 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStephen J. Roberts
Practical Bayesian Optimization for Variable Cost Objectives
May 15, 2018
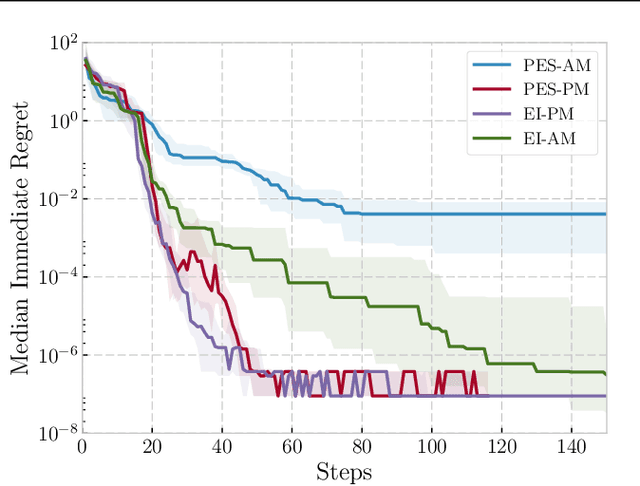
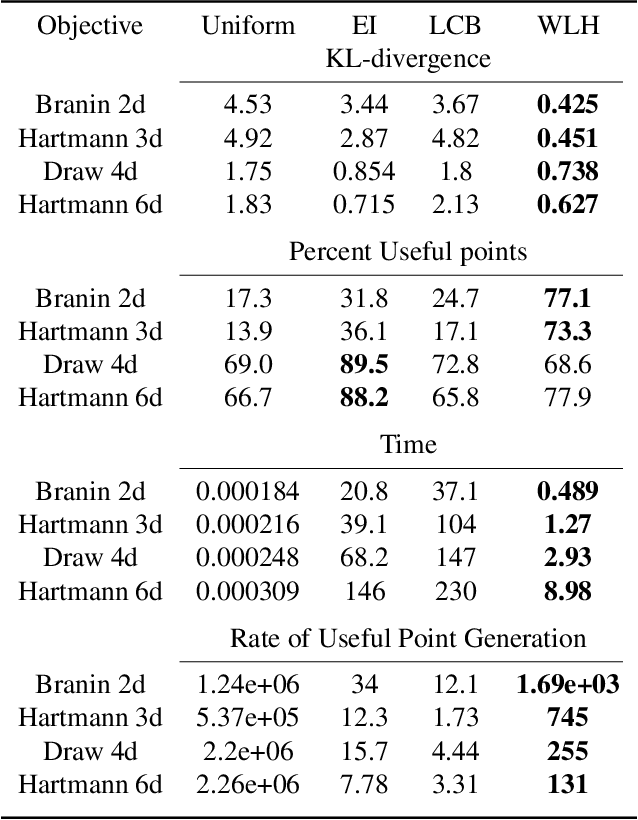
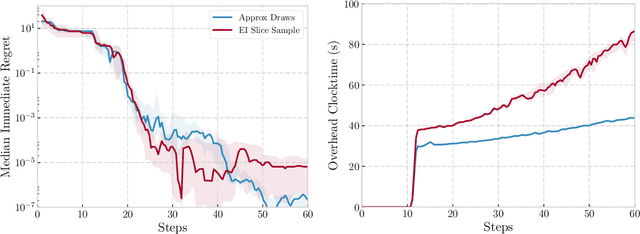
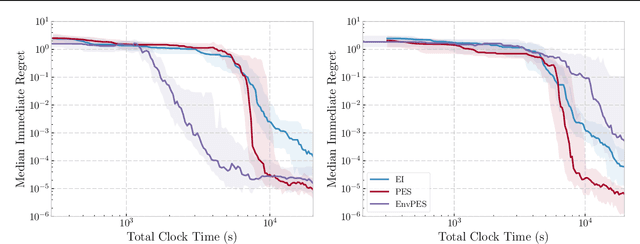
We propose a novel Bayesian Optimization approach for black-box functions with an environmental variable whose value determines the tradeoff between evaluation cost and the fidelity of the evaluations. Further, we use a novel approach to sampling support points, allowing faster construction of the acquisition function. This allows us to achieve optimization with lower overheads than previous approaches and is implemented for a more general class of problem. We show this approach to be effective on synthetic and real world benchmark problems.
