 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Real Users: Rating Dialogue Success with Neural Networks for Reinforcement Learning in Spoken Dialogue Systems
Aug 13, 2015

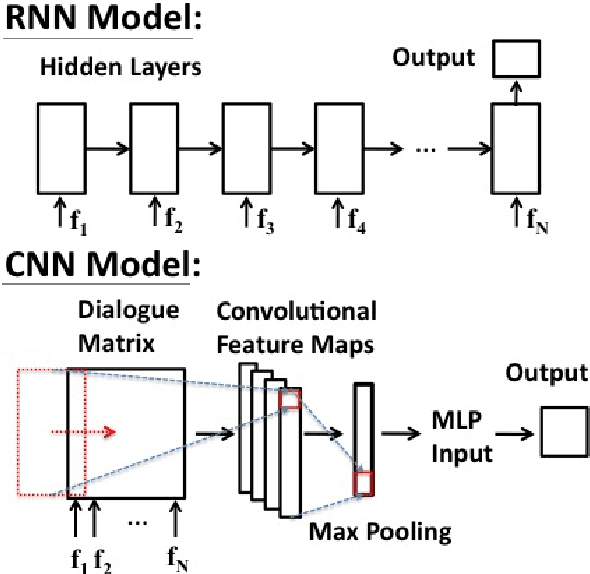
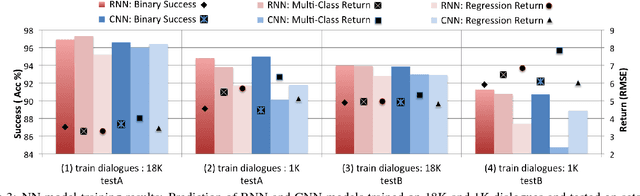
To train a statistical spoken dialogue system (SDS) it is essential that an accurate method for measuring task success is available. To date training has relied on presenting a task to either simulated or paid users and inferring the dialogue's success by observing whether this presented task was achieved or not. Our aim however is to be able to learn from real users acting under their own volition, in which case it is non-trivial to rate the success as any prior knowledge of the task is simply unavailable. User feedback may be utilised but has been found to be inconsistent. Hence, here we present two neural network models that evaluate a sequence of turn-level features to rate the success of a dialogue. Importantly these models make no use of any prior knowledge of the user's task. The models are trained on dialogues generated by a simulated user and the best model is then used to train a policy on-line which is shown to perform at least as well as a baseline system using prior knowledge of the user's task. We note that the models should also be of interest for evaluating SDS and for monitoring a dialogue in rule-based SDS.
Stochastic Language Generation in Dialogue using Recurrent Neural Networks with Convolutional Sentence Reranking
Aug 07, 2015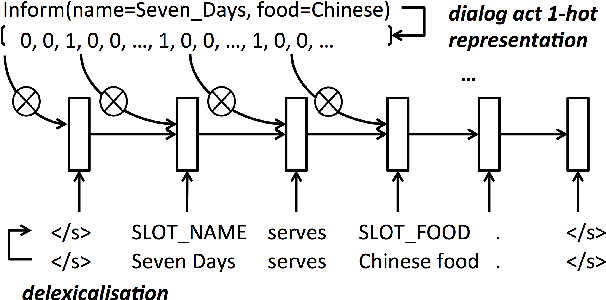

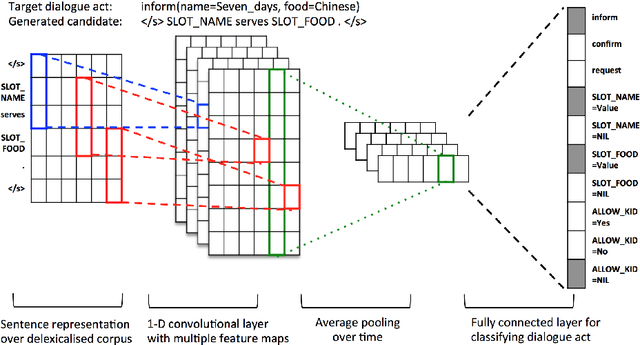
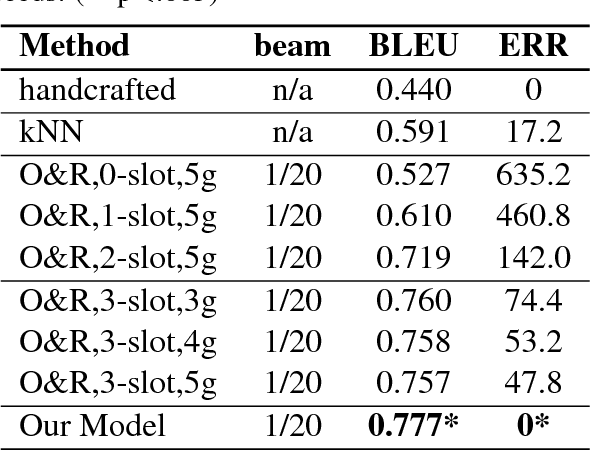
