 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLTK: The Natural Language Toolkit
May 17, 2002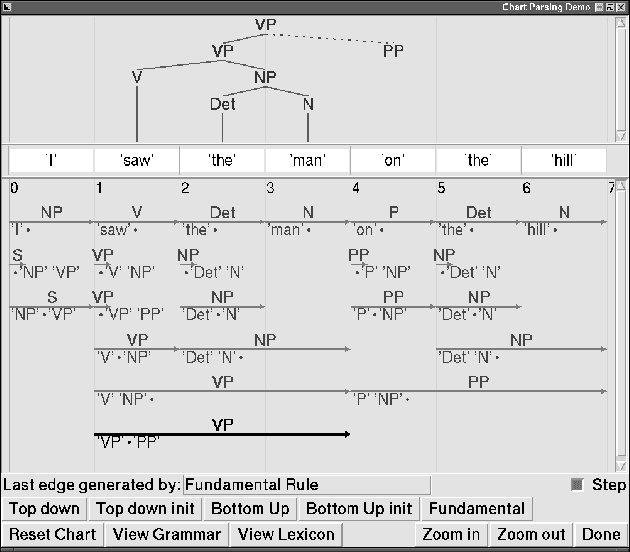
NLTK, the Natural Language Toolkit, is a suite of open source program modules, tutorials and problem sets, providing ready-to-use computational linguistics courseware. NLTK covers symbolic and statistical natural language processing, and is interfaced to annotated corpora. Students augment and replace existing components, learn structured programming by example, and manipulate sophisticated models from the outset.
Querying Databases of Annotated Speech
Apr 11, 2002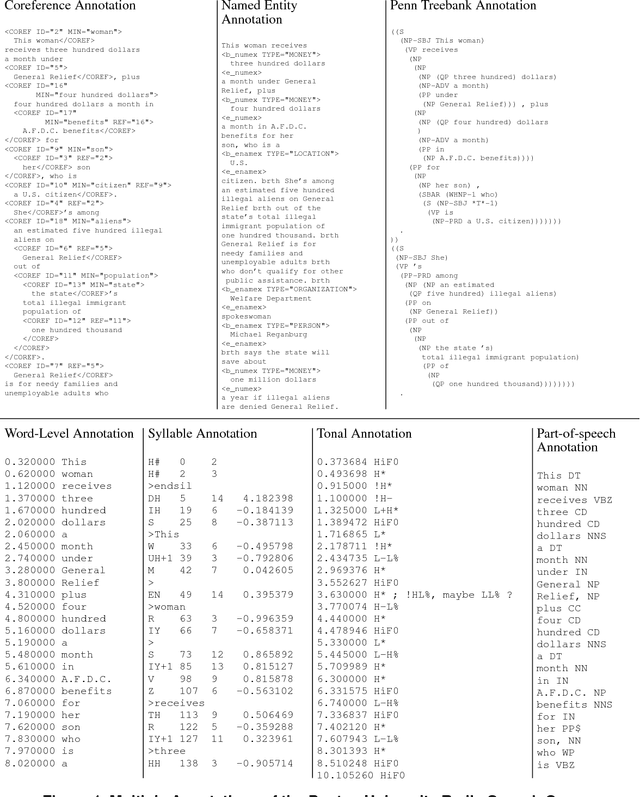
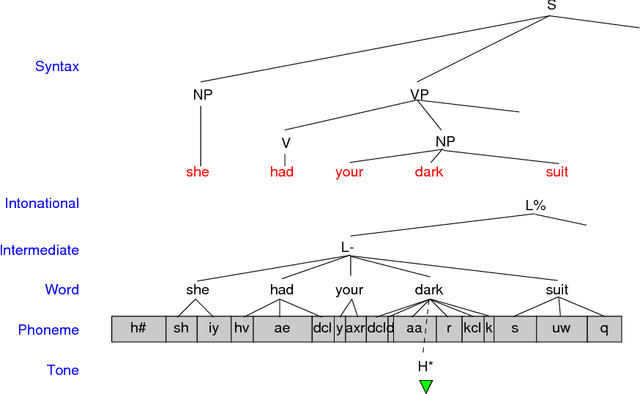
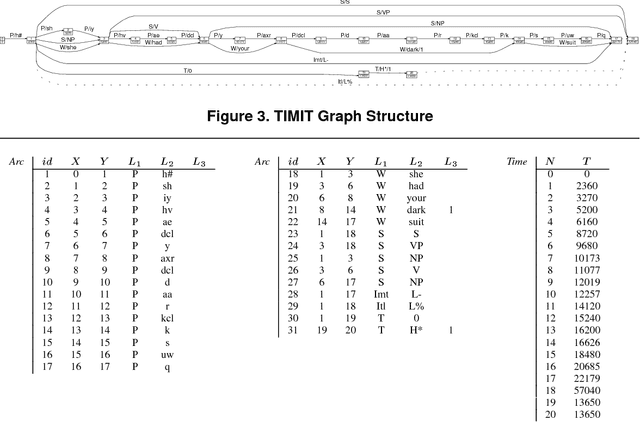
Annotated speech corpora are databases consisting of signal data along with time-aligned symbolic `transcriptions'. Such databases are typically multidimensional, heterogeneous and dynamic. These properties present a number of tough challenges for representation and query. The temporal nature of the data adds an additional layer of complexity. This paper presents and harmonises two independent efforts to model annotated speech databases, one at Macquarie University and one at the University of Pennsylvania. Various query languages are described, along with illustrative applications to a variety of analytical problems. The research reported here forms a part of several ongoing projects to develop platform-independent open-source tools for creating, browsing, searching, querying and transforming linguistic databases, and to disseminate large linguistic databases over the internet.
