 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSudheendra Vijayanarasimhan
End-to-End Learning of Semantic Grasping
Nov 09, 2017

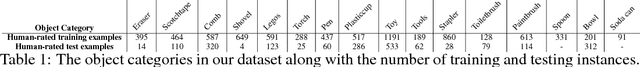
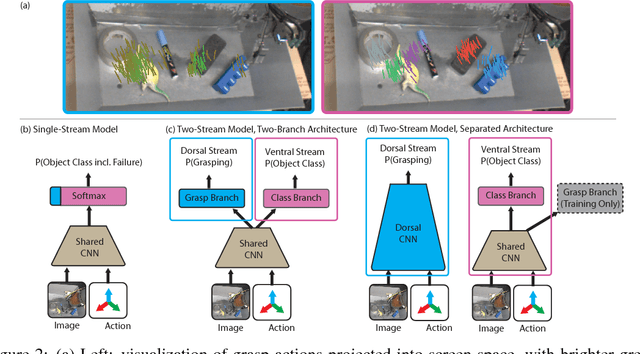
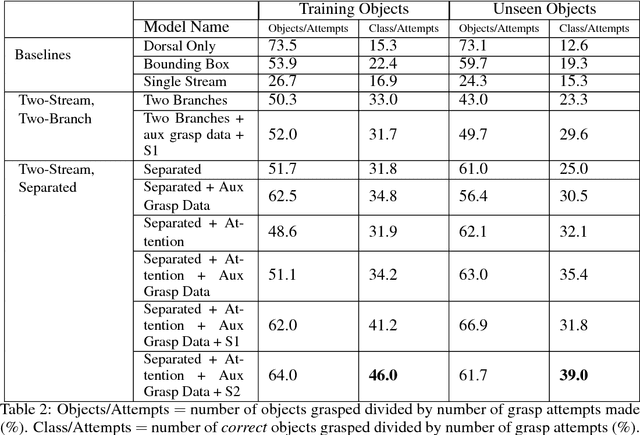
We consider the task of semantic robotic grasping, in which a robot picks up an object of a user-specified class using only monocular images. Inspired by the two-stream hypothesis of visual reasoning, we present a semantic grasping framework that learns object detection, classification, and grasp planning in an end-to-end fashion. A "ventral stream" recognizes object class while a "dorsal stream" simultaneously interprets the geometric relationships necessary to execute successful grasps. We leverage the autonomous data collection capabilities of robots to obtain a large self-supervised dataset for training the dorsal stream, and use semi-supervised label propagation to train the ventral stream with only a modest amount of human supervision. We experimentally show that our approach improves upon grasping systems whose components are not learned end-to-end, including a baseline method that uses bounding box detection. Furthermore, we show that jointly training our model with auxiliary data consisting of non-semantic grasping data, as well as semantically labeled images without grasp actions, has the potential to substantially improve semantic grasping performance.
