 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Data-Driven Classification of Mental Disorders: A Comprehensive Approach to Diagnosing Depression, Anxiety, and Schizophrenia
Feb 06, 2025



This study investigates the potential of multimodal data integration, which combines electroencephalogram (EEG) data with sociodemographic characteristics like age, sex, education, and intelligence quotient (IQ), to diagnose mental diseases like schizophrenia, depression, and anxiety. Using Apache Spark and convolutional neural networks (CNNs), a data-driven classification pipeline has been developed for big data environment to effectively analyze massive datasets. In order to evaluate brain activity and connection patterns associated with mental disorders, EEG parameters such as power spectral density (PSD) and coherence are examined. The importance of coherence features is highlighted by comparative analysis, which shows significant improvement in classification accuracy and robustness. This study emphasizes the significance of holistic approaches for efficient diagnostic tools by integrating a variety of data sources. The findings open the door for creative, data-driven approaches to treating psychiatric diseases by demonstrating the potential of utilizing big data, sophisticated deep learning methods, and multimodal datasets to enhance the precision, usability, and comprehension of mental health diagnostics.
Innovative Framework for Early Estimation of Mental Disorder Scores to Enable Timely Interventions
Feb 06, 2025



Individual's general well-being is greatly impacted by mental health conditions including depression and Post-Traumatic Stress Disorder (PTSD), underscoring the importance of early detection and precise diagnosis in order to facilitate prompt clinical intervention. An advanced multimodal deep learning system for the automated classification of PTSD and depression is presented in this paper. Utilizing textual and audio data from clinical interview datasets, the method combines features taken from both modalities by combining the architectures of LSTM (Long Short Term Memory) and BiLSTM (Bidirectional Long Short-Term Memory).Although text features focus on speech's semantic and grammatical components; audio features capture vocal traits including rhythm, tone, and pitch. This combination of modalities enhances the model's capacity to identify minute patterns connected to mental health conditions. Using test datasets, the proposed method achieves classification accuracies of 92% for depression and 93% for PTSD, outperforming traditional unimodal approaches and demonstrating its accuracy and robustness.
MLtoGAI: Semantic Web based with Machine Learning for Enhanced Disease Prediction and Personalized Recommendations using Generative AI
Jul 26, 2024



In modern healthcare, addressing the complexities of accurate disease prediction and personalized recommendations is both crucial and challenging. This research introduces MLtoGAI, which integrates Semantic Web technology with Machine Learning (ML) to enhance disease prediction and offer user-friendly explanations through ChatGPT. The system comprises three key components: a reusable disease ontology that incorporates detailed knowledge about various diseases, a diagnostic classification model that uses patient symptoms to detect specific diseases accurately, and the integration of Semantic Web Rule Language (SWRL) with ontology and ChatGPT to generate clear, personalized health advice. This approach significantly improves prediction accuracy and ensures results that are easy to understand, addressing the complexity of diseases and diverse symptoms. The MLtoGAI system demonstrates substantial advancements in accuracy and user satisfaction, contributing to developing more intelligent and accessible healthcare solutions. This innovative approach combines the strengths of ML algorithms with the ability to provide transparent, human-understandable explanations through ChatGPT, achieving significant improvements in prediction accuracy and user comprehension. By leveraging semantic technology and explainable AI, the system enhances the accuracy of disease prediction and ensures that the recommendations are relevant and easily understood by individual patients. Our research highlights the potential of integrating advanced technologies to overcome existing challenges in medical diagnostics, paving the way for future developments in intelligent healthcare systems. Additionally, the system is validated using 200 synthetic patient data records, ensuring robust performance and reliability.
