 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multilingual Neural Machine Translation with Universal Encoder and Decoder
Nov 15, 2016
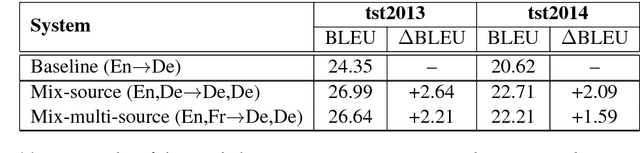
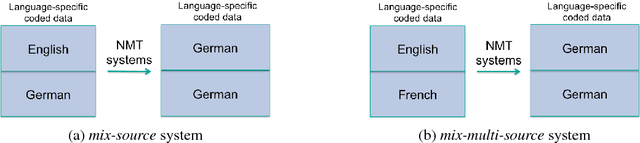
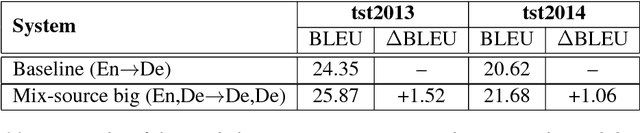
In this paper, we present our first attempts in building a multilingual Neural Machine Translation framework under a unified approach. We are then able to employ attention-based NMT for many-to-many multilingual translation tasks. Our approach does not require any special treatment on the network architecture and it allows us to learn minimal number of free parameters in a standard way of training. Our approach has shown its effectiveness in an under-resourced translation scenario with considerable improvements up to 2.6 BLEU points. In addition, the approach has achieved interesting and promising results when applied in the translation task that there is no direct parallel corpus between source and target languages.
Pre-Translation for Neural Machine Translation
Oct 17, 2016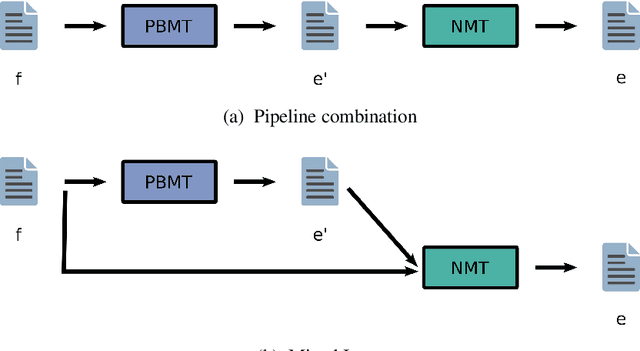
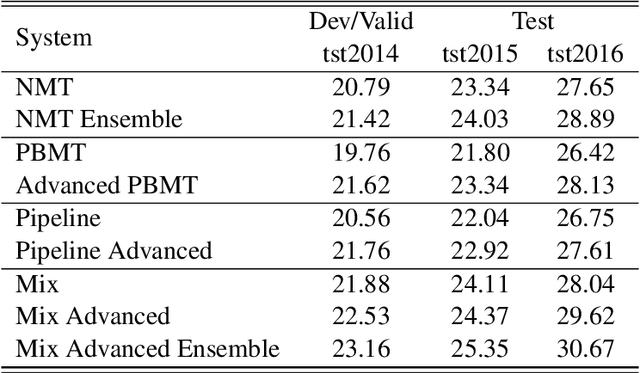
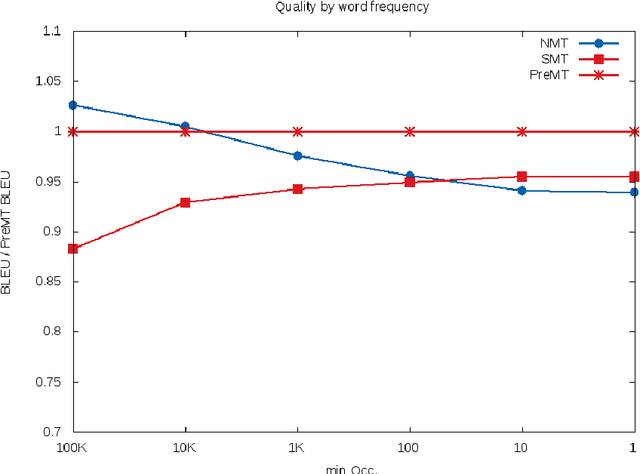

Recently, the development of neural machine translation (NMT) has significantly improved the translation quality of automatic machine translation. While most sentences are more accurate and fluent than translations by statistical machine translation (SMT)-based systems, in some cases, the NMT system produces translations that have a completely different meaning. This is especially the case when rare words occur. When using statistical machine translation, it has already been shown that significant gains can be achieved by simplifying the input in a preprocessing step. A commonly used example is the pre-reordering approach. In this work, we used phrase-based machine translation to pre-translate the input into the target language. Then a neural machine translation system generates the final hypothesis using the pre-translation. Thereby, we use either only the output of the phrase-based machine translation (PBMT) system or a combination of the PBMT output and the source sentence. We evaluate the technique on the English to German translation task. Using this approach we are able to outperform the PBMT system as well as the baseline neural MT system by up to 2 BLEU points. We analyzed the influence of the quality of the initial system on the final result.
Lexical Translation Model Using a Deep Neural Network Architecture
Apr 28, 2015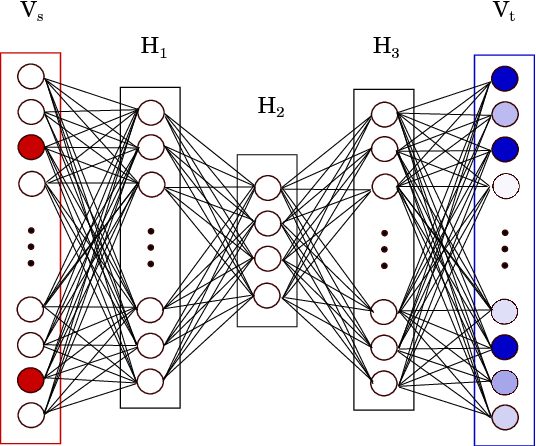
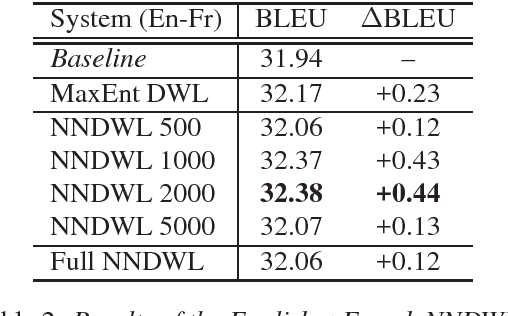
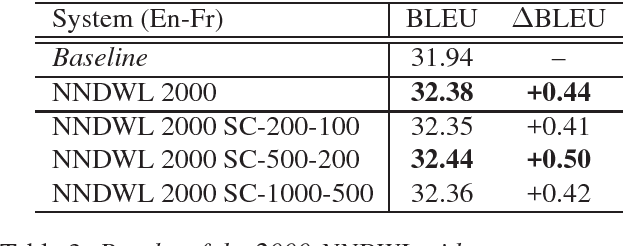
In this paper we combine the advantages of a model using global source sentence contexts, the Discriminative Word Lexicon, and neural networks. By using deep neural networks instead of the linear maximum entropy model in the Discriminative Word Lexicon models, we are able to leverage dependencies between different source words due to the non-linearity. Furthermore, the models for different target words can share parameters and therefore data sparsity problems are effectively reduced. By using this approach in a state-of-the-art translation system, we can improve the performance by up to 0.5 BLEU points for three different language pairs on the TED translation task.