The Kinetics Human Action Video Dataset
May 19, 2017
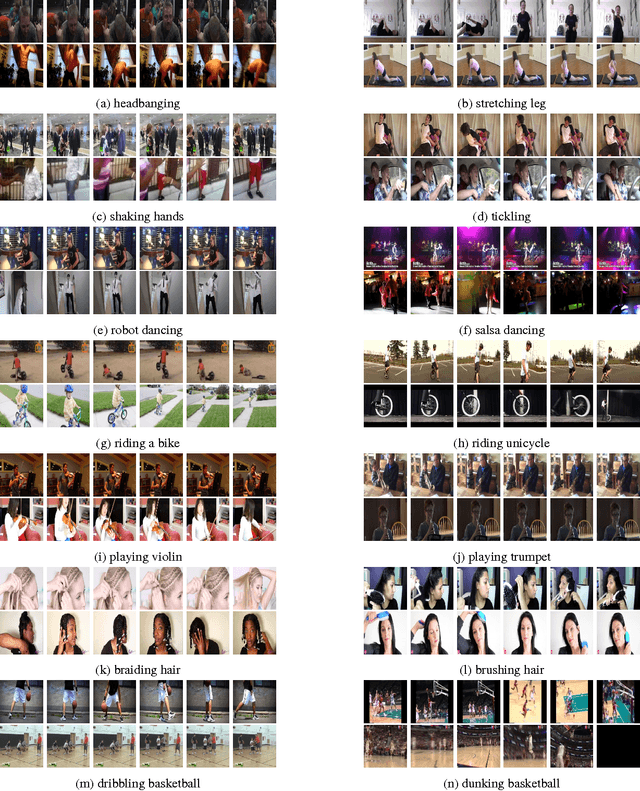
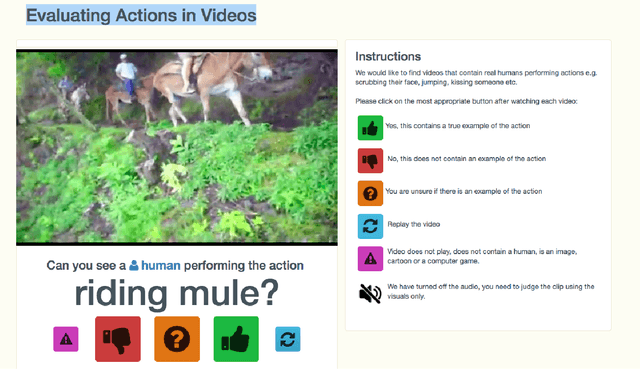
We describe the DeepMind Kinetics human action video dataset. The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands. We describe the statistics of the dataset, how it was collected, and give some baseline performance figures for neural network architectures trained and tested for human action classification on this dataset. We also carry out a preliminary analysis of whether imbalance in the dataset leads to bias in the classifiers.
Motion Prediction Under Multimodality with Conditional Stochastic Networks
May 05, 2017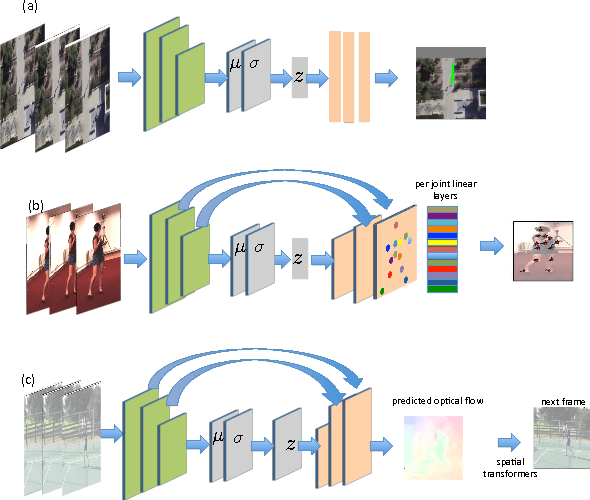
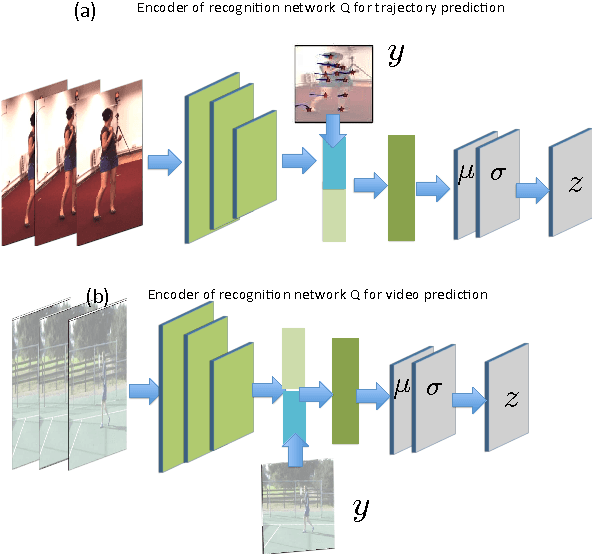

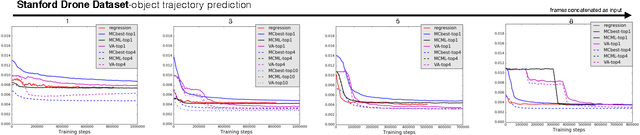
Given a visual history, multiple future outcomes for a video scene are equally probable, in other words, the distribution of future outcomes has multiple modes. Multimodality is notoriously hard to handle by standard regressors or classifiers: the former regress to the mean and the latter discretize a continuous high dimensional output space. In this work, we present stochastic neural network architectures that handle such multimodality through stochasticity: future trajectories of objects, body joints or frames are represented as deep, non-linear transformations of random (as opposed to deterministic) variables. Such random variables are sampled from simple Gaussian distributions whose means and variances are parametrized by the output of convolutional encoders over the visual history. We introduce novel convolutional architectures for predicting future body joint trajectories that outperform fully connected alternatives \cite{DBLP:journals/corr/WalkerDGH16}. We introduce stochastic spatial transformers through optical flow warping for predicting future frames, which outperform their deterministic