Decision support system for Forest fire management using Ontology with Big Data and LLMs
May 18, 2024Forests are crucial for ecological balance, but wildfires, a major cause of forest loss, pose significant risks. Fire weather indices, which assess wildfire risk and predict resource demands, are vital. With the rise of sensor networks in fields like healthcare and environmental monitoring, semantic sensor networks are increasingly used to gather climatic data such as wind speed, temperature, and humidity. However, processing these data streams to determine fire weather indices presents challenges, underscoring the growing importance of effective forest fire detection. This paper discusses using Apache Spark for early forest fire detection, enhancing fire risk prediction with meteorological and geographical data. Building on our previous development of Semantic Sensor Network (SSN) ontologies and Semantic Web Rules Language (SWRL) for managing forest fires in Monesterial Natural Park, we expanded SWRL to improve a Decision Support System (DSS) using a Large Language Models (LLMs) and Spark framework. We implemented real-time alerts with Spark streaming, tailored to various fire scenarios, and validated our approach using ontology metrics, query-based evaluations, LLMs score precision, F1 score, and recall measures.
A Methodology-Oriented Study of Catastrophic Forgetting in Incremental Deep Neural Networks
May 11, 2024Human being and different species of animals having the skills to gather, transferring knowledge, processing, fine-tune and generating information throughout their lifetime. The ability of learning throughout their lifespan is referred as continuous learning which is using neurocognition mechanism. Consequently, in real world computational system of incremental learning autonomous agents also needs such continuous learning mechanism which provide retrieval of information and long-term memory consolidation. However, the main challenge in artificial intelligence is that the incremental learning of the autonomous agent when new data confronted. In such scenarios, the main concern is catastrophic forgetting(CF), i.e., while learning the sequentially, neural network underfits the old data when it confronted with new data. To tackle this CF problem many numerous studied have been proposed, however it is very difficult to compare their performance due to dissimilarity in their evaluation mechanism. Here we focus on the comparison of all algorithms which are having similar type of evaluation mechanism. Here we are comparing three types of incremental learning methods: (1) Exemplar based methods, (2) Memory based methods, and (3) Network based method. In this survey paper, methodology oriented study for catastrophic forgetting in incremental deep neural network is addressed. Furthermore, it contains the mathematical overview of impact-full methods which can be help researchers to deal with CF.
A Decision Support System for Liver Diseases Prediction: Integrating Batch Processing, Rule-Based Event Detection and SPARQL Query
Nov 10, 2023Liver diseases pose a significant global health burden, impacting a substantial number of individuals and exerting substantial economic and social consequences. Rising liver problems are considered a fatal disease in many countries, such as Egypt, Molda, etc. The objective of this study is to construct a predictive model for liver illness using Basic Formal Ontology (BFO) and detection rules derived from a decision tree algorithm. Based on these rules, events are detected through batch processing using the Apache Jena framework. Based on the event detected, queries can be directly processed using SPARQL. To make the ontology operational, these Decision Tree (DT) rules are converted into Semantic Web Rule Language (SWRL). Using this SWRL in the ontology for predicting different types of liver disease with the help of the Pellet and Drool inference engines in Protege Tools, a total of 615 records are taken from different liver diseases. After inferring the rules, the result can be generated for the patient according to the DT rules, and other patient-related details along with different precautionary suggestions can be obtained based on these results. Combining query results of batch processing and ontology-generated results can give more accurate suggestions for disease prevention and detection. This work aims to provide a comprehensive approach that is applicable for liver disease prediction, rich knowledge graph representation, and smart querying capabilities. The results show that combining RDF data, SWRL rules, and SPARQL queries for analysing and predicting liver disease can help medical professionals to learn more about liver diseases and make a Decision Support System (DSS) for health care.
Semantic rule Web-based Diagnosis and Treatment of Vector-Borne Diseases using SWRL rules
Jan 08, 2023



Vector-borne diseases (VBDs) are a kind of infection caused through the transmission of vectors generated by the bites of infected parasites, bacteria, and viruses, such as ticks, mosquitoes, triatomine bugs, blackflies, and sandflies. If these diseases are not properly treated within a reasonable time frame, the mortality rate may rise. In this work, we propose a set of ontologies that will help in the diagnosis and treatment of vector-borne diseases. For developing VBD's ontology, electronic health records taken from the Indian Health Records website, text data generated from Indian government medical mobile applications, and doctors' prescribed handwritten notes of patients are used as input. This data is then converted into correct text using Optical Character Recognition (OCR) and a spelling checker after pre-processing. Natural Language Processing (NLP) is applied for entity extraction from text data for making Resource Description Framework (RDF) medical data with the help of the Patient Clinical Data (PCD) ontology. Afterwards, Basic Formal Ontology (BFO), National Vector Borne Disease Control Program (NVBDCP) guidelines, and RDF medical data are used to develop ontologies for VBDs, and Semantic Web Rule Language (SWRL) rules are applied for diagnosis and treatment. The developed ontology helps in the construction of decision support systems (DSS) for the NVBDCP to control these diseases.