Loss-Calibrated Approximate Inference in Bayesian Neural Networks
May 10, 2018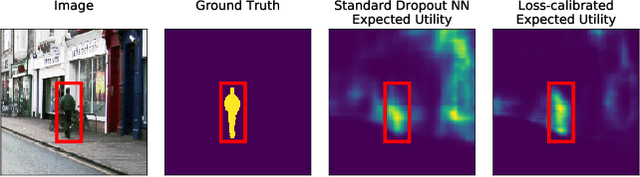
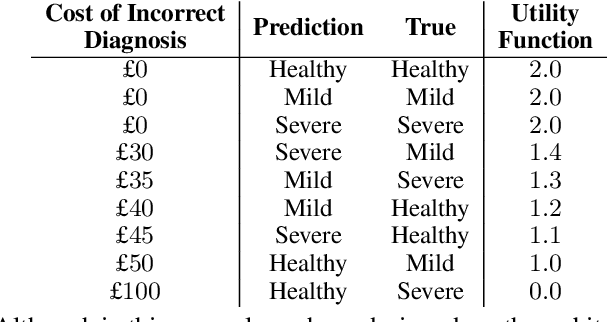
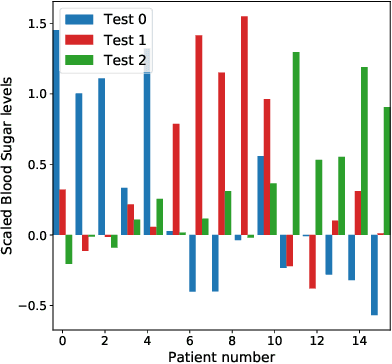
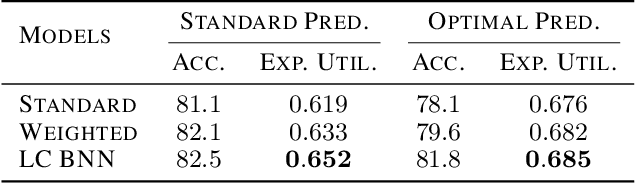
Current approaches in approximate inference for Bayesian neural networks minimise the Kullback-Leibler divergence to approximate the true posterior over the weights. However, this approximation is without knowledge of the final application, and therefore cannot guarantee optimal predictions for a given task. To make more suitable task-specific approximations, we introduce a new loss-calibrated evidence lower bound for Bayesian neural networks in the context of supervised learning, informed by Bayesian decision theory. By introducing a lower bound that depends on a utility function, we ensure that our approximation achieves higher utility than traditional methods for applications that have asymmetric utility functions. Furthermore, in using dropout inference, we highlight that our new objective is identical to that of standard dropout neural networks, with an additional utility-dependent penalty term. We demonstrate our new loss-calibrated model with an illustrative medical example and a restricted model capacity experiment, and highlight failure modes of the comparable weighted cross entropy approach. Lastly, we demonstrate the scalability of our method to real world applications with per-pixel semantic segmentation on an autonomous driving data set.
Quantum algorithms for training Gaussian Processes
Mar 28, 2018Gaussian processes (GPs) are important models in supervised machine learning. Training in Gaussian processes refers to selecting the covariance functions and the associated parameters in order to improve the outcome of predictions, the core of which amounts to evaluating the logarithm of the marginal likelihood (LML) of a given model. LML gives a concrete measure of the quality of prediction that a GP model is expected to achieve. The classical computation of LML typically carries a polynomial time overhead with respect to the input size. We propose a quantum algorithm that computes the logarithm of the determinant of a Hermitian matrix, which runs in logarithmic time for sparse matrices. This is applied in conjunction with a variant of the quantum linear system algorithm that allows for logarithmic time computation of the form $\mathbf{y}^TA^{-1}\mathbf{y}$, where $\mathbf{y}$ is a dense vector and $A$ is the covariance matrix. We hence show that quantum computing can be used to estimate the LML of a GP with exponentially improved efficiency under certain conditions.
