 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-Based Low-Power Speech Recognition with Recurrent Neural Networks
Sep 30, 2016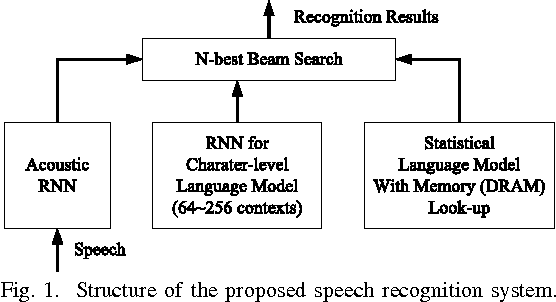
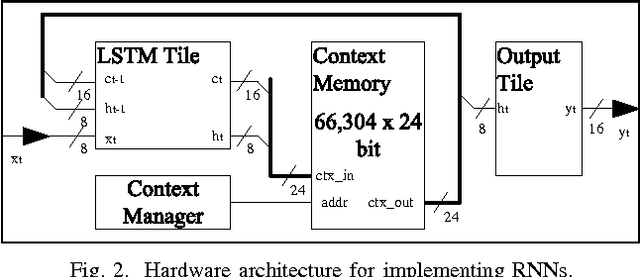
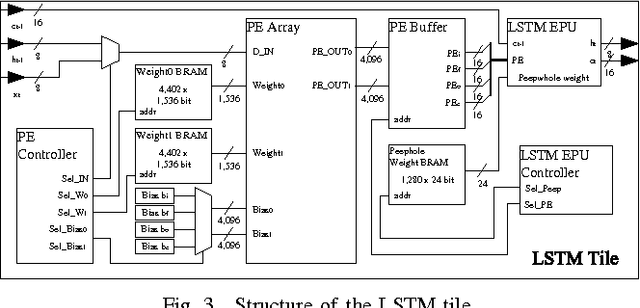
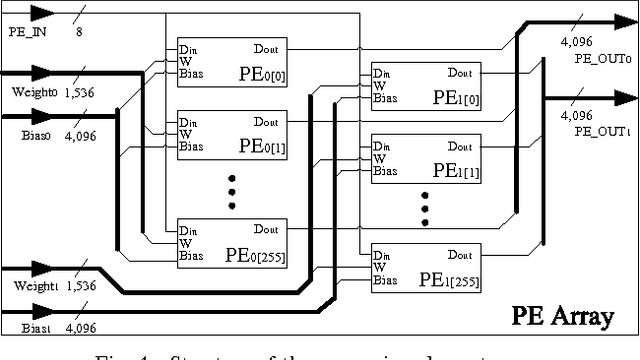
In this paper, a neural network based real-time speech recognition (SR) system is developed using an FPGA for very low-power operation. The implemented system employs two recurrent neural networks (RNNs); one is a speech-to-character RNN for acoustic modeling (AM) and the other is for character-level language modeling (LM). The system also employs a statistical word-level LM to improve the recognition accuracy. The results of the AM, the character-level LM, and the word-level LM are combined using a fairly simple N-best search algorithm instead of the hidden Markov model (HMM) based network. The RNNs are implemented using massively parallel processing elements (PEs) for low latency and high throughput. The weights are quantized to 6 bits to store all of them in the on-chip memory of an FPGA. The proposed algorithm is implemented on a Xilinx XC7Z045, and the system can operate much faster than real-time.
Fixed-Point Performance Analysis of Recurrent Neural Networks
Sep 27, 2016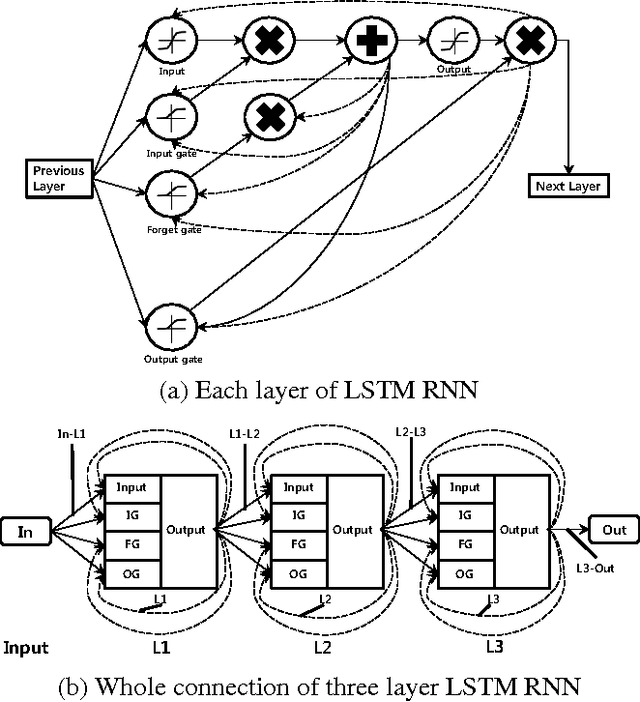
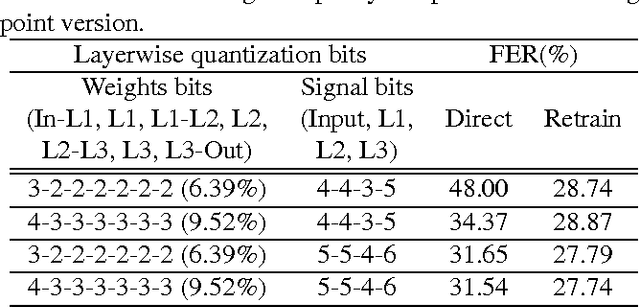
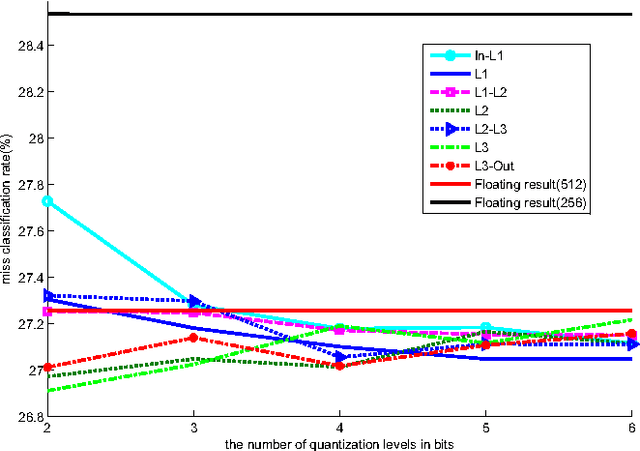
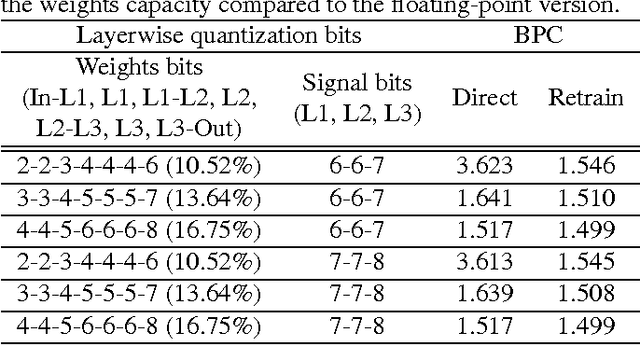
