 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvance Fake Video Detection via Vision Transformers
Apr 29, 2025Recent advancements in AI-based multimedia generation have enabled the creation of hyper-realistic images and videos, raising concerns about their potential use in spreading misinformation. The widespread accessibility of generative techniques, which allow for the production of fake multimedia from prompts or existing media, along with their continuous refinement, underscores the urgent need for highly accurate and generalizable AI-generated media detection methods, underlined also by new regulations like the European Digital AI Act. In this paper, we draw inspiration from Vision Transformer (ViT)-based fake image detection and extend this idea to video. We propose an {original} %innovative framework that effectively integrates ViT embeddings over time to enhance detection performance. Our method shows promising accuracy, generalization, and few-shot learning capabilities across a new, large and diverse dataset of videos generated using five open source generative techniques from the state-of-the-art, as well as a separate dataset containing videos produced by proprietary generative methods.
TrueFake: A Real World Case Dataset of Last Generation Fake Images also Shared on Social Networks
Apr 29, 2025AI-generated synthetic media are increasingly used in real-world scenarios, often with the purpose of spreading misinformation and propaganda through social media platforms, where compression and other processing can degrade fake detection cues. Currently, many forensic tools fail to account for these in-the-wild challenges. In this work, we introduce TrueFake, a large-scale benchmarking dataset of 600,000 images including top notch generative techniques and sharing via three different social networks. This dataset allows for rigorous evaluation of state-of-the-art fake image detectors under very realistic and challenging conditions. Through extensive experimentation, we analyze how social media sharing impacts detection performance, and identify current most effective detection and training strategies. Our findings highlight the need for evaluating forensic models in conditions that mirror real-world use.
GPU-accelerated SIFT-aided source identification of stabilized videos
Jul 29, 2022

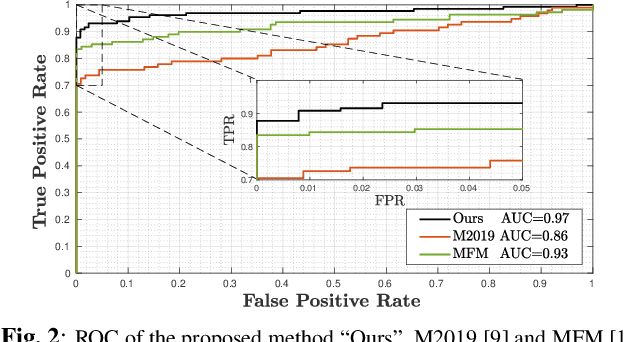
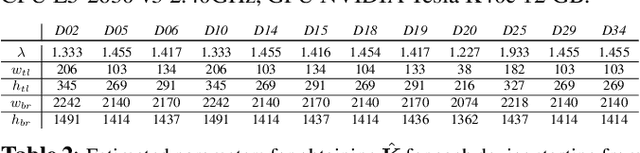
Video stabilization is an in-camera processing commonly applied by modern acquisition devices. While significantly improving the visual quality of the resulting videos, it has been shown that such operation typically hinders the forensic analysis of video signals. In fact, the correct identification of the acquisition source usually based on Photo Response non-Uniformity (PRNU) is subject to the estimation of the transformation applied to each frame in the stabilization phase. A number of techniques have been proposed for dealing with this problem, which however typically suffer from a high computational burden due to the grid search in the space of inversion parameters. Our work attempts to alleviate these shortcomings by exploiting the parallelization capabilities of Graphics Processing Units (GPUs), typically used for deep learning applications, in the framework of stabilised frames inversion. Moreover, we propose to exploit SIFT features {to estimate the camera momentum and} %to identify less stabilized temporal segments, thus enabling a more accurate identification analysis, and to efficiently initialize the frame-wise parameter search of consecutive frames. Experiments on a consolidated benchmark dataset confirm the effectiveness of the proposed approach in reducing the required computational time and improving the source identification accuracy. {The code is available at \url{https://github.com/AMontiB/GPU-PRNU-SIFT}}.