 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganizing Encyclopedic Knowledge based on the Web and its Application to Question Answering
Jun 10, 2001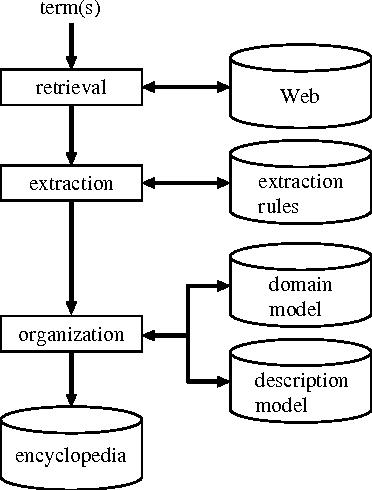

We propose a method to generate large-scale encyclopedic knowledge, which is valuable for much NLP research, based on the Web. We first search the Web for pages containing a term in question. Then we use linguistic patterns and HTML structures to extract text fragments describing the term. Finally, we organize extracted term descriptions based on word senses and domains. In addition, we apply an automatically generated encyclopedia to a question answering system targeting the Japanese Information-Technology Engineers Examination.
* 8 pages, Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics (To appear)
Applying Machine Translation to Two-Stage Cross-Language Information Retrieval
Nov 02, 2000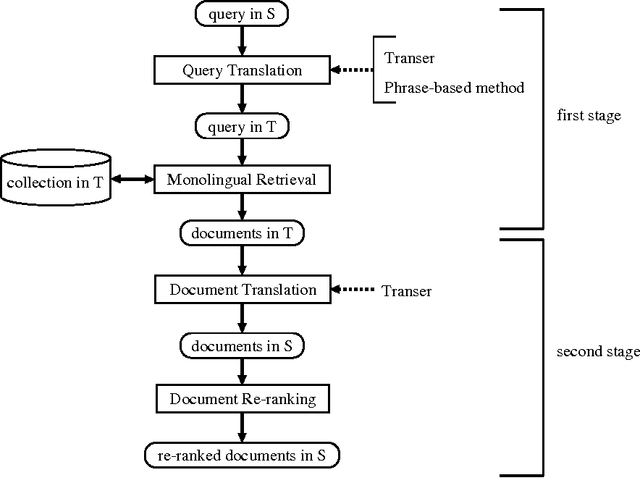
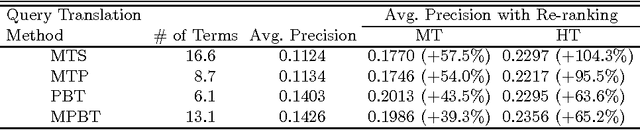

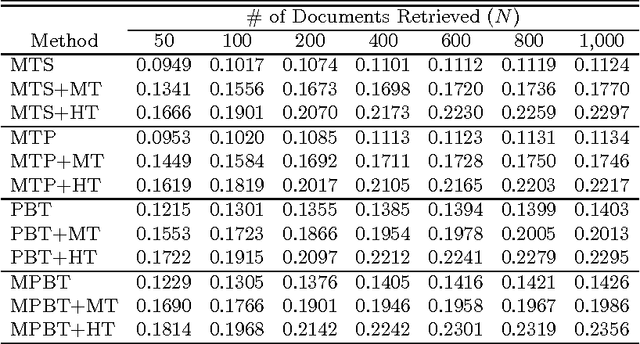
Cross-language information retrieval (CLIR), where queries and documents are in different languages, needs a translation of queries and/or documents, so as to standardize both of them into a common representation. For this purpose, the use of machine translation is an effective approach. However, computational cost is prohibitive in translating large-scale document collections. To resolve this problem, we propose a two-stage CLIR method. First, we translate a given query into the document language, and retrieve a limited number of foreign documents. Second, we machine translate only those documents into the user language, and re-rank them based on the translation result. We also show the effectiveness of our method by way of experiments using Japanese queries and English technical documents.
