 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoham De
The Impact of Neural Network Overparameterization on Gradient Confusion and Stochastic Gradient Descent
Apr 15, 2019
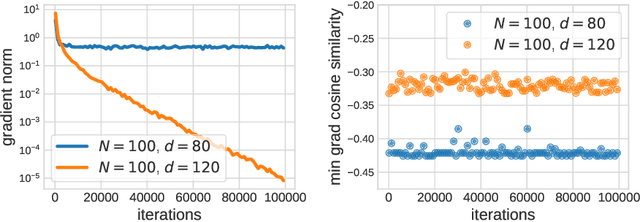
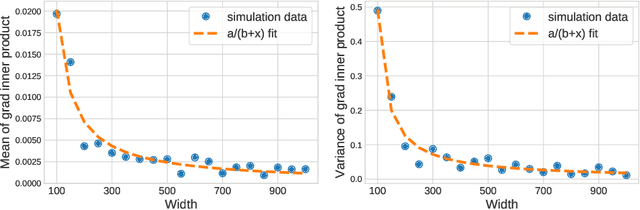
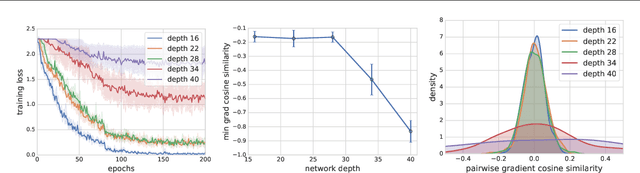
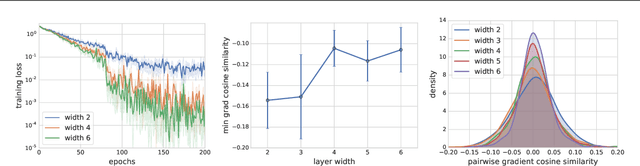
The goal of this paper is to study why stochastic gradient descent (SGD) is efficient for neural networks, and how neural net design affects SGD. In particular, we investigate how overparameterization -- an increase in the number of parameters beyond the number of training data -- affects the dynamics of SGD. We introduce a simple concept called gradient confusion. When confusion is high, stochastic gradients produced by different data samples may be negatively correlated, slowing down convergence. But when gradient confusion is low, we show that SGD has better convergence properties than predicted by classical theory. Using theoretical and experimental results, we study how overparameterization affects gradient confusion, and thus the convergence of SGD, on linear models and neural networks. We show that increasing the number of parameters of linear models or increasing the width of neural networks leads to lower gradient confusion, and thus faster and easier model training. We also show how overparameterization by increasing the depth of neural networks results in higher gradient confusion, making deeper models harder to train. Finally, we observe empirically that techniques like batch normalization and skip connections reduce gradient confusion, which helps reduce the training burden of deep networks.
Convergence guarantees for RMSProp and ADAM in non-convex optimization and an empirical comparison to Nesterov acceleration
Oct 08, 2018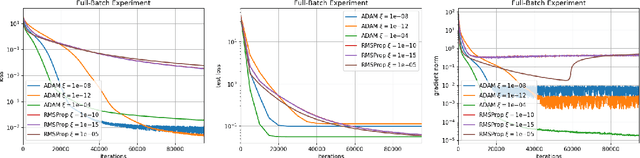
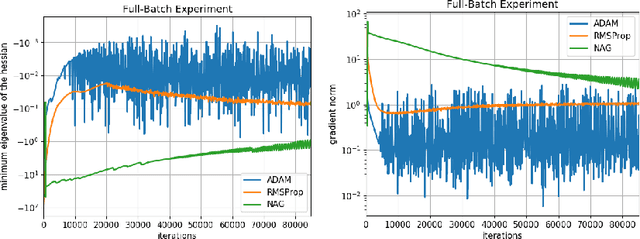
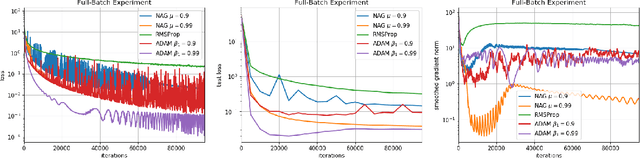
RMSProp and ADAM continue to be extremely popular algorithms for training neural nets but their theoretical convergence properties have remained unclear. Further, recent work has seemed to suggest that these algorithms have worse generalization properties when compared to carefully tuned stochastic gradient descent or its momentum variants. In this work, we make progress towards a deeper understanding of ADAM and RMSProp in two ways. First, we provide proofs that these adaptive gradient algorithms are guaranteed to reach criticality for smooth non-convex objectives, and we give bounds on the running time. Next we design experiments to empirically study the convergence and generalization properties of RMSProp and ADAM against Nesterov's Accelerated Gradient method on a variety of common autoencoder setups. Through these experiments we demonstrate the interesting sensitivity that ADAM has to its momentum parameter $\beta_1$. We show that at very high values