 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonia Chernova
Leveraging Semantics for Incremental Learning in Multi-Relational Embeddings
May 29, 2019
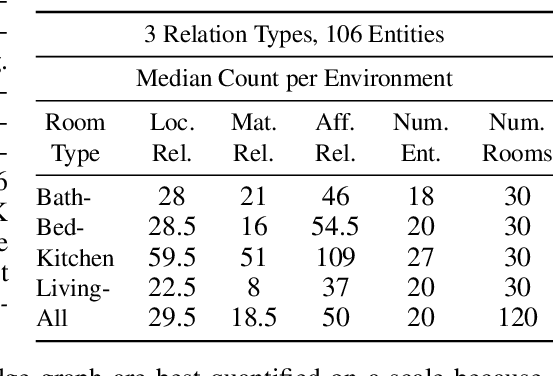
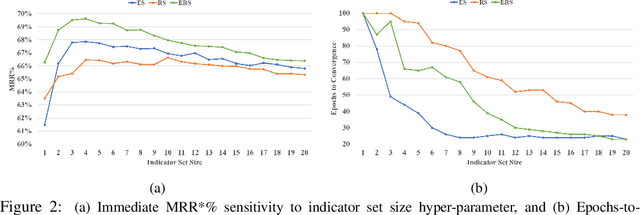
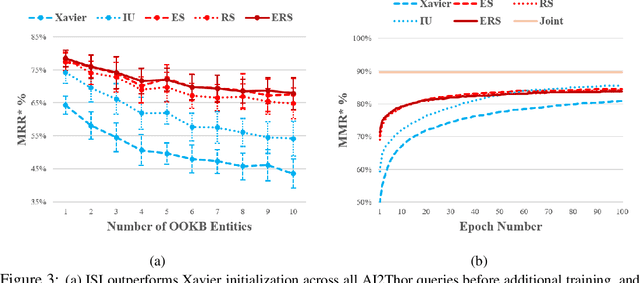

Prior work has shown that the multi-relational embedding objective can be reformulated to learn dynamic knowledge graphs, enabling incremental class learning. The core contribution of our work is Incremental Semantic Initialization, which enables the multi-relational embedding parameters for a novel concept to be initialized in relation to previously learned embeddings of semantically similar concepts. We present three variants of our approach: Entity Similarity Initialization, Relational Similarity Initialization, and Hybrid Similarity Initialization, that reason about entities, relations between entities, or both, respectively. When evaluated on the mined AI2Thor dataset, our experiments show that incremental semantic initialization improves immediate query performance by 21.3 MRR* percentage points, on average. Additionally, the best performing proposed method reduced the number of epochs required to approach joint-learning performance by 57.4\% on average.
Path Ranking with Attention to Type Hierarchies
May 26, 2019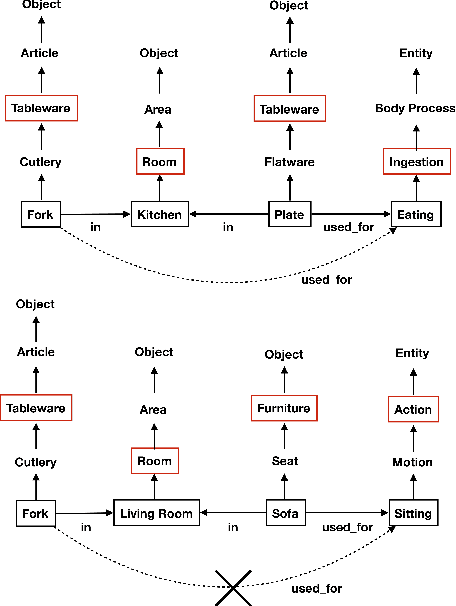
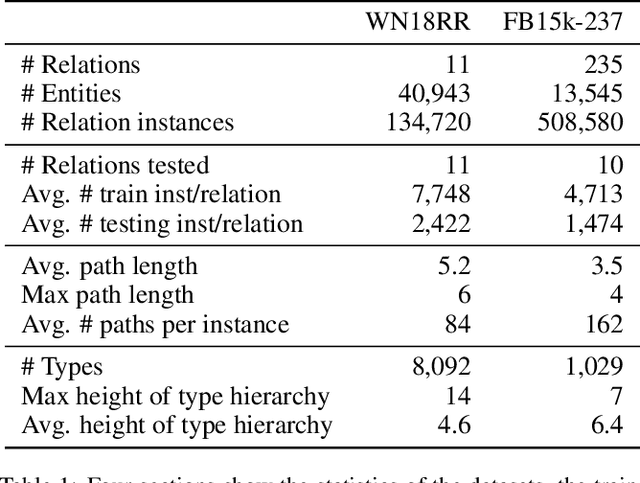
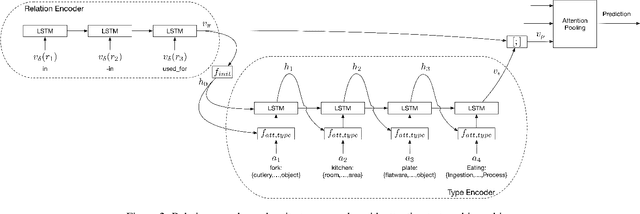
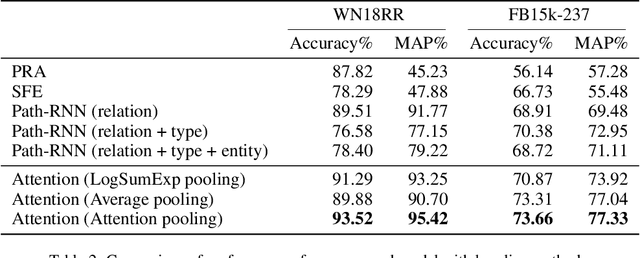