equivalents \cite{DBLP:journals/corr/PatrauceanHC15}. Training stochastic networks involves an intractable marginalization over stochastic variables. We compare various training schemes that handle such marginalization through a) straightforward sampling from the prior, b) conditional variational autoencoders \cite{NIPS2015_5775,DBLP:journals/corr/WalkerDGH16}, and, c) a proposed K-best-sample loss that penalizes the best prediction under a fixed "prediction budget". We show experimental results on object trajectory prediction, human body joint trajectory prediction and video prediction under varying future uncertainty, validating quantitatively and qualitatively our architectural choices and training schemes.
SfM-Net: Learning of Structure and Motion from Video
Apr 25, 2017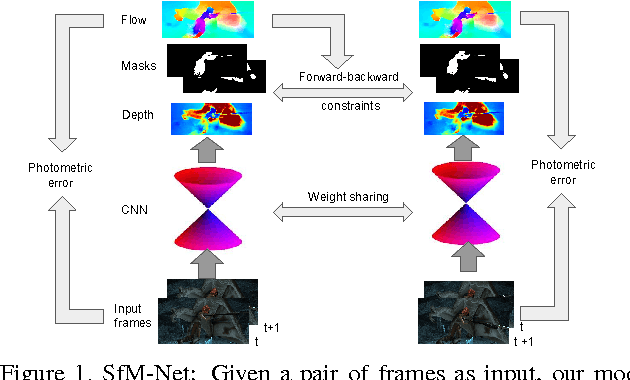
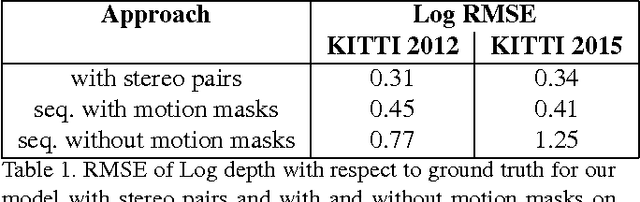
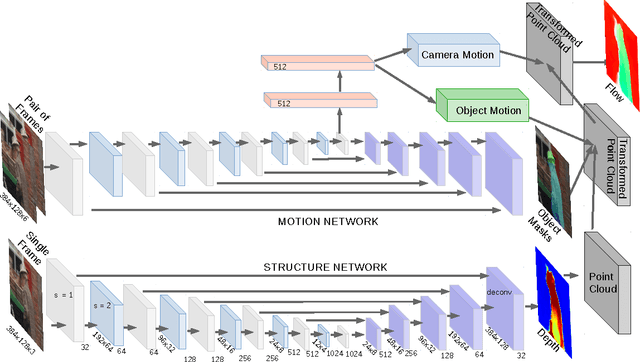
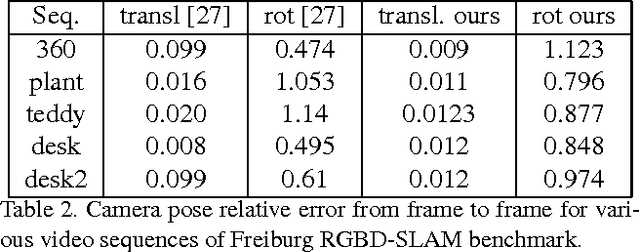
We propose SfM-Net, a geometry-aware neural network for motion estimation in videos that decomposes frame-to-frame pixel motion in terms of scene and object depth, camera motion and 3D object rotations and translations. Given a sequence of frames, SfM-Net predicts depth, segmentation, camera and rigid object motions, converts those into a dense frame-to-frame motion field (optical flow), differentiably warps frames in time to match pixels and back-propagates. The model can be trained with various degrees of supervision: 1) self-supervised by the re-projection photometric error (completely unsupervised), 2) supervised by ego-motion (camera motion), or 3) supervised by depth (e.g., as provided by RGBD sensors). SfM-Net extracts meaningful depth estimates and successfully estimates frame-to-frame camera rotations and translations. It often successfully segments the moving objects in the scene, even though such supervision is never provided.
