 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Bilinear Deep Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018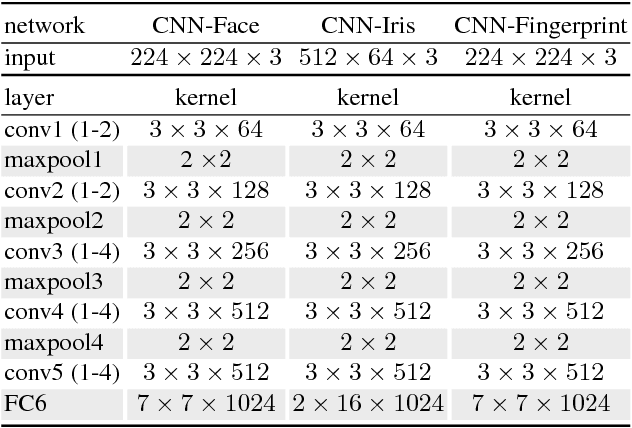
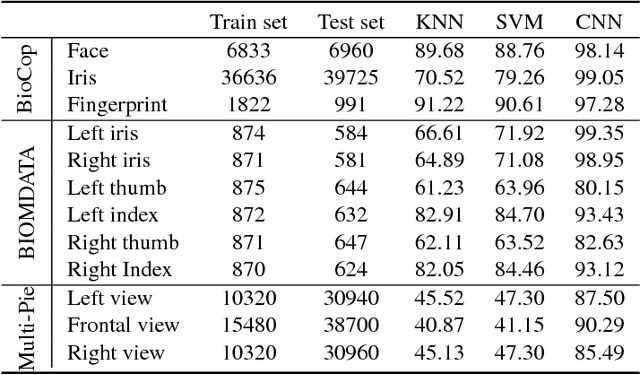
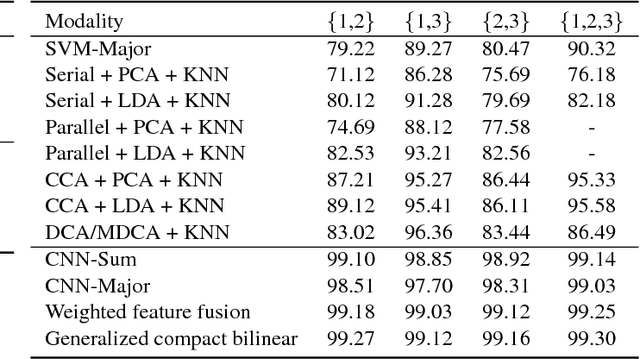
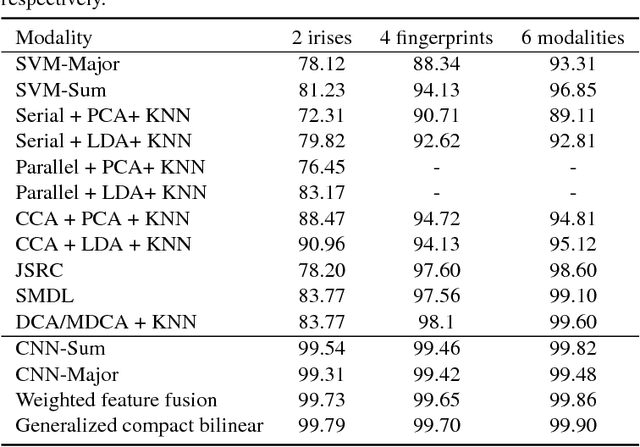
In this paper, we propose to employ a bank of modality-dedicated Convolutional Neural Networks (CNNs), fuse, train, and optimize them together for person classification tasks. A modality-dedicated CNN is used for each modality to extract modality-specific features. We demonstrate that, rather than spatial fusion at the convolutional layers, the fusion can be performed on the outputs of the fully-connected layers of the modality-specific CNNs without any loss of performance and with significant reduction in the number of parameters. We show that, using multiple CNNs with multimodal fusion at the feature-level, we significantly outperform systems that use unimodal representation. We study weighted feature, bilinear, and compact bilinear feature-level fusion algorithms for multimodal biometric person identification. Finally, We propose generalized compact bilinear fusion algorithm to deploy both the weighted feature fusion and compact bilinear schemes. We provide the results for the proposed algorithms on three challenging databases: CMU Multi-PIE, BioCop, and BIOMDATA.
Attribute-Centered Loss for Soft-Biometrics Guided Face Sketch-Photo Recognition
Apr 09, 2018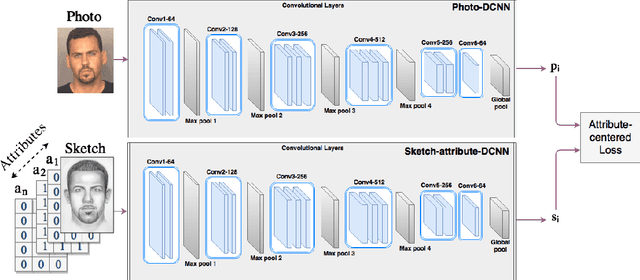

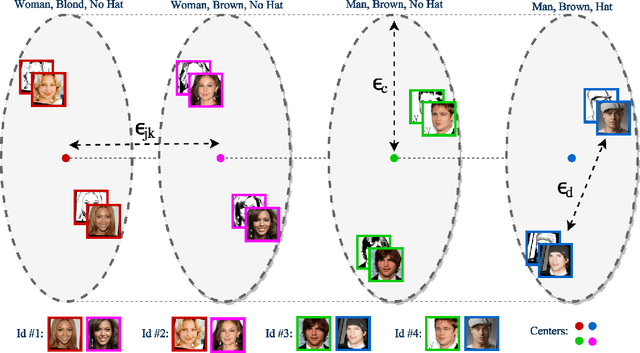

Face sketches are able to capture the spatial topology of a face while lacking some facial attributes such as race, skin, or hair color. Existing sketch-photo recognition approaches have mostly ignored the importance of facial attributes. In this paper, we propose a new loss function, called attribute-centered loss, to train a Deep Coupled Convolutional Neural Network (DCCNN) for the facial attribute guided sketch to photo matching. Specifically, an attribute-centered loss is proposed which learns several distinct centers, in a shared embedding space, for photos and sketches with different combinations of attributes. The DCCNN simultaneously is trained to map photos and pairs of testified attributes and corresponding forensic sketches around their associated centers, while preserving the spatial topology information. Importantly, the centers learn to keep a relative distance from each other, related to their number of contradictory attributes. Extensive experiments are performed on composite (E-PRIP) and semi-forensic (IIIT-D Semi-forensic) databases. The proposed method significantly outperforms the state-of-the-art.