The knowledge base completion problem is the problem of inferring missing information from existing facts in knowledge bases. Path-ranking based methods use sequences of relations as general patterns of paths for prediction. However, these patterns usually lack accuracy because they are generic and can often apply to widely varying scenarios. We leverage type hierarchies of entities to create a new class of path patterns that are both discriminative and generalizable. Then we propose an attention-based RNN model, which can be trained end-to-end, to discover the new path patterns most suitable for the data. Experiments conducted on two benchmark knowledge base completion datasets demonstrate that the proposed model outperforms existing methods by a statistically significant margin. Our quantitative analysis of the path patterns shows that they balance between generalization and discrimination.
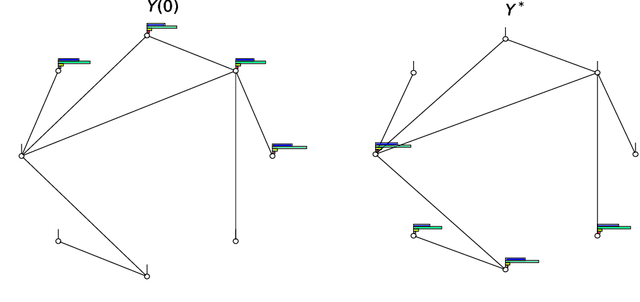
Skill Acquisition via Automated Multi-Coordinate Cost Balancing
Mar 27, 2019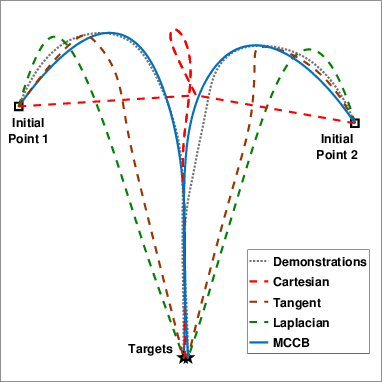
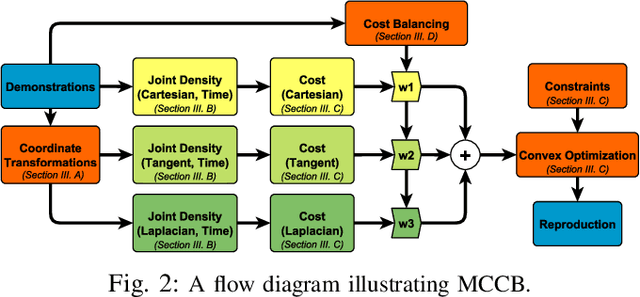

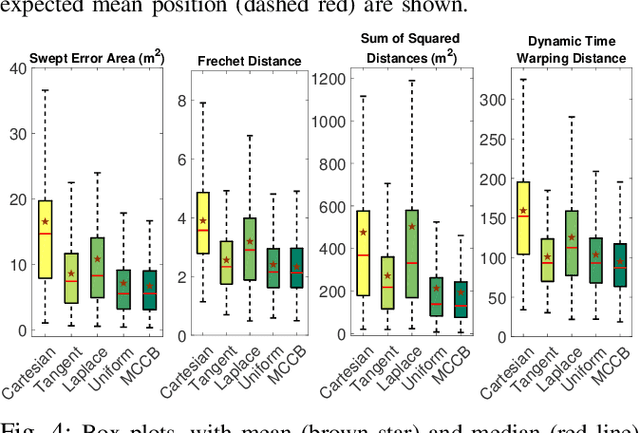
We propose a learning framework, named Multi-Coordinate Cost Balancing (MCCB), to address the problem of acquiring point-to-point movement skills from demonstrations. MCCB encodes demonstrations simultaneously in multiple differential coordinates that specify local geometric properties. MCCB generates reproductions by solving a convex optimization problem with a multi-coordinate cost function and linear constraints on the reproductions, such as initial, target, and via points. Further, since the relative importance of each coordinate system in the cost function might be unknown for a given skill, MCCB learns optimal weighting factors that balance the cost function. We demonstrate the effectiveness of MCCB via detailed experiments conducted on one handwriting dataset and three complex skill datasets.