Forecasting COVID- 19 cases using Statistical Models and Ontology-based Semantic Modelling: A real time data analytics approach
Jun 06, 2022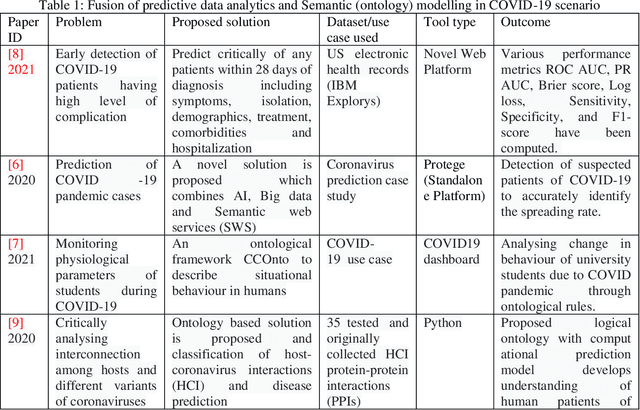
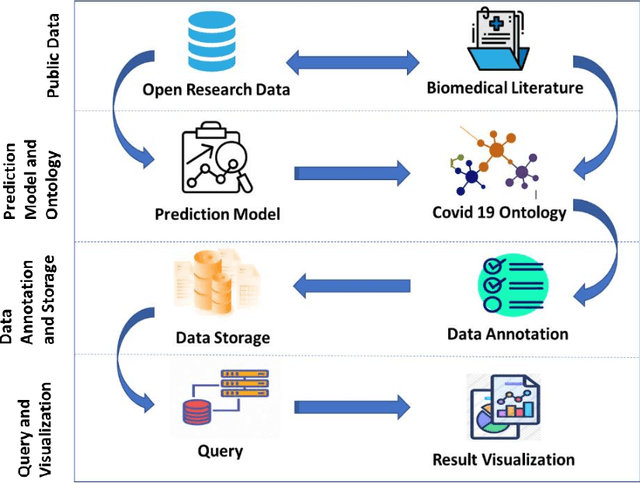
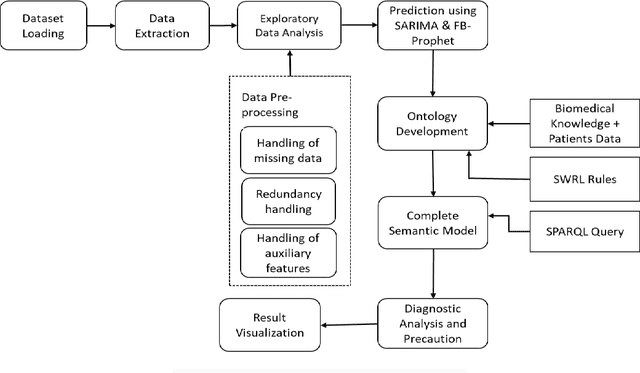

SARS-COV-19 is the most prominent issue which many countries face today. The frequent changes in infections, recovered and deaths represents the dynamic nature of this pandemic. It is very crucial to predict the spreading rate of this virus for accurate decision making against fighting with the situation of getting infected through the virus, tracking and controlling the virus transmission in the community. We develop a prediction model using statistical time series models such as SARIMA and FBProphet to monitor the daily active, recovered and death cases of COVID-19 accurately. Then with the help of various details across each individual patient (like height, weight, gender etc.), we designed a set of rules using Semantic Web Rule Language and some mathematical models for dealing with COVID19 infected cases on an individual basis. After combining all the models, a COVID-19 Ontology is developed and performs various queries using SPARQL query on designed Ontology which accumulate the risk factors, provide appropriate diagnosis, precautions and preventive suggestions for COVID Patients. After comparing the performance of SARIMA and FBProphet, it is observed that the SARIMA model performs better in forecasting of COVID cases. On individual basis COVID case prediction, approx. 497 individual samples have been tested and classified into five different levels of COVID classes such as Having COVID, No COVID, High Risk COVID case, Medium to High Risk case, and Control needed case.