Bayesian Optimization for Dynamic Problems
Mar 09, 2018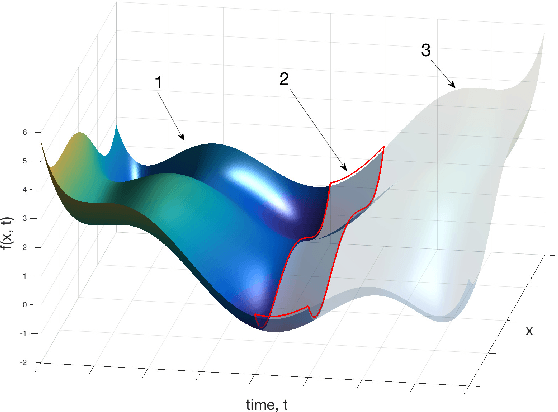

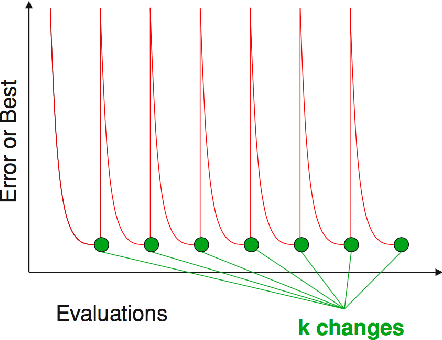
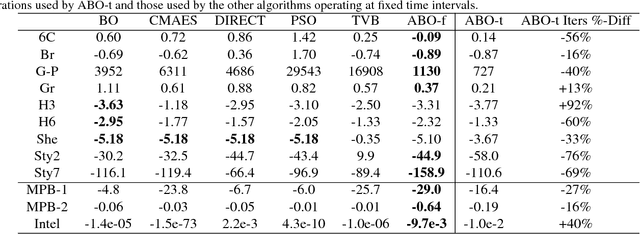
We propose practical extensions to Bayesian optimization for solving dynamic problems. We model dynamic objective functions using spatiotemporal Gaussian process priors which capture all the instances of the functions over time. Our extensions to Bayesian optimization use the information learnt from this model to guide the tracking of a temporally evolving minimum. By exploiting temporal correlations, the proposed method also determines when to make evaluations, how fast to make those evaluations, and it induces an appropriate budget of steps based on the available information. Lastly, we evaluate our technique on synthetic and real-world problems.
Identifying Sources and Sinks in the Presence of Multiple Agents with Gaussian Process Vector Calculus
Feb 22, 2018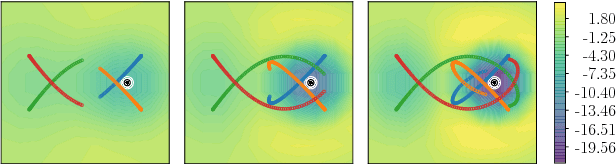
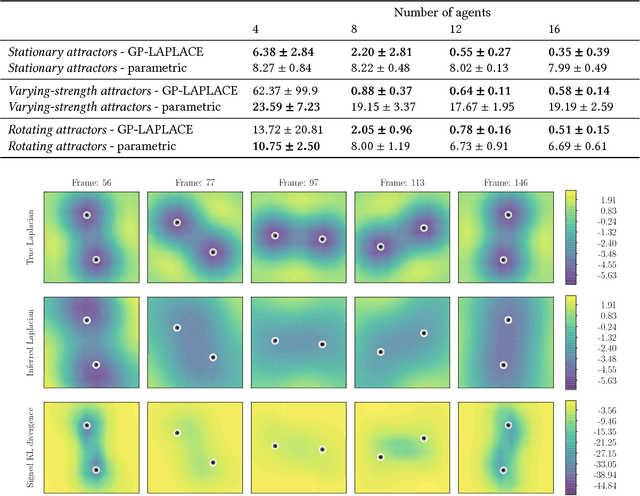
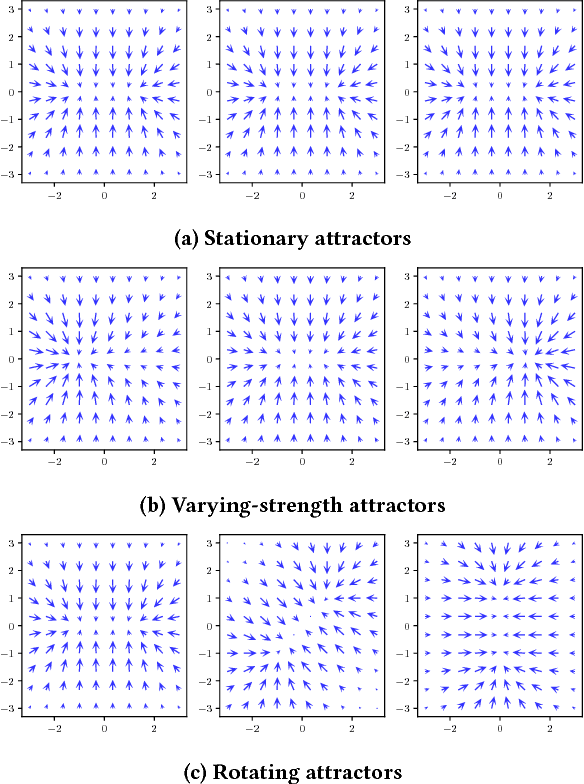
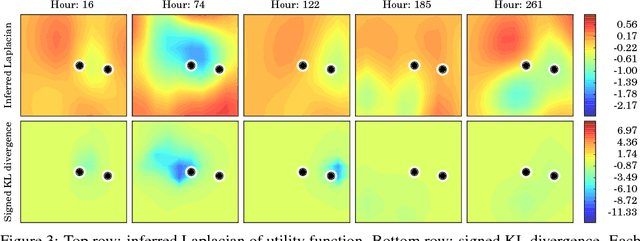
In systems of multiple agents, identifying the cause of observed agent dynamics is challenging. Often, these agents operate in diverse, non-stationary environments, where models rely on hand-crafted environment-specific features to infer influential regions in the system's surroundings. To overcome the limitations of these inflexible models, we present GP-LAPLACE, a technique for locating sources and sinks from trajectories in time-varying fields. Using Gaussian processes, we jointly infer a spatio-temporal vector field, as well as canonical vector calculus operations on that field. Notably, we do this from only agent trajectories without requiring knowledge of