 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality specific U-Net variants for biomedical image segmentation: A survey
Jul 09, 2021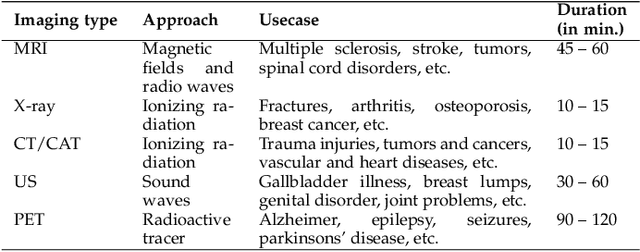

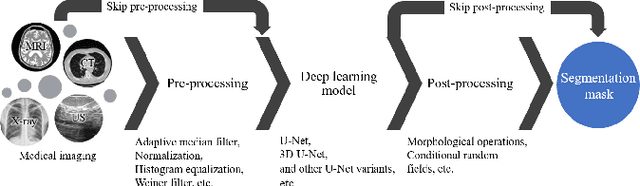
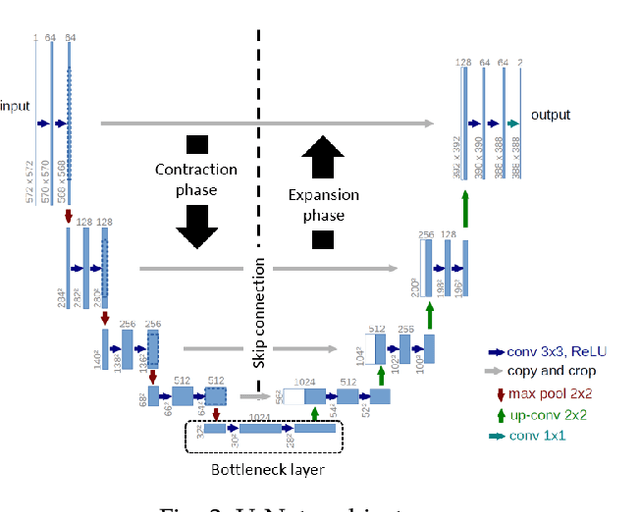
With the advent of advancements in deep learning approaches, such as deep convolution neural network, residual neural network, adversarial network; U-Net architectures are most widely utilized in biomedical image segmentation to address the automation in identification and detection of the target regions or sub-regions. In recent studies, U-Net based approaches have illustrated state-of-the-art performance in different applications for the development of computer-aided diagnosis systems for early diagnosis and treatment of diseases such as brain tumor, lung cancer, alzheimer, breast cancer, etc. This article contributes to present the success of these approaches by describing the U-Net framework, followed by the comprehensive analysis of the U-Net variants for different medical imaging or modalities such as magnetic resonance imaging, X-ray, computerized tomography/computerized axial tomography, ultrasound, positron emission tomography, etc. Besides, this article also highlights the contribution of U-Net based frameworks in the on-going pandemic, severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) also known as COVID-19.
