our experiments on Symlink demonstrate the challenges of the symbol-description linking task for existing models and call for further research effort in this area. We will publicly release Symlink to facilitate future research.
Punctuation Restoration
Feb 19, 2022
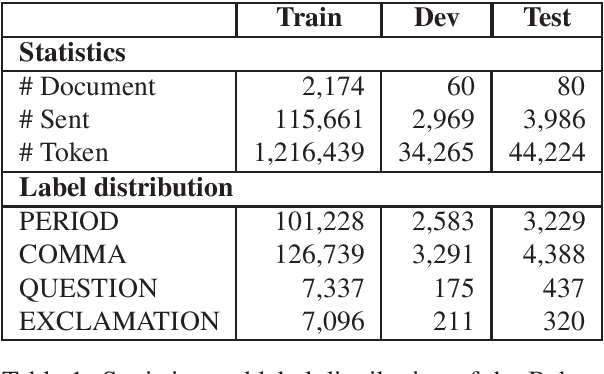


Given the increasing number of livestreaming videos, automatic speech recognition and post-processing for livestreaming video transcripts are crucial for efficient data management as well as knowledge mining. A key step in this process is punctuation restoration which restores fundamental text structures such as phrase and sentence boundaries from the video transcripts. This work presents a new human-annotated corpus, called BehancePR, for punctuation restoration in livestreaming video transcripts. Our experiments on BehancePR demonstrate the challenges of punctuation restoration for this domain. Furthermore, we show that popular natural language processing toolkits are incapable of detecting sentence boundary on non-punctuated transcripts of livestreaming videos, calling for more research effort to develop robust models for this area.
MACRONYM: A Large-Scale Dataset for Multilingual and Multi-Domain Acronym Extraction
Feb 19, 2022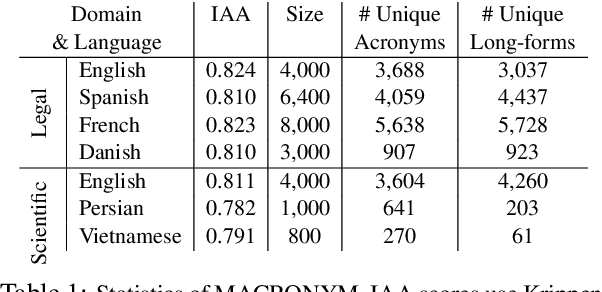
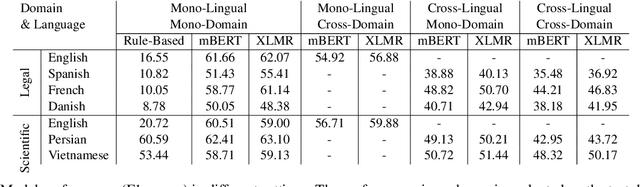
Acronym extraction is the task of identifying acronyms and their expanded forms in texts that is necessary for various NLP applications. Despite major progress for this task in recent years, one limitation of existing AE research is that they are limited to the English language and certain domains (i.e., scientific and biomedical). As such, challenges of AE in other languages and domains is mainly unexplored. Lacking annotated datasets in multiple languages and domains has been a major issue to hinder research in this area. To address this limitation, we propose a new dataset for multilingual multi-domain AE. Specifically, 27,200 sentences in 6 typologically different languages and 2 domains, i.e., Legal and Scientific, is manually annotated for AE. Our extensive experiments on the proposed dataset show that AE in different languages and different learning settings has unique challenges, emphasizing the necessity of further research on multilingual and multi-domain AE.
FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
Feb 16, 2022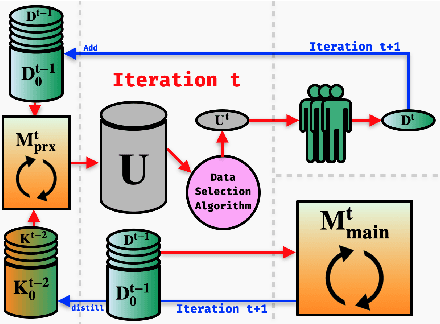

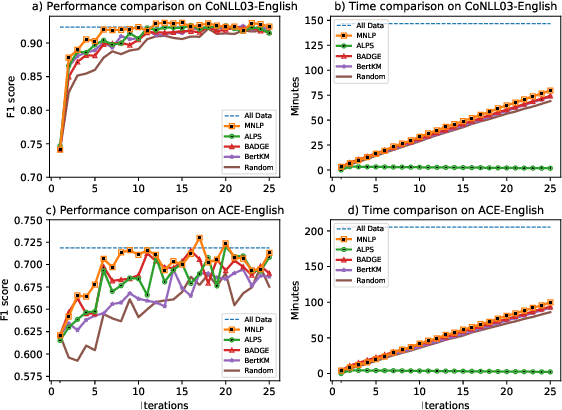

This paper presents FAMIE, a comprehensive and efficient active learning (AL) toolkit for multilingual information extraction. FAMIE is designed to address a fundamental problem in existing AL frameworks where annotators need to wait for a long time between annotation batches due to the time-consuming nature of model training and data selection at each AL iteration. This hinders the engagement, productivity, and efficiency of annotators. Based on the idea of using a small proxy network for fast data selection, we introduce a novel knowledge distillation mechanism to synchronize the proxy network with the main large model (i.e., BERT-based) to ensure the appropriateness of the selected annotation examples for the main model. Our AL framework can support multiple languages. The experiments demonstrate the advantages of FAMIE in terms of competitive performance and time efficiency for sequence labeling with AL. We publicly release our code (\url{https://github.com/nlp-uoregon/famie}) and demo website (\url{http://nlp.uoregon.edu:9000/}). A demo video for FAMIE is provided at: \url{https://youtu.be/I2i8n_jAyrY}.
Predicting Patient Readmission Risk from Medical Text via Knowledge Graph Enhanced Multiview Graph Convolution
Dec 19, 2021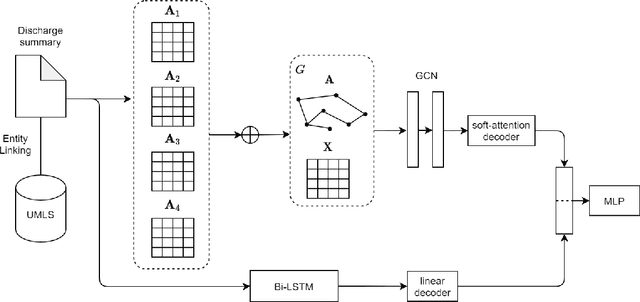
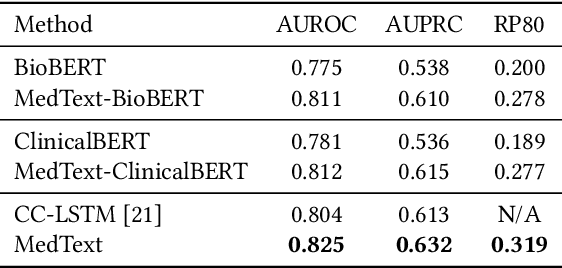
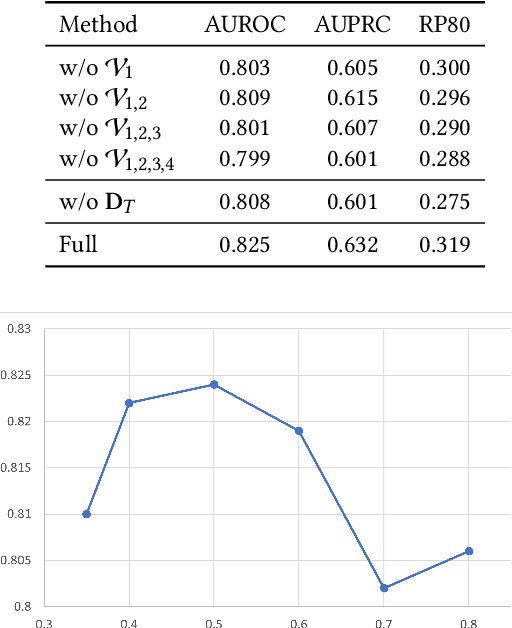
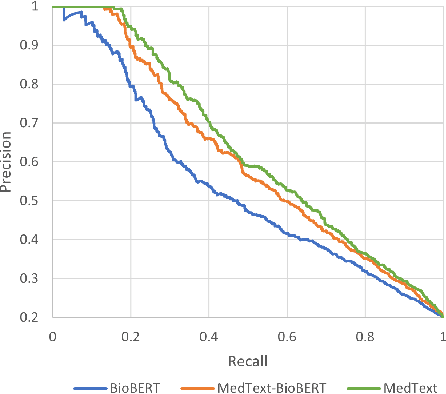
Unplanned intensive care unit (ICU) readmission rate is an important metric for evaluating the quality of hospital care. Efficient and accurate prediction of ICU readmission risk can not only help prevent patients from inappropriate discharge and potential dangers, but also reduce associated costs of healthcare. In this paper, we propose a new method that uses medical text of Electronic Health Records (EHRs) for prediction, which provides an alternative perspective to previous studies that heavily depend on numerical and time-series features of patients. More specifically, we extract discharge summaries of patients from their EHRs, and represent them with multiview graphs enhanced by an external knowledge graph. Graph convolutional networks are then used for representation learning. Experimental results prove the effectiveness of our method, yielding state-of-the-art performance for this task.
Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
Nov 01, 2021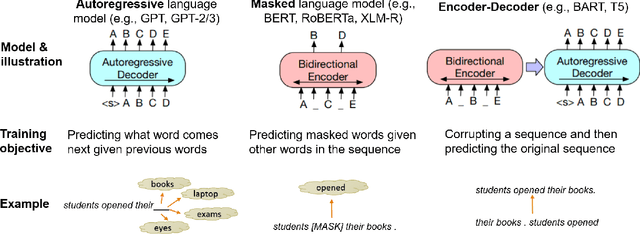
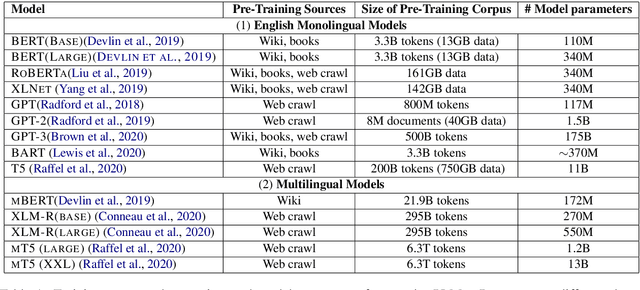
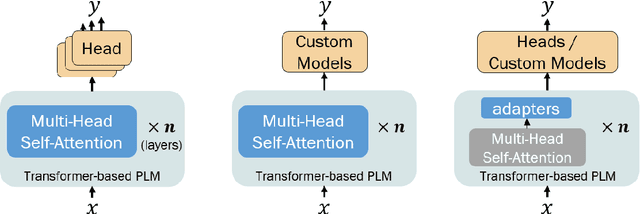

Large, pre-trained transformer-based language models such as BERT have drastically changed the Natural Language Processing (NLP) field. We present a survey of recent work that uses these large language models to solve NLP tasks via pre-training then fine-tuning, prompting, or text generation approaches. We also present approaches that use pre-trained language models to generate data for training augmentation or other purposes. We conclude with discussions on limitations and suggested directions for future research.