* 9 pages, 4 figures
Phonology
Apr 11, 2002

Phonology is the systematic study of the sounds used in language, their internal structure, and their composition into syllables, words and phrases. Computational phonology is the application of formal and computational techniques to the representation and processing of phonological information. This chapter will present the fundamentals of descriptive phonology along with a brief overview of computational phonology.
* 27 pages
Computational Phonology
Apr 10, 2002Phonology, as it is practiced, is deeply computational. Phonological analysis is data-intensive and the resulting models are nothing other than specialized data structures and algorithms. In the past, phonological computation - managing data and developing analyses - was done manually with pencil and paper. Increasingly, with the proliferation of affordable computers, IPA fonts and drawing software, phonologists are seeking to move their computation work online. Computational Phonology provides the theoretical and technological framework for this migration, building on methodologies and tools from computational linguistics. This piece consists of an apology for computational phonology, a history, and an overview of current research.
* 4 pages
Annotation Graphs and Servers and Multi-Modal Resources: Infrastructure for Interdisciplinary Education, Research and Development
Apr 10, 2002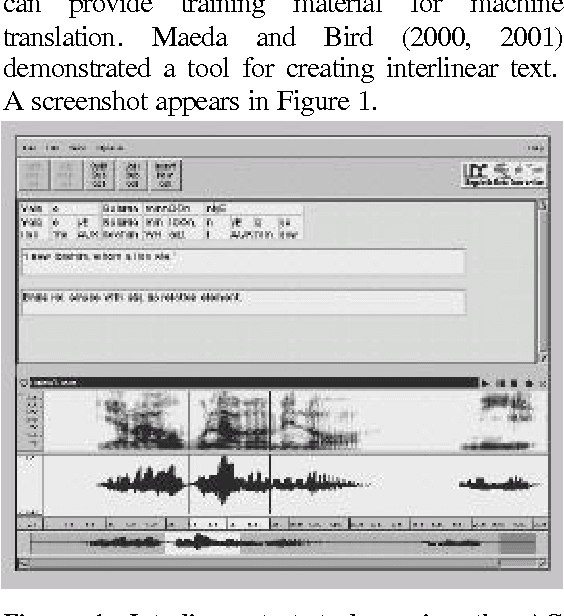
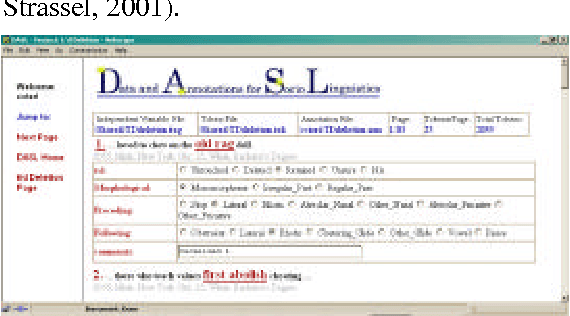

Annotation graphs and annotation servers offer infrastructure to support the analysis of human language resources in the form of time-series data such as text, audio and video. This paper outlines areas of common need among empirical linguists and computational linguists. After reviewing examples of data and tools used or under development for each of several areas, it proposes a common framework for future tool development, data annotation and resource sharing based upon annotation graphs and servers.
* 8 pages, 6 figures
Seven Dimensions of Portability for Language Documentation and Description
Apr 10, 2002The process of documenting and describing the world's languages is undergoing radical transformation with the rapid uptake of new digital technologies for capture, storage, annotation and dissemination. However, uncritical adoption of new tools and technologies is leading to resources that are difficult to reuse and which are less portable than the conventional printed resources they replace. We begin by reviewing current uses of software tools and digital technologies for language documentation and description. This sheds light on how digital language documentation and description are created and managed, leading to an analysis of seven portability problems under the following headings: content, format, discovery, access, citation, preservation and rights. After characterizing each problem we provide a series of value statements, and this provides the framework for a broad range of best practice recommendations.