YouTube-8M: A Large-Scale Video Classification Benchmark
Sep 27, 2016
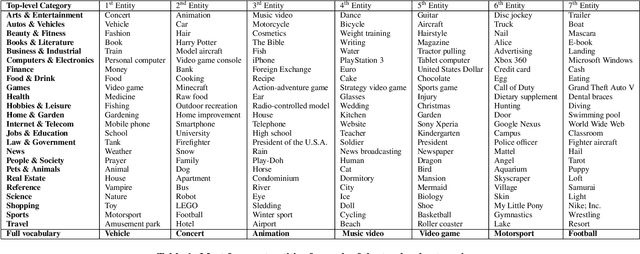
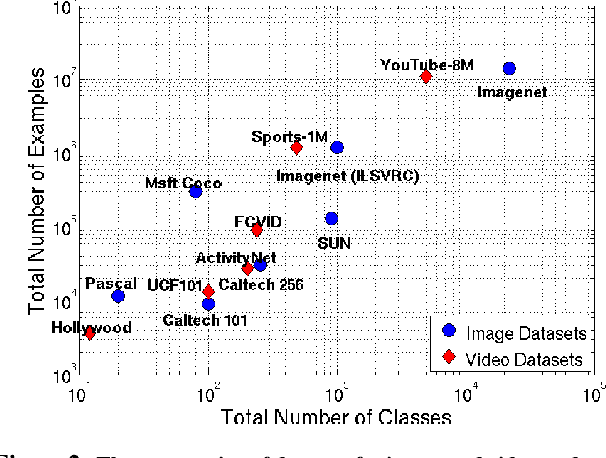

Many recent advancements in Computer Vision are attributed to large datasets. Open-source software packages for Machine Learning and inexpensive commodity hardware have reduced the barrier of entry for exploring novel approaches at scale. It is possible to train models over millions of examples within a few days. Although large-scale datasets exist for image understanding, such as ImageNet, there are no comparable size video classification datasets. In this paper, we introduce YouTube-8M, the largest multi-label video classification dataset, composed of ~8 million videos (500K hours of video), annotated with a vocabulary of 4800 visual entities. To get the videos and their labels, we used a YouTube video annotation system, which labels videos with their main topics. While the labels are machine-generated, they have high-precision and are derived from a variety of human-based signals including metadata and query click signals. We filtered the video labels (Knowledge Graph entities) using both automated and manual curation strategies, including asking human raters if the labels are visually recognizable. Then, we decoded each video at one-frame-per-second, and used a Deep CNN pre-trained on ImageNet to extract the hidden representation immediately prior to the classification layer. Finally, we compressed the frame features and make both the features and video-level labels available for download. We trained various (modest) classification models on the dataset, evaluated them using popular evaluation metrics, and report them as baselines. Despite the size of the dataset, some of our models train to convergence in less than a day on a single machine using TensorFlow. We plan to release code for training a TensorFlow model and for computing metrics.