Anomaly detection in surveillance videos using transformer based attention model
Jun 06, 2022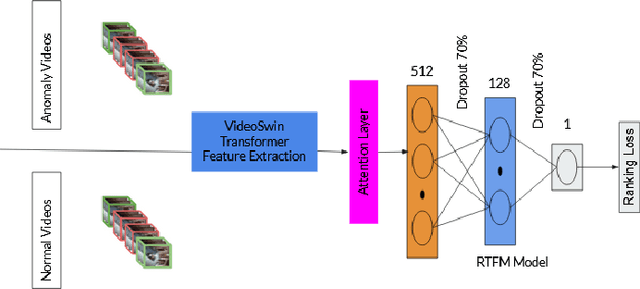
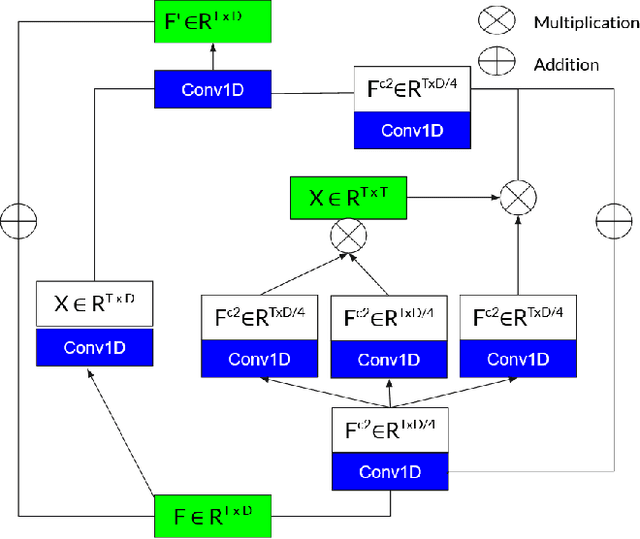

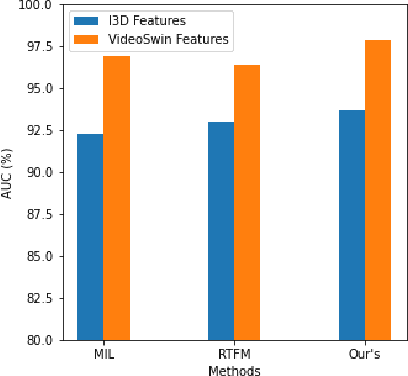
Surveillance footage can catch a wide range of realistic anomalies. This research suggests using a weakly supervised strategy to avoid annotating anomalous segments in training videos, which is time consuming. In this approach only video level labels are used to obtain frame level anomaly scores. Weakly supervised video anomaly detection (WSVAD) suffers from the wrong identification of abnormal and normal instances during the training process. Therefore it is important to extract better quality features from the available videos. WIth this motivation, the present paper uses better quality transformer-based features named Videoswin Features followed by the attention layer based on dilated convolution and self attention to capture long and short range dependencies in temporal domain. This gives us a better understanding of available videos. The proposed framework is validated on real-world dataset i.e. ShanghaiTech Campus dataset which results in competitive performance than current state-of-the-art methods. The model and the code are available at https://github.com/kapildeshpande/Anomaly-Detection-in-Surveillance-Videos
Impact of the composition of feature extraction and class sampling in medicare fraud detection
Jun 03, 2022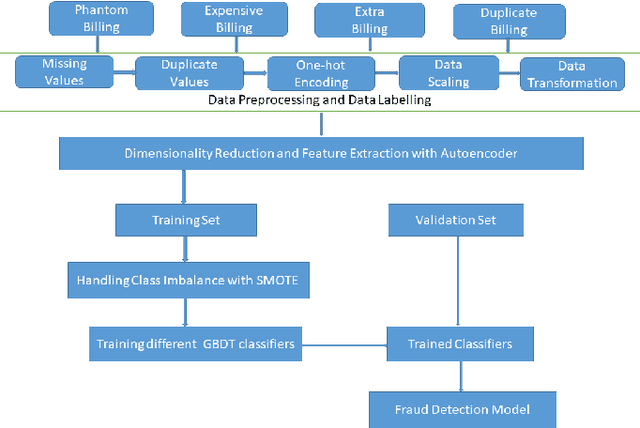
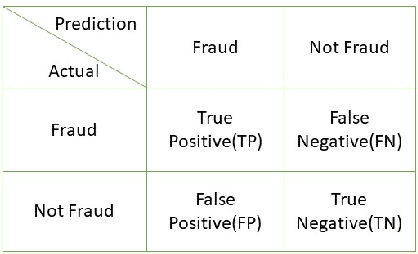
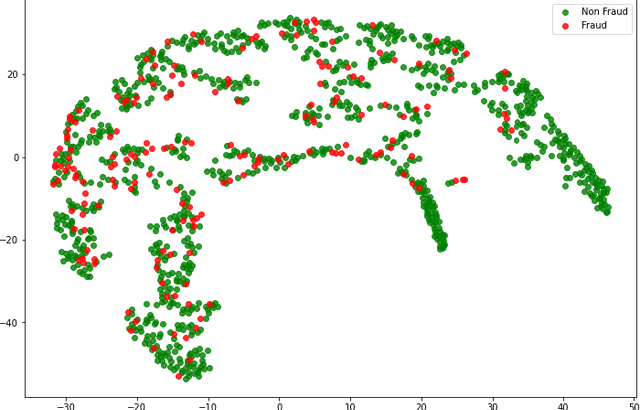
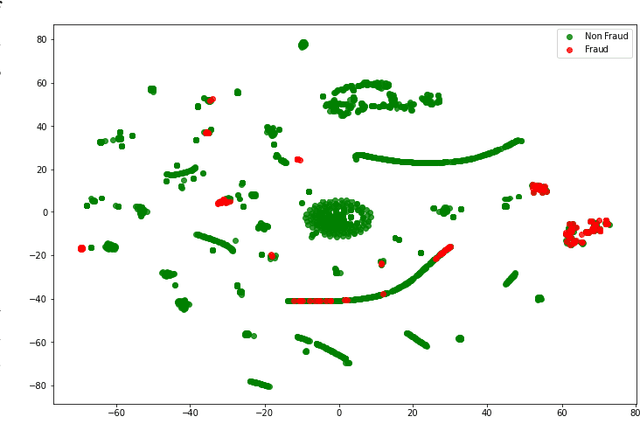