the environment, and also obtain a metric for denoting the significance of inferred causal features in the environment by exploiting our probabilistic method. To evaluate our approach, we apply it to both synthetic and real-world GPS data, demonstrating the applicability of our technique in the presence of multiple agents, as well as its superiority over existing methods.
Inferring agent objectives at different scales of a complex adaptive system
Dec 04, 2017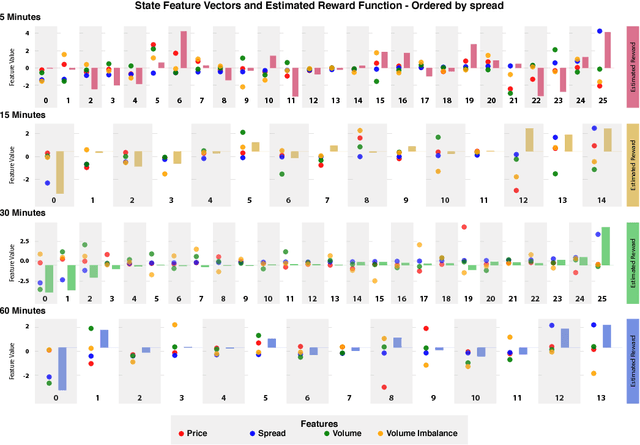
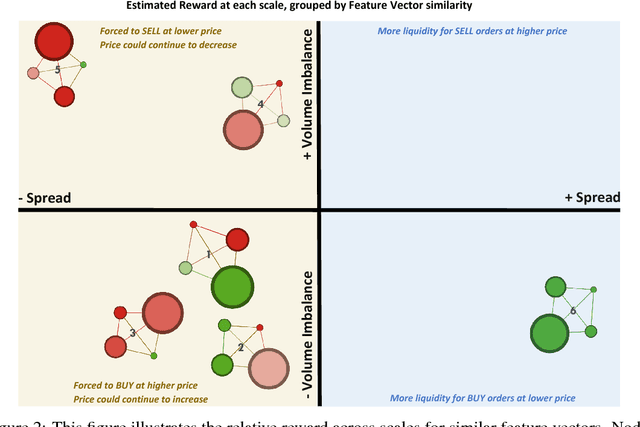
We introduce a framework to study the effective objectives at different time scales of financial market microstructure. The financial market can be regarded as a complex adaptive system, where purposeful agents collectively and simultaneously create and perceive their environment as they interact with it. It has been suggested that multiple agent classes operate in this system, with a non-trivial hierarchy of top-down and bottom-up causation classes with different effective models governing each level. We conjecture that agent classes may in fact operate at different time scales and thus act differently in response to the same perceived market state. Given scale-specific temporal state trajectories and action sequences estimated from aggregate market behaviour, we use Inverse Reinforcement Learning to compute the effective reward function for the aggregate agent class at each scale, allowing us to assess the relative attractiveness of feature vectors across different scales. Differences in reward functions for feature vectors may indicate different objectives of market participants, which could assist in finding the scale boundary for agent classes. This has implications for learning algorithms operating in this domain.