STRATA: A Unified Framework for Task Assignments in Large Teams of Heterogeneous Robots
Mar 14, 2019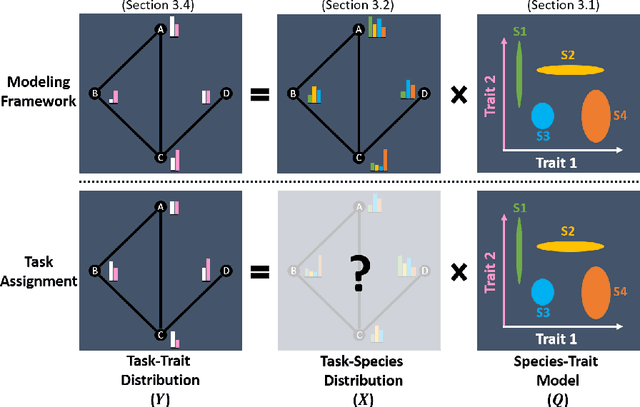
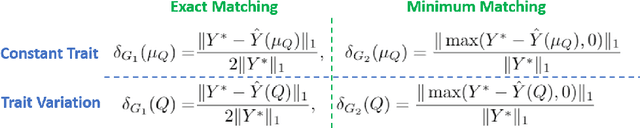
Large teams of robots have the potential to solve complex multi-task problems that are intractable for a single robot working independently. However, solving complex multi-task problems requires leveraging the relative strengths of different robots in the team. We present Stochastic TRAit-based Task Assignment (STRATA), a unified framework that models large teams of heterogeneous robots and performs optimal task assignments. Specifically, given information on which traits (capabilities) are required for various tasks, STRATA computes the optimal assignments of robots to tasks such that the task-trait requirements are achieved. Inspired by prior work in robot swarms and biodiversity, we categorize robots into different species (groups) based on their traits. We model each trait as a continuous variable and differentiate between traits that can and cannot be aggregated from different robots. STRATA is capable of reasoning about both species-level and robot-level differences in traits. Further, we define measures of diversity for any given team based on the team's continuous-space trait model. We illustrate the necessity and effectiveness of STRATA using detailed simulations and a capture the flag game environment.