* 13 pages, 1 Postscript figure
A Novelty-based Evaluation Method for Information Retrieval
Nov 02, 2000
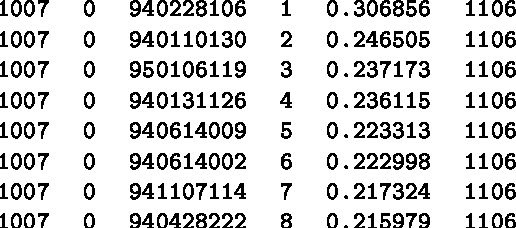
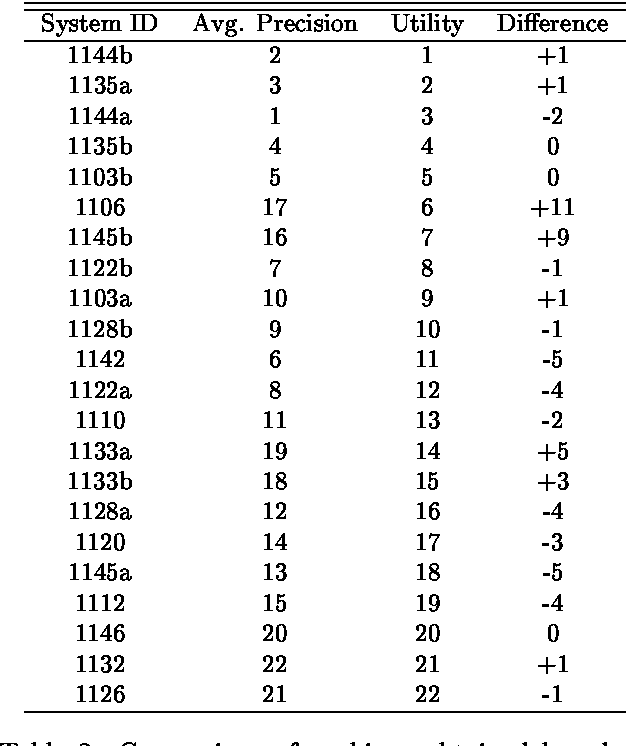
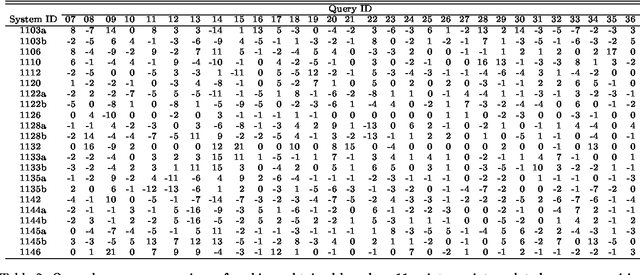
In information retrieval research, precision and recall have long been used to evaluate IR systems. However, given that a number of retrieval systems resembling one another are already available to the public, it is valuable to retrieve novel relevant documents, i.e., documents that cannot be retrieved by those existing systems. In view of this problem, we propose an evaluation method that favors systems retrieving as many novel documents as possible. We also used our method to evaluate systems that participated in the IREX workshop.
* 5 pages
Utilizing the World Wide Web as an Encyclopedia: Extracting Term Descriptions from Semi-Structured Texts
Nov 02, 2000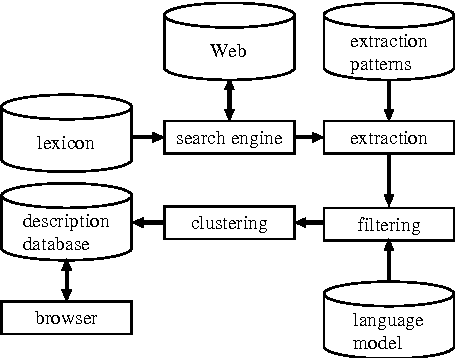
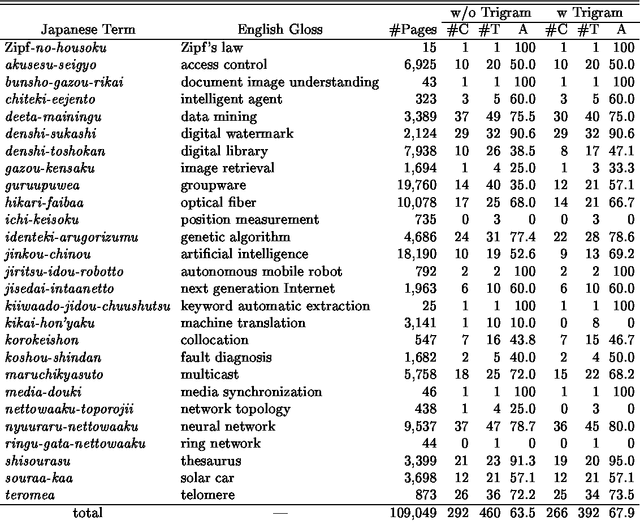
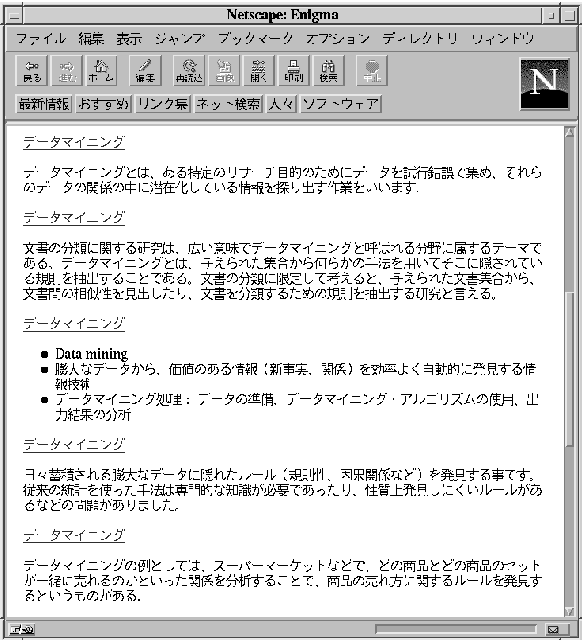

In this paper, we propose a method to extract descriptions of technical terms from Web pages in order to utilize the World Wide Web as an encyclopedia. We use linguistic patterns and HTML text structures to extract text fragments containing term descriptions. We also use a language model to discard extraneous descriptions, and a clustering method to summarize resultant descriptions. We show the effectiveness of our method by way of experiments.