Recurrent neural networks have shown excellent performance in many applications, however they require increased complexity in hardware or software based implementations. The hardware complexity can be much lowered by minimizing the word-length of weights and signals. This work analyzes the fixed-point performance of recurrent neural networks using a retrain based quantization method. The quantization sensitivity of each layer in RNNs is studied, and the overall fixed-point optimization results minimizing the capacity of weights while not sacrificing the performance are presented. A language model and a phoneme recognition examples are used.
Dynamic Hand Gesture Recognition for Wearable Devices with Low Complexity Recurrent Neural Networks
Aug 14, 2016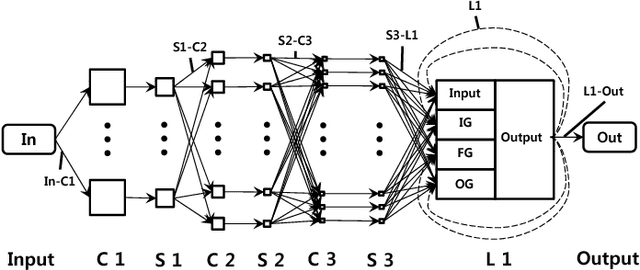
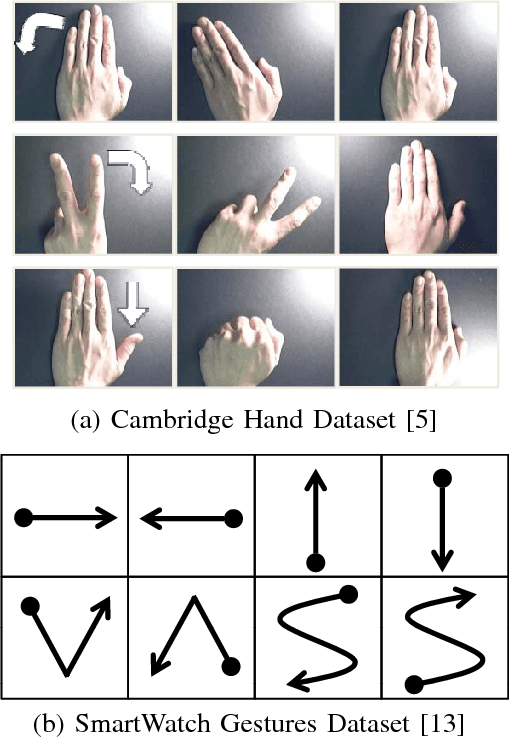

Gesture recognition is a very essential technology for many wearable devices. While previous algorithms are mostly based on statistical methods including the hidden Markov model, we develop two dynamic hand gesture recognition techniques using low complexity recurrent neural network (RNN) algorithms. One is based on video signal and employs a combined structure of a convolutional neural network (CNN) and an RNN. The other uses accelerometer data and only requires an RNN. Fixed-point optimization that quantizes most of the weights into two bits is conducted to optimize the amount of memory size for weight storage and reduce the power consumption in hardware and software based implementations.