RoboCSE: Robot Common Sense Embedding
Mar 01, 2019
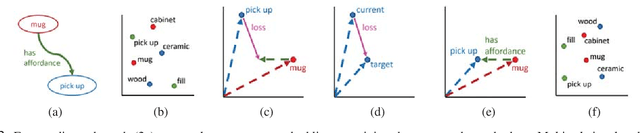
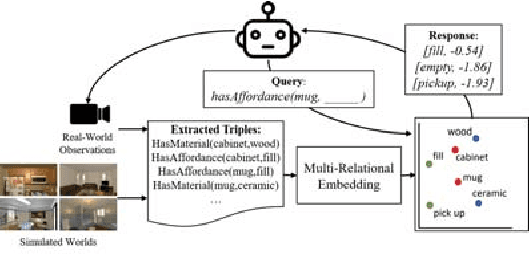

Autonomous service robots require computational frameworks that allow them to generalize knowledge to new situations in a manner that models uncertainty while scaling to real-world problem sizes. The Robot Common Sense Embedding (RoboCSE) showcases a class of computational frameworks, multi-relational embeddings, that have not been leveraged in robotics to model semantic knowledge. We validate RoboCSE on a realistic home environment simulator (AI2Thor) to measure how well it generalizes learned knowledge about object affordances, locations, and materials. Our experiments show that RoboCSE can perform prediction better than a baseline that uses pre-trained embeddings, such as Word2Vec, achieving statistically significant improvements while using orders of magnitude less memory than our Bayesian Logic Network baseline. In addition, we show that predictions made by RoboCSE are robust to significant reductions in data available for training as well as domain transfer to MatterPort3D, achieving statistically significant improvements over a baseline that memorizes training data.
Tool Macgyvering: Tool Construction Using Geometric Reasoning
Feb 10, 2019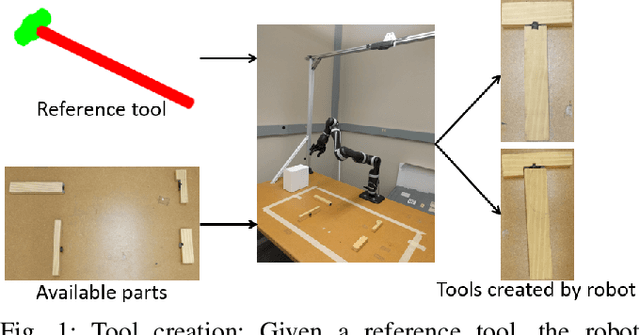
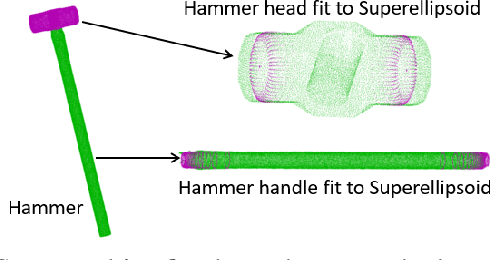
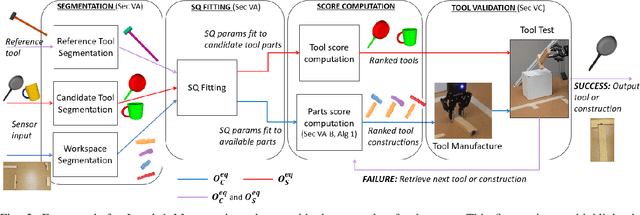
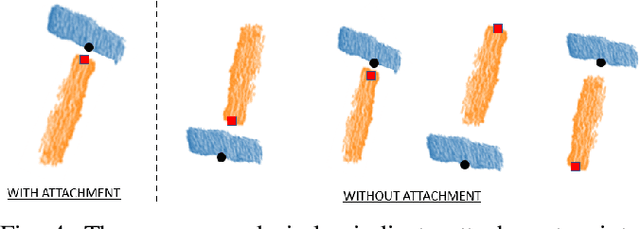
MacGyvering is defined as creating or repairing something in an inventive or improvised way by utilizing objects that are available at hand. In this paper, we explore a subset of Macgyvering problems involving tool construction, i.e., creating tools from parts available in the environment. We formalize the overall problem domain of tool Macgyvering, introducing three levels of complexity for tool construction and substitution problems, and presenting a novel computational framework aimed at solving one level of the tool Macgyvering problem, specifically contributing a novel algorithm for tool construction based on geometric reasoning. We validate our approach by constructing three tools using a 7-DOF robot arm.