* 8 pages
An Integrated Framework for Treebanks and Multilayer Annotations
Apr 03, 2002Treebank formats and associated software tools are proliferating rapidly, with little consideration for interoperability. We survey a wide variety of treebank structures and operations, and show how they can be mapped onto the annotation graph model, and leading to an integrated framework encompassing tree and non-tree annotations alike. This development opens up new possibilities for managing and exploiting multilayer annotations.
* 8 pages
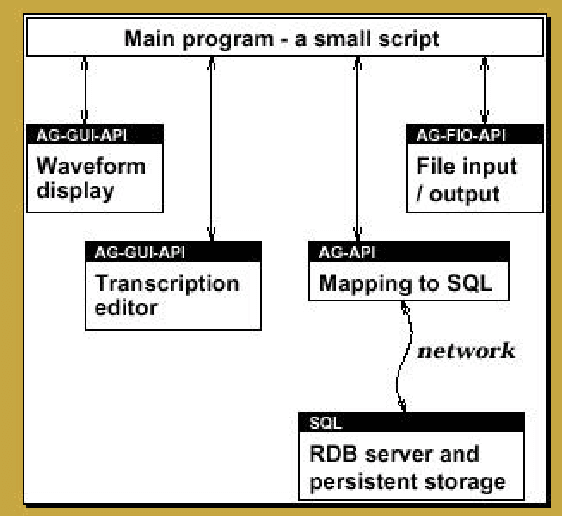
Creating Annotation Tools with the Annotation Graph Toolkit
Apr 03, 2002
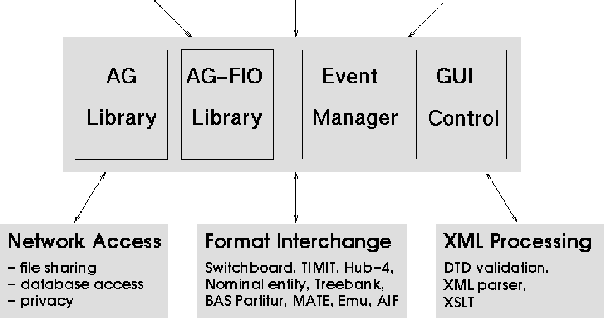
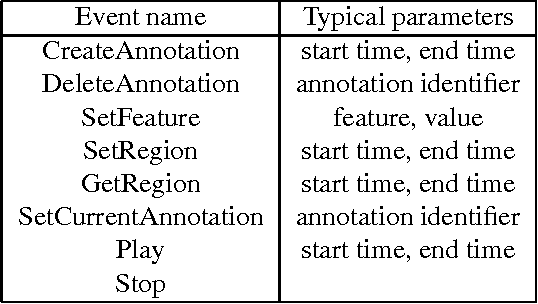
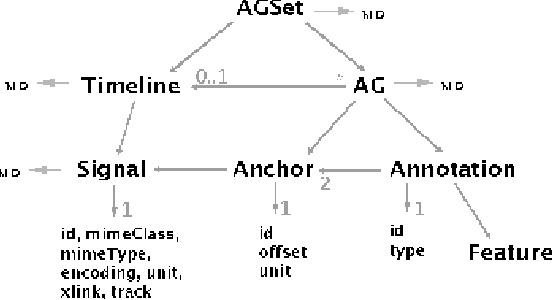
The Annotation Graph Toolkit is a collection of software supporting the development of annotation tools based on the annotation graph model. The toolkit includes application programming interfaces for manipulating annotation graph data and for importing data from other formats. There are interfaces for the scripting languages Tcl and Python, a database interface, specialized graphical user interfaces for a variety of annotation tasks, and several sample applications. This paper describes all the toolkit components for the benefit of would-be application developers.