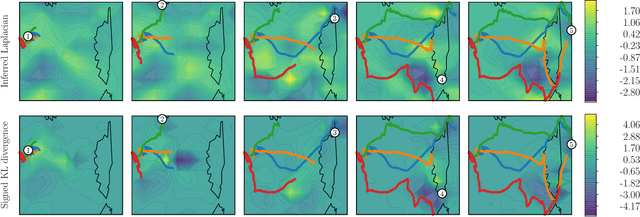
Learning from lions: inferring the utility of agents from their trajectories
Sep 07, 2017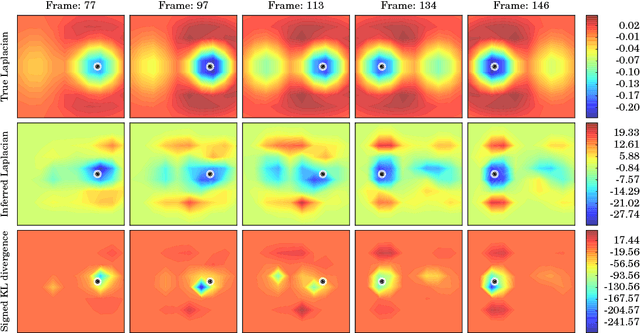
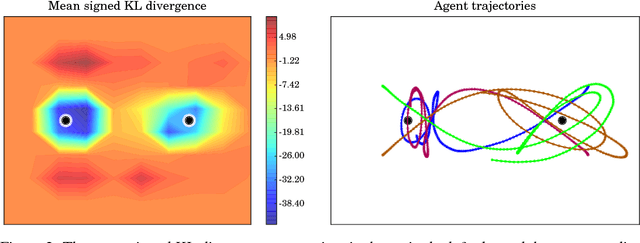
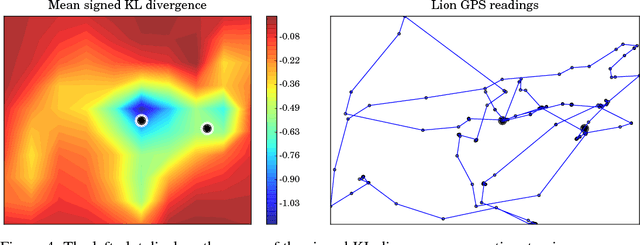
We build a model using Gaussian processes to infer a spatio-temporal vector field from observed agent trajectories. Significant landmarks or influence points in agent surroundings are jointly derived through vector calculus operations that indicate presence of sources and sinks. We evaluate these influence points by using the Kullback-Leibler divergence between the posterior and prior Laplacian of the inferred spatio-temporal vector field. Through locating significant features that influence trajectories, our model aims to give greater insight into underlying causal utility functions that determine agent decision-making. A key feature of our model is that it infers a joint Gaussian process over the observed trajectories, the time-varying vector field of utility and canonical vector calculus operators. We apply our model to both synthetic data and lion GPS data collected at the Bubye Valley Conservancy in southern Zimbabwe.