Classification of Household Materials via Spectroscopy
Jan 06, 2019
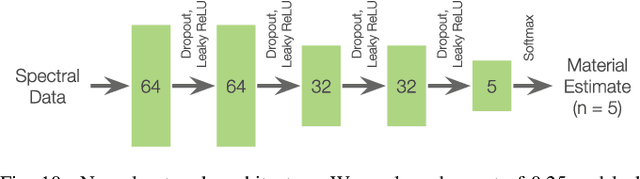
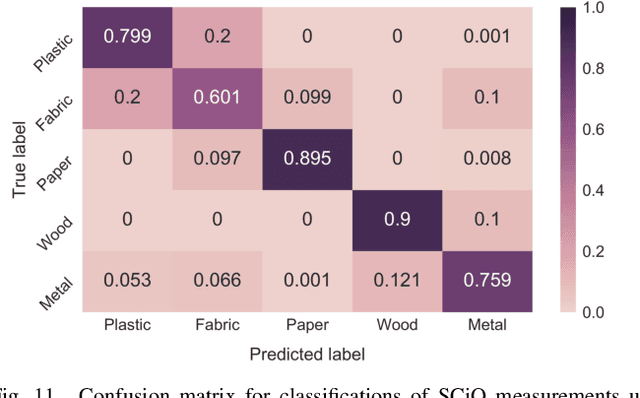

Recognizing an object's material can inform a robot on the object's fragility or appropriate use. To estimate an object's material during manipulation, many prior works have explored the use of haptic sensing. In this paper, we explore a technique for robots to estimate the materials of objects using spectroscopy. We demonstrate that spectrometers provide several benefits for material recognition, including fast response times and accurate measurements with low noise. Furthermore, spectrometers do not require direct contact with an object. To explore this, we collected a dataset of spectral measurements from two commercially available spectrometers during which a robotic platform interacted with 50 flat material objects, and we show that a neural network model can accurately analyze these measurements. Due to the similarity between consecutive spectral measurements, our model achieved a material classification accuracy of 94.6% when given only one spectral sample per object. Similar to prior works with haptic sensors, we found that generalizing material recognition to new objects posed a greater challenge, for which we achieved an accuracy of 79.1% via leave-one-object-out cross-validation. Finally, we demonstrate how a PR2 robot can leverage spectrometers to estimate the materials of everyday objects found in the home. From this work, we find that spectroscopy poses a promising approach for material classification during robotic manipulation.
Unbiasing Semantic Segmentation For Robot Perception using Synthetic Data Feature Transfer
Sep 11, 2018
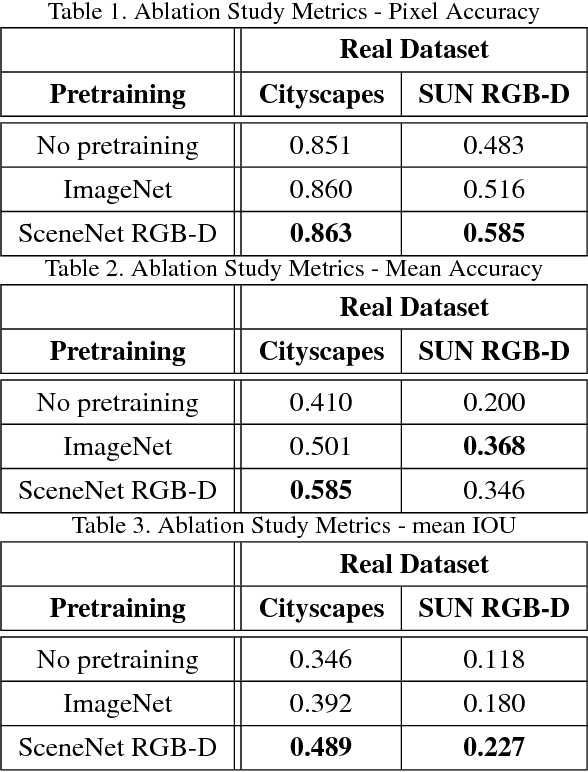
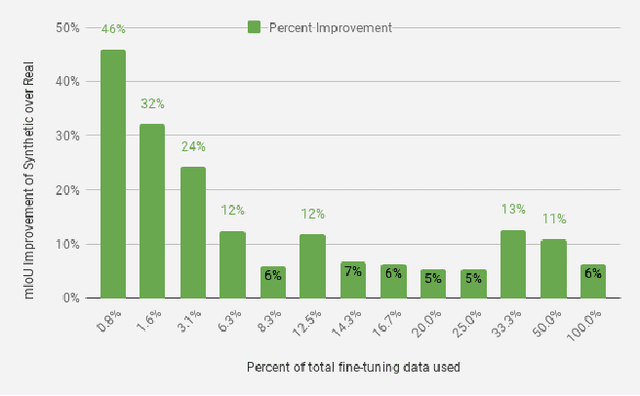

Robot perception systems need to perform reliable image segmentation in real-time on noisy, raw perception data. State-of-the-art segmentation approaches use large CNN models and carefully constructed datasets; however, these models focus on accuracy at the cost of real-time inference. Furthermore, the standard semantic segmentation datasets are not large enough for training CNNs without augmentation and are not representative of noisy, uncurated robot perception data. We propose improving the performance of real-time segmentation frameworks on robot perception data by transferring features learned from synthetic segmentation data. We show that pretraining real-time segmentation architectures with synthetic segmentation data instead of ImageNet improves fine-tuning performance by reducing the bias learned in pretraining and closing the \textit{transfer gap} as a result. Our experiments show that our real-time robot perception models pretrained on synthetic data outperform those pretrained on ImageNet for every scale of fine-tuning data examined. Moreover, the degree to which synthetic pretraining outperforms ImageNet pretraining increases as the availability of robot data decreases, making our approach attractive for robotics domains where dataset collection is hard and/or expensive.
