 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecGANs with Conditional Convolution Layer
Jun 03, 2019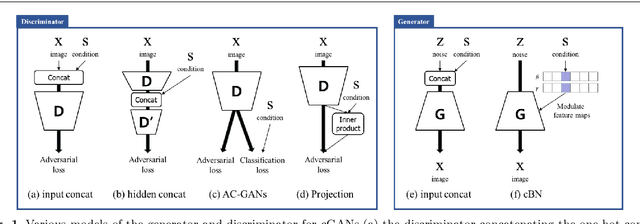

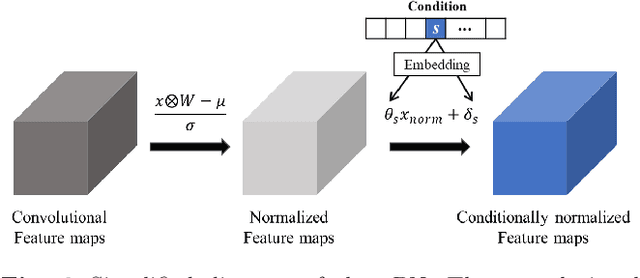

Conditional generative adversarial networks (cGANs) have been widely researched to generate class conditional images using a single generator. However, in the conventional cGANs techniques, it is still challenging for the generator to learn condition-specific features, since a standard convolutional layer with the same weights is used regardless of the condition. In this paper, we propose a novel convolution layer, called the conditional convolution layer, which directly generates different feature maps by employing the weights which are adjusted depending on the conditions. More specifically, in each conditional convolution layer, the weights are conditioned in a simple but effective way through filter-wise scaling and channel-wise shifting operations. In contrast to the conventional methods, the proposed method with a single generator can effectively handle condition-specific characteristics. The experimental results on CIFAR, LSUN and ImageNet datasets show that the generator with the proposed conditional convolution layer achieves a higher quality of conditional image generation than that with the standard convolution layer.
PEPSI++: Fast and Lightweight Network for Image Inpainting
May 22, 2019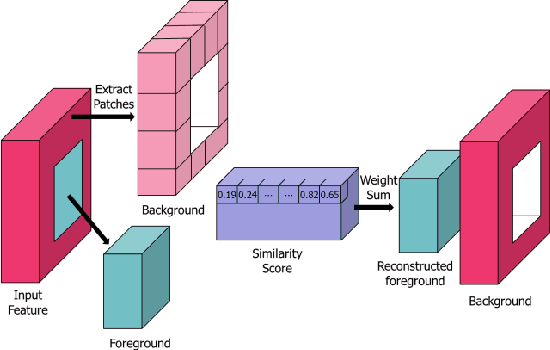
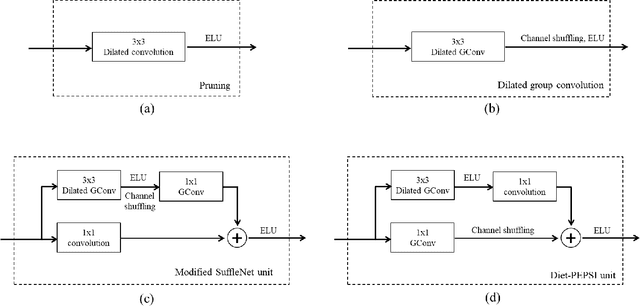


Generative adversarial network (GAN)-based image inpainting methods which utilize coarse-to-fine network with a contextual attention module (CAM) have shown remarkable performance. However, they require numerous computational resources such as convolution operations and network parameters due to two stacked generative networks, which results in a low speed. To address this problem, we propose a novel network structure called PEPSI: parallel extended-decoder path for semantic inpainting network, which aims at not only reducing hardware costs but also improving the inpainting performance. The PEPSI consists of a single shared encoding network and parallel decoding networks with coarse and inpainting paths. The coarse path generates a preliminary inpainting result to train the encoding network for prediction of features for the CAM. At the same time, the inpainting path results in higher inpainting quality with refined features reconstructed using the CAM. In addition, we propose a Diet-PEPSI which significantly reduces the network parameters while maintaining the performance. In the proposed method, we present a Diet-PEPSI unit (DPU) which effectively aggregates the global contextual information with a small number of parameters. Extensive experiments and comparisons with state-of-the-art image inpainting methods demonstrate that both PEPSI and Diet-PEPSI achieve significant improvements in qualitative scores and reduced computation cost.
Unsupervised Deep Power Saving and Contrast Enhancement for OLED Displays
May 15, 2019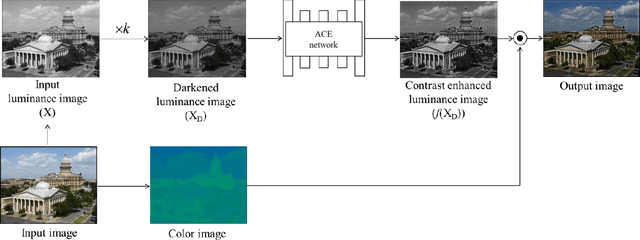

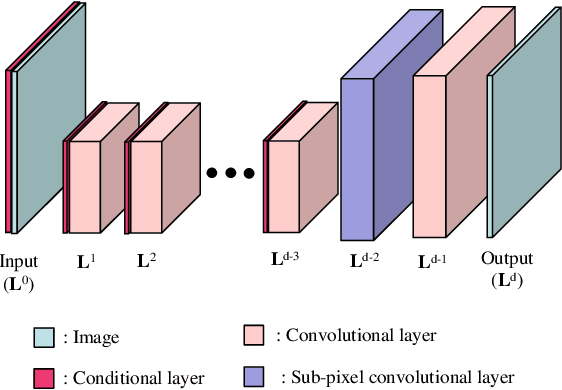

Various power saving and contrast enhancement (PSCE) techniques have been applied to an organic light emitting diode (OLED) display for reducing the power demands of the display while preserving the image quality. In this paper, we propose a new deep learning-based PSCE scheme that can save power consumed by the OLED display while enhancing the contrast of the displayed image. In the proposed method, the power consumption is saved by simply reducing the brightness a certain ratio, whereas the perceived visual quality is preserved as much as possible by enhancing the contrast of the image using a convolutional neural network (CNN). Furthermore, our CNN can learn the PSCE technique without a reference image by unsupervised learning. Experimental results show that the proposed method is superior to conventional ones in terms of image quality assessment metrics such as a visual saliency-induced index (VSI) and a measure of enhancement (EME).