The natural language generation (NLG) component of a spoken dialogue system (SDS) usually needs a substantial amount of handcrafting or a well-labeled dataset to be trained on. These limitations add significantly to development costs and make cross-domain, multi-lingual dialogue systems intractable. Moreover, human languages are context-aware. The most natural response should be directly learned from data rather than depending on predefined syntaxes or rules. This paper presents a statistical language generator based on a joint recurrent and convolutional neural network structure which can be trained on dialogue act-utterance pairs without any semantic alignments or predefined grammar trees. Objective metrics suggest that this new model outperforms previous methods under the same experimental conditions. Results of an evaluation by human judges indicate that it produces not only high quality but linguistically varied utterances which are preferred compared to n-gram and rule-based systems.
Multi-domain Dialog State Tracking using Recurrent Neural Networks
Jun 23, 2015
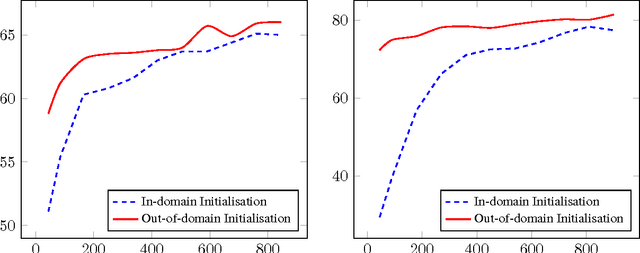
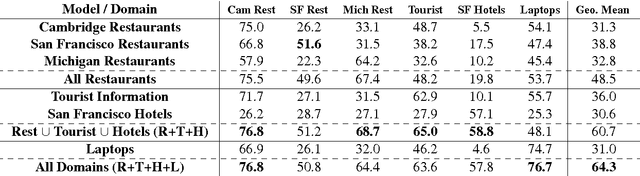
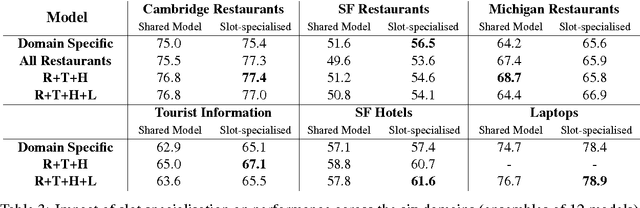
Dialog state tracking is a key component of many modern dialog systems, most of which are designed with a single, well-defined domain in mind. This paper shows that dialog data drawn from different dialog domains can be used to train a general belief tracking model which can operate across all of these domains, exhibiting superior performance to each of the domain-specific models. We propose a training procedure which uses out-of-domain data to initialise belief tracking models for entirely new domains. This procedure leads to improvements in belief tracking performance regardless of the amount of in-domain data available for training the model.