Hate speech detection using static BERT embeddings
Jun 29, 2021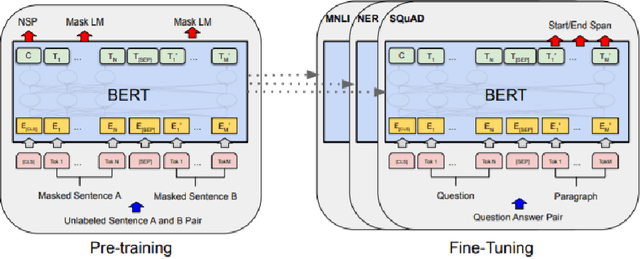
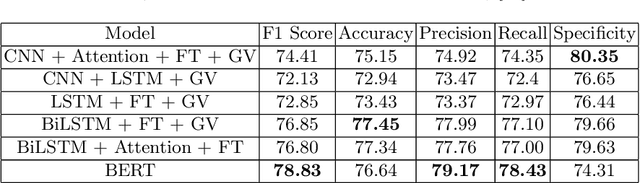
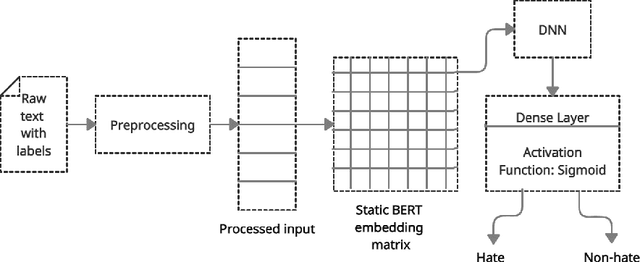
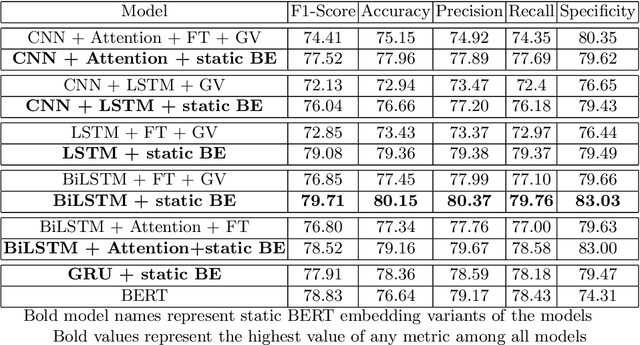
With increasing popularity of social media platforms hate speech is emerging as a major concern, where it expresses abusive speech that targets specific group characteristics, such as gender, religion or ethnicity to spread violence. Earlier people use to verbally deliver hate speeches but now with the expansion of technology, some people are deliberately using social media platforms to spread hate by posting, sharing, commenting, etc. Whether it is Christchurch mosque shootings or hate crimes against Asians in west, it has been observed that the convicts are very much influenced from hate text present online. Even though AI systems are in place to flag such text but one of the key challenges is to reduce the false positive rate (marking non hate as hate), so that these systems can detect hate speech without undermining the freedom of expression. In this paper, we use ETHOS hate speech detection dataset and analyze the performance of hate speech detection classifier by replacing or integrating the word embeddings (fastText (FT), GloVe (GV) or FT + GV) with static BERT embeddings (BE). With the extensive experimental trails it is observed that the neural network performed better with static BE compared to using FT, GV or FT + GV as word embeddings. In comparison to fine-tuned BERT, one metric that significantly improved is specificity.
BERT based sentiment analysis: A software engineering perspective
Jun 28, 2021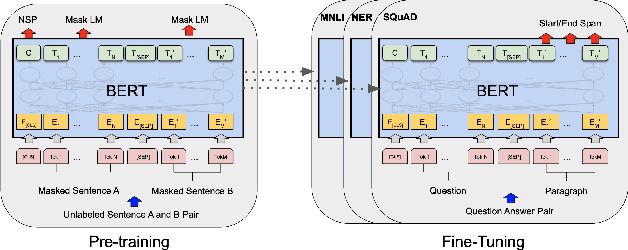

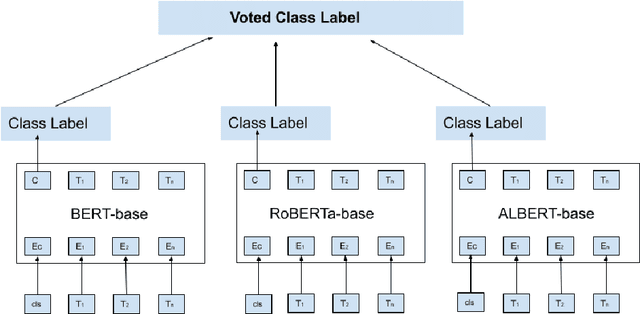

Sentiment analysis can provide a suitable lead for the tools used in software engineering along with the API recommendation systems and relevant libraries to be used. In this context, the existing tools like SentiCR, SentiStrength-SE, etc. exhibited low f1-scores that completely defeats the purpose of deployment of such strategies, thereby there is enough scope for performance improvement. Recent advancements show that transformer based pre-trained models (e.g., BERT, RoBERTa, ALBERT, etc.) have displayed better results in the text classification task. Following this context, the present research explores different BERT-based models to analyze the sentences in GitHub comments, Jira comments, and Stack Overflow posts. The paper presents three different strategies to analyse BERT based model for sentiment analysis, where in the first strategy the BERT based pre-trained models are fine-tuned; in the second strategy an ensemble model is developed from BERT variants, and in the third strategy a compressed model (Distil BERT) is used. The experimental results show that the BERT based ensemble approach and the compressed BERT model attain improvements by 6-12% over prevailing tools for the F1 measure on all three datasets.