of the momentum parameter ($\beta_1 = 0.99$) ADAM outperforms a carefully tuned NAG on most of our experiments, in terms of getting lower training and test losses. On the other hand, NAG can sometimes do better when ADAM's $\beta_1$ is set to the most commonly used value: $\beta_1 = 0.9$, indicating the importance of tuning the hyperparameters of ADAM to get better generalization performance. We also report experiments on different autoencoders to demonstrate that NAG has better abilities in terms of reducing the gradient norms, and it also produces iterates which exhibit an increasing trend for the minimum eigenvalue of the Hessian of the loss function at the iterates.
Training Quantized Nets: A Deeper Understanding
Nov 13, 2017
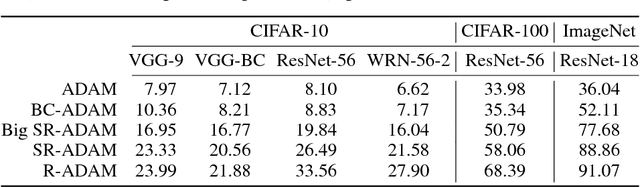
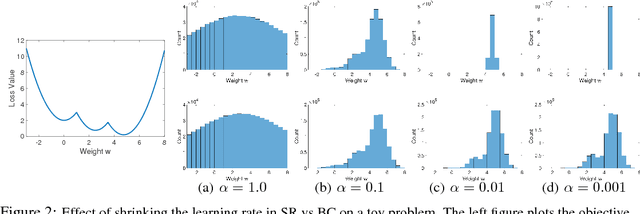
Currently, deep neural networks are deployed on low-power portable devices by first training a full-precision model using powerful hardware, and then deriving a corresponding low-precision model for efficient inference on such systems. However, training models directly with coarsely quantized weights is a key step towards learning on embedded platforms that have limited computing resources, memory capacity, and power consumption. Numerous recent publications have studied methods for training quantized networks, but these studies have mostly been empirical. In this work, we investigate training methods for quantized neural networks from a theoretical viewpoint. We first explore accuracy guarantees for training methods under convexity assumptions. We then look at the behavior of these algorithms for non-convex problems, and show that training algorithms that exploit high-precision representations have an important greedy search phase that purely quantized training methods lack, which explains the difficulty of training using low-precision arithmetic.
Variance Reduction for Distributed Stochastic Gradient Descent
Apr 07, 2017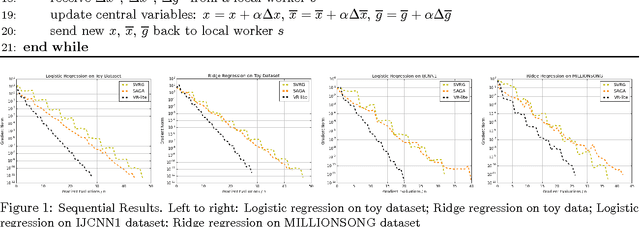
Variance reduction (VR) methods boost the performance of stochastic gradient descent (SGD) by enabling the use of larger, constant stepsizes and preserving linear convergence rates. However, current variance reduced SGD methods require either high memory usage or an exact gradient computation (using the entire dataset) at the end of each epoch. This limits the use of VR methods in practical distributed settings. In this paper, we propose a variance reduction method, called VR-lite, that does not require full gradient computations or extra storage. We explore distributed synchronous and asynchronous variants that are scalable and remain stable with low communication frequency. We empirically compare both the sequential and distributed algorithms to state-of-the-art stochastic optimization methods, and find that our proposed algorithms perform favorably to other stochastic methods.
