 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Litigation: Graphs and LLMs for Retrieval and Reasoning in eDiscovery
May 29, 2024



Electronic Discovery (eDiscovery) involves identifying relevant documents from a vast collection based on legal production requests. The integration of artificial intelligence (AI) and natural language processing (NLP) has transformed this process, helping document review and enhance efficiency and cost-effectiveness. Although traditional approaches like BM25 or fine-tuned pre-trained models are common in eDiscovery, they face performance, computational, and interpretability challenges. In contrast, Large Language Model (LLM)-based methods prioritize interpretability but sacrifice performance and throughput. This paper introduces DISCOvery Graph (DISCOG), a hybrid approach that combines the strengths of two worlds: a heterogeneous graph-based method for accurate document relevance prediction and subsequent LLM-driven approach for reasoning. Graph representational learning generates embeddings and predicts links, ranking the corpus for a given request, and the LLMs provide reasoning for document relevance. Our approach handles datasets with balanced and imbalanced distributions, outperforming baselines in F1-score, precision, and recall by an average of 12%, 3%, and 16%, respectively. In an enterprise context, our approach drastically reduces document review costs by 99.9% compared to manual processes and by 95% compared to LLM-based classification methods
Learning Embeddings from Knowledge Graphs With Numeric Edge Attributes
May 18, 2021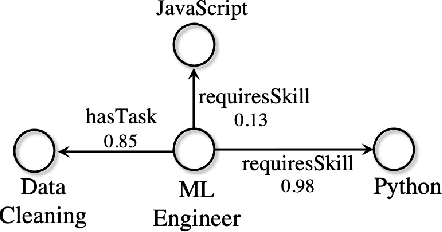
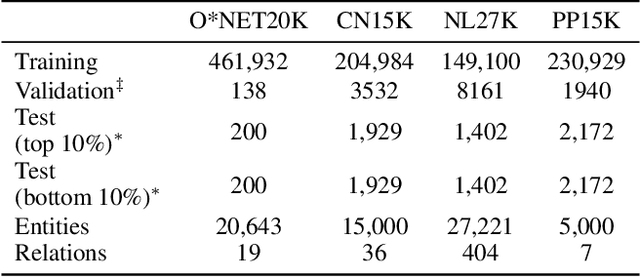

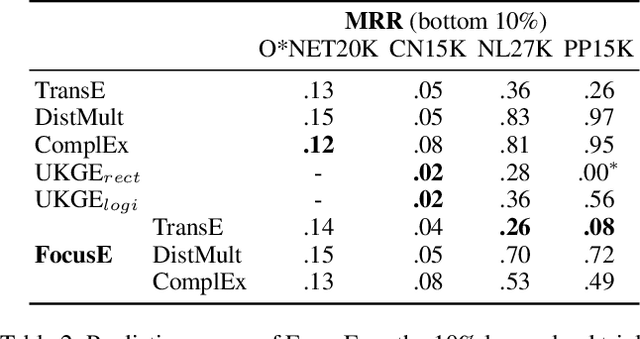
Numeric values associated to edges of a knowledge graph have been used to represent uncertainty, edge importance, and even out-of-band knowledge in a growing number of scenarios, ranging from genetic data to social networks. Nevertheless, traditional knowledge graph embedding models are not designed to capture such information, to the detriment of predictive power. We propose a novel method that injects numeric edge attributes into the scoring layer of a traditional knowledge graph embedding architecture. Experiments with publicly available numeric-enriched knowledge graphs show that our method outperforms traditional numeric-unaware baselines as well as the recent UKGE model.
Background Knowledge Injection for Interpretable Sequence Classification
Jun 25, 2020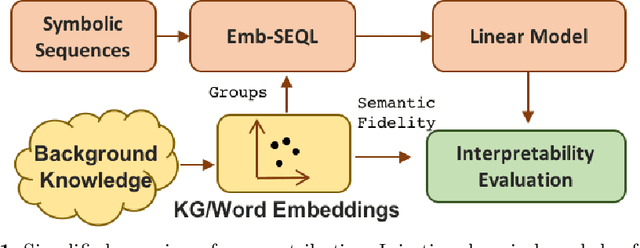
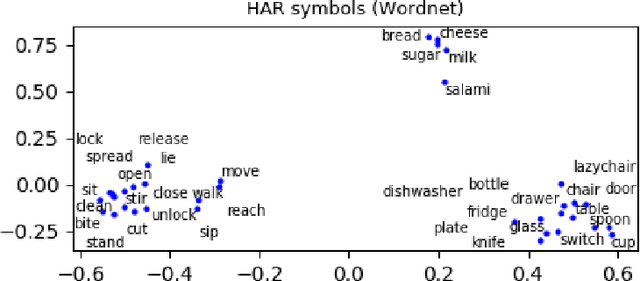
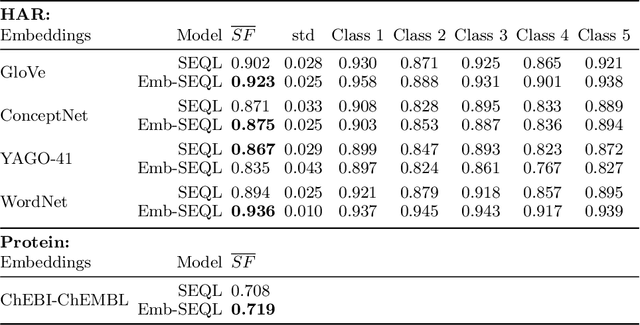
Sequence classification is the supervised learning task of building models that predict class labels of unseen sequences of symbols. Although accuracy is paramount, in certain scenarios interpretability is a must. Unfortunately, such trade-off is often hard to achieve since we lack human-independent interpretability metrics. We introduce a novel sequence learning algorithm, that combines (i) linear classifiers - which are known to strike a good balance between predictive power and interpretability, and (ii) background knowledge embeddings. We extend the classic subsequence feature space with groups of symbols which are generated by background knowledge injected via word or graph embeddings, and use this new feature space to learn a linear classifier. We also present a new measure to evaluate the interpretability of a set of symbolic features based on the symbol embeddings. Experiments on human activity recognition from wearables and amino acid sequence classification show that our classification approach preserves predictive power, while delivering more interpretable models.