Efficient Large Scale Video Classification
May 22, 2015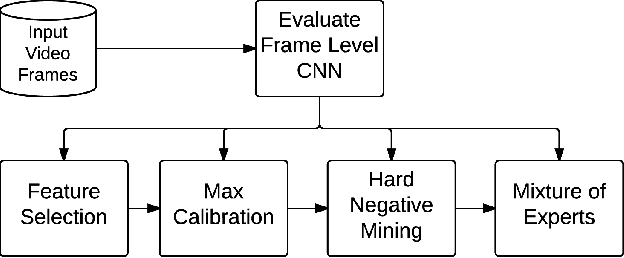

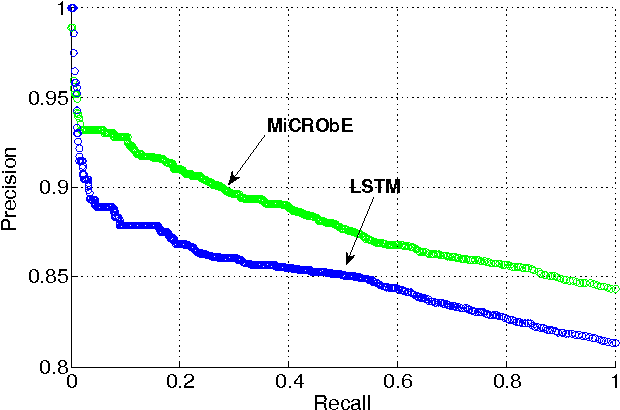
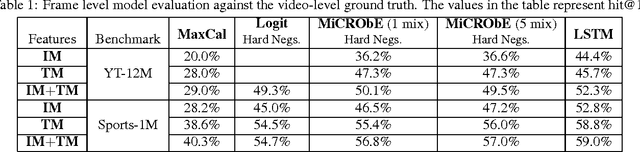
Video classification has advanced tremendously over the recent years. A large part of the improvements in video classification had to do with the work done by the image classification community and the use of deep convolutional networks (CNNs) which produce competitive results with hand- crafted motion features. These networks were adapted to use video frames in various ways and have yielded state of the art classification results. We present two methods that build on this work, and scale it up to work with millions of videos and hundreds of thousands of classes while maintaining a low computational cost. In the context of large scale video processing, training CNNs on video frames is extremely time consuming, due to the large number of frames involved. We propose to avoid this problem by training CNNs on either YouTube thumbnails or Flickr images, and then using these networks' outputs as features for other higher level classifiers. We discuss the challenges of achieving this and propose two models for frame-level and video-level classification. The first is a highly efficient mixture of experts while the latter is based on long short term memory neural networks. We present results on the Sports-1M video dataset (1 million videos, 487 classes) and on a new dataset which has 12 million videos and 150,000 labels.