Efficient Distributed SGD with Variance Reduction
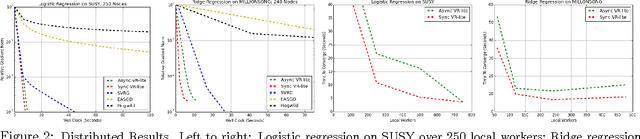
Apr 07, 2017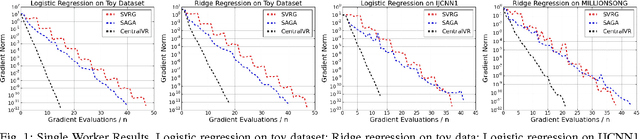
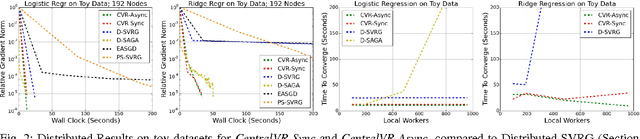
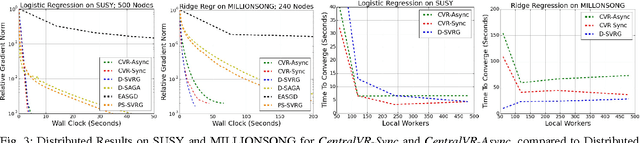
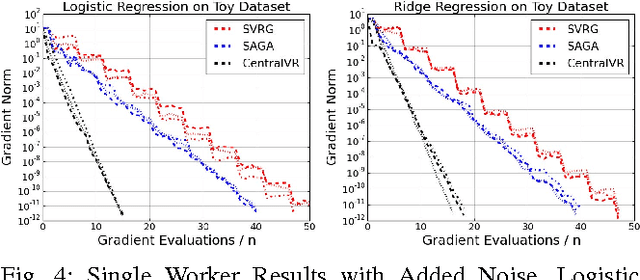
Stochastic Gradient Descent (SGD) has become one of the most popular optimization methods for training machine learning models on massive datasets. However, SGD suffers from two main drawbacks: (i) The noisy gradient updates have high variance, which slows down convergence as the iterates approach the optimum, and (ii) SGD scales poorly in distributed settings, typically experiencing rapidly decreasing marginal benefits as the number of workers increases. In this paper, we propose a highly parallel method, CentralVR, that uses error corrections to reduce the variance of SGD gradient updates, and scales linearly with the number of worker nodes. CentralVR enjoys low iteration complexity, provably linear convergence rates, and exhibits linear performance gains up to hundreds of cores for massive datasets. We compare CentralVR to state-of-the-art parallel stochastic optimization methods on a variety of models and datasets, and find that our proposed methods exhibit stronger scaling than other SGD variants.
Big Batch SGD: Automated Inference using Adaptive Batch Sizes
Apr 06, 2017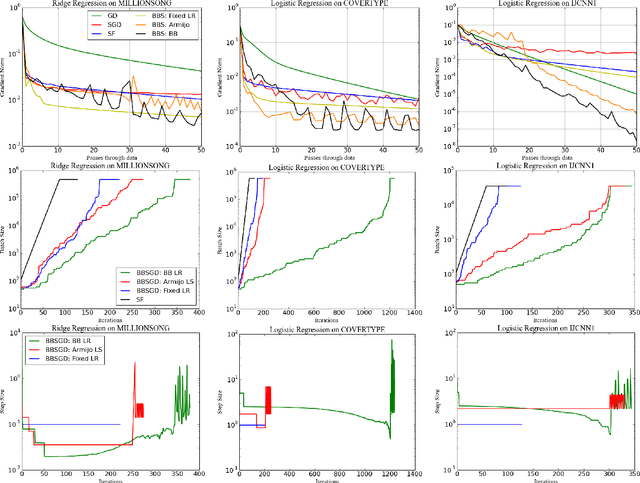
Classical stochastic gradient methods for optimization rely on noisy gradient approximations that become progressively less accurate as iterates approach a solution. The large noise and small signal in the resulting gradients makes it difficult to use them for adaptive stepsize selection and automatic stopping. We propose alternative "big batch" SGD schemes that adaptively grow the batch size over time to maintain a nearly constant signal-to-noise ratio in the gradient approximation. The resulting methods have similar convergence rates to classical SGD, and do not require convexity of the objective. The high fidelity gradients enable automated learning rate selection and do not require stepsize decay. Big batch methods are thus easily automated and can run with little or no oversight.