A Novel Approach to Forecasting Financial Volatility with Gaussian Process Envelopes
May 02, 2017
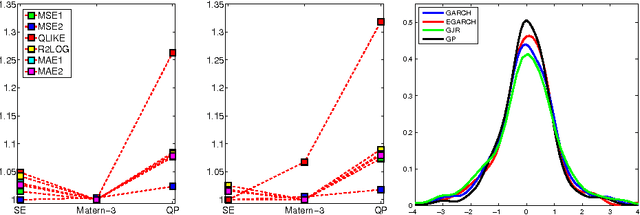
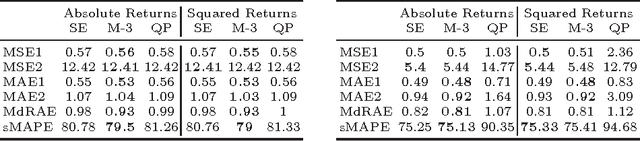
In this paper we use Gaussian Process (GP) regression to propose a novel approach for predicting volatility of financial returns by forecasting the envelopes of the time series. We provide a direct comparison of their performance to traditional approaches such as GARCH. We compare the forecasting power of three approaches: GP regression on the absolute and squared returns; regression on the envelope of the returns and the absolute returns; and regression on the envelope of the negative and positive returns separately. We use a maximum a posteriori estimate with a Gaussian prior to determine our hyperparameters. We also test the effect of hyperparameter updating at each forecasting step. We use our approaches to forecast out-of-sample volatility of four currency pairs over a 2 year period, at half-hourly intervals. From three kernels, we select the kernel giving the best performance for our data. We use two published accuracy measures and four statistical loss functions to evaluate the forecasting ability of GARCH vs GPs. In mean squared error the GP's perform 20% better than a random walk model, and 50% better than GARCH for the same data.
Optimal client recommendation for market makers in illiquid financial products
Apr 27, 2017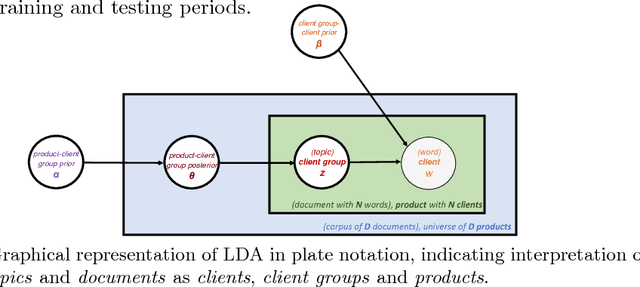
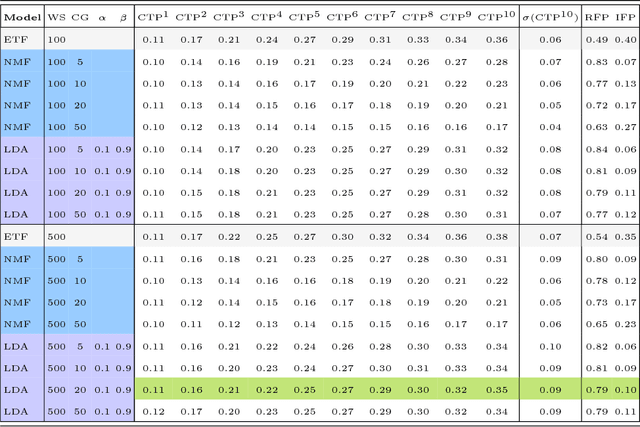
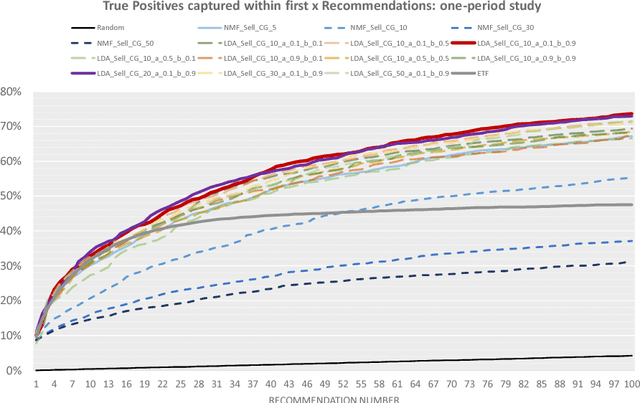
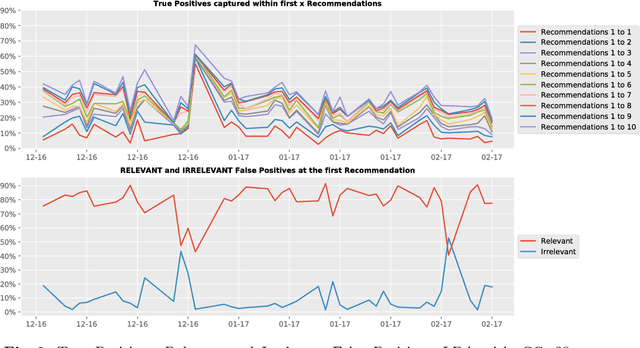
The process of liquidity provision in financial markets can result in prolonged exposure to illiquid instruments for market makers. In this case, where a proprietary position is not desired, pro-actively targeting the right client who is likely to be interested can be an effective means to offset this position, rather than relying on commensurate interest arising through natural demand. In this paper, we consider the inference of a client profile for the purpose of corporate bond recommendation, based on typical recorded information available to the market maker. Given a historical record of corporate bond transactions and bond meta-data, we use a topic-modelling analogy to develop a probabilistic technique for compiling a curated list of client recommendations for a particular bond that needs to be traded, ranked by probability of interest. We show that a model based on Latent Dirichlet Allocation offers promising performance to deliver relevant recommendations for sales traders.