Beyond Short Snippets: Deep Networks for Video Classification
Apr 13, 2015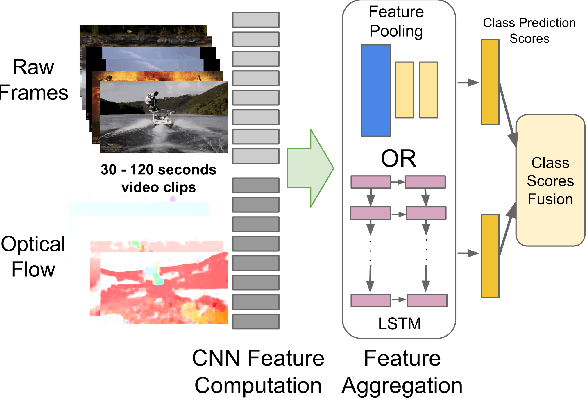
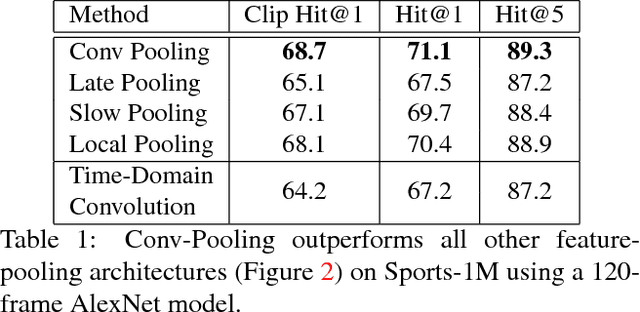
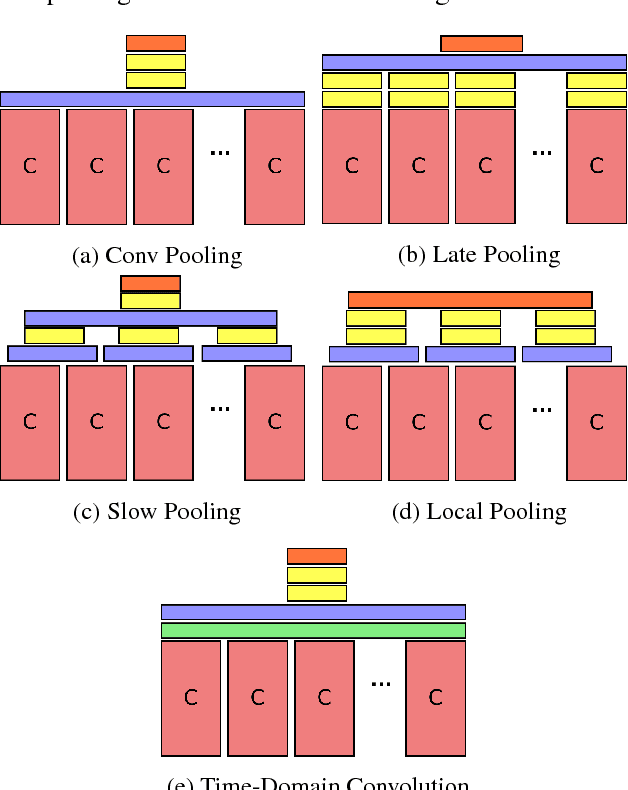
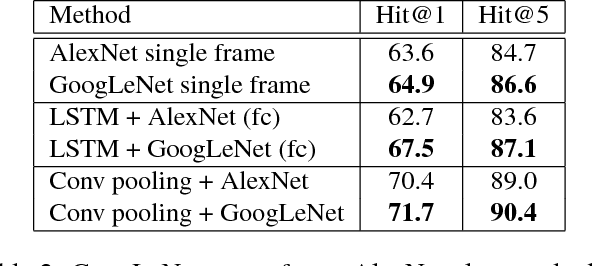
Convolutional neural networks (CNNs) have been extensively applied for image recognition problems giving state-of-the-art results on recognition, detection, segmentation and retrieval. In this work we propose and evaluate several deep neural network architectures to combine image information across a video over longer time periods than previously attempted. We propose two methods capable of handling full length videos. The first method explores various convolutional temporal feature pooling architectures, examining the various design choices which need to be made when adapting a CNN for this task. The second proposed method explicitly models the video as an ordered sequence of frames. For this purpose we employ a recurrent neural network that uses Long Short-Term Memory (LSTM) cells which are connected to the output of the underlying CNN. Our best networks exhibit significant performance improvements over previously published results on the Sports 1 million dataset (73.1% vs. 60.9%) and the UCF-101 datasets with (88.6% vs. 88.0%) and without additional optical flow information (82.6% vs. 72.8%).