Web based disease prediction and recommender system
Jun 05, 2021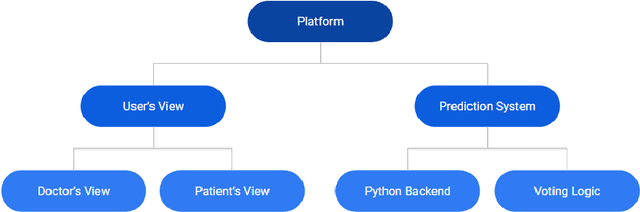
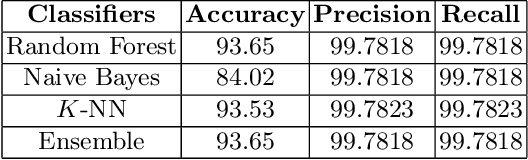
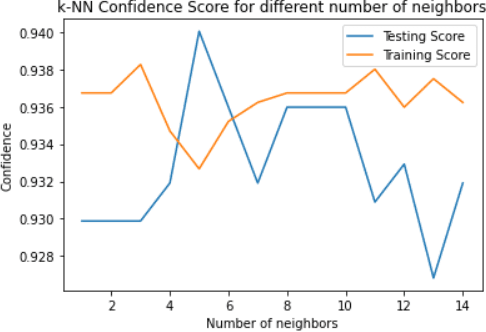
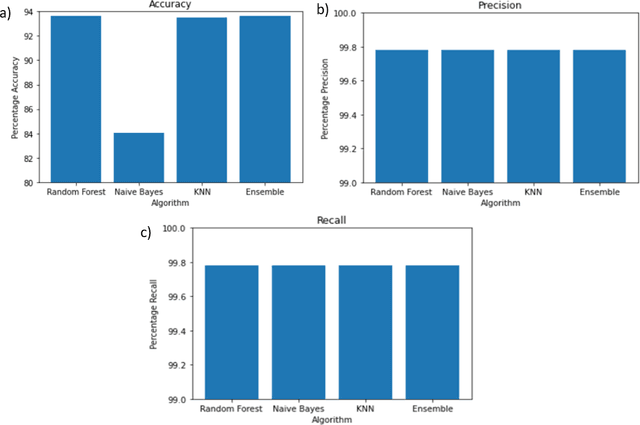
Worldwide, several cases go undiagnosed due to poor healthcare support in remote areas. In this context, a centralized system is needed for effective monitoring and analysis of the medical records. A web-based patient diagnostic system is a central platform to store the medical history and predict the possible disease based on the current symptoms experienced by a patient to ensure faster and accurate diagnosis. Early disease prediction can help the users determine the severity of the disease and take quick action. The proposed web-based disease prediction system utilizes machine learning based classification techniques on a data set acquired from the National Centre of Disease Control (NCDC). $K$-nearest neighbor (K-NN), random forest and naive bayes classification approaches are utilized and an ensemble voting algorithm is also proposed where each classifier is assigned weights dynamically based on the prediction confidence. The proposed system is also equipped with a recommendation scheme to recommend the type of tests based on the existing symptoms of the patient, so that necessary precautions can be taken. A centralized database ensures that the medical data is preserved and there is transparency in the system. The tampering into the system is prevented by giving the no "updation" rights once the diagnosis is created.