Distribution of Gaussian Process Arc Lengths
Mar 23, 2017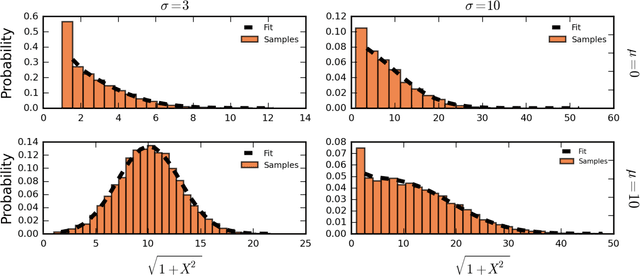
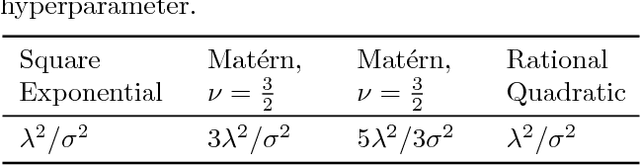
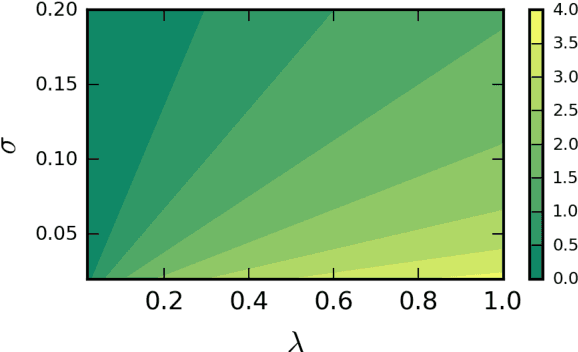
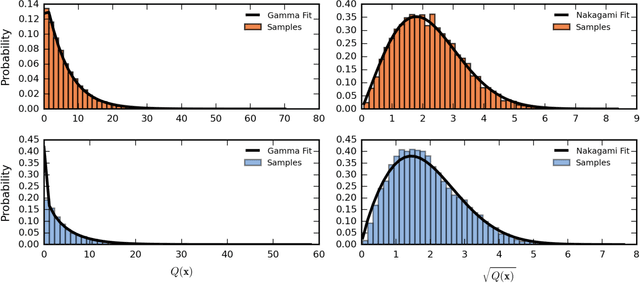
We present the first treatment of the arc length of the Gaussian Process (GP) with more than a single output dimension. GPs are commonly used for tasks such as trajectory modelling, where path length is a crucial quantity of interest. Previously, only paths in one dimension have been considered, with no theoretical consideration of higher dimensional problems. We fill the gap in the existing literature by deriving the moments of the arc length for a stationary GP with multiple output dimensions. A new method is used to derive the mean of a one-dimensional GP over a finite interval, by considering the distribution of the arc length integrand. This technique is used to derive an approximate distribution over the arc length of a vector valued GP in $\mathbb{R}^n$ by moment matching the distribution. Numerical simulations confirm our theoretical derivations.