* 8 pages, 12 figures
Models and Tools for Collaborative Annotation
Apr 03, 2002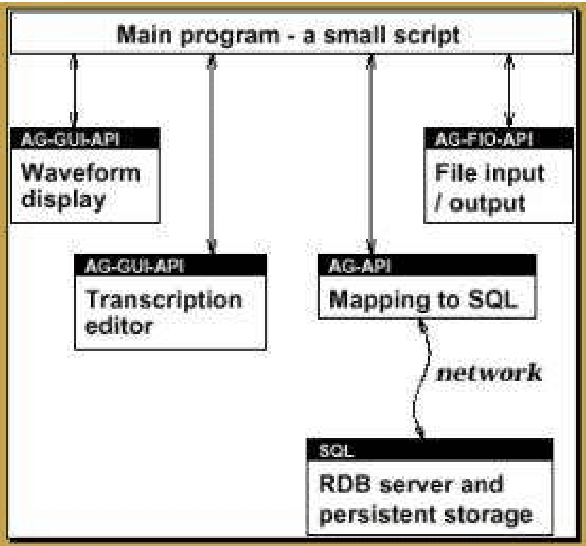

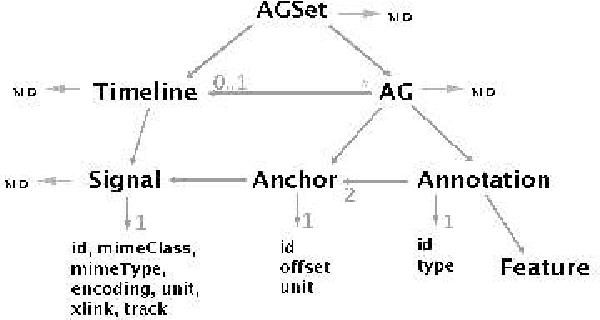
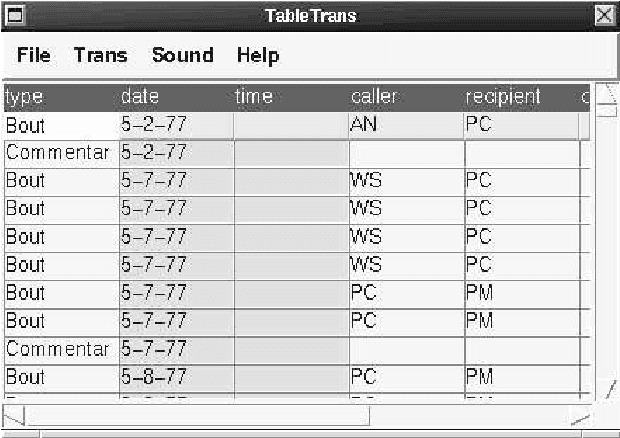
The Annotation Graph Toolkit (AGTK) is a collection of software which facilitates development of linguistic annotation tools. AGTK provides a database interface which allows applications to use a database server for persistent storage. This paper discusses various modes of collaborative annotation and how they can be supported with tools built using AGTK and its database interface. We describe the relational database schema and API, and describe a version of the TableTrans tool which supports collaborative annotation. The remainder of the paper discusses a high-level query language for annotation graphs, along with optimizations, in support of expressive and efficient access to the annotations held on a large central server. The paper demonstrates that it is straightforward to support a variety of different levels of collaborative annotation with existing AGTK-based tools, with a minimum of additional programming effort.
* 8 pages, 6 figures
TableTrans, MultiTrans, InterTrans and TreeTrans: Diverse Tools Built on the Annotation Graph Toolkit
Apr 03, 2002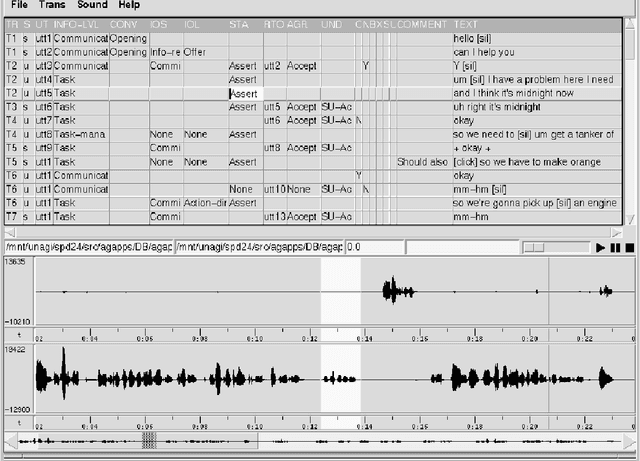



Four diverse tools built on the Annotation Graph Toolkit are described. Each tool associates linguistic codes and structures with time-series data. All are based on the same software library and tool architecture. TableTrans is for observational coding, using a spreadsheet whose rows are aligned to a signal. MultiTrans is for transcribing multi-party communicative interactions recorded using multi-channel signals. InterTrans is for creating interlinear text aligned to audio. TreeTrans is for creating and manipulating syntactic trees. This work demonstrates that the development of diverse tools and re-use of software components is greatly facilitated by a common high-level application programming interface for representing the data and managing input/output, together with a common architecture for managing the interaction of multiple components.
* 7 pages, 7 figures