CHS-Net: A Deep learning approach for hierarchical segmentation of COVID-19 infected CT images
Jan 17, 2021

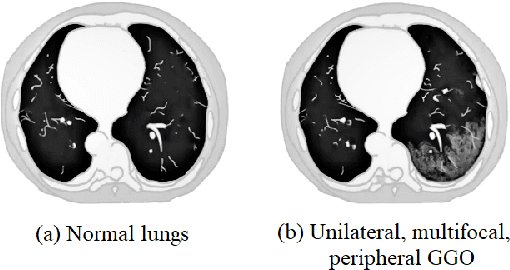
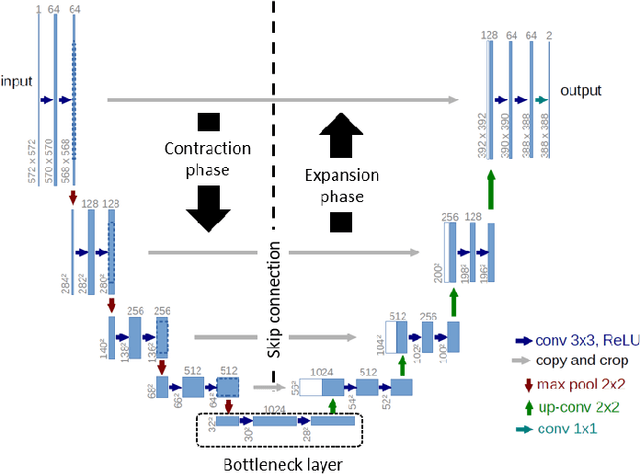
The pandemic of novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) also known as COVID-19 has been spreading worldwide, causing rampant loss of lives. Medical imaging such as computed tomography (CT), X-ray, etc., plays a significant role in diagnosing the patients by presenting the excellent details about the structure of the organs. However, for any radiologist analyzing such scans is a tedious and time-consuming task. The emerging deep learning technologies have displayed its strength in analyzing such scans to aid in the faster diagnosis of the diseases and viruses such as COVID-19. In the present article, an automated deep learning based model, COVID-19 hierarchical segmentation network (CHS-Net) is proposed that functions as a semantic hierarchical segmenter to identify the COVID-19 infected regions from lungs contour via CT medical imaging. The CHS-Net is developed with the two cascaded residual attention inception U-Net (RAIU-Net) models where first generates lungs contour maps and second generates COVID-19 infected regions. RAIU-Net comprises of a residual inception U-Net model with spectral spatial and depth attention network (SSD), consisting of contraction and expansion phases of depthwise separable convolutions and hybrid pooling (max and spectral pooling) to efficiently encode and decode the semantic and varying resolution information. The CHS-Net is trained with the segmentation loss function that is the weighted average of binary cross entropy loss and dice loss to penalize false negative and false positive predictions. The approach is compared with the recently proposed research works on the basis of standard metrics. With extensive trials, it is observed that the proposed approach outperformed the recently proposed approaches and effectively segments the COVID-19 infected regions in the lungs.
Early-stage COVID-19 diagnosis in presence of limited posteroanterior chest X-ray images via novel Pinball-OCSVM
Oct 16, 2020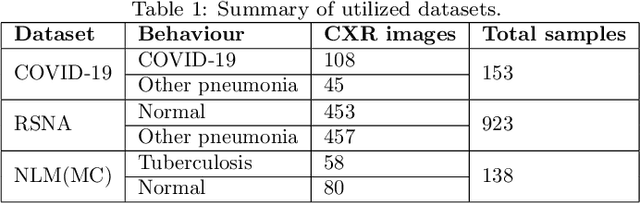
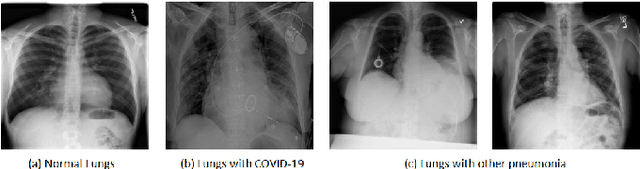
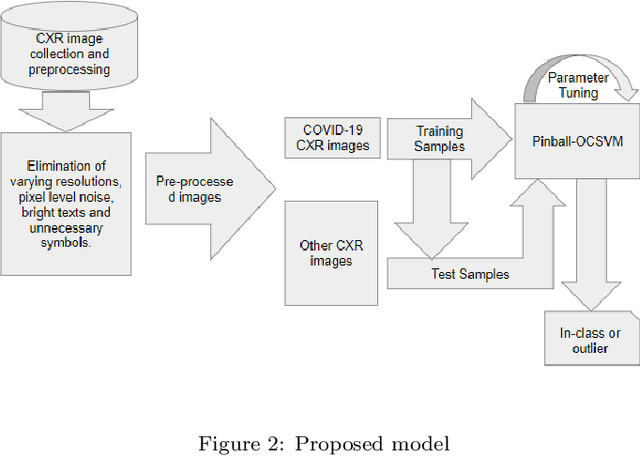
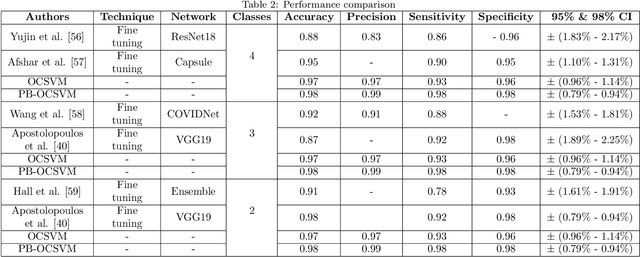