Learning Generalizable Robot Skills from Demonstrations in Cluttered Environments
Aug 04, 2018
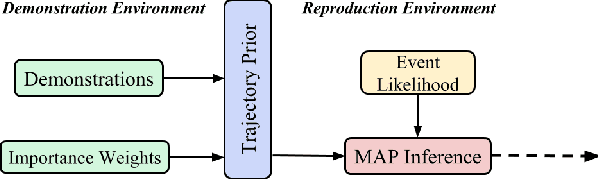
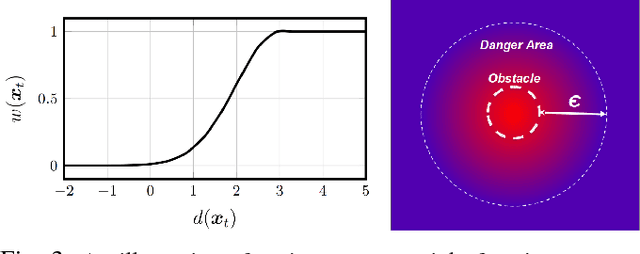
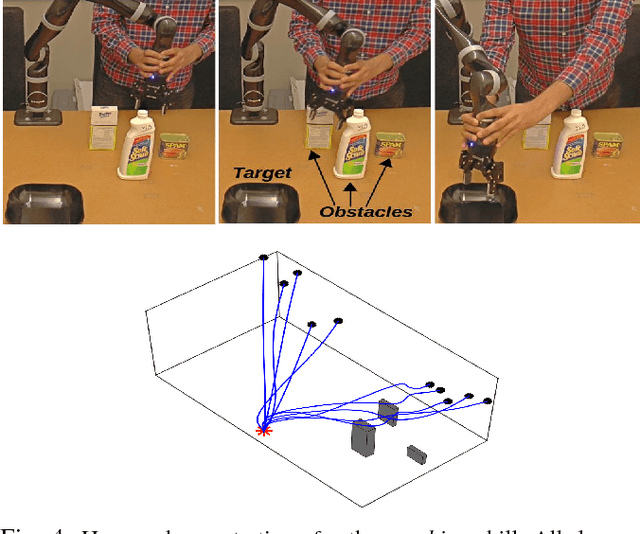
Learning from Demonstration (LfD) is a popular approach to endowing robots with skills without having to program them by hand. Typically, LfD relies on human demonstrations in clutter-free environments. This prevents the demonstrations from being affected by irrelevant objects, whose influence can obfuscate the true intention of the human or the constraints of the desired skill. However, it is unrealistic to assume that the robot's environment can always be restructured to remove clutter when capturing human demonstrations. To contend with this problem, we develop an importance weighted batch and incremental skill learning approach, building on a recent inference-based technique for skill representation and reproduction. Our approach reduces unwanted environmental influences on the learned skill, while still capturing the salient human behavior. We provide both batch and incremental versions of our approach and validate our algorithms on a 7-DOF JACO2 manipulator with reaching and placing skills.