Deep Networks With Large Output Spaces
Apr 10, 2015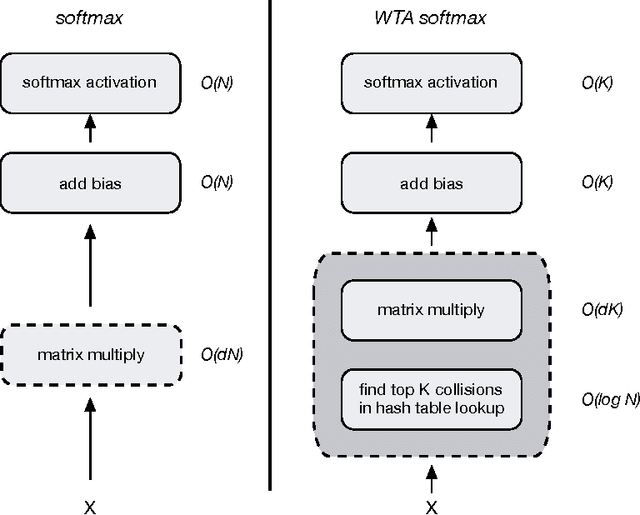
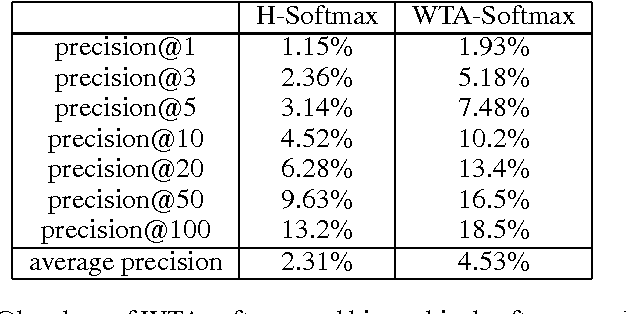
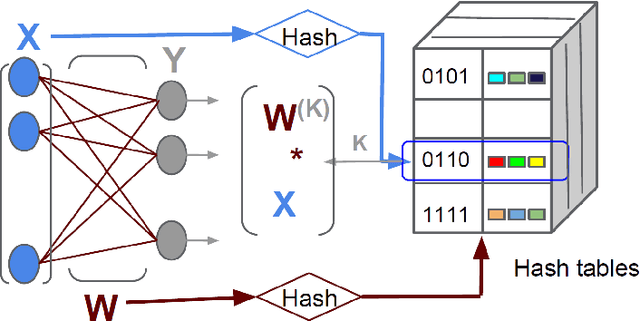
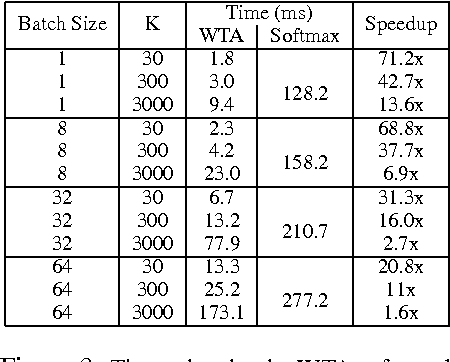
Deep neural networks have been extremely successful at various image, speech, video recognition tasks because of their ability to model deep structures within the data. However, they are still prohibitively expensive to train and apply for problems containing millions of classes in the output layer. Based on the observation that the key computation common to most neural network layers is a vector/matrix product, we propose a fast locality-sensitive hashing technique to approximate the actual dot product enabling us to scale up the training and inference to millions of output classes. We evaluate our technique on three diverse large-scale recognition tasks and show that our approach can train large-scale models at a faster rate (in terms of steps/total time) compared to baseline methods.