It is evident that the infection with this severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) starts with the upper respiratory tract and as the virus grows, the infection can progress to lungs and develop pneumonia. According to the statistics, approximately 14\% of the infected people with COVID-19 have severe cough and shortness of breath due to pneumonia, because as the viral infection increases, it damages the alveoli (small air sacs) and surrounding tissues. The conventional way of COVID-19 diagnosis is reverse transcription polymerase chain reaction (RT-PCR), which is less sensitive during early stages specially, if the patient is asymptomatic that may further lead to more severe pneumonia. To overcome this problem an early diagnosis method is proposed in this paper via one-class classification approach using a novel pinball loss function based one-class support vector machine (PB-OCSVM) considering posteroanterior chest X-ray images. Recently, several automated COVID-19 diagnosis models have been proposed based on various deep learning architectures to identify pulmonary infections using publicly available chest X-ray (CXR) where the presence of less number of COVID-19 positive samples compared to other classes (normal, pneumonia and Tuberculosis) raises the challenge for unbiased learning in deep learning models that has been solved using class balancing techniques which however should be avoided in any medical diagnosis process. Inspired by this phenomenon, this article proposes a novel PB-OCSVM model to work in presence of limited COVID-19 positive CXR samples with objectives to maximize the learning efficiency while minimize the false-positive and false-negative predictions. The proposed model outperformed over recently published deep learning approaches where accuracy, precision, specificity and sensitivity are used as performance measure parameters.
Face Mask Detection using Transfer Learning of InceptionV3
Sep 17, 2020


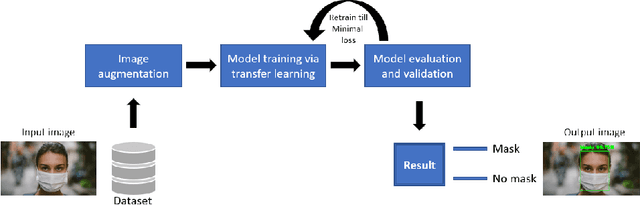
The world is facing a huge health crisis due to the rapid transmission of coronavirus (COVID-19). Several guidelines were issued by the World Health Organization (WHO) for protection against the spread of coronavirus. According to WHO, the most effective preventive measure against COVID-19 is wearing a mask in public places and crowded areas. It is very difficult to monitor people manually in these areas. In this paper, a transfer learning model is proposed to automate the process of identifying the people who are not wearing mask. The proposed model is built by fine-tuning the pre-trained state-of-the-art deep learning model, InceptionV3. The proposed model is trained and tested on the Simulated Masked Face Dataset (SMFD). Image augmentation technique is adopted to address the limited availability of data for better training and testing of the model. The model outperformed the other recently proposed approaches by achieving an accuracy of 99.9% during training and 100% during testing.