Son of Zorn's Lemma: Targeted Style Transfer Using Instance-aware Semantic Segmentation
Jan 09, 2017
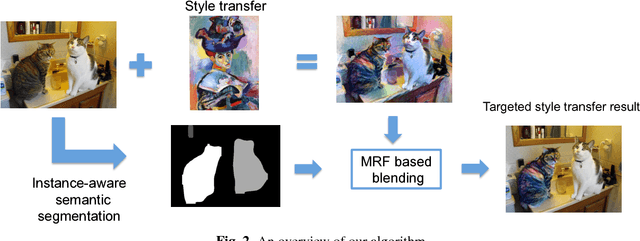

Style transfer is an important task in which the style of a source image is mapped onto that of a target image. The method is useful for synthesizing derivative works of a particular artist or specific painting. This work considers targeted style transfer, in which the style of a template image is used to alter only part of a target image. For example, an artist may wish to alter the style of only one particular object in a target image without altering the object's general morphology or surroundings. This is useful, for example, in augmented reality applications (such as the recently released Pokemon GO), where one wants to alter the appearance of a single real-world object in an image frame to make it appear as a cartoon. Most notably, the rendering of real-world objects into cartoon characters has been used in a number of films and television show, such as the upcoming series Son of Zorn. We present a method for targeted style transfer that simultaneously segments and stylizes single objects selected by the user. The method uses a Markov random field model to smooth and anti-alias outlier pixels near object boundaries, so that stylized objects naturally blend into their surroundings.
An Empirical Study of ADMM for Nonconvex Problems
Dec 10, 2016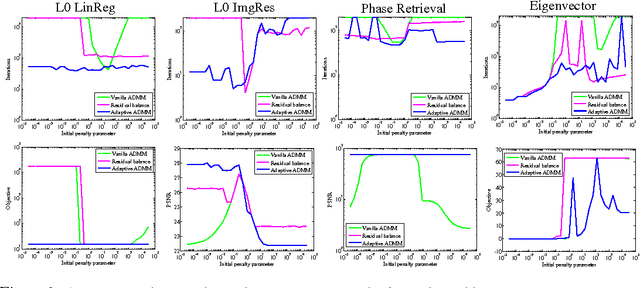
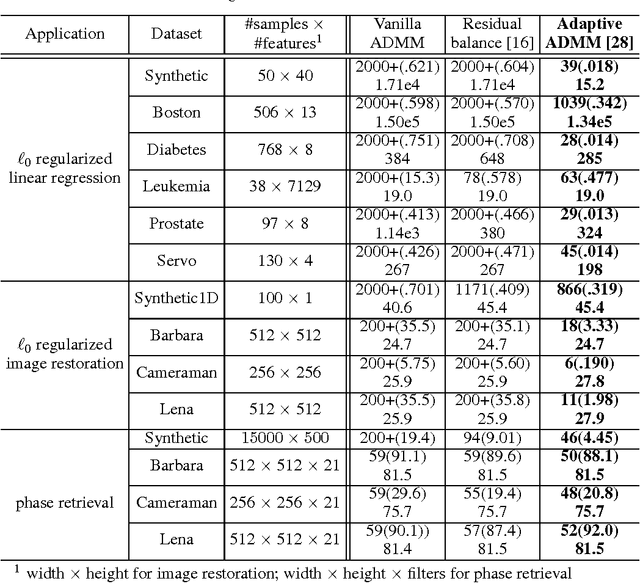
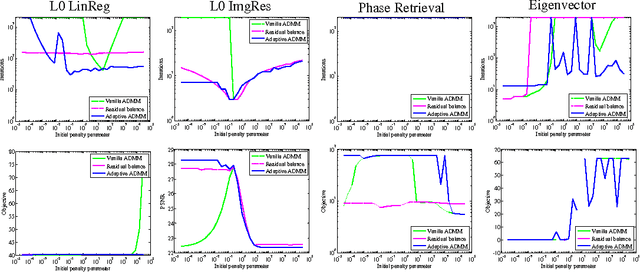
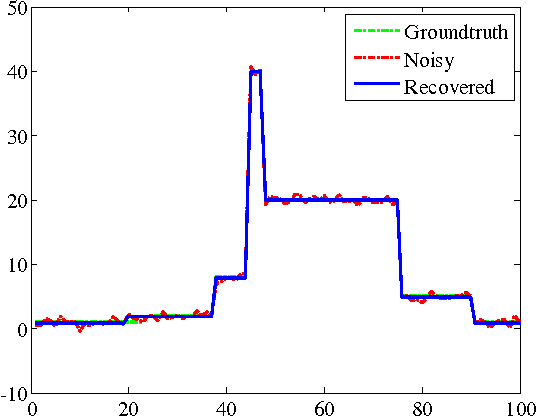