With healthcare being critical aspect, health insurance has become an important scheme in minimizing medical expenses. Following this, the healthcare industry has seen a significant increase in fraudulent activities owing to increased insurance, and fraud has become a significant contributor to rising medical care expenses, although its impact can be mitigated using fraud detection techniques. To detect fraud, machine learning techniques are used. The Centers for Medicaid and Medicare Services (CMS) of the United States federal government released "Medicare Part D" insurance claims is utilized in this study to develop fraud detection system. Employing machine learning algorithms on a class-imbalanced and high dimensional medicare dataset is a challenging task. To compact such challenges, the present work aims to perform feature extraction following data sampling, afterward applying various classification algorithms, to get better performance. Feature extraction is a dimensionality reduction approach that converts attributes into linear or non-linear combinations of the actual attributes, generating a smaller and more diversified set of attributes and thus reducing the dimensions. Data sampling is commonlya used to address the class imbalance either by expanding the frequency of minority class or reducing the frequency of majority class to obtain approximately equal numbers of occurrences for both classes. The proposed approach is evaluated through standard performance metrics. Thus, to detect fraud efficiently, this study applies autoencoder as a feature extraction technique, synthetic minority oversampling technique (SMOTE) as a data sampling technique, and various gradient boosted decision tree-based classifiers as a classification algorithm. The experimental results show the combination of autoencoders followed by SMOTE on the LightGBM classifier achieved best results.