Fruit classification using deep feature maps in the presence of deceptive similar classes
Jul 12, 2020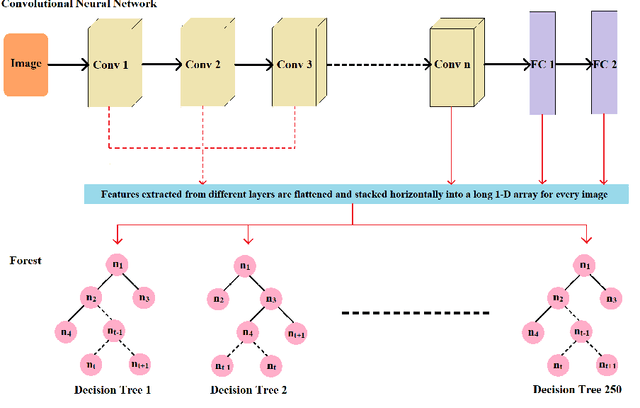
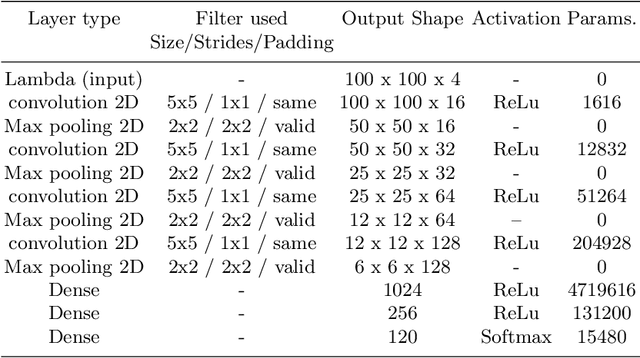

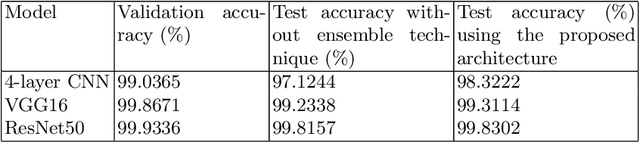
Autonomous detection and classification of objects are admired area of research in many industrial applications. Though, humans can distinguish objects with high multi-granular similarities very easily; but for the machines, it is a very challenging task. The convolution neural networks (CNN) have illustrated efficient performance in multi-level representations of objects for classification. Conventionally, the existing deep learning models utilize the transformed features generated by the rearmost layer for training and testing. However, it is evident that this does not work well with multi-granular data, especially, in presence of deceptive similar classes (almost similar but different classes). The objective of the present research is to address the challenge of classification of deceptively similar multi-granular objects with an ensemble approach thfat utilizes activations from multiple layers of CNN (deep features). These multi-layer activations are further utilized to build multiple deep decision trees (known as Random forest) for classification of objects with similar appearance. The Fruits-360 dataset is utilized for evaluation of the proposed approach. With extensive trials it was observed that the proposed model outperformed over the conventional deep learning approaches.
Enhanced Behavioral Cloning Based self-driving Car Using Transfer Learning
Jul 11, 2020

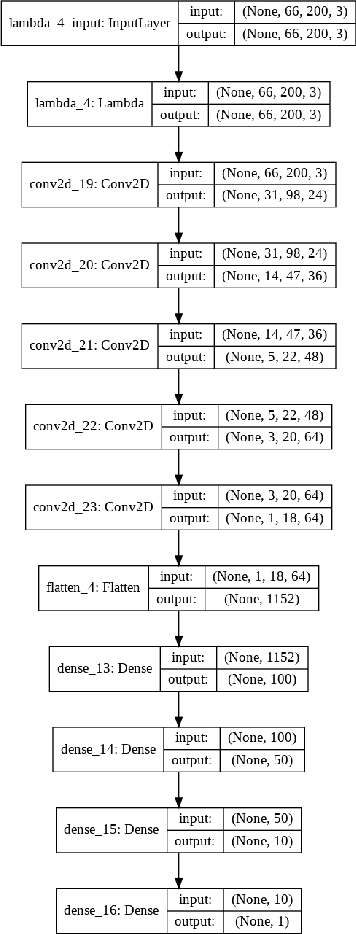

With the growing phase of artificial intelligence and autonomous learning, the self-driving car is one of the promising area of research and emerging as a center of focus for automobile industries. Behavioral cloning is the process of replicating human behavior via visuomotor policies by means of machine learning algorithms. In recent years, several deep learning-based behavioral cloning approaches have been developed in the context of self-driving cars specifically based on the concept of transfer learning. Concerning the same, the present paper proposes a transfer learning approach using VGG16 architecture, which is fine tuned by retraining the last block while keeping other blocks as non-trainable. The performance of proposed architecture is further compared with existing NVIDIA architecture and its pruned variants (pruned by 22.2% and 33.85% using 1x1 filter to decrease the total number of parameters). Experimental results show that the VGG16 with transfer learning architecture has outperformed other discussed approaches with faster convergence.