The alternating direction method of multipliers (ADMM) is a common optimization tool for solving constrained and non-differentiable problems. We provide an empirical study of the practical performance of ADMM on several nonconvex applications, including l0 regularized linear regression, l0 regularized image denoising, phase retrieval, and eigenvector computation. Our experiments suggest that ADMM performs well on a broad class of non-convex problems. Moreover, recently proposed adaptive ADMM methods, which automatically tune penalty parameters as the method runs, can improve algorithm efficiency and solution quality compared to ADMM with a non-tuned penalty.
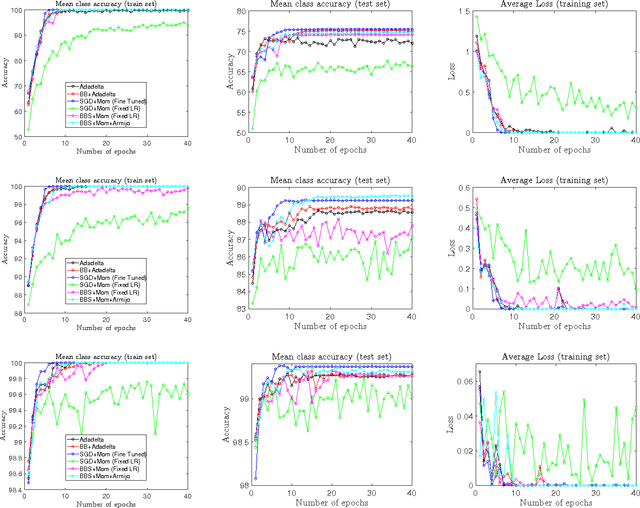
Layer-Specific Adaptive Learning Rates for Deep Networks
Oct 15, 2015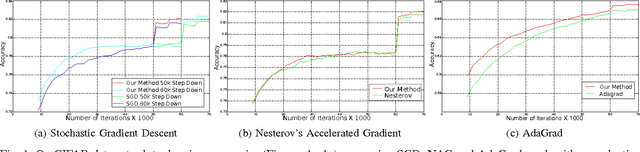
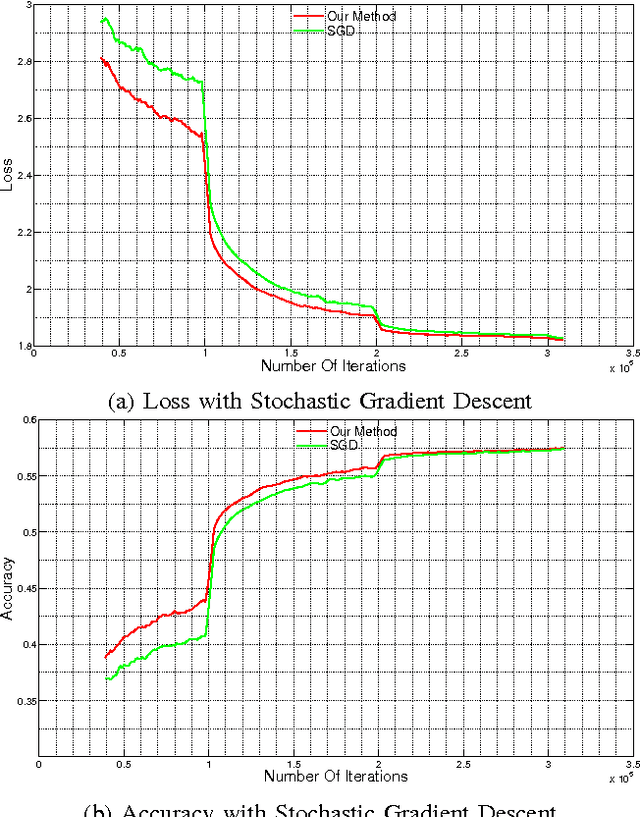


The increasing complexity of deep learning architectures is resulting in training time requiring weeks or even months. This slow training is due in part to vanishing gradients, in which the gradients used by back-propagation are extremely large for weights connecting deep layers (layers near the output layer), and extremely small for shallow layers (near the input layer); this results in slow learning in the shallow layers. Additionally, it has also been shown that in highly non-convex problems, such as deep neural networks, there is a proliferation of high-error low curvature saddle points, which slows down learning dramatically. In this paper, we attempt to overcome the two above problems by proposing an optimization method for training deep neural networks which uses learning rates which are both specific to each