* 8 pages, 2 Postscript figures
Cross-Language Information Retrieval for Technical Documents
Jul 07, 1999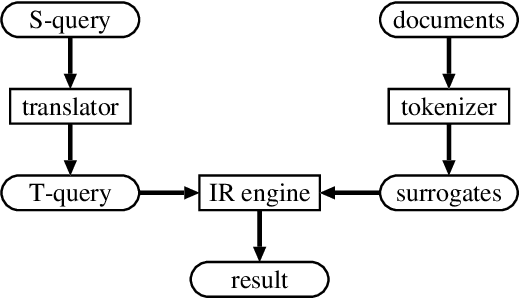
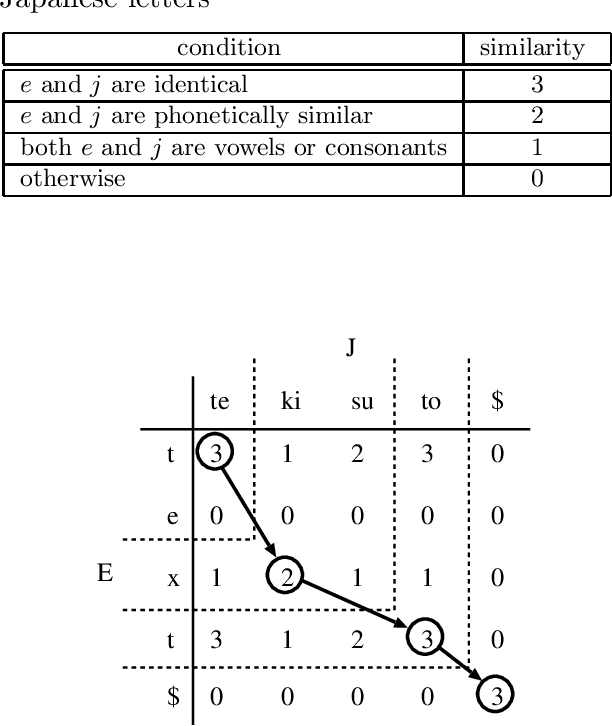

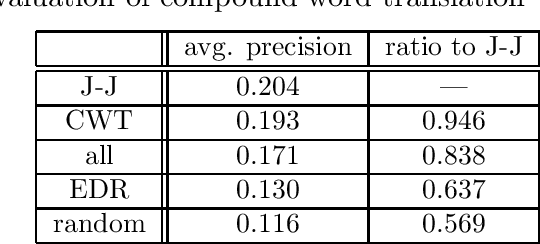
This paper proposes a Japanese/English cross-language information retrieval (CLIR) system targeting technical documents. Our system first translates a given query containing technical terms into the target language, and then retrieves documents relevant to the translated query. The translation of technical terms is still problematic in that technical terms are often compound words, and thus new terms can be progressively created simply by combining existing base words. In addition, Japanese often represents loanwords based on its phonogram. Consequently, existing dictionaries find it difficult to achieve sufficient coverage. To counter the first problem, we use a compound word translation method, which uses a bilingual dictionary for base words and collocational statistics to resolve translation ambiguity. For the second problem, we propose a transliteration method, which identifies phonetic equivalents in the target language. We also show the effectiveness of our system using a test collection for CLIR.
* 9 pages, 5 Postscript figures, uses colacl.sty and psfig.tex