Cross-Task Instance Representation Interactions and Label Dependencies for Joint Information Extraction with Graph Convolutional Networks
Mar 26, 2021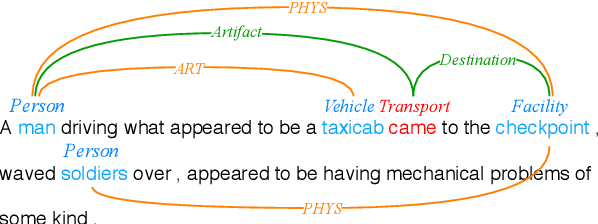
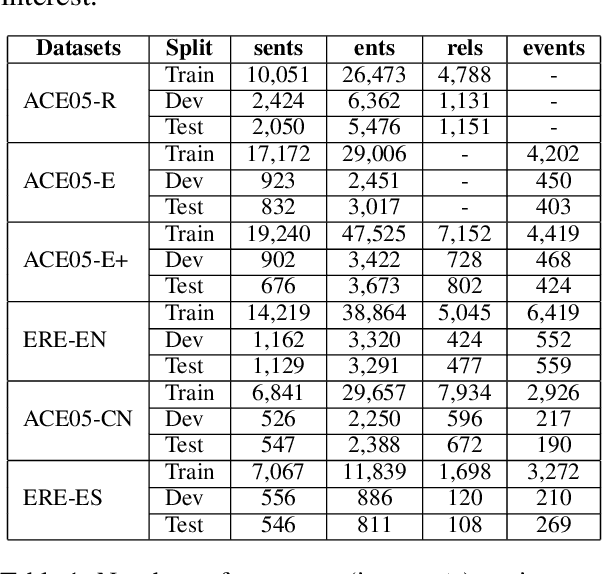
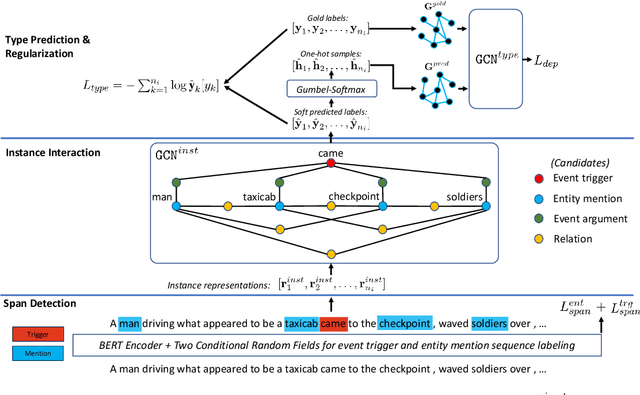
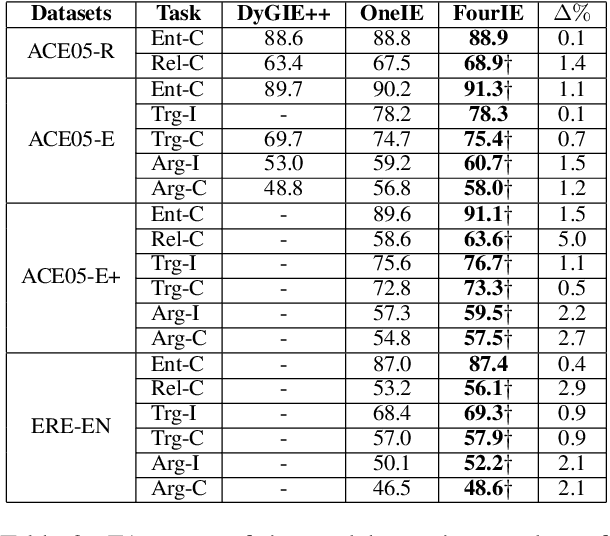
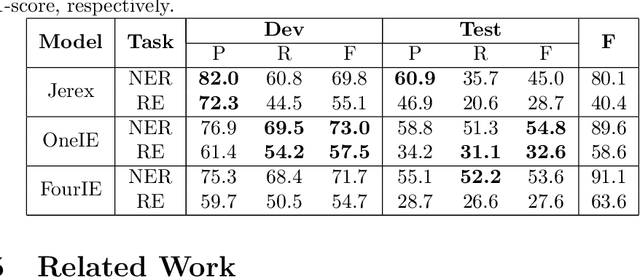
Existing works on information extraction (IE) have mainly solved the four main tasks separately (entity mention recognition, relation extraction, event trigger detection, and argument extraction), thus failing to benefit from inter-dependencies between tasks. This paper presents a novel deep learning model to simultaneously solve the four tasks of IE in a single model (called FourIE). Compared to few prior work on jointly performing four IE tasks, FourIE features two novel contributions to capture inter-dependencies between tasks. First, at the representation level, we introduce an interaction graph between instances of the four tasks that is used to enrich the prediction representation for one instance with those from related instances of other tasks. Second, at the label level, we propose a dependency graph for the information types in the four IE tasks that captures the connections between the types expressed in an input sentence. A new regularization mechanism is introduced to enforce the consistency between the golden and predicted type dependency graphs to improve representation learning. We show that the proposed model achieves the state-of-the-art performance for joint IE on both monolingual and multilingual learning settings with three different languages.