layer in the network and adaptive to the curvature of the function, increasing the learning rate at low curvature points. This enables us to speed up learning in the shallow layers of the network and quickly escape high-error low curvature saddle points. We test our method on standard image classification datasets such as MNIST, CIFAR10 and ImageNet, and demonstrate that our method increases accuracy as well as reduces the required training time over standard algorithms.
Plagiarism Detection in Polyphonic Music using Monaural Signal Separation
Feb 27, 2015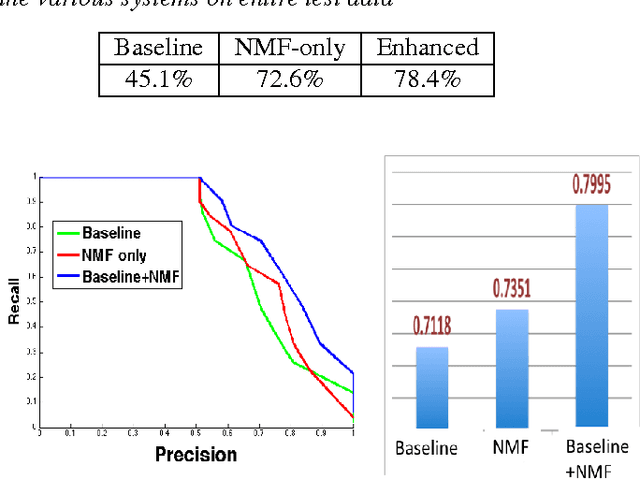
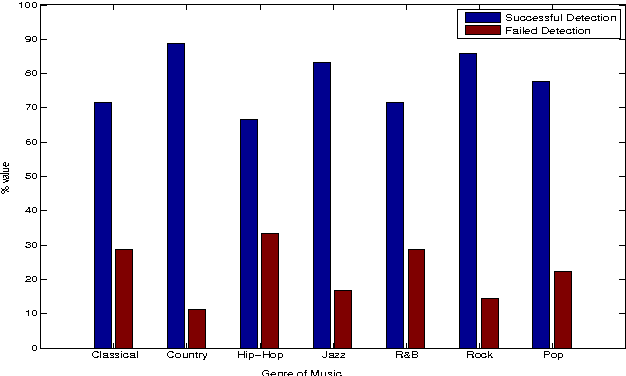
Given the large number of new musical tracks released each year, automated approaches to plagiarism detection are essential to help us track potential violations of copyright. Most current approaches to plagiarism detection are based on musical similarity measures, which typically ignore the issue of polyphony in music. We present a novel feature space for audio derived from compositional modelling techniques, commonly used in signal separation, that provides a mechanism to account for polyphony without incurring an inordinate amount of computational overhead. We employ this feature representation in conjunction with traditional audio feature representations in a classification framework which uses an ensemble of distance features to characterize pairs of songs as being plagiarized or not. Our experiments on a database of about 3000 musical track pairs show that the new feature space characterization produces significant improvements over standard baselines.
* Preprint version