Statistical Modeling in Continuous Speech Recognition (CSR)(Invited Talk)
Jan 10, 2013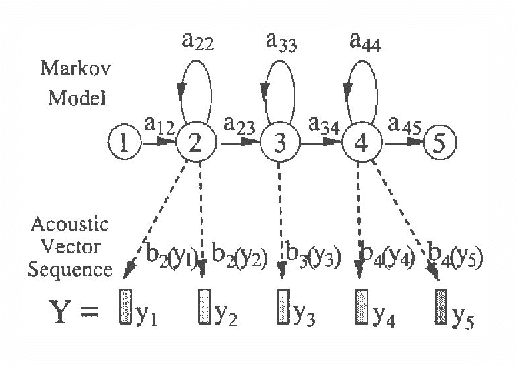
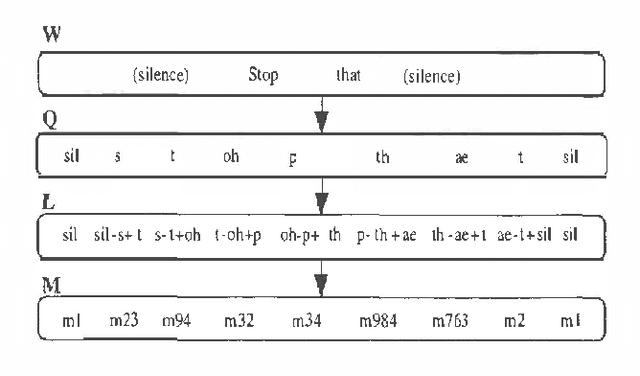
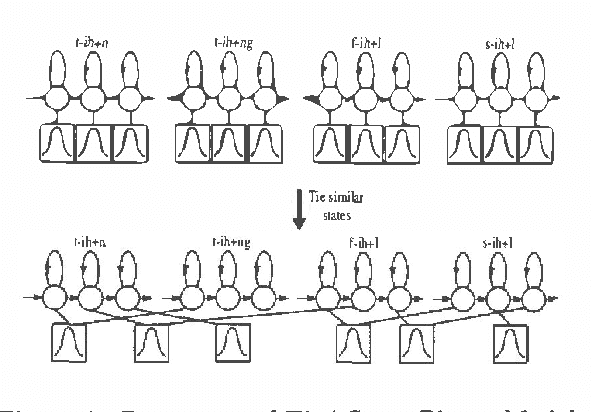
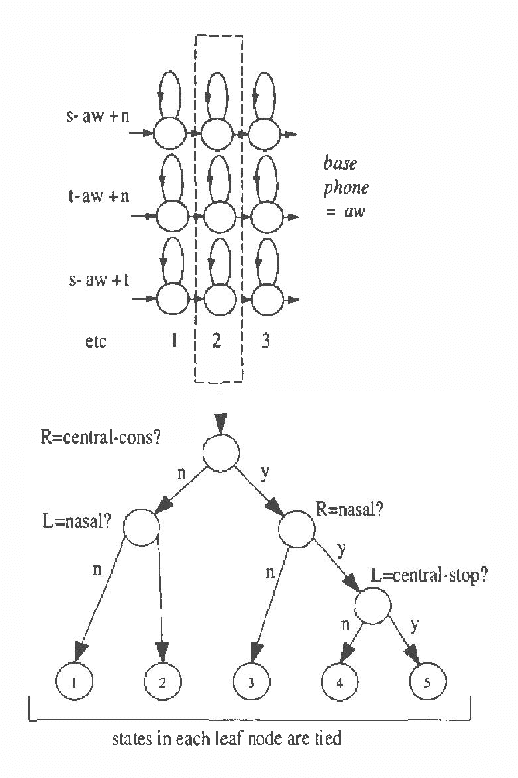
Automatic continuous speech recognition (CSR) is sufficiently mature that a variety of real world applications are now possible including large vocabulary transcription and interactive spoken dialogues. This paper reviews the evolution of the statistical modelling techniques which underlie current-day systems, specifically hidden Markov models (HMMs) and N-grams. Starting from a description of the speech signal and its parameterisation, the various modelling assumptions and their consequences are discussed. It then describes various techniques by which the effects of these assumptions can be mitigated. Despite the progress that has been made, the limitations of current modelling techniques are still evident. The paper therefore concludes with a brief review of some of the more fundamental modelling work now in progress.