Automated diagnosis of COVID-19 with limited posteroanterior chest X-ray images using fine-tuned deep neural networks
May 28, 2020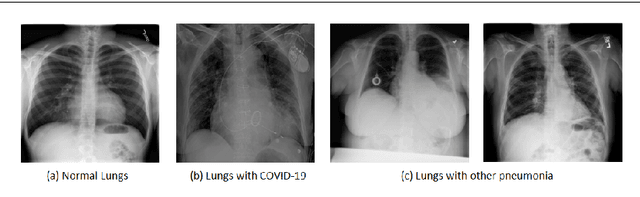
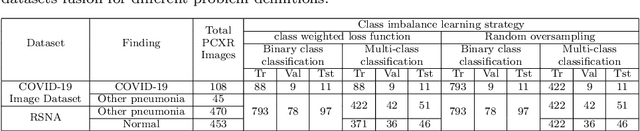
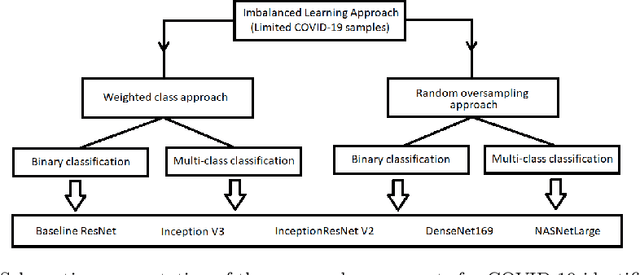
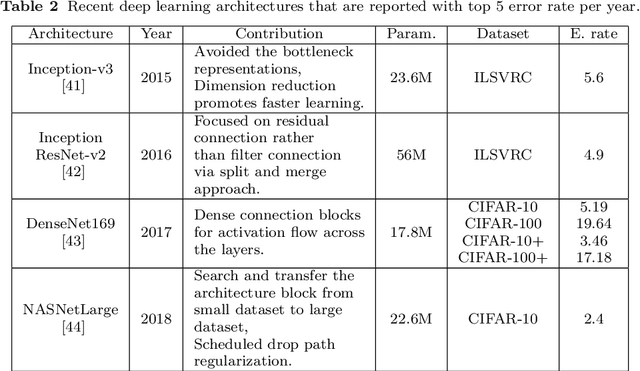
The novel coronavirus 2019 (COVID-19) is a respiratory syndrome that resembles pneumonia. The current diagnostic procedure of COVID-19 follows reverse-transcriptase polymerase chain reaction (RT-PCR) based approach which however is less sensitive to identify the virus at the initial stage. Hence, a more robust and alternate diagnosis technique is desirable. Recently, with the release of publicly available datasets of corona positive patients comprising of computed tomography (CT) and chest X-ray (CXR) imaging; scientists, researchers and healthcare experts are contributing for faster and automated diagnosis of COVID-19 by identifying pulmonary infections using deep learning approaches to achieve better cure and treatment. These datasets have limited samples concerned with the positive COVID-19 cases, which raise the challenge for unbiased learning. Following from this context, this article presents the random oversampling and weighted class loss function approach for unbiased fine-tuned learning (transfer learning) in various state-of-the-art deep learning approaches such as baseline ResNet, Inception-v3, Inception ResNet-v2, DenseNet169, and NASNetLarge to perform binary classification (as normal and COVID-19 cases) and also multi-class classification (as COVID-19, pneumonia, and normal case) of posteroanterior CXR images. Accuracy, precision, recall, loss, and area under the curve (AUC) are utilized to evaluate the performance of the models. Considering the experimental results, the performance of each model is scenario dependent; however, NASNetLarge displayed better scores in contrast to other architectures, which is further compared with other recently proposed approaches. This article also added the visual explanation to illustrate the basis of model classification and perception of COVID-19 in CXR images.