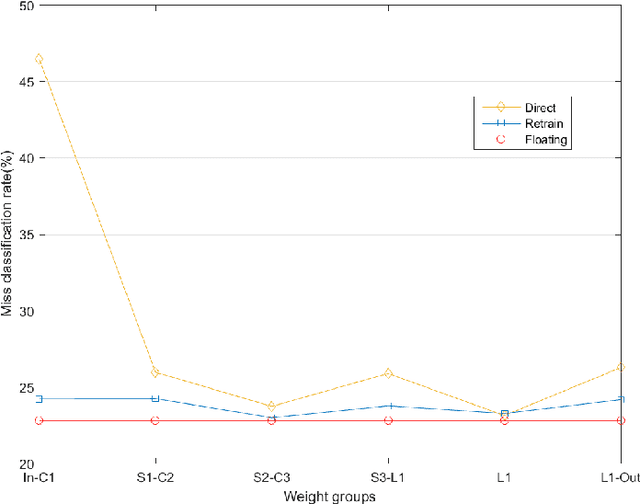
Resiliency of Deep Neural Networks under Quantization
Jan 07, 2016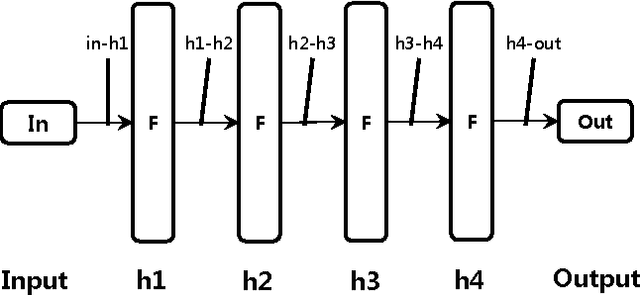
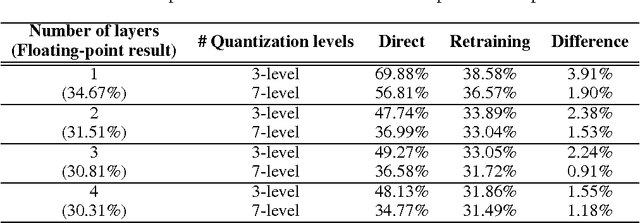
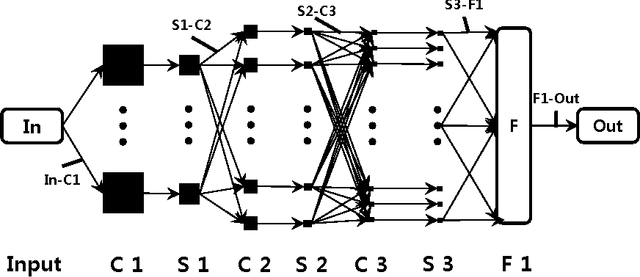
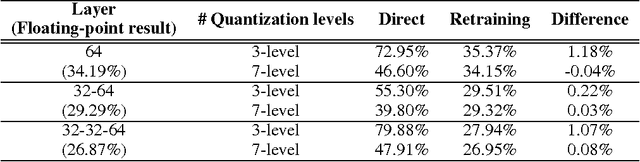
The complexity of deep neural network algorithms for hardware implementation can be much lowered by optimizing the word-length of weights and signals. Direct quantization of floating-point weights, however, does not show good performance when the number of bits assigned is small. Retraining of quantized networks has been developed to relieve this problem. In this work, the effects of retraining are analyzed for a feedforward deep neural network (FFDNN) and a convolutional neural network (CNN). The network complexity is controlled to know their effects on the resiliency of quantized networks by retraining. The complexity of the FFDNN is controlled by varying the unit size in each hidden layer and the number of layers, while that of the CNN is done by modifying the feature map configuration. We find that the performance gap between the floating-point and the retrain-based ternary (+1, 0, -1) weight neural networks exists with a fair amount in 'complexity limited' networks, but the discrepancy almost vanishes in fully complex networks whose capability is limited by the training data, rather than by the number of connections. This research shows that highly complex DNNs have the capability of absorbing the effects of severe weight quantization through retraining, but connection limited networks are less resilient. This paper also presents the effective compression ratio to guide the trade-off between the network size and the precision when the hardware resource is limited.